2016年8月3日
効率的な統計実践のための、10個のシンプルなルール

本記事は、原著者の許諾のもとに翻訳・掲載しております。
イントロダクション
数ヵ月前、広く成功を収めており、非常に役立つ“10個のシンプルなルール”シリーズの提唱者であるPhil Bourneは、何人かの統計学者に統計に関する10個のシンプルなルールの記事をまとめることを提案しました。(そのルールのうち「PLOSでTen Simple Rulesの記事を書くためのルール」はPhil Bourne ^(1) のものです。その代わり、Philに対するあふれるほどの賞賛で満足してくれると思います。)
10個のシンプルなルールを書くガイドライン ^(1) の中で示唆されているのは、「自分の読者を知りなさい」ということです。私たちはルールのリストを、研究者を念頭に置いて作り上げました。研究者は統計に関する幾分かの知識を持ち、同じビルに少なくとも1人は統計学者がいたり、あるいは健全なDIY精神と、ノートパソコンの中に統計のパッケージを持っていたりするかもしれません。私たちは協働的なリサーチと教えることの両方の経験を利用しました。それはつまり、何度も「学生の論文/私の学位申請書/審査員のレポートをちょっと見てくれませんか。統計のインプットが必要なのですが、かなり分かりやすいものじゃないとダメなんです」と頼まれる私たちのイライラから生まれたということです。
多くの概念をはっきり説明してくれるすばらしいリソースも利用できますし、ここよりもはるかに多くの詳細があります。私たちのお気に入りはCoxやDonnelly ^(2) 、Leek ^(3) 、Peng ^(4) 、Kassら ^(5) 、Tueky ^(6) そしてYu ^(7) のものです。
統計に関する記事は全て、少なくとも1つのただし書きを必要とします。私たちの記事では、次のようなものです。:この記事では『科学』という語を、興味のある疑問を研究するためにデータを用いる調査を表す、便利で簡潔な語として使っています。これには社会科学や工学、デジタル・ヒューマニティーズ、ファイナンスなどが含まれます。統計学者は、統計科学がほとんど全ての組織のほぼ全ての部分で影響力を持つということを管理者に思い出させないようにするものではありません。
ルール1:統計的手法は、データが科学的な質問に答えられるようにするべきである
統計の経験のないユーザと熟練の統計学者たちの大きな違いは、データの使い方をじっくり考えるとすぐに現れます。実験によって科学的な質問に答えるためのデータが得られるのは明らかですが、統計の経験のないユーザは、データと科学的な問題の間につながりがあるのが当然だと考えます。その結果、科学的な目標ではなく、データ構造に基づいたテクニックに飛びついてしまう傾向があります。例えば、遺伝子の微細な配列を表したデータが表の中にあったとします。すると彼らは「どのテストを使えばいいか」と考えることで手法を探そうとするでしょう。一方、もっと経験のある人は、「違いのある遺伝子はどこだろう」というような基本的な質問から始めて、それから、データが答えを提供するような複数の方法を検討します。おそらく、正式な統計のテストは有効でしょう。しかし、ヒートマップやクラスタリングといった他のアプローチも代わりの手段になるかもしれません。同様に、神経画像検査では、様々な実験的な状態における脳の機能を理解することが、主な目的となります。これをカッコいい画像で説明するのは二の次です。統計の技術から科学の疑問へという観点の変化は、データの収集や分析のアプローチ法も変えるかもしれません。質問について学んだ後、統計の専門家たちは調査に協力してくれる科学者たちと一緒に、データが質問に答えてくれる方法、そしてそのためにはどんな研究が一番有効かを話し合います。
一緒に、彼らはばらつきに関する潜在的なソースと、どんな隠された現実がデータと科学的推論の間にある仮説的なつながりを壊す可能性があるかを特定しようとします。そこまでやってから、分析の目標と戦略を設定します。これは、統計家との協力が有用であることの主な理由です。そして協力のプロセスは、研究の初期に始めるのが最も有効であることの理由にもなります。 ルール3 を参照してください。
ルール2:シグナルはいつもノイズと一緒にやって来る
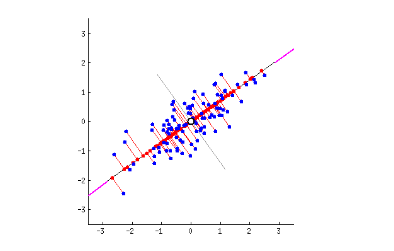
ばらつきに取り組むことは、統計の規律の中心を成すものです。ばらつきは、いろいろな形で現れます。ばらつきがいい場合もあります。結果の中のばらつきを説明するための予測変数では、ばらつきが必要だからです。例えば、喫煙が肺がんと関連があるか調べるためには、喫煙習慣にばらつきが必要になります。病気と遺伝子の関連を見つけるためには、遺伝子のバリエーションが必要です。その他の場合は、ばらつきは厄介なものかもしれません。例えば、同じものを3回計測して3つの異なる数字が出た時などです。こちらのばらつきは、通常「ノイズ」と呼ばれ、理解もされないし無用なものとも考えられません。統計的な分析は、データや興味深いばらつき、ノイズの存在、あるいは無用なばらつきによって得られたシグナルを評価することを目的としています。
