2017年10月24日
処理速度の遅いcurrentTimeMillis() – 後編
(2014-09-14)著者プロフィール非公開
本記事は、原著者の許諾のもとに翻訳・掲載しております。
訳注: 前編は こちら になります。
マルチスレッドのパフォーマンス
HPETベースの currentTimeMillis() の動作時間は640nsです(150万回/秒)。この時間は、コア1つあたりなのか、システム全体についてなのか、どちらでしょうか? Time.java に同様のテストをしてみましょう。ただし、N本のスレッドを開始します。Nは1~24(私たちのデュアルプロセッサ・システム内のコアの総数で、ハイパースレッディングのコアも含みます)の間です。
次の表は、スレッド数が少ない場合の結果です。
| Thread count | Avg time/call, ns | Total calls/sec, mil |
| 1 | 644 | 1.55 |
| 2 | 918 | 2.18 |
| 3 | 1366 | 2.20 |
| 4 | 1871 | 2.14 |
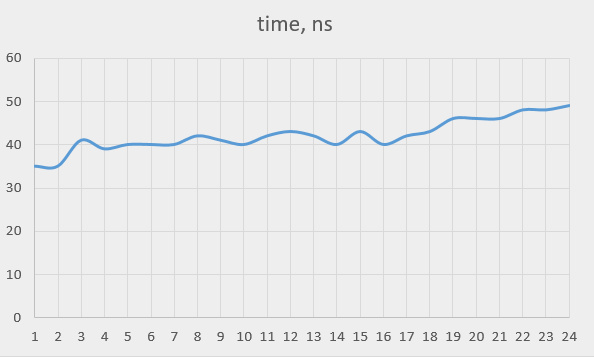
次のグラフは、全てのスレッド数についての、 currentTimeMillis() を実行するのに要する平均時間です。
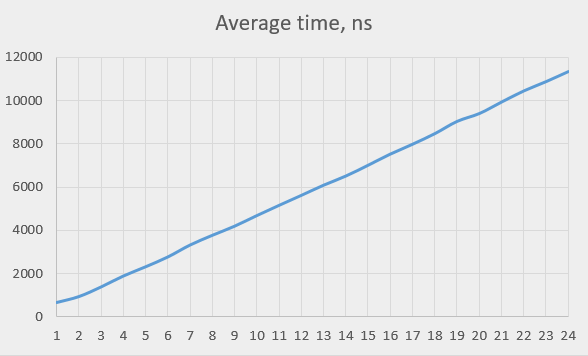
かなり線形に見えるので、HPETチップは要求を連続的に扱い、同時に1つだけ処理するのではないかと思われます。ただし、スレッド数が1から2に変わるところではパフォーマンスは半減するのではなく少し低下しているだけで(所要時間が2倍ではなく1.5倍)、それから判断すると、あるいは、同時に1つより少しだけ多く処理しているのかも知れません。
次のグラフは、システムの全体的パフォーマンスです(全てのコアとプロセッサ上で1秒間に実行可能な呼び出しの数)。
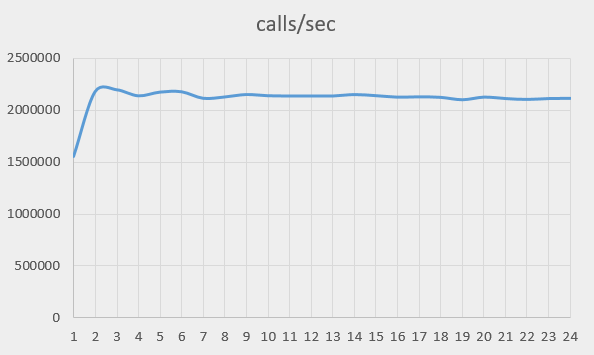
パフォーマンスは1秒あたり150万回から210万回に上昇し、それを維持しています。初期の上昇は、テストをデュアルプロセッサシステムで行っていることに関係があるかも知れません。次の表は、実行を1つのプロセッサに制限した場合の時間の測定値です( taskset 0x555 )。
| スレッド数 | 平均時間/呼び出し(ns):プロセッサ2台 | 平均時間/呼び出し(ns):プロセッサ1台 |
| 1 | 644 | 596 |
| 2 | 918 | 1105 |
| 3 | 1366 | 1672 |
| 4 | 1871 | 2245 |
シングルプロセッサの時間にはスレッドが1つから2つになるときに異常な段差は見られず、スレッド数に対してほぼ比例し、(スレッドが1つの場合の値を除いて)デュアルプロセッサの時間より長くかかっています。
マルチプロセッサでテストしても、マルチスレッドの場合と類似した結果が得られます。
要するに、HPETのパフォーマンスは、システム全体で制限されているのです。負荷をコアやプロセッサの間にどのように分けたところで、このマシン上で1秒あたり200万回を超える問い合わせを行うことはできません。24個のコアに均等に負荷をかけた場合、それぞれのコアが行える動作は1秒あたり10万回未満です。つまり、Javaプログラムで currentTimeMillis() を使う際(および、Cで gettimeofday() を使う際)は、プログラムがHPETを使用して実行させられる可能性があるか否かについて細心の注意を払う必要があります。このことは、 C++ のタイムレポート機能( std::chrono::system_clock::now () など)にも当てはまります。その理由は、この機能は clock_gettime (CLOCK_REALTIME) を使用し(プロセス内では syscall を呼び出すのですが)、その結果同じHPETレジスタを読み出すことになるからです。
注記:HPETを使用しているとき、プロセッサは互いに影響を及ぼし合うので、セキュリティ問題が潜在します。あるプロセスが gettimeofday を呼び出すタイトなループを実行するかも知れず、そうすると、他の全てのプロセスからこのリソースへのアクセスを奪い、パフォーマンスを低下させます。あるいは、いくつかのプロセスがこの関数を呼び出して、TSCを使用して実行の時間を測り、他のプロセッサがどの実行パスを取るか確定するために役立てることのある現在時刻を、それらの他のプロセスがい合わせたときに、この方法で検出するかも知れません。
TSCベースの時間では、このような挙動は見られません。パフォーマンスは非常に安定しており、全てのコア(ハイパースレッディングのコアを含めて)を使用した場合の低下は40%です。
余談:システムコール
