2016年6月20日
ソフトウェアエンジニアは一般的な人々と比べてどのくらい稼ぐのか : Pythonでのデータ収集・処理・可視化
本�記事は、原著者の許諾のもとに翻訳・掲載しております。
(訳注:2016/7/15、記事を修正いたしました。)
本記事では、世界50カ国におけるソフトウェアエンジニアの年収の中央値と国内の年収の平均値(1人当たりのGDP)を比較します。その方法は、まず lxml を使ってWebページからデータを収集し、 Pandas のデータフレームに変換した後、クリーニングを行います。そのデータに対し matplotlib を使い、全体としての傾向を可視化する散布図と棒グラフを作成するというものです。一般的な人々と比較するとソフトウェアエンジニアはどのくらい稼いでいるのか、その収入が高い国と低い国を比較してみましょう。
データは PayScale と 国際通貨基金(IMF) から得たもので、2014年5月に Bloomberg に掲載されたものです。そこに、PayScaleが最も入手しやすい50カ国の統計データが含まれていました。ソフトウェアエンジニアに関するその統計データは2013年5月1日~2014年5月1日の収入データで、2014年5月5日時点の為替レートを使って換算されています。調査に回答した各国のソフトウェアエンジニアの実務経験年数の中央値は2~5年に及んでいました。
セットアップ
まず、必要なライブラリをロードし、プロットスタイルといくつかの変数を設定します。このとき、 geonamescache オブジェクトも設定します。地理データと年収の統計データをこの インタラクティブマップ でリンクさせるため、国コードの追加が必要になるからです。
%load_ext signature
%matplotlib inline
import os
import pandas as pd
import matplotlib as mpl
import matplotlib.pyplot as plt
import numpy as np
import geonamescache
from lxml import html
mpl.style.use('ramiro')
data_dir = os.path.expanduser('~/data')
gc = geonamescache.GeonamesCache()
chartinfo = '''Figures represent income data from May 2013 to May 2014 using exchange rates from May 2014. Average annual income figures are for 2014.
Author: Ramiro Gómez - ramiro.org • Data: Bloomberg/PayScale - bloomberg.com/visual-data/best-and-worst/highest-paid-software-engineers-countries'''データ検索とクリーニング
Webページからデータを収集するため、ソースを調べて、データテーブルを特定する方法を決めました。データテーブルは、そのページで hid のクラスを持つ唯一のテーブルなので、以下のxpathの式で、ロード後にHTMLソースからテーブルを抽出することができるようにしています。
url ='http://www.bloomberg.com/visual-data/best-and-worst/highest-paid-software-engineers-countries'
xpath = '//table[@class="hid"]'
tree = html.parse(url)
table = tree.xpath(xpath)[0]
raw_html = html.tostring(table)Pandasを使えば、この生データのHTML文字列を簡単にデータフレームへ変換できます。ここでは、 Rank 列をインデックスとして、1行目をヘッダとして使うようにPandasを設定します。 read_html 関数はリストを返しますが、今回は1つのデータフレームオブジェクトのリストとなりますので、この結果を得たら最初の数行を表示します。
df = pd.read_html(raw_html, header=0, index_col=0)[0]
df.head()| 国 | 平均収入に対するソフトウェアエンジニアの年収の中央値の比率 | ソフトウェアエンジニアの年収の中央値 | 国内の年収の平均値 | |
|---|---|---|---|---|
| 順位 | ||||
| 1 | Pakistan t | 5.56 | $7,200 | $1,296 |
| 2 | India t | 3.91 | $6,200 | $1,584 |
| 3 | South Africa t | 3.64 | $24,000 | $6,595 |
| 4 | Bulgaria t | 3.28 | $25,200 | $7,682 |
| 5 | China t | 3.15 | $23,100 | $7,333 |
さらに、Pandasにより自動的に決定されたデータタイプを表示します。
df.dtypesCountry object
Ratio of median software engineer pay to average income float64
Median annual pay for software engineers object
Average annual income object
