2017年5月24日
確率的データ構造の比較:カッコウフィルタ対ブルームフィルタ
本記事は、原著者の許諾のもとに翻訳・掲載しております。
確率的データ構造は少ないメモリでデータをコンパクトに保存し、保存されたデータに関するクエリに対し、おおよその答えを提供してくれます。クエリに対し空間効率の良い方法で答えるように設計されており、それはつまり、正確さを犠牲にするということにもなります。しかし、これらは一般的に、問われているデータ構造の仕様にもよりますが、誤差率の保証と境界を提供してくれます。メモリ使用量が少ないため、確率的データ構造はストリーミングや低出力の設定に特に有用なのです。ですから、動画の視聴回数を数えたり、過去に投稿された一意となるツイートのリストを維持したりするなど、ビッグデータの環境下では非常に有用です。例えば、 HyperLogLog++ 構造 は、2.56KBのメモリで最大790億の一意のアイテムを数えることができるのですが、誤差率はわずか1.65パーセントです。
Fast Forward Labsのチームは、『リアルタイムストリームのための確率論手法』のレポートとプロトタイプを活用して確率的データ構造を詳しく調査しました(この話題に興味があれば、連絡をください)。この記事では、標準的なブルームフィルタを改良した 新しい 確率的データ構造であるカッコウフィルタを調査することによってアップデートされた内容を紹介します。カッコウフィルタには、いくつかの利点があります。1) 要素の動的な削除と追加を可能にする。2) 同じような機能を持つブルームフィルタのバリアントと比べて、実装が容易である。3) 特に容量が小さい場合には、似たような空間の制限の下では、カッコウフィルタは偽陽性を出す可能性が低い。ここではカッコウフィルタをPythonで実装し、それをカウンティング・ブルームフィルタ(ブルームフィルタの変形)と比較します。
アプリケーション
難解に思えますが、確率的データ構造は非常に役立つものです。例えば、大きなスケールのインターネットアプリケーションであるTwitterは、新規ユーザを確保し続けるために奮闘しています。この問題に取り組むため、Twitterの普及・エンゲージメントチームは、新規ユーザとあまり熱心に利用していないユーザの両方に、もっと頻繁にTwitterを利用してもらうようマーケティングキャンペーンを展開しています。このキャンペーンを補助するために、全ての新規ユーザをカッコウフィルタに追加することができます。ユーザがアクティブになるとそのユーザは除外され、エンゲージメントチームは現在カッコウフィルタに含まれているユーザに的を絞って促進キャンペーンを行うことができるのです。カッコウフィルタは、ユーザのアクティビティレベルに応じて、ユーザを追加したり削除したりできます。カッコウフィルタは実装が簡単なので、このユースケースでは適した方法と言えます。何億人ものユーザがいても、メモリ使用量が少なく、低い偽陽性率で処理できるのです。
“カッコウ”という名前が意味するもの
ブルームフィルタと同様に、カッコウフィルタもある要素が集合のメンバであるかをテストするための確率的データ構造です。”カッコウ”という名前は、フィルタの基盤ストレージ構造としてカッコウハッシュテーブルを使うことからきています。カッコウハッシュテーブルという名前は、鳥の カッコウ が行う 托卵 に似たふるまいをするように設計されていることから名づけられました。カッコウは他の鳥の巣の中に卵を産むことで知られています。そして卵が孵化すると、カッコウのヒナは巣の持ち主の卵を排除してしまうのです。カッコウハッシュテーブルはこれと似た方法で、使用されている”バケット”の中に要素を挿入するのです。この方法については後ほど、カッコウフィルタの項目で説明します。カッコウフィルタについて知る前に、ブルームフィルタについてざっと確認しておきましょう。
ブルームフィルタの概要
ブルームフィルタ は、集合のメンバシップの空間効率の良いテストを可能にする一般的な確率的データ構造です。例えば、ツイートのリアルタイムストリームを監視する際、ブルームフィルタによってツイートが最新のものであるのか、それとも繰り返しのものであるかをテストすることができます。ブルームフィルタでは、ハッシュ関数を使い、整数として要素をコンパクトにエンコードします。エンコードされた要素は、その時に設定されたビット配列のインデックスとして扱われます。要素が繰り返し使われているのか、そうでないのかをテストするには、ブルームフィルタで要素をハッシュし、そのインデックス一式を生成します。そして生成された各インデックスが、以前に設定されたものなかどうかの確認を行います。同じインデックスに対して、複数の要素をハッシュすることが可能なので、メンバシップテストは、偽もしくはおそらく新しい要素であるのどちらかを返してきます。つまり、ブルームフィルタでは偽陰性が生じることはないのですが、制御可能な偽陽性率が生じるということになります。要素が繰り返し使われているものではないとブルームフィルタが示した場合、その結果は正しいと考えることができますが、逆に繰り返し使われていると示した場合、間違っている(偽陽性)可能性があります。
