2023年5月31日
フロントエンドパフォーマンスのチェックリスト2021年版(PDF、Apple Pages、MS Word)-前編

本記事は、原著者の許諾のもとに翻訳・掲載しております。
クイックサマリー:2021年のWebパフォーマンスを高速化しましょう。 毎年恒例のフロントエンドパフォーマンスのチェックリスト(PDF、Apple Pages、MS Wordに対応)は、指標やツールからフロントエンドのテクニックに至るまで、現代のWebで高速なユーザ体験を生み出すために知る必要があるすべてを提供します。 このチェックリストは2016年から更新を続けてきました。 メールのニュースレターでも、フロントエンドに関する便利な情報をご確認いただけます。
none
Webパフォーマンスは厄介な代物だと思いませんか。 どうすれば現在のパフォーマンスを実際に知ることができるのでしょう。 いったい何がパフォーマンスのボトルネックになっているのでしょうか。 読み込みに時間がかかるJavaScriptか、表示が遅いWebフォントか、サイズが大きい画像か、それとも緩慢なレンダリングでしょうか。 果たして私たちは、ツリーシェイキング、スコープホイスティング、コード分割による最適化や、インターセクションオブザーバー、プログレッシブハイドレーション、クライアントヒント、HTTP/3、サービスワーカー、さらにはエッジワーカーによる、手の込んだ読み込みパターンを使用した最適化を十分に行っているでしょうか。 そして最も重要な点として、いったいどこからパフォーマンス改善に手をつけ、どのように長期にわたってパフォーマンスを重視する文化を確立すればよいのでしょうか。
かつては、パフォーマンスは通常、あくまで後で考えるものでした。 プロジェクトの最後の最後まで後回しにされた結果、最小化、連結、アセットの最適化に加え、 場合によりサーバのconfigファイルにいくつかの微調整を加えるだけで済むことが珍しくありませんでした。 いま振り返ってみると、状況はずいぶん変わったように感じられます。
パフォーマンスは単なる技術的な問題ではありません。 アクセシビリティやユーザビリティから検索エンジン最適化に至るまで、あらゆる要素に影響を与えます。 パフォーマンスをワークフローに組み込むならば、デザインはパフォーマンスへの影響を考慮して決定する必要があります。 パフォーマンスは継続的に測定、監視、改良しなければなりません。 さらに、Webの複雑性が高まることによって新たな課題が生まれ、指標の追跡が困難になっています。 なぜなら、端末、ブラウザ、プロトコル、ネットワークのタイプとレイテンシによってデータが大きく変わるからです(CDN、ISP、キャッシュ、プロキシ、ファイアウォール、ロードバランサ、サーバのすべてがパフォーマンスに関係します)。
それでは、プロジェクトの最初からWebサイトの最終リリースまで、パフォーマンスを改善するときに考慮すべきことをすべてまとめた全体像を作成するとしたら、どのようなものになるでしょうか。 以下に(なるべく偏りがなく客観的な)フロントエンドパフォーマンスのチェックリスト2021年版を紹介します。 高速な反応時間と円滑なユーザインタラクションを確保し、Webサイトがユーザの帯域幅を奪わないようにするために、考慮する必要がある項目の最新情報をまとめました。
目次#
前編
- 準備段階:計画と指標
パフォーマンスを重視する文化、Core Web Vitals、パフォーマンスのプロファイル、CrUX、Lighthouse、FID、TTI、CLS、端末。 - 現実的な目標の設定
パフォーマンスバジェット、パフォーマンス目標、RAILフレームワーク、170KB/30KBバジェット。 - 環境の定義
フレームワークの選択、パフォーマンスコストの基準設定、Webpack、依存関係、CDN、フロントエンドアーキテクチャ、CSR、SSR、CSR + SSR、静的レンダリング、プリレンダリング、PRPLパターン。
中編
- アセットの最適化
Brotli、AVIF、WebP、レスポンシブ画像、AV1、アダプティブメディア読み込み、動画圧縮、Webフォント、Googleフォント。 - ビルドの最適化
JavaScriptモジュール、モジュール/ノーモジュールのパターン、ツリーシェイキング、コード分割、スコープホイスティング、Webpack、デファレンシャルサービング、Webワーカー、WebAssembly、JavaScriptバンドル、React、SPA、パーシャルハイドレーション、インポート・オン・インタラクション、サードパーティ、キャッシュ
後編
- デリバリの最適化
遅延読み込み、インターセクションオブザーバー、遅延レンダリングとデコーディング、クリティカルCSS、ストリーミング、リソースヒント、レイアウトシフト、サービスワーカー。 - ネットワーク接続、HTTP/2、HTTP/3
OCSPステープリング、EV/DV証明書、パッケージング、IPv6、QUIC、HTTP/3。 - テストとモニタリング
監査ワークフロー、プロキシブラウザ、404ページ、GDPRに基づくcookie同意プロンプト、パフォーマンス診断CSS、アクセシビリティ。 - 手軽に成果を上げる
- チェックリストのダウンロード(PDF、Apple Pages、MS Word)
- さあ、始めよう!