dtype: objectさらなる調査に進む前に、出力結果を見ると、クリーニングの必要なものがいくつかあると分かりますね。 Country 列の値は全てスペースの後にtが続いて終わるという形になっていますから、単純にこれを削除します。また、ドルで表されている金額についても、ここの数値は計算やプロットに使用するため、数値型に変換する必要があります。
df['Country'] = df['Country'].apply(lambda x: x.rstrip('t').strip())
for col in df.columns[2:]:
df[col] = pd.to_numeric(df[col].apply(lambda x: x.lstrip('$').replace(',', '')))
df.dtypesCountry object
Ratio of median software engineer pay to average income float64
Median annual pay for software engineers int64
Average annual income int64
dtype: objectこれで良くなったようです。サニティチェックとして、データに含まれている上記の比率がそれぞれの年収の数値に基づくものとして合っているか、確認するといいでしょう。つまり、自分たちの手で比率を計算し、既存の数値と同じになるかチェックするのです。
ratio = round(df['Median annual pay for software engineers'] / df['Average annual income'], 2)
all(ratio == df['Ratio of median software engineer pay to average income'])True調査と可視化
年収の比較
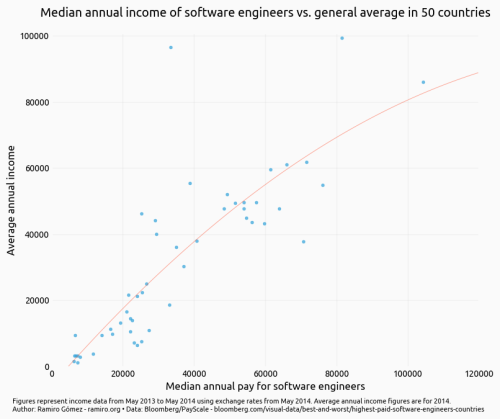
全体像を見るため、まずは散布図を作成します。これは世界50カ国全てのレコードがプロットされるもので、X軸はソフトウェアエンジニアの年収の中央値を、Y軸は国内の年収の平均値を示します。さらに、傾向の有無を確かめるため、二次多項式で求めた近似曲線を描きます。
x = 'Median annual pay for software engineers'
y = 'Average annual income'
title = 'Median annual income of software engineers vs. general average in 50 countries'
fig = plt.figure(figsize=(11, 9))
ax = fig.add_subplot(111)
ax.plot(x, y, '.', data=df, ms=10, alpha=.7)
ax.set_title(title, fontsize=20, y=1.04)
ax.set_xlabel(x)
ax.set_ylim(bottom=0, top=101000)
ax.set_ylabel(y)
# Polynomial curve fitting
# http://docs.scipy.org/doc/numpy/reference/routines.polynomials.classes.html
polynomial = np.polynomial.Polynomial.fit(df[x], df[y], 2)
xp = np.linspace(0, 120000, 100)
yp = polynomial(xp)
ax.plot(xp, yp, '-', lw=1, alpha=.5)
fig.text(0, -.04 , chartinfo, fontsize=11)
plt.show() 注釈
注釈
タイトル:世界50カ国における、ソフトウェアエンジニアの年収の中央値と国内の年収の平均値の比較
X軸:ソフトウェアエンジニアの年収の中央値
Y軸:国内の年収の平均値
注記:2013年5月~2014年5月の収入データを、2014年5月の為替レートで換算した数値を使用。平均年収は2014年の数値。
上の図と以下で作成する図を読み取っていく前に、このデータの問題点をいくつか挙げておきましょう。まず、PayScaleの調査に回答した人数が不明で、回答者の実務経験年数は2~5年の範囲に分散しています。このサンプルが各国のソフトウェアエンジニアの収入をきちんと代表しているかは不確かなのです。
その上、ここで比較しているのは、ソフトウェアエンジニアの年収の中央値と、国内の年収の平均値です。 上位の稼ぎ手の収入が全体の高い割合を占めている 国がいくつもあることを考えると、国内の年収の中央値と比べた場合は、図の形は違ったものになりそうです。
そのことを念頭に置いた上での話ですが、ソフトウェアエンジニアは、50カ国の大多数では、職業の中で望ましい選択肢となっているようです。図の左下を見ると、ミドルレベルのソフトウェアエンジニアが平均的な人の何倍も稼いでいる国がありますね。ただし、ソフトウェアエンジニアの方がずっと収入の少ない国もあります。ソフトウェアエンジニアの収入に関する上位と下位の国を突き止めるために、次はランキングを棒グラフで表してみましょう。
国別ランキング
以下の棒グラフでは、平均収入に対するソフトウェアエンジニアの収入の中央値の比率によって、各国を並べます。データフレームは既にその比率で上位から下位へと並んでいますので、単純にheadメソッドとtailメソッドを使えば、表示したい部分のレコードを得ることができます。
col = 'Ratio of median software engineer pay to average income'