多くの統計の手順の出発点は、数学的な抽象化を導入することです。例えばある特定の病気と診断された、あるいは診断テストで値のスコアを受け取った患者という結果は、調査の対象となる個人によって様々です。統計の形式主義は、このようなバリエーションをおそらく確率分布を使って表すでしょう。ですから、例えば、理論上は確率分布によってデータのヒストグラムが置き換えられます。そうすると、注意の対象が生のデータから確率分布の正確な特徴を決定する数字のパラメータ―例えばその形や広がり、中心の位置など―に移り変わります。確率分布は統計モデルの中で、私たちが観察する、あるいは観察したいデータを生成するためにシグナルとノイズを合体させる方法を特定するモデルと共に使われます。この基本的なステップによって、統計の推測が可能になります。これがなければ、全てのデータの値はただ1つしかないものとして考えられ、「同じ物を複数回計測したのに、機器が違う値を出してくるのは何故だ?」ということの原因となったかもしれない全ての詳細なプロセスを探すはめになります。シグナルとノイズを「統計的モデルにおける確率」として概念化することは、極めて効果的な単純化であることが証明されており、それによって私たちが理解しようとしている定量の不確かさを表すためのデータの中のばらつきを捉えることができるのです。形式主義はまた、私たちにシステムエラーの可能性のあるソース、つまりバイアスを探すことを教えてくれます。
ビッグデータは、この問題の重要性を下げることはなく、ますます重要にします。例えば、Google Flu Trendは2008年にかなりの期待を伴って登場しました。しかし、インフルエンザの有病率をほぼ50パーセントと過剰に見積もることが分かりました。これは主に、データが集められる過程で起こるバイアスによるものです。Harford ^(8) を参照してください。
ルール3:本当に早いうちから計画を立てる
データの収集に多くの労力が必要とされる場合、統計の問題は、「サンプル数 n はいくつにすべきか」というような独立した問題として扱われることはあまりないでしょう。 ルール1 で述べたように、実験を計画する際、統計の経験が豊富な人は、1つ1つの細かいことに注目するのではなく、一歩引いて大きな視野で、様々な視点からデータの収集について考えます。全体としてのゴールを見据え、「この実験における理想的な結果はどんなものか? その結果をどう解釈するか?」というようなことを考えます。XとYを観察し、両者が一緒に変化するのか、逆にそれぞれが個別に変化するのかを判断しようとする場合、XとYがどのように測定されたものかが鍵となるでしょう。例えばXとYの表す概念的な意味の範囲、測定に影響する多くの要因、またそれらの要因をコントロールする能力、そして一部の要因が系統誤差(バイアス)を生む可能性があるかどうか、といったことなどです。
ルール2 で、対象の理論量に着眼点を移すことで、データを目的にリンクさせるのに統計モデルが役立つという話をしました。例えば、一組の神経細胞から電気生理学的測定を行う場合、神経生物学者は「同様の測定条件下においては、この2つの神経細胞が類似した神経細胞の類い全体を代表するものだ」という前提のもと、ある特定の測定法を用いるのが当然だと思い込んでいるかもしれません。一方、統計学者はまず、共変動の測定データをどうやって取るかを考えるでしょう。測定に影響を及ぼす主要な要因は何か、実験デザインがよければその影響を取り除けるかどうか、実験を繰り返す中でのばらつきの原因となるものは何か、また、ばらつきの原因についての定量的な知識がデータの収集にどのように影響するか、調査する神経細胞がきちんと定義された対象者たちから採取されたサンプルと考えてよいのかどうか、神経細胞の一組を取り出す工程がそのあとの統計分析の工程にどのように影響し得るのか、などといったことを考えていきます。こうした基本的な問題を網羅する会話を交わすことで、実験者が考えていなかった可能性を浮かび上がらせることができるのです。
計画の段階で質問をすることで、分析の段階で問題が起こるのを防ぐことができます。慎重にデータを取得することで、分析の明快さも精度も高まります。Ronald Fisherも、「実験が済んだあとに統計学者に意見を求めても、大抵の場合、それは単に終わったことを議論しようと言っているようなものだ。もしかしたら統計学者は、失敗の原因を語り出すかもしれない」と言っています ^(9) 。調査計画を読む出発点としては、 ^(2) の第1章から4章を参照されることをお勧めします。