(チェックリストのPDFファイル(166KB)、編集可能なApple Pagesファイル(275KB)、.docxファイル(151KB)も自由にダウンロードできます。皆さんが最適化を楽しめますように!)
準備段階:計画と指標 #
細かい最適化はパフォーマンスを維持するにはとても重要ですが、明確な目標を念頭に置くことも必要不可欠です。 測定可能な目標を定め、プロセス全体を通したすべての意思決定に反映させるようにしましょう。 目標設定に関してはいくつもの異なるモデルがあり、以下で紹介するモデルは筆者の独断によるものです。 早いうちに自分が何を優先するかを決めるようにしましょう。
01. パフォーマンスを重視する文化を確立する。
多くの組織において、フロントエンドの開発者は、共通する基本的な問題が何であるかや、それを修正するためにどんな戦略を採用すべきかをはっきりと把握しています。 しかし、パフォーマンスを重視する文化がしっかりと確立されていないと、意思決定のたびに部門同士で争いが起き、分断化した組織になってしまいます。 開発を進めるには、ビジネスのステークホルダーの支持が必要です。 支持を得るには、速度(特に、後で詳しく説明するCore Web Vitals)の向上が、ステークホルダーが関心を持っている基準や重要業績評価指標(KPI)にプラスの影響を与えるというケーススタディ、すなわち概念実証(PoC)を確立しなければなりません。
パフォーマンス向上のメリットをより明確にする手段として、例えばコンバージョン率と、アプリケーション読み込み速度やレンダリングのパフォーマンスの相関を明らかにし、収益パフォーマンスへの影響を示すことができます。 あるいは、サーチボットのクローリング率(PDF、27~50ページ)を利用しても良いでしょう。
開発/デザインチームと業務/マーケティングチームの方向性がしっかりと一致していなければ、パフォーマンスを長く維持することはできません。 カスタマーサービスと営業チームによく寄せられる苦情を精査し、直帰率が高い場合やコンバージョン率が低下した場合は詳しく分析しましょう。 そして、パフォーマンスの向上によって、こうしたよくある問題を軽減することができないか調べてみましょう。 どのステークホルダーと話すのかに応じて、主張の内容を調整することも必要です。
モバイルとデスクトップの両方でパフォーマンス実験を行い、結果を測定してみましょう(例えば、Google Analyticsなどを利用できます)。 こうした実験は、現実のデータに基づき、自社に合ったケーススタディを構築するのに役立ちます。 さらに、WPO Stats上で公表されたケーススタディと実験データを利用することで、なぜパフォーマンスが重要なのか、それがユーザ体験と業績指標にどのような影響を与えるのか、これらに対する企業の感性が磨かれます。 ただし、パフォーマンスが重要だと主張するだけでは不十分です。 測定と追跡が可能な目標を定め、それを継続的に観測する必要があります。
