2015年10月14日
データサイエンスのワークフロー ― データ分析を効率に行うために
(2015-09-08)by Florentino Bexiga
本記事は、原著者の許諾のもとに翻訳・掲載しております。
データを扱うときに、きちんと定められたワークフローがあると助かります。具体的には、「ストーリーを伝える」(データの可視化/ジャーナリズム)ことだけを目的として分析を行いたいのか、それとも一定のタスク(データマイニング)をモデリングするためにデータに依存するシステムを構築することが目的なのか、プロセスが重要です。前もって方法論を定めておくことによって、チームの足並みが揃い、次に何をすべきか考え出そうとして無駄な時間を費やさなくて済みます。それによって早く結果が得られ、資料の公表も早くなります。
これを念頭に、Ashley Madisonの漏洩データ分析に関する 前回の記事 に続いて、私たちが現在使用しているワークフローをご紹介します。このワークフローは、データ漏洩(Ashleyのケースなど)を分析するためだけでなく、社内のデータの分析にも使用されます。ただし、重要な点として、このワークフローは未完成であり、より効率的な結果を得るために今後変更される可能性があります。
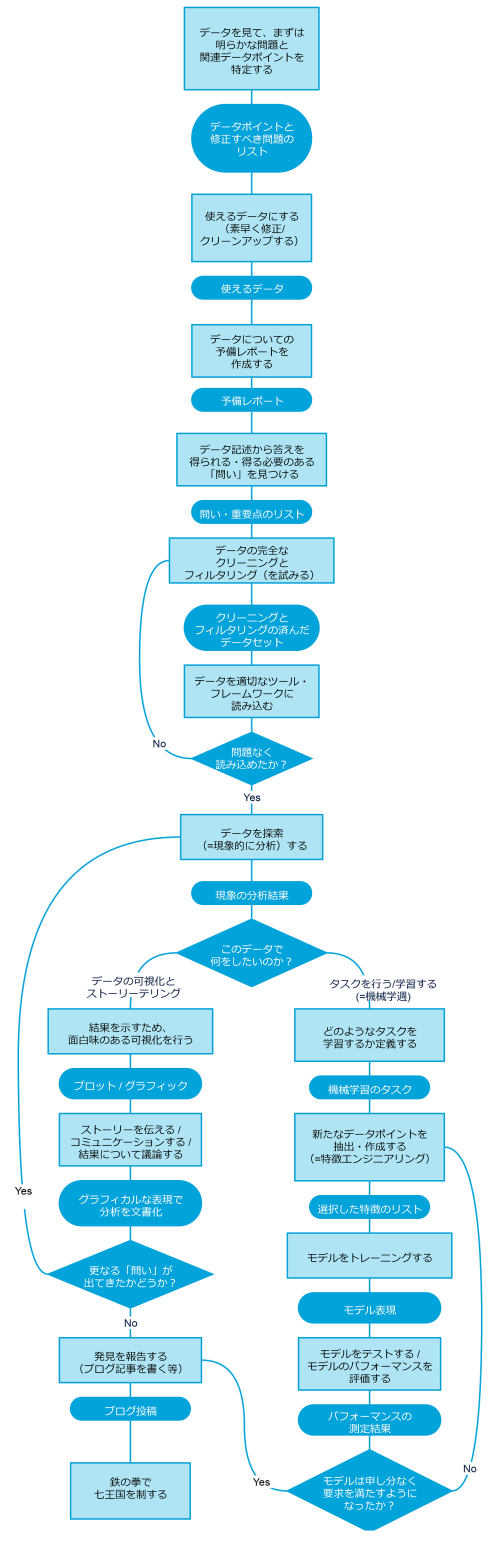
予備的分析(データの問題点の洗い出し)
まず、データを最初に見て、明らかな問題(修正する必要のある問題)があるか、また、それに関する(使用できる)データポイントを特定しなければなりません。
簡単に修正できる問題が特定された場合は、データをすぐに使えるようにするために、素早い修正とデータクリーニングを行わなければなりません。
この時点で、データについての予備レポートを作成し、レポートにはデータポイントの簡単な説明(フォーマット、タイプ、意味)を記載します。目標は、早い段階で関係者に注目させるために、洞察力があって公表に値する内容を、なるべく早く作成することです。
探索的データ分析
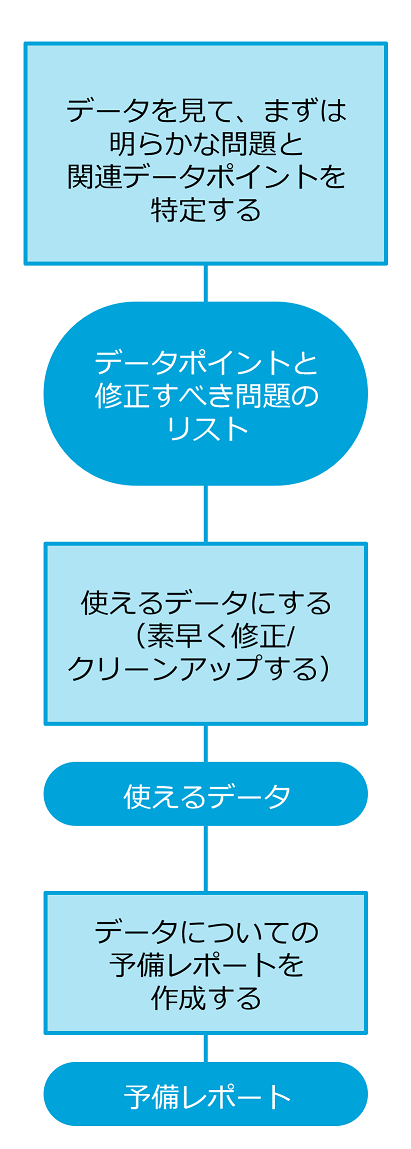