ルール4: データの質を心配する
熟練した実験者たちは、データ分析となると、「無意味なデータは無意味な結果を生む」ということを直感的に理解します。しかし近年はデータ収集が複雑化し、大抵はデータの前処理も含め、テクノロジーの力について様々な前提条件を考えておくことが求められます。簡単に見過ごされがちなことが計り知れない影響を及ぼす可能性がありますから、データの前処理は慎重に行うことを強くお勧めします。
前処理済みのデータを扱う場合も、分析の前に相当な労力をかけることが必要かもしれません。様々な呼称があり、「データクリーニング」、「データマンジング」「データ加工」などと呼ばれるものです。多くの場合、データクリーニングによってデータの質に関する重要な点が見えてきますから、その実体験が非常に役立つでしょう。いいケースでは、測定されたものが確かに自分の欲しいデータだったと確認できます。逆に悪いケースだと、損失を早めに切ることを決断させてくれます。
個々の測定をよく理解し、持続的に記録することが大切です。あるべきデータの値がなければ、適切なソフトウェアでそれを認識することが大切です。例えば、999は数字の999を意味するかもしれませんし、もしくは「不明」という意味のコードかもしれません。「検出なし」というような状況を何とかするための防衛策があるべきですし、例えば変数27の半分が0.00027と等しい値を持つなどという異常がないかどうかスキャンを行うべきです。データがどのようにして自分のデスクやパソコンに届いたのかということを、できるだけきちんと理解するようにしましょう。なぜ一部のデータがない、もしくは不完全なのか? 本当に妥当な仕組みの中で、データが取れなかったということなのか? データ取得の仕組みを理解することが、深刻な間違いにつながる結果を回避するのに一役買うかもしれません。 例えば、注意欠陥・多動性障害について脳の発達状況を画像診断するという研究では、最も深刻な多動性障害を持つ子供のデータが一部取得できていないかもしれません。MRスキャナの中でじっとしていられなかったという可能性も考えられるのです。
ひとたび苦労してデータを使いやすいフォーマットにしてしまえば、ほら見てください。探索的データ解析としても知られているように、コツコツとデータをいじる工程は、分析の中でも最も有益な情報を得られるところです。探索結果のプロットから、データの質の問題や外れ値を見つけ出すことができます。平均、標準偏差、正規化などの簡潔なデータのまとめは、考えを洗練し、仮説の妥当性を確認するのにも役立ちます。全く新しい科学の分野に進む場合は特に、研究の多くはあえて試験的に進められます。今までにない分野なので調査の前にはっきりした仮説を立てることができないという時などです。非公式にデータに取り組むことで、新たな仮説やアイデアが生まれることがあります。しかし、公式に分析を行う前には、具体的なデータの収集法に関する知識をつけ、その選択がどのように結果に影響するかを考えることも重要です。そして、仮説を立てる工程とそれをテストする工程の両方に、同一のデータ集合を使うのには問題があるということも、きちんと覚えておく必要があります。 ルール9 を参照してください。
ルール5: 統計分析は、ただの「計算のセット」ではない
統計のソフトウェアは、分析の助けになるツールを提供してくれますが、分析を定義してはくれません。科学的な背景は極めて重要で、理にかなった統計分析を行うための鍵になるのは、分析手法が科学的な疑問と密に対応するようにすることです。 ルール1 を参照してください。特定のアルゴリズムや、論文の「手法」の章の中にあるソフトウェアを参照したりするのも有用ではありますが、なぜその分析手法を選んだのかと問われたら、それだけでは説明の代わりにはならないでしょう。読者は、答えが導き出された本質的な質問に対して、分析手法が適切にリンクしているかどうかという基本的なことを知りたがるでしょう。読者をごまかしてはいけません。はっきり説明しましょう。
同時に、かっちりしたアルゴリズムの分析工程を踏むと、後から自分で同じ分析を再現する時や、他の人が同様または類似したデータを取ろうとした時にも非常に役立ちます。 ルール10 を参照してください。
ルール6:シンプルさを保つ
他が全て等しいなら、シンプルさが複雑さに勝ります。このルールは改めて注目を浴び、多くの分野での操作手順において大事にされており、また”オッカムのかみそり”、”KISS”、”less is more”、”シンプルは究極の洗練”などの様々な表現で説明されています。節約の原則は信頼できるガイドとなり得るのです。シンプルなアプローチで始め、複雑にするとしても必要がある時だけ、不可欠と思えるものだけを加えます。
