2017年10月17日
プログラミング言語について
(2017-06-28)by Artem Chistyakov
本記事は、原著者の許諾のもとに翻訳・掲載しております。
最初に学んだプログラミング言語を覚えています。2年生のとき必須であった情報クラスの授業でBASIC言語を学習していました。暗い蛍光灯の下、前かがみに机の前に座りながら、空気のこもった教室の壁際に並べられ、音を立てているIBMパソコンを我慢できずに見ていました。時は1997年のロシアです。誰の家にもコンピュータはありませんでした。先生がチョークで汚れた黒板に下記のように書きました。
SCREEN 15, 0
PSET (100, 100)
DRAW "R20 D20 L20 U20"
END他のクラスメートのきょとんとした視線同様にそこに書かれた訳の分からない「暗号文」に8歳の自分も視線を注いでいました。先生は『恐れる必要はありません』と。安心させようとやわらかい口調で言いました。この日までの数週間、彼女に授業でフローチャートを書かされていました。この時点で、既にポテトの皮むきやレゴの組み立ての「アルゴリズム」を詳細に設計することができていました。それでも黒板から睨み付けるラテン文字は異質でした。
先生は行ごとのプログラム解読に進みました。英訳を避けながら、それぞれの語彙素に意味を割り当て、暗記するよう促しました。しばらくすると上記のプログラムを見て絵文字で書かれているかのように解釈しました。
????
➡️ 100
⬇️ 100 ???? "➡️ 20 ⬇️ 20 ⬅️ 20 ⬆️ 20"
????このプログラミング教育の取り組みとこの取り組みが自然言語とのつながりを無視していることについて今でもよく考えます。英語を話す人にとっては自己記述的である単純なコード一連でも、英語を話せない人にとってはかなりのプログラミングの課題となります。我々はプログラマでした。20数名の小さいコンパイラでした。
抽象プログラミング
10年後に話しを早送りします。当時、アルゴリズムとデータ構造体を学ぶ大学生でした。C/C++でプログラムを書いていましたし、私も仲間もある程度英語が理解できていました。しかし、それでも教科書はロシア語でしたし、基本的なライブラリ関数名は意味が分からないまま覚えていきました。まず、入門クラスの講義で教授は、“Hello, World!”や他のC言語で書かれた簡単なプログラムを見せてくれました。それぞれの関数名を黒板に書きながらゆっくりと明確に発音してくれました。教授の解釈では、 getch() は「ガ・チェ」で、 clrscr() は「ケ・レ・エー・エス・ケー・エゥー」でした。今となっては信じがたいのですが、しばらく混沌としていましたが、「get character」と「clear screen」を見たときはなるほどと思いました。この発見を仲間にも話したら彼らも同じくらい驚いていました。
後から振り返って考えると、自然言語とのつながりが欠落していたことによって、役立つはずのコンテキストを知ることができなかったのです。しかし、抽象数学と類似しているのでこの方法でのプログラミング言語の学習は説得力があります。これにより、 char *strstr(const char *haystack, const char *needle) を Ω(x,y) として考えることを促してくれます。関数にややこしい名前が付いていたとしても、暗記させられた他の語彙素と何ら変わりはなかったので、我々が気づくことはありません。このようにプログラミングを覚えると、ドキュメンテーションが全てで、名前は基本的概念へのつながりでしかありません。
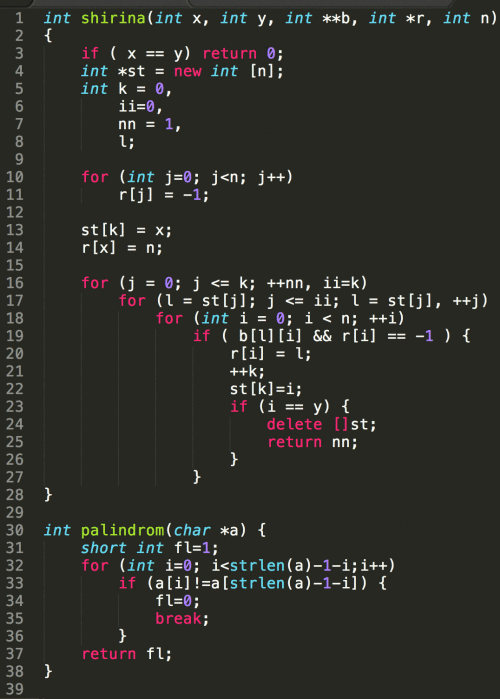
名前付けについてですが、我々のプログラムでは数学表記とロシア語の単語のラテン文字表記したものを混ぜたもの使っています。見た目が簡潔なこと、全体的にコードが不可解なことから、ロシアのプロのプログラマは「govnokod」と名づけます。訳すと、文字通り「クズコード」を意味します。学術的環境で構築されたプログラミングは、ほとんどがこのようになっています。さらに、専門家の心配をよそにこれらのコードは「クリーン」なコード同様うまく機能します。

2006年頃に書いた「govnokod」の一例