データの予備分析の後は、もっと方法論的な手法を適用しなければなりません。第1のステップは、データから答えが分かる可能性のある問いについて考え始めることです。
予備的分析で特定された関連データポイントは、次に、クリーニングしてフィルタにかける必要があります。クリーニングの過程には、テキストからスペースと非表示文字を取り除くこと、データを変換すること、ガベージ領域から使えるデータを抽出することなどの、いくつかの方策が伴います。
クリーニング済みのデータは、適切なフレームワークやツールでの読み込みが容易なフォーマット(CVS、JSONなど)に変換することもできます。
読み込みでなにか問題が発生した場合は、クリーニングでなんらかの詳細が脱落した可能性が高いので、前のステップのいくつかを見直すべきです。
クリーニングとフィルタリングの済んだデータの読み込みに成功したら、次のステップは、データを隅々まで探索することです。主な目的は、データセットを洞察すること、つまり、生データを実際の情報コンテンツに変形させることです。
「探索的データ分析」とは、そこにあると信じられているもの、そこに無いと信じられているもの、それらを探すための態度、柔軟さ、意思である ― John Tukey
この時点で、「このデータで何をしたいのか」という問いに答えることができなければなりません。
データの可視化 / ストーリーを伝える
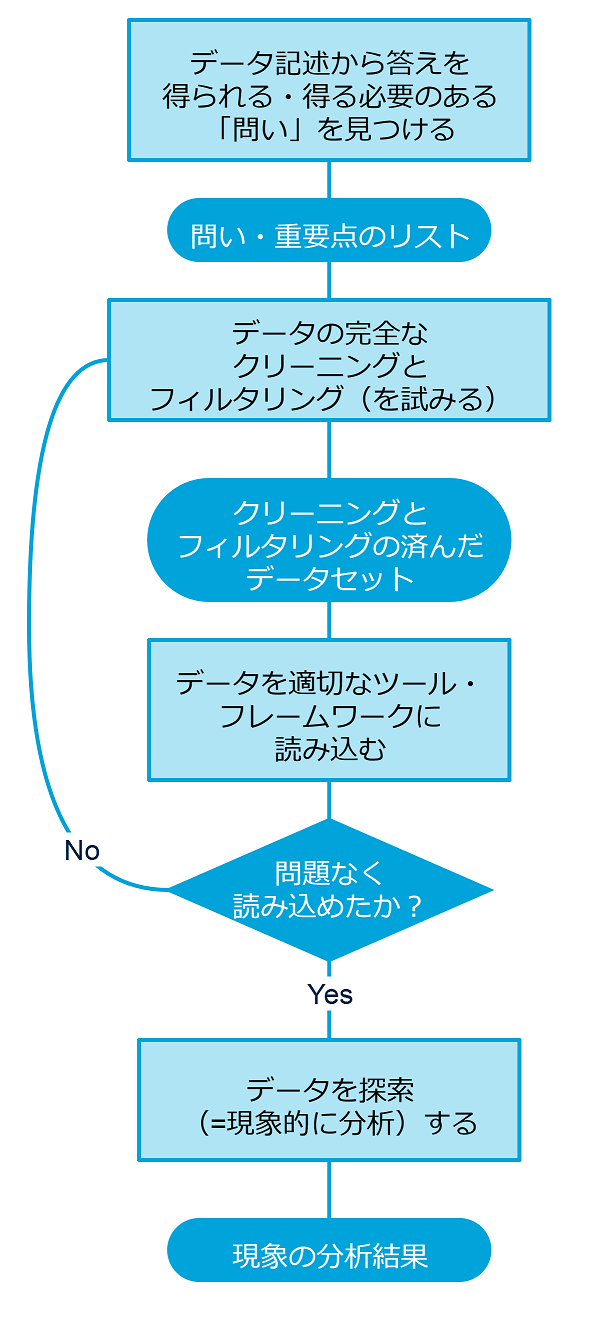
データをよく理解することだけが目的なら、探索的分析で得られた結果を表現する最良の方法を見つけなければなりません。
読者を惹きつけるストーリーを作るためには、最も関心の高い結果を定めることから最も魅力的で分かりやすい視覚技法を見つけることまでにわたって、すべての詳細が最重要項目になります。ある分析を行うと、他にも興味をそそる側面が明らかになることがよくあり、さらにまた探索しなければならなくなります。