そのためには、どうすればよいのでしょうか。Allison McKnightは、長期的なパフォーマンスの向上に関する講演の中で、Etsyにおいてパフォーマンスを重視する文化の確立をどのように促進したかに関する包括的なケーススタディを紹介しています(スライド)。 最近では、Tammy Evertsが、小規模な組織と大規模な組織の両方で非常に高いパフォーマンスを上げるチームの習慣について語っています。
こうした対話を組織内で実施するときは、UXがさまざまな体験のスペクトルであるのと同様に、Webパフォーマンスにも幅があるという点に留意するのが重要です。 Karolina Szczurが述べているとおり、「1つの数値だけが望ましい評価をもたらすと考えるのは誤っています」。 したがって、パフォーマンスに関する目標は、きめ細かく、追跡可能で、目に見えるものである必要があります。
![]() モバイルでは、ユーザが体験する読み込み時間が速い場合、セッション当たりの収益は平均と比べて17%増加します。(Addy OsmaniによるImpact of Web Performanceからの引用)
モバイルでは、ユーザが体験する読み込み時間が速い場合、セッション当たりの収益は平均と比べて17%増加します。(Addy OsmaniによるImpact of Web Performanceからの引用)
 1つの数値だけが望ましい評価をもたらすと考えるのは誤っています。(画像の出典:Karolina CzczurによるPerformance is a distributionからの引用)
1つの数値だけが望ましい評価をもたらすと考えるのは誤っています。(画像の出典:Karolina CzczurによるPerformance is a distributionからの引用)
02. 目標:最も速い競合サイトよりも20%以上速くなることを目指す。
心理学的な調査によれば、ユーザがあなたのWebサイトを競合サイトよりも速いと感じるには、比較対象との速度差が20%以上で速くなければなりません。 主要な競合サイトを調べ、こうしたサイトのモバイルとデスクトップにおけるパフォーマンス関連の指標を収集し、それらを上回るための基準値を設定しましょう。 ただし、正確な成果や目標を定めるには、まず自社サイトの分析を精査し、ユーザ体験の全体像を把握する必要があります。 その後は、90パーセンタイル値に相当するユーザ体験を再現し、テストしてみましょう。
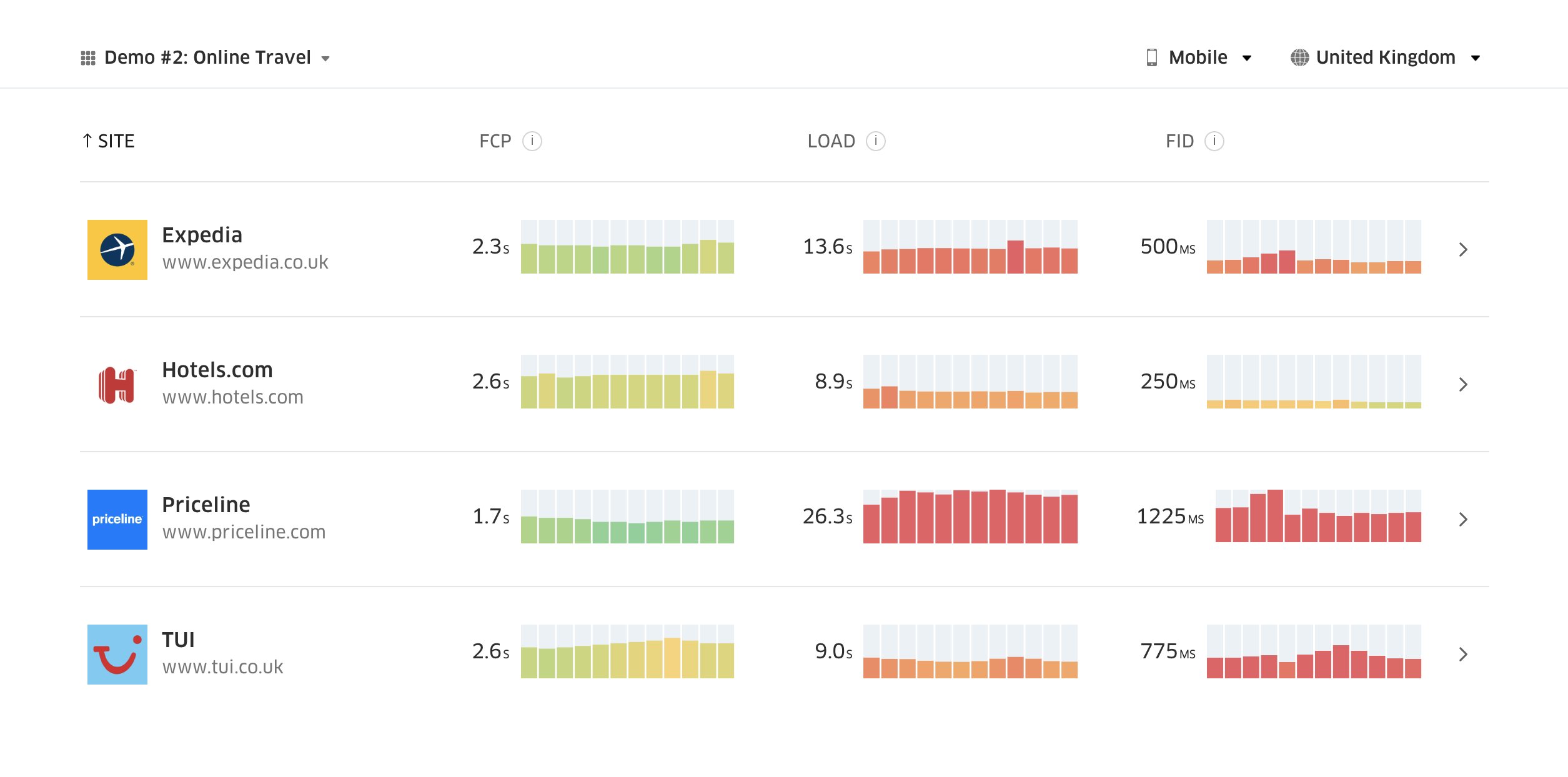
競合サイトのパフォーマンスを把握する最初の一歩として、Chrome UX Report(CrUX。既製のRUMデータセット。Ilya Grigorikの動画による紹介はこちら、Rick Viscomiによる詳細なガイドはこちら)や、Chrome UX Reportに基づくRUMモニタリングツールであるTreoを利用することができます。 データはChromeブラウザのユーザから収集されるため、レポートはChrome固有のものとなりますが、幅広い訪問者に関して、とても詳細なパフォーマンスの分布(最も重要なのはCore Web Vitalsのスコア)を知ることが可能です。 なお、新たなCrUXデータセットは毎月第2火曜日に公表されます。