ソフトウェア業界に入った大学の友人の数名は、ロシアの学校のプログラミングを教える方法を蔑視しています。正しい英語で抽象プログラミングの名前を学び直し、学校で叩き込まれたプログラミングへの英語不可知論の姿勢を懸念しています。これは2つの理由から興味深いと思います。
- 外国語を学ぶのは困難です。一般的な考えとは逆に英語の習得は簡単ではありません。
- プログラミングにおける名前付けとの結びつきは他の知識作業分野よりも格別に強いものです。
それぞれのポイントを詳しく見てみましょう。
英語は難しい
Redisを作成したSalvatore Sanfilippoの『 15年間英語に苦しめられた 』と題したブログの投稿は、英語で自分の考えを表現することに10年以上も悪戦苦闘する姿を書いています。現代のWebスタックの礎を築いた人によって書かれました。
新しいTCP/IP攻撃を行なっているのに、英語で投稿を書くことができなかった。それは1998年の事でコミュニケーションをとることができないという事実に制約を感じていた。読むことに努力を注がないと英語で書かれた技術書を読めなかったため、脳のエネルギーを50%も消費してしまうことになり、内容を理解するエネルギーがほとんど残っていなかった。
良くも悪くも、英語は世界の共通語としての競争に勝ったと言えるでしょう。きちんとしたプログラミングをしたい場合、英語を流暢に読むことは必須となっています。しかしながら、外国語で 書く ことはさらに困難を極めます。一方で、典型的なプログラミングのタスクでは、ちょっとした短い物語を書くのに必要な語彙は使いません。もう一方では、簡潔で明確な名前が必要になりますが、英語が堪能でないと思い浮かべるのに一苦労です。
個人的推測ですが、平均すると、英語のネイティブスピーカーの設計した比較的大きいAPIの方が、英語力が中級の人が設計した同じようなAPIよりも表現が豊かだと思います。これが顕著になったのが、Clojureに入った時です。Rich Hickeyは語彙を意図的に使用することで知られています。Clojureでは、 単純は簡単ではない 、 コレクションはシーケンスではない 、 reify や transducer などの関数名は平凡だとされています。
類語辞典や 逆引き辞典 で武装しても、Richの語義を使用した職人技に英語が外国語の人が太刀打ちできるはずがありません。現実にはGoogle翻訳や命名規則などである程度のところまでたどり着くことはできます。時折、 isHided や visibles 、 unexisting といった大間違いをしたとしても、GitHubの星数の判定に影響することはありません。
概して、英語が外国語の人でも英語で問題なく 物 に名前を付けることはできますが、オブジェクトの性質の説明や特定の相互作用を明確にラベル付けするのは容易ではありません。幼い子供が言葉を覚える過程を考えてください。幼い子供は難しい動きを「並列」や「散在」などの単語を使わず身近なもので表現するでしょう。あるいは、不規則に何かがオンやオフになることを「断続的」とは言わないでしょう。
いたるところに名前
ハックニー風の古いことわざによると『情報科学にはキャッシュの無効化と名前付けの2つの難しいことがある』そうです。名前を考えることがなぜ困難なのか簡単に想像はつくと思います。多くの場合、プログラムは必ずしも「現実」世界にうまく反映することのできない複雑な抽象データ構造体を扱います。
名前付けに関してプログラマは信じられないほど独創的です。構成管理ツールのChefでは、クックブックやキッチン、ナイフなど料理に関する比喩を使っています。リアルタイムデータ処理システムを提供するStormでは、streams(流れ)やspouts(噴出)、bolts(固定)などを使用しています。実用性の低いものでは、Herokuが「flexile-sentry.heroku.com」といったサーバホスト名の生成で皆を楽しませています。比喩と「おかしい」名前が開発者の経験を向上させるのか、それとも基本的な概念をあいまいにしているだけなのかについての議論が続いていますが、この投稿の本題には関係ないのでこれ以上は触れません。重要なのは、開発者が名前付けに多くの時間を費やしているということです。時には生産性を損なうほど時間を掛け過ぎていると感じます。