「データ分析に可視化は不可欠である。可視化はいわば攻撃の最前線であり、他のどんな方法でも理解することのできない複雑なデータの構造を明らかにする。予想外の効果が見つかり、予想した効果には異議がとなえられる」―ウィリアム・クリーブランド
可視化が完成し、ストーリーの「スクリプト」が準備できたら、最後のステップは、例えば、ブログ記事を書くなどして、分析結果を発表することです。
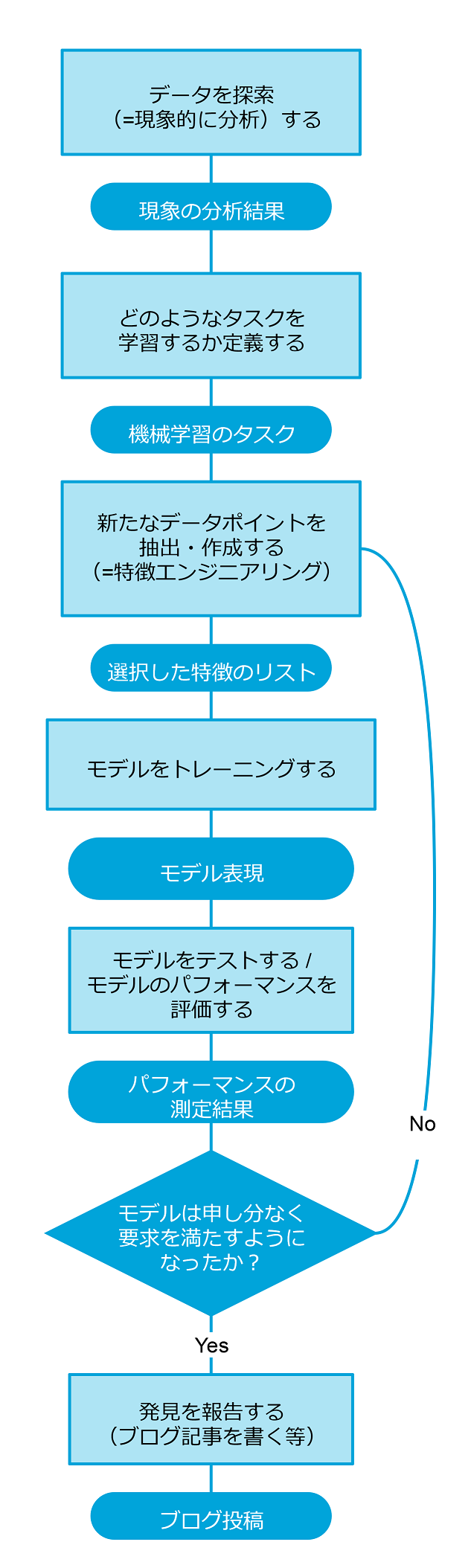
知識の発見
分析の目的がモデルを作成することであり、そのために変数間の関係を探索し、データが発生するプロセスを理解しなければならない場合には、更に幾つかのステップが必要となります。
まず手始めに、どういうタイプの課題もしくはタスクがあるのか見極めなければなりません(回帰、分類、クラスタリングなど)。それから、特徴の抽出と選択を行います。これは、データの中から関連する情報だけを取り出すために、そして特定の学習タスクにとって最も重要な特徴を確認するために必要な作業です。
トレーニングもしくはテストのためのデータが準備できたら、モデルを構築できます。テスト時のモデルのパフォーマンス次第では、データセットを再構築したり、もしくは、結果を最適化するために異なるアルゴリズムを採用したりする必要が出てくるかもしれません。
モデルが申し分のないパフォーマンスを見せるようになったら、結果及び得られた発見について報告しなければなりません。
最後に
これまで見てきたように、データを取り扱う場合には特に、プロセスが重要です。初期の段階では、タイムリーかつ洞察に満ちた結果の発見が非常に重要な意味を持ちます。その後は、広範囲に渡って細心の注意を払った分析が求められます。そのすべての場面において、きちんと定められたワークフローがあれば、チームは効果的に、データジャーナリズム(ストーリーを伝える)であれデータマイニング(データをモデリングする)であれ、目標を達成することができるでしょう。
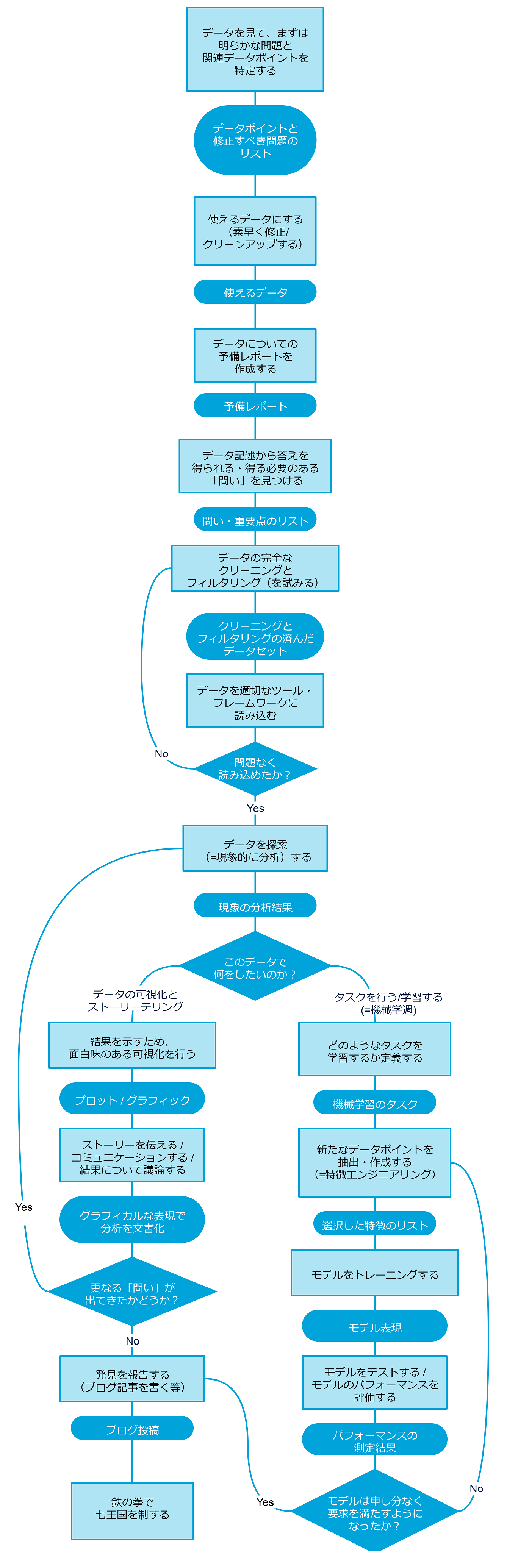
