2019年3月14日
データサイエンティストにおいて、最も需要のあるスキルとは
(2018-10-12)by Jeff Hale
本記事は、原著者の許諾のもとに翻訳・掲載してお��ります。
雇用者は何を求めているのか?
データサイエンティストは、多くのことを知っていると期待されます。例えば機械学習、コンピュータ科学、統計、数学、データの可視化、コミュニケーション、そしてディープラーニングといったものです。これらの分野の中には、データサイエンティストが学んでいる可能性のある何十もの言語やフレームワーク、テクノロジが含まれています。雇用者側から求められたいデータサイエンティストは、限られた学びの時間をどのように割り当てるべきでしょうか。
私はデータサイエンティストにどのようなスキルが求められているのかを探るため、Web上の求人情報サイトを見て回りました。一般的なデータサイエンスのスキルと、特殊な言語やツールは分けて考えています。検索した日は2018年10月10日、サイトは LinkedIn と Indeed 、 SimplyHired 、 Monster 、それに[AngelList](https://angel.co/jobs)です。以下は、各Webサイトにデータサイエンティストの求人がどれだけ掲載されていたかを示す図です。
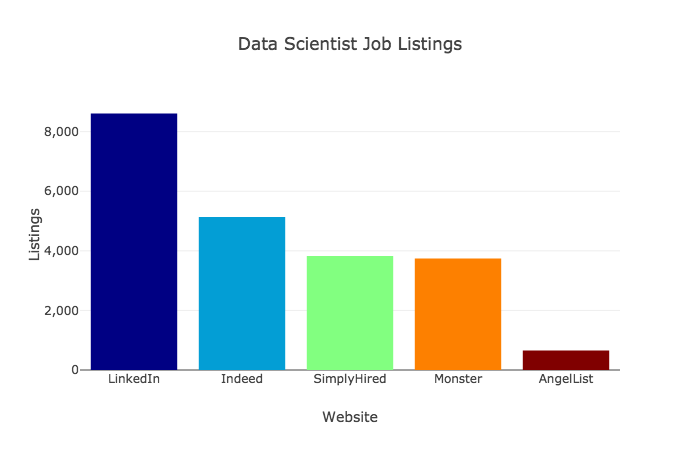
注釈:
データサイエンティストの求人情報
(縦軸)掲載件数
(横軸)Webサイト
私は多くの求人情報や調査を読み、そこに頻繁に現れるスキルにはどのようなものがあるのかを探りました。 マネジメント のような単語は比較の対象にしていません。求人情報においてそのような語は、様々な文脈で使われるからです。
全ての検索はアメリカ合衆国において、 “データサイエンティスト” 、 “[キーワード]” で行いました。完全一致検索を使うことで結果を絞り込みました。しかしながら、この方法によって、結果がデータサイエンティストのポジションに関連があり、全ての検索語句に同様に影響したことを確実にしました。
AngelListは求人のあるデータサイエンティストのポジションの数ではなく、広告を出している会社の数を公表しています。私はAngelListをどちらの分析からも外しました。AngelListの検索のアルゴリズムは 「OR検索」 で実行されており、 「AND検索」 に変える機能はないようだからです。 「データサイエンティスト」 と、データサイエンティストのポジションでしか見られない 「TensorFlow」 で検索するなら、AngelListでも問題ありません。しかし、キーワードが 「データサイエンティスト」 、 「react.js」 だと、データサイエンティストではない求人広告を掲載した、非常に多くの会社がヒットしてしまいます。
GlassDoor も、私の分析から外しました。このサイトは、米国内で26,263件の 「データサイエンティスト」 の求人を掲載していると述べていますが、私が見ることができたのはせいぜい900件でした。それに、他のメジャーなプラットフォームの3倍以上にあたる数のデータサイエンティストの求人情報を掲載しているとは考えにくいからです。
LinkedInに掲載された400件以上の一般技能の求人情報と200件以上の特殊技能の求人情報に見られた用語は、最終的な分析に含めました。もちろん、重複しているものもあります。結果はこちらの Googleシート に記録しました。
私は.csvファイルをダウンロードし、それらをJupyterLabにインポートしました。そして出現率を計算し、求人情報Webサイト全体での平均を出しました。
また、ソフトウェアについての結果を、Glassdoorが自身のサイトで2017年前半のデータサイエンティストの求人情報に関して行った 調査 とも比較をしました。
KDNuggetsが行った、使用に関する調査 の情報を合わせると、スキルの中でもより重要なものと、比較的重要度の低いものがあることが明らかになりました。それについては後ほど触れましょう。
私はKaggleのKernelでインタラクティブチャートと追加の分析を行いました。可視化のために、Plotlyを使用しました。PlotlyをJupyterLabと一緒に使うことについては、この記事を書いている時点では少々の論争がありそうです。使用説明は、私のKaggleのKernelの最後と、 Plotlyのドキュメント の中にあります。
一般的なスキル
以下に示すチャートは、雇用者がしばしばデータサイエンティストに求める一般的なスキルをまとめたものです。
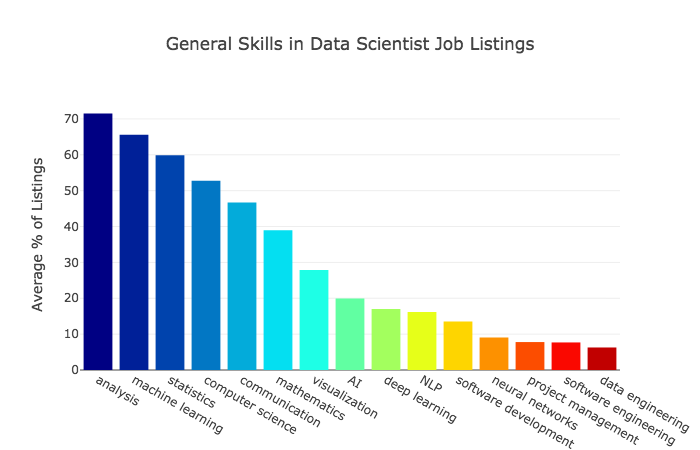
注釈:
データサイエンティストの求人情報に書かれている、一般的なスキル
(縦軸)求人情報の平均(パーセント)
(横軸、左から)分析
機械学習
統計
コンピュータサイエンス
コミュニケーション
数学
可視化
AI
ディープラーニング
NLP
ソフトウェア開発
ニューラルネットワーク
プロジェクト管理
ソフトウェア工学
データ工学
この結果を見ると、分析と機械学習が、データサイエンティスト職の核となるスキルだと分かります。データから見識を拾い集めることは、データサイエンスの最も重要な役割です。機械学習はパフォーマンスを予想するためのシステム構築に関するものですし、非常に需要があります。
データサイエンスには統計やコンピュータ科学のスキルが要求されます。それは驚くことではありません。統計、コンピュータ科学、それに数学は大学での専攻科目でもあり、そのことが出現頻度の高さに寄与しているのかもしれません。
半数近くの求人情報でコミュニケーションに触れられているのは、興味深いですね。データサイエンティストは洞察を伝える能力や、他者と一緒に働く力を持っている必要があります。
AIとディープラーニングは、いくつかの他の単語と比べるとそれほど頻繁には登場しません。しかし、これらは機械学習の一分野です。ディープラーニングは、以前は別のアルゴリズムが使われていた機械学習のタスクにおいて、ますます使われるようになっています。例えば、多くの自然言語処理の問題のための最良の機械学習アルゴリズムは、今ではディープラーニングのアルゴリズムなのです。私は、将来的にはディープラーニングのスキルがより明確に求められるようになり、機械学習とディープラーニングが同義語に近づくことを望んでいます。
では具体的には、雇用者が求めているのは、どのようなデータサイエンティスト向けのソフトウェアなのでしょうか? 次はその問題を考えてみましょう。
技術的なスキル
下記の表は、雇用者がデータサイエンティストに使用経験を期待する特定の言語、ライブラリ、技術的なツールの上位20位です。