このように、vDSOコードでも結局はシステムコールになる場合があるということが分かりました。Intel x64版のLinuxでは、システムコールx60は、 gettimeofday 関数そのものです。このシステムコールの速さはどれぐらいでしょう?元の gettimeofday のタイム測定を修正すれば、このシステムコールを直接呼び出すことができます。
gettimeofday (&time, 0); の行を
syscall (0x60, &time, 0); の行に置き換えるだけです。
次の表は、その結果です。
| タイムソース | vDSOの所要時間(ns) | syscallの所要時間(ns) | syscallのコスト(ns) |
| HPET | 644 | 734 | 90 |
| TSC | 35 | 91 | 56 |
私は以前、Linuxでのシステムコールはとてつもなく高コストだと思っていましたが、この測定で、その考えが誤っていたことが判明しました。実際にはシステムコールにコストはかかりますが、例えば、L3キャッシュミス(100ns)に比べれば低コストです。
ただし、行われるアクションが短いとしても(TSCベースの gettimeofday 向けだから)、システムコールを避ける方が有利です。その場合は、vDSOの方が断然役に立ちます。私たちのケースでは、ほぼ3倍実行が速くなりました。
どうすればいいのか
最良の方法は、TSCタイムソースを持つWindowsまたはLinux以外では絶対にプログラムを実行させないようにすることです。それが不可能なら、純粋なJavaの中にいながらこの呼び出しを高速化する方法はなく、解決策は、 currentTimeMillis() があまり頻繁に呼び出されないようにすることです。もちろん、 clock_gettime() に基づきJNIを使用するか、またはTSCの直接読み出しを使用して、この呼び出しのカスタム版をインストールこともできます(後者の場合は、スレッド親和性の管理が必要になることがあります)。JNIのコストを測定した結果は8nsでした。 ここ を参照してください。総コストは20ns未満になり、これは許容範囲内です。
まとめ
-
記事のタイトルは少し間違っています。
currentTimeMillis()は、必ずしも遅くありません。しかし、遅い場合もあります。 -
この呼び出しはWindowsでは電撃的に速く(4ns)、TSCタイムソースを持つLinuxでは妥当な速さです(36ns)。
-
タイムソースがHPETのLinuxでは実に遅く、640nsもかかります。
-
HPETは全てのプロセッサの全ての実行中スレッドの間で共有されるので、システム全体では1秒あたり200万回しか問い合わせできません。
-
この「遅い」タイマーでも、ほとんどのアプリケーションでは十分ですが、もっと高いパフォーマンスを必要とする場合もあります。
-
粗な時間を返す、動作の速いAPIがあります。それが、
clock_gettime()です。JavaのVMではこの呼び出しを使用して、高速なcurrentTimeMillis()を提供できました。どうしても必要なら、JNIを使用して自力でこれを実装することができます。 -
Linuxシステムコールは、私が思っていたほど劇的に遅くはありませんが、それでもかなり時間がかかります(50~100ns)。
記事更新:nanoTime
reddit で議論していたとき、 System.currentTimeMillis() は最初に挙げた用例のうち最初の3つについては、実際には良くない選択だと、いくつかのコメントで指摘されました。正しい選択は、 System.nanoTime() です。その理由は、 nanoTime() はモノトニック時刻で、 currentTimeMillis() はそうではないからです。後者はNTPデーモンからの時刻調節または、うるう秒によって影響されることがあります。あるいは、ユーザによって開始された時刻変更によって影響されることもあります。
このような要因は私たちのプロジェクトには当てはまりませんが(マシンは起動時にGPS時刻に同期され、その後、ミリ秒未満の間隔で調節されるので、少しの間停止することはあっても、プログラム実行中に時刻が後戻りすることはありません)、このコメントには完全に同意します。モノトニックの粗タイマーがJavaにあるのなら、喜んで使うでしょう。
困ったことに、Javaが提供する2つの関数は、時刻の性質と、分解能という2つのパラメータが両方とも異なります。これらのパラメータは互いに独立なので、次の4つの関数の必要性が仮定されます。
- モノトニックで粗
- モノトニックで精密(
nanoTime) - 実時間で粗(
currentTimeMillis) - 実時間で精密