そうは言うものの、科学的データには細かな構造があり、その上、重要な複雑さに対してシンプルなモデルがいつも順応できるというわけではありません。広く知られた独立性の仮定が正しくないことがよくあり、ほとんどの場合、詳しく検定する必要があります。 ルール8 を見てください。膨大な量の測定値、説明変数の間の相互作用、非線形の挙動のメカニズム、欠測データ、混乱、サンプリングの偏りなどが、いずれも複雑なモデルを必要としています。
次のことを覚えてください。しっかりと要求を満たした優れたデザインがあれば、シンプルな分析方法から強力な結果が得られます。 ルール3 を見てください。シンプルなモデルは複雑な現象から秩序を築くのに役立ち、シンプルなモデルは仲間や広く世界の人々とのコミュニケーションに最適です。
ルール7:変動性を評価する
生物学の測定値のほとんどにおいて、測定を繰り返すとかなりの変化が現れ、そのためデータに基づいた計算結果の全てにおいて不確実性が生まれます。統計分析の基本的な目的とは、よくある標準誤差や信頼区間という形で、不確実性の評価に役立てるということです。統計学のモデリングと推論における偉大な成果のひとつが、対象を測定した同じデータから標準誤差の算出ができるということです。結果を出すにあたっては、統計上の不確実性の概念を入れることが不可欠です。よくある誤りは、データや変数の依存関係を考慮せずに標準誤差を推定してしまうことです。これは、一般に実際の不確実性をかなり過小評価してしまうことを意味します。 ルール8 を見てください。
たとえ同じ生物学的素材で測定が繰り返されたとしても、ある計算によるデータから得られる数値はどれも少し異なるものだということを忘れないでください。もし新しい素材を使えば、そのサンプル内に元々存在する変動性によって測定値の変動性が増大する可能性があります。データを集めるのが別の日、別の研究室、あるいは手順を若干変え得るということであれば、考慮すべき変動性の潜在的要因が3つ以上あります。マイクロアレイ分析においてはバッチ効果が変動性の追加をもたらすものとしてよく知られており、フィルタをかけるのにはいくつかの方法があります。変動性の追加は結論における不確実性の追加を意味し、この不確実性はレポートされなければなりません。このレポートは、次回の調査を計画する際に非常に貴重な存在です。
不確実性の評価が過度に楽観的になるというのは、ビッグデータにとてもありがちな特徴です(Cox ^(10) 、Meng ^(11) )。ためになって、魅力的にシンプルで、調査が大きく関わる定量分析については、 ^(11) の”data defect”のセクションを見てください。ビッグデータは常に見た目ほどビッグというわけではありません。特に、こういう測定値は従属的になる傾向が強いので、少量のサンプルに対する膨大な量の測定値については、標準誤差をきめ細かに推定する必要があります。
ルール8:仮定をチェックする
あらゆる統計的な推論には仮定が含まれます。それは実際の知識やデータの変動に対する確率論的な表現に基づいており、いわゆる統計モデルのことです。”モデルフリー”と呼ばれる手法でさえも、制限は少ないものの、仮定は必要で、この用語はいくぶん紛らわしい言葉です。
最も一般的な統計学の手法には線形関係という仮定が含まれています。例えば、一般的な相関係数は、ピアソン相関係数とも呼ばれますが、線形の関連を測るものです。線状であることは、しばしば初期の推定あるいは一般的傾向の記述として使えるものです。特にデータに含まれるノイズの結果、関係が線形なのか非線形なのかの区別がつきにくい時に有効です。しかし、どんなデータセットであるとしても、線形モデルの妥当性は経験に基づくものであり、調査されるべきです。
色々な意味で更に厄介ですが、よく起こることは、統計分析の仮定で、データに含まれる複数の観測値が統計的に独立しているということです。なぜ厄介かというと、これは仮定の比較的小さな偏差でも劇的な効果を出せるからです。例えば、時間をかけて測定値を得る場合は、時間的なシーケンシングが重要になるでしょう。この場合、時系列に適切な専用メソッドの使用を検討する必要があります。