title = 'Best and worst countries ranked by ratio of median software engineer pay to average income'
limit = 10
best = df.head(limit)[::-1]
worst = df.tail(limit)
ticks = np.arange(limit)では、2種類の棒グラフを含む図を作成しましょう。ソフトウェアエンジニアの収入比率が高い国を左側のグラフに、低い国を右側のグラフに示します。
fig = plt.figure(figsize=(14, 5))
fig.suptitle(title, fontsize=20)
ax1 = fig.add_subplot(1, 2, 1)
ax1.barh(ticks, best[col], alpha=.5, color='#00ff00')
ax1.set_yticks(ticks)
ax1.set_yticklabels(best['Country'].values, fontsize=15, va='bottom')
ax2 = fig.add_subplot(1, 2, 2)
ax2.barh(ticks, worst[col], alpha=.5, color='#ff0000')
ax2.set_yticks(ticks)
ax2.set_yticklabels(worst['Country'].values, fontsize=15, va='bottom')
fig.text(0, -.07, chartinfo, fontsize=12)
plt.show()
注釈
タイトル:平均収入に対するソフトウェアエンジニアの収入の中央値の比率で見た、上位国と下位国
注記:2013年5月~2014年5月の収入データを、2014年5月の為替レートで換算した数値を使用。平均年収は2014年の数値。
上の図を見ても、収入格差が非常に大きな国があり、ソフトウェアエンジニアが平均より多く稼ぎそうだということが分かります。このデータセットでは、平均年収が最も低い国はパキスタンとインドで、平均年収が最も高い国はノルウェー、カタールの順です。推測するに、比率が高い国での収入分布は低収入に、比率の低い国での収入分布は高収入に偏っているのだと思います。やはり、中央値と平均値ではなく、中央値と中央値を比べた方が面白いのですが、そのような比較をするには別のデータソースを見つけるしかありません。
国コードの追加
この最後の短いセクションでは、 インタラクティブなD3.jsベースのマップ でデータを可視化するために、今回のデータセットに ISO 3166-1 Alpha-3 の国コードを追加する方法をご紹介します。
df_map = df.copy()
names = gc.get_countries_by_names()
df_map['iso3'] = df_map['Country'].apply(lambda x: names[x]['iso3'])
df.head(5)| 国 | 平均収入に対するソフトウェアエンジニアの収入の中央値の比率 | ソフトウェアエンジニアの年収の中央値 | 国内の年収の平均値 | |
|---|---|---|---|---|
| 順位 | ||||
| 1 | Pakistan | 5.56 | 7200 | 1296 |
| 2 | India | 3.91 | 6200 | 1584 |
| 3 | South Africa | 3.64 | 24000 | 6595 |
| 4 | Bulgaria | 3.28 | 25200 | 7682 |
| 5 | China | 3.15 | 23100 | 7333 |
ここで、冒頭で初期設定したgeonamescacheオブジェクトを使って、名前をキーとする国の辞書を得ます。この値も辞書となっており、何よりISO 3166-1 Alpha-3の国コードを含んでいます。最後に、数バイトを節約するため国の列を削除して、データフレームをCSVファイルで保存します。
del df_map['Country']
df_map.to_csv(data_dir + '/economy/income-software-engineers-countries.csv', encoding='utf-8', index=False)まとめ
この記事では、50カ国におけるソフトウェアエンジニアの収入データを調べ、平均的な人の収入と比較しました。その過程では、ソースのWebページからデータセットを入手し、データのクリーニングを行い、可視化して結果を解釈すると共に、今回のデータセットと処理方法に潜む問題点を挙げました。
ソフトウェアエンジニアは、大多数の国では望ましい職業の1つとなっているようですが、移住計画を立てる前に上記の問題点をよく考慮するようにしましょう。また、職業や居住地を選ぶ際はきっと、収入が唯一の選択基準ではないはずです。
signatureAuthor: Ramiro Gómez • Last edited: April 08, 2016
Linux 4.2.0-35-generic – CPython 3.5.1 – IPython 4.1.2 – matplotlib 1.5.1 – numpy 1.10.4 – pandas 0.18.0

株式会社リクルート プロダクト統括本部 プロダクト開発統括室 グループマネジャー 株式会社ニジボックス デベロップメント室 室長 Node.js 日本ユーザーグループ代表
- X: @yosuke_furukawa
- Github: yosuke-furukawa
関連記事