注釈:
データサイエンティストの求人広告に見られる、技術的なスキルのトップ20
(縦軸)求人情報の割合(パーセント)
上位の技術的スキルを、簡単に見てみましょう。

Python は、最も需要のある言語です。オープンソースの言語で、幅広く人気があります。初心者にも使いやすく、多くのサポートツールがあります。新しいデータサイエンスのツールの大半は、この言語と互換性があります。Pythonはデータサイエンティストにとって最も重要な言語です。

RはPythonに大きく遅れをとっているわけではありません。かつてはデータサイエンティストの最重要言語でした。今でも多くの需要があると分かり、驚きました。このオープンソースの言語は統計にルーツを持つので、今でも統計学者の間では非常に人気があります。
PythonやRは、データサイエンティストの職に就く全ての人に必須のものだと言っても過言ではないでしょう。

SQL も高い需要があります。SQLとはStructured Query Language(構造化照会言語)の頭文字を取ったもので、リレーショナルデータベースと情報を交換する第一の手段です。SQLはデータサイエンスの世界では時々見落とされてしまいますが、自分を売り出すつもりなら、マスターしておく価値のあるスキルです。


次は Hadoop と Spark です。どちらも、Apacheがビッグデータのために出している、オープンソースのツールです。
Apache Hadoopは、汎用ハードウェアで構築された、コンピュータのクラスタ上で非常に大きなデータセットを分散ストレージおよび分散処理するためのオープンソース・ソフトウェア・プラットフォームです。 参照元はこちら 。
Apache Sparkは高速のインメモリデータ処理エンジンです。データを扱う人にとっては、データセットへの高速の相互アクセスを要求されるストリーミングや機械学習、あるいはSQLのワークロードを効率的に実行することができるように開発された、簡潔で表現力に富むAPIが備えられています。 参照元はこちら 。
これらのツールは他の多くのものと比べて、Mediumやチュートリアルで触れられることが少ないようです。PythonやR、SQLと比べると、これらのスキルを持っている求職者はずっと少ないように思います。もしもHadoopやSparkを使った経験がある、あるいはその機会を作れるなら、競争で一歩上を行くための足掛かりになるはずです。


次に来るのは Java と SAS です。この2つの言語がこれほど上位にくることに驚きました。どちらも後ろ盾に大きな会社がついていて少なくともいくらかは無料の提供物があります。JavaもSASも、データサイエンスのコミュニティ内ではほとんど注目を集めることはありません。
次に需要が高いのは Tableau です。この解析学のプラットフォーム兼可視化ツールはパワフルで使いやすく、人気は上がっています。無料のパブリック版もありますが、データを個人的に保存したいなら料金がかかります。
Tableauについて詳しくない方は、Udemyの Tableau 10 A-A のような短期クラスをとることをおすすめします。別にコミッションをもらっているわけではありませんが、私自身がクラスをとってみて、とても有用だと思いました。
以下に、需要の高い言語、フレームワーク、その他データサイエンスのソフトウェアツールをさらに下位まで示したリストを載せておきます。
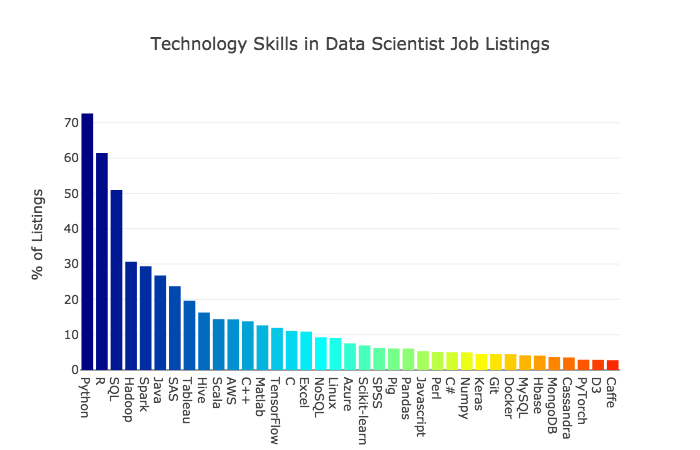
注釈:
データサイエンティストの求人情報に見られた、技術的なスキル
(縦軸)求人情報の割合(パーセント)
歴史的な比較
GlassDoorは自身のサイトで2017年1月から2017年7月までの間、データサイエンティストには一般的なソフトウェアのスキルの上位10個を 分析 しました。下の図は、2018年10月におけるLinkedIn、Indeed、SimplyHired、Monsterの平均と比較して、GlassDoorでその単語がどのくらい出現したかを示したものです。
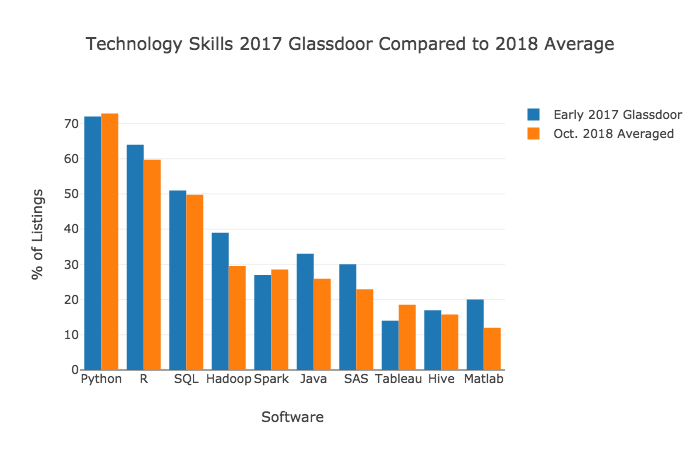