非線形性と統計的な依存性に加え、欠測データ、測定値内の系統的なバイアス、他の様々な要素が統計モデリングの仮定を破る原因となり得ます。これは、どんなに実験がすばらしかったとしても同じことが言えます。広く普及している統計ソフトウェアでは、内在的な仮定に細心の注意を払わなくても分析を簡単に行うことが可能です。ただし、不正確だったり、更には誤解を招いたりするような結果になってしまう危険もあります。そのため、使用中のメソッドに取り入れられた仮定を理解することは大切です。仮定を理解し評価するために、できることは何でもしなければいけません。少なくとも、統計モデルがどれくらいデータに適合しているかを確認したくなるでしょう。データの視覚的な表示とプロット、あてはめの残差は、仮定の関連性やモデルの適合性を評価するのに役立ちます。また、モデルの適合性を評価する基本的な技術は、ほとんどの統計ソフトウェアに備わっています。モデルの中には、同じデータで”適合テストをパス”できるものがいくつかあることを覚えておいてください。詳しくは ルール1 と ルール6 を見てください。
ルール9:可能であれば繰り返す
優秀なアナリストはデータを細かく調べ、色々な種類のパターンを探します。そして、予測可能な結果と予測不可能な結果を研究します。この過程には、大量のデータを視覚化して置き換えたり、いくつもの数字を細かく切り分けたりといった何十もの手順を含むことが珍しくありません。最終的に、データの特性のいくつかに関心が寄せられ、重要であると見なされると、その結果が論文発表の場で報告されるということがよくあります。
p 値のような統計的な推測値が広い範囲のデータに従うようになると、通常の解釈ができなくなります。この事実を無視することは、放った矢の着地点を中心に的を描くのと同じで不正直です。これは p ハッキングとして知られていて、その危険性や落とし穴について書かれた文書も多くあります。例として ^(12) と ^(13) を見てください。
最近では、科学的な p 値の使用に対する批判が大きくなってきています。その大部分は、” p 値は0.05未満”の結果でなければ発表する価値がないという誤解に基づいています。American Statistical Association(ASA) ^(14) は最近の声明の中で、 p 値を使うメリットと限界について説明しています。
統計学者は、報告された分析用に特定の変数を選ぶといった、最も顕著なデータスヌーピングを気にしがちです。このような場合には、結果の調整を助けるメソッドが存在します。例えば、BenjaminiとHochberg ^(15) が提案した偽発見率メソッドは、その中でも基本的なメソッドです。
分析によっては、予備データに何かの操作を加えても問題がない場合があります。それ以外の状況では、アナリストは非常に小さい p 値だけを信頼することで、非公式なチェックを作業に取り入れるでしょう。例えば、高エネルギー物理学では、”5シグマ”の結果を要求することが、”どこでも効果”に対する近似補正の、少なくとも一部の役目を果たすことになります。
データスヌーピングで生じる問題を解決するために本当に信頼できる唯一の方法は、適用するデータ特性と共に、鍵となる結果を導く統計的推論の手順を記録することです。そして、新しいデータを使って同じ分析を繰り返します。このタイプの独立した繰り返しは、実験手順を修正することで更に改善され、実験の細部にある程度の堅牢性を与えることができるようになります。
理想的なのは、第三者が繰り返すことです。時間の経過に耐え得る科学的な結果とは、多様に異なりながらも関連性の高い状況を網羅して確認された結果です。実験の繰り返しを行わない場合は、データの摂動の適切なフォームが役に立つでしょう(Yu ^(16) )。多くの場合、例えば多施設での臨床試験のような大規模な研究などでは、完全な繰り返しは非常に難しいか不可能です。そのような場合には、次の ルール10 で述べる最低基準を適用します。
ルール10:再現性のある分析を行う
科学的な結果を報告する際の現在のフレームワークでは、 ルール9 で検討したような独立した繰り返しはほとんどの研究者にとって現実的ではありません。より実現が簡単な基準として、それとは異なる基準となるのは再現性です。つまり、分析の完全な説明および同一のデータセットがあれば、テーブルや数値や統計的推論が再現できるはずです。しかし、このように基準を低くしても、計算アーキテクチャやソフトウェアのバージョンや設定の違いなど、いくつかの問題に直面することになります。
分析のステップを高度に体系化し( ルール5 を見てください)、結果を得るために使用したデータとコードを共有し、Goodmanら ^(17) の考えに従うことによって、結果の再現性を劇的に向上させることができます。
Sweave ^(18) やknitr ^(19) 、iPython ^(20) notebookといった再現性を備えた最新の研究ツールは、こうした手法を採用しており、更に研究結果と共にコードを報告する機能も兼ね備えています。再現性のある研究は、それ自体が現在進行中の研究分野であり、注目すべき非常に重要な分野です。
結論