同様にBinaryEdgeのデータサイエンスチームでも、ワークフローを作るべく作業を進めています。このワークフローは、既に行われた業務、並びに今後行われる業務を表現しています。最後に挙げる図をみるとお分かりのとおり、4つのメインフェーズに分かれています。
最初のフェーズは、データをまだ入手したばかりの段階における「予備的分析」であり、データポイントの概要を把握するために素早く結果を出すことが肝心です。この段階における焦点は、データをできるかぎり迅速に使える形式に変更し、興味深い洞察をすぐに導く、ということです。
次のフェーズでは、「探索的データ分析」が行われます。ここでは「問い」がシステマティックに検証されます。そしてその回答を得るために、データのクリーニングとフィルタリングが行われます。
この後の段階では、データを最終的にどのようにしたいかによって、2つの異なるフェーズが考えられます。
「探索的データ分析」の結果を表したい場合には、「データを可視化してストーリーを伝える」、というフェーズへ移ります。この段階では、「どのように」結果を表すか、ということに焦点が移ります。データを可視化すること、そして元のデータに隠されているあらゆる「秘密」を語り、ユーザを魅了する「ストーリー」を作り出すことが、このフェーズにおける最も重要な課題です。
モデルを構築するためにデータのパターンを検討したい、という状況も考えられます。その場合には「知識の発見」フェーズへと進みます。ここでの焦点は、データをよりよく「説明する」モデルを構築することです。そのためには、データポイントをフィルタリングしたり新たに作成したりした後(エンジニアリング)、最適なパフォーマンスを可能とするアルゴリズムを探し当てるために幾つかテストを行います。
こちらの図が、データサイエンスのワークフロー全体を表しているものです。
先ほど触れましたが、このワークフローが確定版というわけではありません。業務の効率を向上するためにたゆまず変化し続けています。皆さんからのご意見やご提案をコメント欄に頂ければ幸いです。
私たちの最新のデータ分析や記事をタイムリーに入手するためには、ぜひ ツイッター や Google+ 、 フェイスブック をフォローしてください。