注釈:
2018年の平均と、2017年のGlassDoorにおける技術的なスキルの比較
(縦軸)求人情報の割合(パーセント)
(横軸)ソフトウェア
(青)2017年前半のGlassDoor
(オレンジ)2018年10月の平均
結果は、かなり似通っています。私の分析でもGlassDoorの分析でも、Python、R、SQLが需要の高い上位3つでした。さらに、上位9つのスキルが、順番はやや違うにしても同じだということも分かりました。
この結果から、2017年前半と比べると、R、Hadoop、Java、MatLabの需要が減っており、Tableauは増えているということが見てとれます。これは、 KDnuggets開発者の調査 などの補足的な結果から、私が予想していたことです。そこではR、Hadoop、Java、SASはすべて、複数年にわたって使用の減少傾向が見られ、Tableauでははっきりとした上昇傾向が見られました。
おすすめ
これらの分析結果に基づいて、市場での競争力を高めたい現役、あるいは将来のデータサイエンティストにおすすめできるものを挙げておきます。
-
データの分析ができることを明言し、機械学習をしっかりマスターすることに集中しましょう。
-
コミュニケーション技能に投資しましょう。あなたのアイデアをもっとインパクトのあるものにするために、『 Made to Stick 』を読むことをおすすめします。さらに、あなたの文章をより明晰なものにするために、 Hemmingway Editor というアプリもチェックしましょう。
-
ディープラーニングのフレームワークをマスターしましょう。ディープラーニングのフレームワークに熟練することは、機械学習の熟練にますます大きな部分を占めています。ディープラーニングのフレームワークの使用、興味、人気を比べるには、私が書いた こちら の記事をご覧ください。
-
PythonとRのどちらを学ぶか迷っているなら、Pythonを選びましょう。Pythonを完全にマスターしているなら、Rを学ぶことも考えましょう。Pythonに加えてRにも精通していれば、あなたの需要はより高まります。
雇用者がPythonのスキルを持ったデータサイエンティストを探している時、志願者たちがnumpyやpandas、scikit-learn、matplotlibといったデータサイエンス向けの一般的なPythonのライブラリに関する知識を持っていると期待している可能性が高いです。これらのツールを学ぶことを考えているなら、以下のリソースをお勧めします。
- DataCamp と DataQuest 。この2つはリーズナブルな価格のオンラインSaaSデータサイエンス教育ツールで、コードを書いて学ぶことができます。どちらも、教わることのできる技術的ツールは複数あります。
- DataSchool は、データサイエンスの概念を説明してくれる一連の YouTubeの動画 など、様々なリソースがあります。
- McKinneyの『 Python for Data Analysis 』。pandasライブラリの初期の作成者によって書かれたこの本は、pandasに焦点を当て、さらにデータサイエンスのための基本的なPythonやnumpy、scikit-learnの機能性についても議論しています。
- MüllerとGuidoによる『 Introduction to Machine Learning with Python 』。Müllerはscikit-learnの初期の管理者です。scikit-learnを使った機械学習について学ぶのにはいい本です。
もしも積極的にディープラーニングを学ぶことを考えているのなら、 TensorFlow や PyTorch の前に Keras か FastAI から始めることをお勧めします。Cholletによる『 Deep Learning with Python 』はKerasを学ぶのにすばらしいリソースです。
これらのおすすめ以外に、あなたが興味を持っていることを学びましょう。学習時間をどのように割り当てるか、非常に悩ましいのは明らかですが。