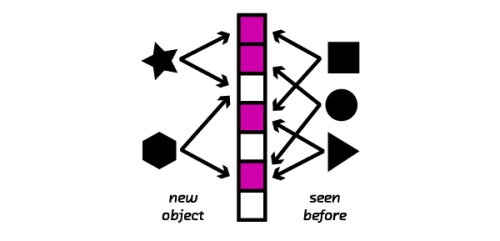
注釈:新しい要素、繰り返し使われている要素
従来のブルームフィルタでハッシングを行う際、情報の損失を伴ったり、元の状態に戻せなかったりという点から、要素を削除することができません。つまり、削除には全フィルタを構築しなおすという作業が必要になってきてしまいます。しかし、上記で挙げたTwitterに投稿された特定のツイートの例のように、繰り返し使われている要素を削除したい場合どうしたらいいのでしょう? この問題を解決するために、カウンティング・ブルームフィルタが導入されました。カウンティング・ブルームフィルタでは、従来のブルームフィルタ内にあるバケットを1ビットからnビットのカウンタに拡張して削除を行えるようになっています。つまり、ブルームフィルタのインデックスを設定するよりも、インクリメントを挿入した方が良いということです。
カッコウフィルタ
要素の削除が要求される場合、ブルームフィルタの代わりにカッコウフィルタを使うこともできます。このフィルタは 2014年 にFan氏らによって発表されました。カウンティング・ブルームフィルタ同様、カッコウフィルタでは、挿入、削除、検索を行うことができるのですが、ブルームフィルタとは異なった基本データ構造や挿入方法を使用しています。
カッコウフィルタは、挿入された要素の”フィンガープリント”を格納する カッコウハッシュテーブル で成り立っており、要素のフィンガープリントは、その要素のハッシュから派生したビット文字列です。カッコウハッシュテーブルは、バケットの配列で構成されており、バケットに挿入された要素は、2つのハッシュ関数に基づいて収容可能な2つのバケットへとマッピングされます。各バケットは、フィンガープリントの変数を格納するように設定することができ、通常、カッコウフィルタは、そのフィンガープリントとバケットのサイズで識別されます。例えば、(2,4)というカッコウフィルタでは、2ビットの長さのフィンガープリントを格納し、カッコウハッシュテーブル内の各バケットには、最大4つのフィンガープリントを格納することができます。上述の2014年に発表された 論文 を受けて、私たちはカッコウフィルタを Python で実装しました。以下のコードは、カッコウフィルタを初期化し、簡単な挿入と削除のテストを行うものです。パフォーマンスを比較するために、カウンティング・ブルームフィルタも実装しました。
from cuckoofilter import CuckooFilter
c_filter = CuckooFilter(10000, 2) #容量とフィンガープリントのサイズを指定するc_filter.insert("James")
print("James in c_filter == {}".format("James" in c_filter))
# James in c_filter == True
c_filter.remove("James")
print("James in c_filter == {}".format("James" in c_filter))
# James in c_filter == Falsefrom cuckoofilter import CountingBloomFilter
b_filter = CountingBloomFilter(10000) #カウンティング・ブルームフィルタの容量を指定する
b_filter.add("James")
print("James in b_filter == {}".format("James" in b_filter))
# James in b_filter == True
b_filter.remove("James")
print("James in b_filter == {}".format("James" in b_filter))
# James in b_filter == Falseカッコウフィルタへの挿入
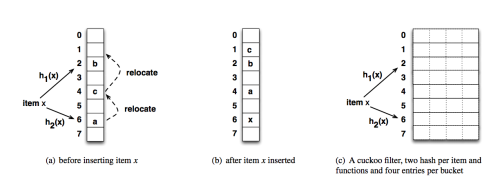
注釈:(a) 要素xを挿入する前、(b) 要素xを挿入した後、(c) カッコウフィルタ:各要素に2つのハッシュと関数、各バケットに4つのエントリ
カッコウフィルタは、挿入、削除、検索の3つの操作をサポートしています。Fan氏らの論文で記述されている上記の図は、カッコウフィルタへの挿入がどのように機能するかを示しています。カッコウフィルタのあらゆる操作では、挿入操作が最も使用されています。カッコウフィルタに要素を挿入するためには、ハッシュとそのフィンガープリントに基づいた要素から、2つのインデックスを取得します。その後、これらのインデックスを取得するとすぐに、得られたインデックスに対応する収容可能な2つのバケットのうちの1つへと要素のフィンガープリントを挿入します。私たちの実装では、最初のインデックスを初期値としました。