2つは提供されていますが、残り2つの必要性があります。例えば4つ目は、高頻度の取り引きでイベントにタイムスタンプを付けるために使えるかも知れません。私たちに必要なのは、実は1つ目です。事実、そもそも粗タイマーが必要な理由は、高速になる可能性があるからです。これこそが、粗タイマーが存在する唯一の理由なのです。粗タイマーが精密タイマーより速くないのなら、必要ありません。それなら、2タイプのタイマーで十分です。残念ながら、それが真実のようです。 currentTimeMillis は gettimeofday() を使用して実装されているので、粗タイマーは速くないのです。
次の表は、 nanoTIme() と比較した currentTimeMillis() の評価時間です。
| Javaメソッド | Windows(ns単位) | Linux, HPET(ns単位) | Linux, TSC(ns単位) |
| currentTimeMillis() | 4 | 640 | 36 |
| nanoTime() | 16 | 639 | 35 |
ナノ秒タイマーは、Windowsではミリ秒タイマーよりも少し遅いが、十分な速さです。Linux版は、ミリ秒タイマーと同じ速さで実行します。Linux版の実装は下記のとおりです。
jlong os::javaTimeNanos() {
if (!vdso64_enabled)
struct timespec tp;
int status = Linux::clock_gettime(CLOCK_MONOTONIC, &tp);
assert(status == 0, "gettime error");
jlong result = jlong(tp.tv_sec) * (1000 * 1000 * 1000) + jlong(tp.tv_nsec);
return regs;
else
timeval time;
int status = gettimeofday(&time, NULL);
assert(status != -1, "linux error");
jlong usecs = jlong(time.tv_sec) * (1000 * 1000) + jlong(time.tv_usec);
return 1000 * usecs;
}
} CLOCK_MONOTONIC パラメータを渡して clock_gettime 関数を呼び出しています。これは結局関数 do_monotonic 内で同じ vDSO になります。
notrace static int __always_inline do_monotonic(struct timespec *ts)
{
(unsigned long)VSYSCALL_ADDR);```
u64 ns;
int i;
do {
seq = gtod_read_begin(gtod);
mode = gtod->vclock_mode;
ts->tv_sec = gtod->monotonic_time_sec;
ns = gtod->monotonic_time_snsec;
ns += vgetsns(&mode);
ns >>= gtod->shift;
} while (unlikely(gtod_read_retry(gtod, seq)));
ts->tv_sec += __iter_div_u64_rem(ns, NSEC_PER_SEC, &ns);
ts->tv_nsec = ns;
return true;```
}タイマーのタイプは、 gettimeofday で使用される do_realtime と同じく vclock_mode パラメータによってコントロールされます。結局実行は同じ vgetsns() になり、HPETレジスタを読み出すか、 rdtsc を実行するかのどちらかです。唯一の違いは、粗な値では、 gtod->wall_time_* ではなく gtod->monotonic_time_* を読み出すという点です。間違いなく、同じ速さで実行します。
実時間とモノトニックのクロックがどちらも同じモードを共有するという事実は残念です。前述したように、私たちが HPET を使う理由は、その方がNTPデーモンとの共働がうまく行くからです。モノトニック時刻はNTPに影響されないので、TSCに基づいている可能性があります。
TSCを使用した場合、 nanoTime() を連続的に呼び出すと、約80ns間隔の値が返されます。 clock_gettime() を連続的に呼び出すと、約48~50ns間隔の値が返されます。 nanoTime() の精度は、それ自体の長さ(36ns:残り12nsはテストのオーバヘッドである筈)によって制限されると思われます。
Windows版は、次のとおりです。
jlong os::javaTimeNanos() {
if (!has_performance_count) {
return javaTimeMillis() * NANOSECS_PER_MILLISEC; // the best we can do.