「嘘には3つある。普通の嘘と、真っ赤な嘘と、統計だ」というマーク・トウェインの有名な言葉があります。確かに、主張に偽りの根拠を与えるために、選択的にデータが使われることはよくあります。データを故意に誤用したり、データやデータ概要の入手方法に関わる重要な情報を隠したりすることは、当然、非常に倫理に反することです。しかしもっと油断ならないのは、悪意が無いとはいえ、誤った統計的な根拠に基づく科学的な仮説に関する主張が、世の中に広く流布しているという事例です。本稿の主な目的の1つは、こうした問題の多くの根源を強調し、落とし穴を避ける方法を伝えることでした。
研究者として私たちが行っている中心的かつ日常的な仕事は、解決しようとしている問題に対してデータは何を言えるのかを解釈することです。この過程を助けるために構築された言語が統計であり、確率はその文法です。十分な言語の運用能力が無くても、初歩的な会話は可能です(そして、ごく普通に会話は取り交わされます)。しかし、多くの些細な現象を把握するには、原理に基づく統計的な分析は必要不可欠です。それにより、重要な要素が解釈の過程で抜け落ちないように保証され、調査結果が時間の経過に耐え得るものになる可能性が高まるのです。この数学的に洗練された言語で完璧かつ流暢に会話できるようになるには、何年もの訓練と練習が必要ですが、本稿で紹介した10のシンプルなルールが、何らかの基本的なガイドラインを提供できれば幸いです。
ASAの p 値に関する発言が多くの記事で伝えられていますが、中でも特に、生物統計解析者であるAndrew Vickers ^(21) の次の言葉が気に入っています。「統計学を、レシピとしてではなく科学として扱う」。これは、ルール0の候補となる素晴らしい言葉だと言えます。
謝辞
本稿執筆にあたり、多くの同僚に非公式に相談しましたが、本稿で表明した意見は、著者たちによる小規模な委員会独自の意見です。ユーモアを交えた統計的なアイデアに関して xkcd.com に、思慮深い解説の信頼できるソースとしてブログ Simply Statistics に、世の中に(少なくともメディアに)統計をもたらしてくれたことについて FiveThirtyEight に、本稿の共同投稿を提案してくれたPhil Bournに、努力を始めてくれたことに関してASAのSteve Piersonに感謝します。
参考資料
-
Dashnow H, Lonsdale A, Bourne PE (2014) Ten simple rules for writing a PLOS ten simple rules article[PLOSの10個のシンプルなルールの記事を書くための10個のシンプルなルール]. PLoS Comput Biol 10(10): e1003858. doi: 10.1371/journal.pcbi.1003858. pmid:25340653
* 記事
* PubMed/NCBI
* Google Scholar ↩ ↩ -
Leek JT (2015) The Elements of Data Analytic Style[データ分析方法の要素]. Leanpub, https://leanpub.com/artofdatascience ↩
-
Peng R (2014) The Art of Data Science[データサイエンスの技術]. Leanpub, https://leanpub.com/artofdatascience . ↩
-
Kass RE, Eden UT, Brown EN (2014) Analysis of Neural Data[ニューラルデータの分析]. Springer: New York. ↩
-
Tukey JW (1962) The future of data analysis[データ分析の未来]. Ann Math Stat 33: 1–67. doi: 10.1214/aoms/1177704711
* 記事
* PubMed/NCBI
* Google Scholar ↩ -
Yu B (2013) Stability[安定性]. Bernoulli, 19(4): 1484–1500. doi: 10.3150/13-bejsp14
* 記事
* PubMed/NCBI
* Google Scholar ↩ -
Harford T (2015) Big Data: are we making a big mistake? [ビッグデータ:私たちは大きな間違い犯しているのか?]. Significance 11: 14–19. doi: 10.1111/j.1740-9713.2014.00778.x
* 記事
* PubMed/NCBI
* Google Scholar ↩ -
Fisher RA (1938) Presidential address[会長挨拶]. Sankhyā 4: 14–17.