カッコウハッシュテーブルが満たされ始めると、要素が挿入されるべき収容可能な2つのインデックスに空きがないという状況に直面します。この場合、この時点でカッコウハッシュテーブルにある要素は、新しい要素を挿入するために必要な空間を解放すべく、他のインデックスと交換させられます。この方法で挿入を実装することによって、収容可能な2つのインデックスのうちの1つにあるフィンガープリントを調べ、そのフィンガープリントが存在するのであれば、簡単にテーブルから要素を削除することができます。この挿入方法をより具体的にするために、私たちは、挿入方法を実装する以下のコードを提供しています。
#カッコウフィルタに挿入する方法のデモのための関数例
import mmh3
def obtain_indices_from_item(item_to_insert, fingerprint_size, capacity):
#文字列のハッシュ
hash_value = mmh3.hash_bytes(item_to_insert)
#ハッシュをフィンガープリントのサイズにサブセット化する
fingerprint = hash_value[:fingerprint_size]
#インデックスを導出する
index_1 = int.from_bytes(hash_value, byteorder="big")
index_1 = index_1 % capacity
#フィンガープリントからインデックスを導出する
hashed_fingerprint = mmh3.hash_bytes(fingerprint)
finger_print_index = int.from_bytes(hashed_fingerprint, byteorder="big")
finger_print_index = finger_print_index % capacity
#2番目のインデックス -> 1番目のインデックス xor ハッシュ(フィンガープリント)から導出したインデックス
index_2 = index_1 ^ finger_print_index
index_2 = index_2 % capacity
return index_1, index_2, fingerprint
def insert_into_table(table, index_1, index_2, bucket_capacity):
#now insert item into the table
if len(table[index_1]) #大まかなカッコウハッシュテーブルを作成しましょう
capacity = 10 #カッコウハッシュテーブルの容量
bucket_capacity = 4
table = [[] for _ in range(capacity)]#インデックスを取得する
index_1, index_2, fp = obtain_indices_from_item("James", 2, 10)
#"James"をテーブルに挿入しましょう
table, _ = insert_into_table(table, index_1, index_2, bucket_capacity)
print("Table after James is inserted.")
#"James"が挿入されたか見てみる
print(table)
# Jamesが挿入された後のテーブル
# [[], [], [], [], [], [], [], [], [], [b'\xc0\n']]#もう一度"James"を挿入しましょう
index_1, index_2, fp = obtain_indices_from_item("James", 2, 10)
#"James"をテーブルに挿入
table, _ = insert_into_table(table, index_1, index_2, bucket_capacity)
print("Table after James is inserted a second time.")
#再度"James"が挿入されたか見てみる
print(table)
print("\n")
# 2度Jamesが挿入された後のテーブル
# [[], [], [], [], [], [], [], [], [], [b'\xc0\n', b'\xc0\n']]
#次は違う要素を挿入しましょう
index_1, index_2, fp = obtain_indices_from_item("Henry", 2, 10)
table, _ = insert_into_table(table, index_1, index_2, bucket_capacity)
print("Table after Henry is inserted.")