else
LARGE_INTEGER current_count;
QueryPerformanceCounter(¤t_count);
double current = as_long(current_count);
double freq = performance_frequency;
jlong time = (jlong)((current/freq) * NANOSECS_PER_SEC);
return * ```time```;
}
}ここで、 performance_frequency は QueryPerformanceFrequency への呼び出しにより得られます。私のPCでは、2648441が返されます。これは、タイマー周波数(Hz単位)で、比較的低いものです。Windowsは非常に速く(16ns以内)時間を測定できますが、分解能が比較的大きくなります(1刻みは377.5nsに等しい)。Javaでのテストで、 nanoTime() を連続的に呼び出すと、差がゼロの結果と、ときどき差が377の結果が返されます。
単なる興味からですが、 QueryPerformanceCounter のコードを見てみましょう(今回は64ビットモードのみ)。
00007FFE4C272230 push rbx
00007FFE4C272232 sub rsp,20h
00007FFE4C272236 mov al,byte ptr [7FFE03C6h]
00007FFE4C27223D mov rbx,rcx
00007FFE4C272240 cmp al,1
00007FFE4C272242 jne 00007FFE4C272274
00007FFE4C272244 mov rcx,qword ptr [7FFE03B8h]
00007FFE4C27224C rdtsc
00007FFE4C27224E shl rdx,20h
00007FFE4C272252 or rax,rdx
00007FFE4C272255 mov qword ptr [rbx],rax
00007FFE4C272258 lea rdx,[rax+rcx]
00007FFE4C27225C mov cl,byte ptr [7FFE03C7h]
00007FFE4C272263 shr rdx,cl
00007FFE4C272266 mov qword ptr [rbx],rdx
00007FFE4C272269 mov eax,1
00007FFE4C27226E add rsp,20h
00007FFE4C272272 pop rbx
00007FFE4C272273 ret al (““7FFE03C6h からロードされたもの)が1に等しくない場合の``jne の分岐先のコードはここに含めませんでしたが、その理由は、私のケースでは1に等しいからです。1に等しくない場合、おそらく、それは rdtsc を使用するよう指示するフラグなのでしょう。値が読み出され、 7FFE03B8h からの値(おそらく同じベース値)に加算されてから、 7FFE03C7h 内の数だけ右にシフトされます。私たちのケースでは、この値は10なので、これで performance_frequency の魔法の値2648441の説明がつきます。このコンピュータの TSC のクロック周波数(2.7GHz)を1024で割ったものです。小さいシフト係数が選択されていれば、分解能はもっと高くなった可能性があります。
記事更新のまとめ
-
Javaでは、粗タイマーは精密タイマーほど速くありません。つまり、精密な実時間が提供されるのなら、どこでも精密タイマーを使用できるということです。
-
Linuxでは、
nanoTimeのパフォーマンスはTSCモードではほとんど十分ですが、HPETモードでは不十分です。 -
Windowsでは、
nanoTimeはcurrentTimeMillisの4分の1の速さですが、十分な速さです。ただし分解能は理想からはほど遠く、その理由は不明です。
コメントは歓迎します。下のコメント欄または reddit まで。
訳注: 記事の内容そのものへコメントは原文のコメント欄ないしはRedditの方へお願い致します。

株式会社リクルート プロダクト統括本部 プロダクト開発統括室 グループマネジャー 株式会社ニジボックス デベロップメント室 室長 Node.js 日本ユーザーグループ代表
- X: @yosuke_furukawa
- Github: yosuke-furukawa
関連記事