時々、Illustratorで膨大なベクトル画像をいじっていたりSketchでWebページのモックアップをしていたりする妻のパソコンの画面を見ることがあります。ほぼ全ての高度なグラフィックエディタには、現在のドキュメントの全てのレイヤや図形を一覧で表示するちょっとしたウィンドウがあります。Illustratorの公式マニュアルを読むと、イメージの全ての要素に意識的に名前を付けることを推奨しています。

しかし、Juliaが起動している時は、このウィンドウはチュートリアルには見えません。Juliaは主に生成されたレイヤ名に依拠し、複雑なイラストでも問題なくナビゲーションできるようです。
-final (copy).ai")
Juliaがイラストを処理中
Illustratorでは、ファイル名を前もって指定するよう求めることもなければ、同じ名前のレイヤを2つ持っていても怒鳴りることもありません。生成された名前から始め、必要に応じて名前を変更します。 これをRuby on Railsアプリケーションのブートストラップと比較してみましょう。必要な引数nameは、アプリケーションモジュール、セッションキーに使用され、生成されたテンプレートに挿入されます。
$ rails new experiment-2
...
$ grep -r -i experiment .
./app/views/layouts/application.html.erb: <title>Experiment2</title>
./config/application.rb:module Experiment2
./config/initializers/session_store.rb:Rails.application.config.session_store :cookie_store, key: '_experiment-2_session' もし後にexperiment-2をSpaceElevatorに名前変更したい場合でも自分で行うことができます。最も高度なRuby IDEやRubyMineでもっても、プロジェクトの名前変更のような(一見)簡単な作業ができません。しかし、これは氷山の一角でしかありません。「ダイヤモンドは永遠に」と思われている方、10年前からのデータベース図式の説明を新規に入社した人にしていませんよ。名前付けの失敗作には悩まされ続けることになります。
だからこそ、名前付けは未だに難しいのです。外国語ならなおさらのことです。さらに最悪なのは、後で名前を変更しようとしても困難であるか全く不可能なことです。どうすればこの事態を打開できるのでしょうか。特に2つの問題の解決に興味があります。
- ドメインの専門家にプログラミングを使って彼らの分野を促進してもらえるようにする。
- 母国語が異なるプログラマが作成したコード間のギャップを埋める。
少数の名前 = 少ない名前付け
Clojureの洗練された、ほとんどエリート主義的なアプローチについて既に上述でいじりましたが、別の側面もあります。関数型プログラミング言語は、やっていくのにそんなに固有名を必要としない傾向があります。これにはいくつかの異なる概念が要因となっています。
- 関数構成
- ラムダ関数の簡略構文
- 命名規則と「数学的」表記
下記のClojureのスニペットを見てください。ここでは、特定の文字列の中で指定された回数以上出現する単語(言葉)のみを返す関数を見せています。
(defn frequent-terms
"sを小文字のシーケンスに分割し、冠詞と句読点を
削除し、n回以上出てくる単語のみを返す。"
[s n]
(->> s
clojure.string/lower-case
(re-seq #"\w+")
(remove #{"a" "an" "the"})
Frequencies
(keep #(when (> (val %) n) (key %)))))
(frequent-terms
"もしウッドチャックが木を投げられるとしたら、ウッドチャックは何本の木を投げるだろう。
もしウッドチャックが木を投げられるとしたら、投げられるだけの木を投げるだろう。"
3)
