2014年7月11日
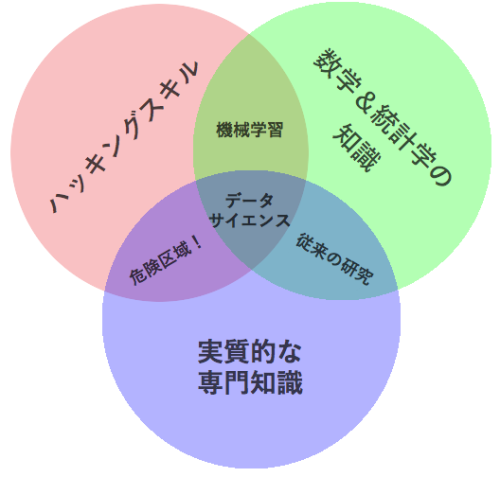
データサイエンス・ベン図
(2010-09-30)by Drew Conway
本記事は、原著者の許諾のもとに翻訳・掲載しております。
2010年9月27日、私は Strata conference 2011 を主催する オライリー の手助けをするため、あらゆるデータについて考えているニューヨークで最も洗練された思想家のグループと一緒に、恐縮しながら半日の アンカンファレンス に参加しました。分野別のセッションはどれもすばらしく、専門家主導の飛び抜けた議論を見越して各セッションの参加人数が決められていました。私が出席した中で最もよかったセッションの1つでは、データサイエンス指導に関連する問題に焦点を当てたため、必然的に有能なデータサイエンティストになるために必要なスキルについての議論になりました。
以前述べたとおり 、私は「データサイエンス」という用語は 少し間違っている と思っていますが、この議論の後、私は非常に期待しました。このテーマに関するカリキュラムがどんなものになるかについて全く意見が合わなかったのが主な理由です。これらのスキルの定義の難しさは実体と方法論の間の境目があいまいだという点にあり、そのため、ハッカー、統計学者、特定分野の専門家、それらが重なる部分やデータサイエンスが適合する箇所を区別する方法は不明です。
しかし、有能なデータサイエンティストになりたいのなら、 多くのことを学ぶ必要がある ということは明白です。残念ながら、単にテキストやチュートリアルを列挙するだけでは、もつれた結び目を解くことはできません。従って、議論を簡単にして、 既に アイデア で いっぱい の マーケット に私自身の考えを加えるために、データサイエンス・ベン図を発表します。
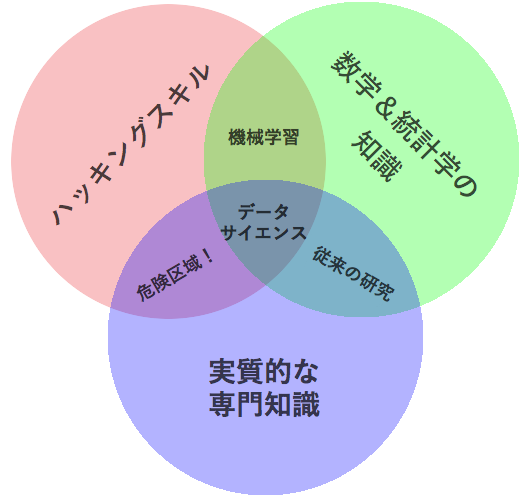
データサイエンス・ベン図の見方
データの三原色は、 「ハッキングスキル」、「数学&統計学の知識」、そして「実質的な専門知識」 です。
- 2010年9月27日、私たちはたくさん時間をかけて、データサイエンスに関するコースは大学の”どこ”に存在する可能性があるかについて話しました。これらのスキルにはもともと複数の分野にまたがる性質があるということを誰もがよく知っていたので、その話し合いでは主に言葉を使って効果的に表現していましたが、その時に私がこの3つを強調した理由が分かりますか? まずは、どれも分野を特定しないからです。しかし、もっと重要なのは、これらのスキル1つ1つにはそれ自体にとても価値がありますが、このうち2つだけを組み合わせた場合、良くても単にデータサイエンスでないという程度で済むだけで、最悪の場合、実に危険だということです。
- 良くも悪くも、データは電子的にやり取りされる商材ですから、このマーケットでやっていくためには、ハッカーを語ることが必要です。しかし大学などでコンピュータサイエンスを学んでいなければならないということではありません。実際、私がこれまでに出会った印象に残るハッカーの多くは、コンピュータサイエンスのコースだけを受講していたわけではありません。コマンドラインでテキストファイルを巧みに扱えることや、ベクトル演算を理解すること、アルゴリズム的に考えることが、データハッカーとして成功するためのハッキングスキルなのです。
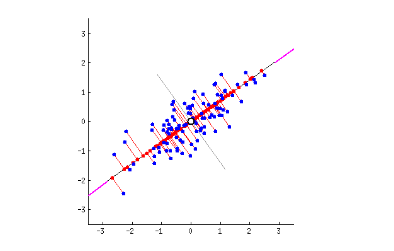