#"Henry"が挿入されたか見てみる
print(table)
# Henryが挿入された後のテーブル
# [[], [], [b'\x1c\xb2'], [], [], [], [], [], [], [b'\xc0\n', b'\xc0\n']]カウンティング・ブルームフィルタに対するベンチマーキング
偽陽性率の比較
カッコウフィルタとカウンティング・ブルームフィルタを比較してみましょう。ブルームフィルタやカッコウフィルタといった確率的データ構造において重要なメトリックが偽陽性率です。挿入の項目で示したように、カッコウフィルタとブルームフィルタの各内部での働きが異なることを考えると、これらを比較することは容易ではありません。偽陽性率の問題に対処すべく、両フィルタの空間割り当てを修正し、偽陽性率の変化を観測するために、容量に変化を与えました。以下の図は、両データ構造の容量に対する偽陽性率をグラフ化したものです。
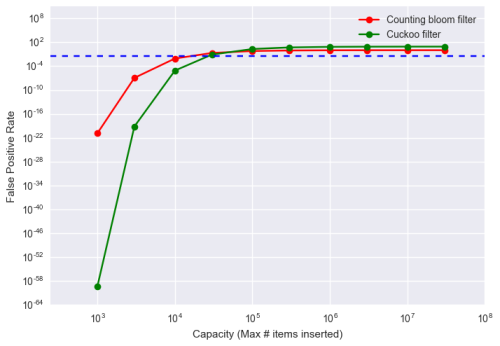
注釈:偽陽性率、容量(挿入された要素の最大値)
グラフを見て分かるように、カッコウフィルタにおける主な優位性は、空間を修正した場合に少ない容量でより低い偽陽性率になることです。原論文に記されている通り、3パーセント以下の偽陽性率(青い点線)が要求されるアプリケーションでは、カッコウフィルタがとりわけ理想的であると言えます。注目すべきは、この場合のカッコウフィルタは、単純に空間の最適化を行わずに実装を行っているということです。つまりこれは、最適化されたブルームフィルタと比較すると、調整を行っていないカッコウフィルタの方がより良いパフォーマンスを発揮することになります。カウンティング・ブルームフィルタとカッコウフィルタを比較したその他のパフォーマンスの評価テストは、こちらの ノートブック をご覧ください。
挿入時のスループットの比較
その他に考慮すべき重要なメトリックは、挿入時のスループットです。挿入時のスループットとは、既存のフィルタに要素を挿入する際にかかる時間を指します。カウンティング・ブルームフィルタの設計上、要素をフィルタに挿入する時間は、フィルタが満たされても変化がありません。しかし、カッコウフィルタでは、フィルタが容量を満たしていくにつれ、フィルタに要素を挿入する時間が増していきました。もし、要素がカッコウテーブルに挿入され、可能性のあるインデックスの両方に空きがない場合、今ある要素は、挿入されようとしている要素の空きを解放するために他のインデックスと交換されるのです。カッコウテーブルが満たされると、通常、より多くの交換が発生することになり、より多くの要素が他に移動されることになります。
以下の図では、同じ容量、同じ占有率の下で、カウンティング・ブルームフィルタとカッコウフィルタの挿入時間を示したものです(詳しくは ノートブック をご覧ください)。カッコウフィルタでは、80パーセントの占有率であった場合、最大85パーセントまで挿入のスループットが増加したのに対し、カウンティング・ブルームフィルタでは、一貫して安定したスループットを保っていました。また、カッコウフィルタの挿入のスループットが顕著に増加しているにもかかわらず、カッコウフィルタは全範囲にわたって、カウンティング・ブルームフィルタよりも3倍速いことが、この図から見て取れます。このように違いがはっきりと示されたとは言え、カウンティング・ブルームフィルタは、最適化することによってカッコウフィルタと同等の挿入速度を提供することができます。ここでは、カッコウフィルタの容量が満たされている場合に起こる、挿入時のスループットの明らかな変化を強調しようとしたにすぎません。
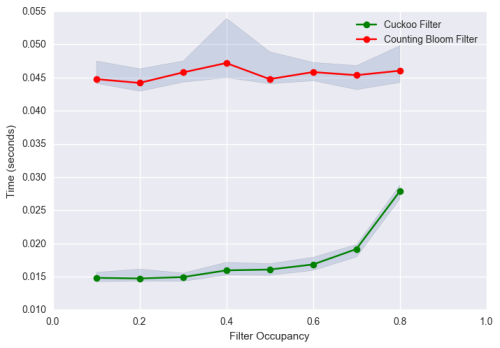
注釈:時間(秒)、フィルタの占有率
まとめ
ブルームフィルタやブルームフィルタの変形から、ストリーミングによるアプリケーションやメンバシップテストが重要とされる場合においては、このフィルタが役に立つことが証明されました。この記事では、単純に実装が可能なカッコウフィルタが、特定の状況下において、追加設定や調整をせずにカウンティング・ブルームフィルタよりも、より良い実質的なパフォーマンスを発揮することを紹介しました。結論として、通常カウンティング・ブルームフィルタが使用される場合でも、他の選択肢としてカッコウフィルタを使用することができます。

株式会社リクルート プロダクト統括本部 プロダクト開発統括室 グループマネジャー 株式会社ニジボックス デベロップメント室 室長 Node.js 日本ユーザーグループ代表
- X: @yosuke_furukawa
- Github: yosuke-furukawa
関連記事