; => ("woodchuck" "wood") このやや複雑な関数を実装する際に考えるべき名前はたった1つでした。関数の名前です。入力文字列に s と名付けました。これは、Closureで全ての文字列関数に使用されている規則で、別の共通の規則に従うと n は関数が受け入れられる唯一の数字を示します。いつくかの 高階関数 を作成することで、明白な反復とインデックスや一時変数などの副産物を避けています。ラムダ関数( #(when (> (val %) n) (key %))) )を導入する際にもClojureの構文では引数に名前を付ける必要がなく、 % 文字を介して参照します( %1 や %2 として、複数の引数にアクセスができます)。
全ての関数構成にいい名前が付いているとは限りません。繰り返しになりますが、数学者はギリシャ文字を標準表記に組み込むことでこの問題を回避しました。APIの作成にギリシャ文字を避けることをお勧めしませんが、下記の例のようにローカル関数のヘルパを f や g で問題なく示す場合が多々あります。
(letfn [(f [x] (Math/pow (Math/sin x) 2))]
(f (transduce (map f) + [1 2 3 4 5])))xとは一体
Clojureは簡潔さと表現力のバランスをほぼ完璧に保っているとは思いますが、正直、この「数学的」名前にはたびたび悩まされました。Clojureの名前付け方法に慣れるまでは、関数の宣言を理解するのに時間がかかるでしょう。今でも、sやn、fの代わりに string 、 min-occurrences 、 squared-sine が使えればと思います。しかし、ここでは実験のため、手作りではなく、他の可読性を高める名前付け方法を模索します。
メタ情報を提供するだということは明らかです。Illustratorの例で見てみると、依然として生成されたレイヤ名で異なる種類のオブジェクトを見分けています。プログラミング言語においてこの役割は(ある程度)型宣言と注釈が行います。下記のHaskellで書かれたプログラムを見てみましょう。
repeat n x | n > 0 = x : repeat (n - 1) x
| otherwise = [] repeat 関数によって数字の n と値の x 受け取り、 x のコピーを n 個から成るリストを返します。通常Haskellでは、型の特定は必要ありませんが、コンパイラに仮定を宣言するために型情報を追加することも1つの選択だと思います。 repeat 関数の型宣言は下記のようになります。
; n x (return value)
repeat :: Int -> a -> [a] この型署名は読み手に n が整数であること、 x は任意の型 a の値であること、そして戻り値が型 a の値のリストであることを知らせてくれます。この型署名(例えば、 k ∈ ℕ であるところに n + k の反復を返す)に一致する repeat 関数の実装方法は無数にあるものの、Haskellコンパイラは既にかなりの数の無効な実装を捉えることができます。例えば文字列 x がある場合、関数はタプルのリストを作ることも不規則な値を返すこともできません(ファイルから返された値を読み込むこともできません)。これは、プログラムが公開される前から確認されています。表面的には、互いにメリットがある状況のように見えますが、現実は決して白黒はっきりしているわけではありません。
理論上、言語の型システムは強固であればあるほど、より多くの情報を静的に利用することが可能になるため、その言語に対してより強力なリファクタリングやコードの検査ツールを作成することが可能になります。もちろん、IDEAやVisual Studioに組み込まれているJavaやScala、C#の計装はRubyの計装よりも信頼性が高いです。それと同時にHaskellの開発者がコンパイラ以外のツールの使用を控える傾向にある一方で、lisp使用者はエディタを対話型評価環境(REPL)に接続することで同じような(あるいはことなる)成果を得ているという逆説があります。
「単なる名前」を改善する中で、型システムによって魔法のように「数学的」表記のコードがキュメンテーションされることはありません。例えば、ある文字列の存在を次から次へと検索する下記のC言語の strstr 関数の宣言をそれぞれ比較してみてください。
# 1.
char * strstr(const char *a, const char *b);