* 記事
* PubMed/NCBI
* Google Scholar ↩ -
Cox DR (2015) Big data and precision[ビッグデータと精度]. Biometrika 102: 712–716. doi: 10.1093/biomet/asv033
* 記事
* PubMed/NCBI
* Google Scholar ↩ -
Meng XL (2014) A trio of inference problems that could win you a Nobel prize in statistics (if you help fund it)[(出資して統計学の部門ができれば)統計学でノーベル賞を取れるかもしれない3つの推論の課題]. In: Lin X, Genest C, Banks DL, Molenberghs G, Scott DW, Wang J-L,editors. Past, Present, and Future of Statistical Science, Boca Raton: CRC Press. pp. 537–562. ↩ ↩
-
Gelman A, Loken E (2014) The statistical crisis in science[科学における統計学の危機]. Am Sci 102: 460–465 doi: 10.1511/2014.111.460
* 記事
* PubMed/NCBI
* Google Scholar ↩ -
Aschwanden C (2015) Science isn’t broken[科学は壊れていない]. August 11 2015
http://fivethirtyeight.com/features/science-isnt-broken/ ↩ -
Wasserstein RL, Lazar NA (2016) The ASA’s statement on p-values: context, process, and purpose[ASAによるp値に関する声明:コンテキスト、プロセス、目的], The American Statistician doi: 10.1080/00031305.2016.1154108.
* 記事
* PubMed/NCBI
* Google Scholar ↩ -
Benjamini Y, Hochberg Y (1995) Controlling the false discovery rate: a practical and powerful approach to multiple testing[偽発見率の操作:多重検定への実践的かつ強力なアプローチ]. J R Statist Soc B 57: 289–300
* 記事
* PubMed/NCBI
* Google Scholar ↩ -
Yu, B (2015) Data wisdom for data science[データサイエンスのためのデータの知恵]. April 13 2015 http://www.odbms.org/2015/04/data-wisdom-for-data-science/ ↩
-
Goodman A, Pepe A, Blocker AW, Borgman CL, Cranmer K, et al. (2014) Ten simple rules for the care and feeding of scientific data[科学的データへの留意と投入に関する10のシンプルなルール]. PLoS Comput Biol 10(4): e1003542. doi: 10.1371/journal.pcbi.1003858. pmid:24763340
* 記事
* PubMed/NCBI
* Google Scholar ↩ -
Leisch F (2002) Sweave: Dynamic generation of statistical reports using data analysis[データを用いた統計的レポートのダイナミックな生成]. In Härdle W, Rönz H, editors. Compstat: Proceedings in Computational Statistics[計算機統計学の方法], Heidelberg: Springer-Verlag, pp. 575–580. ↩
-
Xie Y (2014) Dynamic Documents with R and knitr[Rとknitrを使ったダイナミックなレポート作成]. Boca Raton: CRC Press. ↩
-
Pérez F, Granger BE (2007) IPython: A system for interactive scientific computing[IPython:相互的な計算機統計学のシステム]. Comput Sci Eng 9 (3), 21–29. doi: 10.1109/mcse.2007.53
* 記事
* PubMed/NCBI
* Google Scholar ↩ -
Baker M (2016) Statisticians issue warning over misuse of P values[p値の誤用を警告する統計学者の課題]. Nature 531, (151) doi: 10.1038/nature.2016.19503.
* 記事
* PubMed/NCBI
* Google Scholar ↩

株式会社リクルート プロダクト統括本部 プロダクト開発統括室 グループマネジャー 株式会社ニジボックス デベロップメント室 室長 Node.js 日本ユーザーグループ代表
- X: @yosuke_furukawa
- Github: yosuke-furukawa
関連記事