- データを取得してクレンジングしたら、次のステップは実際にそのデータから洞察を得ることです。それには適切な数学的・統計学的手法を用いることが必要となりますので、数学や統計学についての最低限の理解が求められます。有能なデータサイエンティストになるには統計学で博士号を取得しなければならないと言っているわけではなく、 最小二乗法 による回帰とは何で、それをどう解釈すべきかを分かっている必要があるということです。
- 3つ目の「実質」の部分は、データサイエンスついてこれまで書かれてきた多くの考え方と、私の考えが異なる点です。私にとって、「データ」+「数学&統計学」は単なる機械学習のスキルであり、もしあなたが興味を持っているのが機械学習なら大変結構ですが、データサイエンスに取り組んでいるなら、十分とは言えません。科学とは発見と知識の構築です。それには、この分野に関して深く調べたくなるような疑問を持つことや、データに応用して統計的手法でテストできる仮説を立てることが必要なのです。一方、「実質的な専門知識」+「数学と統計学」は、多くの伝統的な研究者が陥る、言わば落とし穴です。博士レベルの研究者は、ほとんどの時間をその分野の専門知識を得るために費やす一方、テクノロジを学ぶことにはほとんど時間を割きません。ある意味これは学界の文化です。研究者たちがテクノロジを理解したとしても、それが報われる風土はないのです。とは言え、この伝統を打ち破りたいと情熱を燃やす若い研究者や大学院生が大勢いるのも事実だということを付け加えておきます。
- 最後に「ハッキングスキル」と「実質的な専門知識」の交わった領域、「危険区域」について一言。ここに当てはまるのは「ある程度知識があるだけに危険」な人たちで、この図の中では最も問題となります。この領域に属す人というのはよく知っている分野に関連していそうなデータの抽出や構造化は完璧で、恐らくR言語の知識も線型回帰を実行して係数を求められるくらいは備わっているかもしれませんが、その係数が何を意味するのかは分かっていないのです。「嘘、大嘘、そして統計」という表現が広まったのはこの領域からです。この2つのスキルが重なる領域では、無知のせいか悪意のせいかは分かりませんが、分析結果やそこに至る経緯について全く理解していなくても、一見まともに見える分析を行うことができます。幸いなことに、数学と統計を全く学ばずにハッキングスキルと実質的な専門知識を取得するというケースは非常に稀で、あえて避けた場合のみのように思えます。ですから、この危険区域に当てはまる人たちは多くはありませんが、大きなダメージを与えるのに多くの人を必要とするわけではありません。
手短に説明しましたが、これでデータサイエンスとは何なのか、またそれを得るためには何が必要なのか少しはお分かりいただけたかと思います。このような問題について大局的に考慮するとよいと思います。そうしないと、特定のツールやプラットフォームなど、重箱のスミをつつくような議論になってしまい、話し合いの本質を見失ってしまうでしょう。
大事なことをたくさん飛ばしたと思いますが、そもそもこの記事の目的は具体例を挙げることではありません。いつもどおり、コメント歓迎します。
dataist にクロスポストされています。

株式会社リクルート プロダクト統括本部 プロダクト開発統括室 グループマネジャー 株式会社ニジボックス デベロップメント室 室長 Node.js 日本ユーザーグループ代表
- X: @yosuke_furukawa
- Github: yosuke-furukawa
関連記事