# 2.
char * strstr(const char *haystack, const char *needle) #2 では、「乾草の針」という慣用句を知っている英語を話せる人であれば、引数の順番が直ちに理解できるでしょう。それと同時に英語が話せない人に取っては、#1も#2と同じように不可解であるという問題が浮上します。
プレーンテキストの制約
どうすればいいのでしょうか。関数型プログラミングや高度な型システムは確かに覚えなければならない名前の数を減らしてくれ、役に立つプログラムを作り出してくれます。しかし、 strstr のような関数は常に存在するため、自然言語の語義やドキュメンテーションの熟読で得たコンテキストから理解しない限り、不可解のままになります。英語を話す人は、なぜ外国人が自分の言語や文字体系をベースにプログラミング言語を作成しないのかと思っていることでしょう。もちろん 存在 しますが、このような試みは、アイデアの統合に基づいて構築された分野で孤立してしまう運命にあります。
別の例を挙げてみましょう。下記のスクリーンショットでは、ロシア語にローカライズされたMicrosoft Excelでスプレッドシートが編集されています。ロシア語版Excelの不思議なところは、ビルトイン関数ライブラリまでもが国際化されているため、関数名をキリル文字で入力します。

キリル文字で名前が付けられたMS Excel関数
正直、見た目がとんでもないと思います。しかし、英語が全く話せない土木技師の父は変だと思っていません。100枚ものシートからなるブックを作成し、フィルタや条件、ピボットテーブルを駆使する父は、恐ろしいほどExcelの数式に精通しています。 IF が何を意味するのか知りませんが、 ЕСЛИ は常に使っています。すばらしいのは、父のスプレッドシートを、英語を話す人に送った場合、使用する「英語版」MS Excelで開いたとしても、全ての数式が英語で表記され、父の意図したとおりに機能することです。
しかし、記でお見せした何千もの行からなる「govnokod」を受け取るとしたらどうでしょう。コンパイルは実行できると思いますが、ラテン文字表記されたロシア語とギリシャ文字で書かれたAPIを理解できないでしょう。どのようにすればExcelで見られるような、「本当の」プログラミング言語の規模の国際性を実現できるか分かりません。明確なのは、これは、プログラムの作成と配布のための主要メディアとしてのプレーンテキストの限界が表面化しているケースの1つであるということです。書式と開発環境の両方をコントロールしているからExcelはこれを実現できるのです。
プログラマの中にはプレーンテキストに代わるものについての議論になると非常に防衛的になります。読んだ後に このブログで論評 しましたが、現代のプログラマの「バイブル」である『The Pragmatic Programmer(実用的プログラマ)』では、プレーンテキストが実用的プログラマの手裏剣であることを説明するのに1章捧げています。それでも、先進的なIDE(すでに実装の詳細が分かりにくい)の普及や非テキストプログラミング環境( MIT Scratch や Unreal Blueprints など )の採用が進んでいることを考えると、これら全てのアイデアを組み合わせ、誰にとっても実用的なプログラミングツールを生み出してくれる何かの登場の兆しが見える気がします。
おさらい
識別子としての名前や特に柔軟性のあるソフトウェア開発でもっても、フィールドで一度選ばれた名前の厳格性に対する不満の産物がこの投稿です。時折、新しいプロジェクトや関数、あるは変数を形容する呼称を選ぶのに手間取ります。これは、名前付けが難しいこともありますが、英語が母国ではないことにも原因があると考えます。しかし、現在のプログラミングツールや技術によって難しさが生じている部分が依然としてあります。
関数型プログラミングによってプログラムで使う固有名を削減できます。型宣言によって意味に深みを与え、可読性を損なうことなく数学的表記が使えるようになりました。静的型の検証と厳格なコンパイラによって高度なリファタリングツールを構築するのが簡単になったので、名前が悪い場合は後で変更が可能になります。この投稿では、普遍的なコンピューティングを通して、これらの傾向やアイデアを役立てることで異なる文化間のギャップを埋めることができることを説明しました。
恐らくこの分野における最大の改善は、伝統的なプログラミングツール(テキストエディタやCLI)を超えて、純粋にビジュアルでインタラクティブな環境に向かうことにあるのではないでしょうか。プログラミングは「思考のためのツール」として知られていますが、そうなるためには、ExcelやIllustratorの教訓から学び、新しいアイデアを「実用できない」と切り捨てるのではなく、取り入れられる状態でいる必要があります。つまり、コンピュータも世界共通の言葉である共感を学ぶ必要があるということです。

株式会社リクルート プロダクト統括本部 プロダクト開発統括室 グループマネジャー 株式会社ニジボックス デベロップメント室 室長 Node.js 日本ユーザーグループ代表
- X: @yosuke_furukawa
- Github: yosuke-furukawa
関連記事