オンラインのポータルでデータサイエンティストの職を探しているなら、LinkedInを始めてみるといいでしょう。コンスタントに一番多くの結果が出てきました。
もしもオンサイトでの仕事あるいはポストを探しているなら、キーワードが重要です。 “データサイエンス” で検索すると、どのサイトでも “データサイエンティスト” にした時のおよそ3倍の結果が出てきました。しかし、厳密にデータサイエンティストの仕事だけを求めているなら、 “データサイエンティスト” で検索した方がいいでしょう。
あなたが何を目指しているとしても、オンラインのポートフォリオを作ることをおすすめします。需要の高いスキルをなるべくたくさん書いて、あなたの強みを明示しましょう。LinkedInのプロフィールであなたのスキルを示すこともおすすめします。
このプロジェクトの一環で、私は記事にできそうなデータを他にも集めました。今後の動向にも、ぜひ注目してください。
もしも相互的に示したチャートやそのコードを見たいのなら、私の Kaggle Kernel をチェックしてください。
この記事が、データサイエンティストを雇用する組織が何を求めているのかを知るヒントになってくれたことを願います。何かためになったことがあれば、拍手をして、他の人の目にも留まるようにTwitterでシェアしてくれたらうれしいです。

株式会社リクルート プロダクト統括本部 プロダクト開発統括室 グループマネジャー 株式会社ニジボックス デベロップメント室 室長 Node.js 日本ユーザーグループ代表
- X: @yosuke_furukawa
- Github: yosuke-furukawa
関連記事