他にも以下を利用することができます。
- Addy OsmaniのChrome UX Report Compare Tool
- Speed Scorecard(収益への影響の推定も可能)
- Real User Experience Test Comparison
- SiteSpeed CI(合成テストに基づく)
注記:Page Speed InsightsやPage Speed Insights API(非推奨とはなっていません)を使用する場合、CrUXのパフォーマンスデータは、単なる合計値ではなく特定ページのデータを取得できます。 このデータは、「ランディングページ」や「商品一覧」などのアセットにパフォーマンス目標を設定するときには、合計値よりもはるかに役立つ可能性があります。 バジェットのテストにCIを使用する場合において、CrUXを目標設定に使用したときは、テスト対象の環境がCrUXと一致するようにしてください(Patrick Meenanに感謝します)。
速度を重視する理由を示すのに助けが必要な場合、パフォーマンス不良遅いパフォーマンスによるコンバージョン率の低下や直帰率の上昇を可視化したい場合、あるいは組織内でRUMソリューションを提唱する必要がある場合は、Sergey Chernyshevが開発したUX Speed Calculatorを利用しましょう。 このオープンソースのツールは、データをシミュレーションし、可視化することで、あなたの意見を理解してもらうのに役立ちます。
 CrUXは、Google Chromeのユーザからトラフィックを収集し、時系列のパフォーマンス分布の概要を作成します。Chrome UXダッシュボードで独自のCrUXを作成することが可能です。(プレビューを拡大)
CrUXは、Google Chromeのユーザからトラフィックを収集し、時系列のパフォーマンス分布の概要を作成します。Chrome UXダッシュボードで独自のCrUXを作成することが可能です。(プレビューを拡大)
 あなたの意見を理解してもらうために、パフォーマンスに関する証拠が必要なときは、UX Speed Calculatorが便利です。これは実際のデータに基づき、パフォーマンスが直帰率、コンバージョン率、合計収益に与える影響を可視化します。(プレビューを拡大)
あなたの意見を理解してもらうために、パフォーマンスに関する証拠が必要なときは、UX Speed Calculatorが便利です。これは実際のデータに基づき、パフォーマンスが直帰率、コンバージョン率、合計収益に与える影響を可視化します。(プレビューを拡大)
時には、もっと詳しいデータが欲しいこともあるでしょう。 CrUXのデータを、すでに持っている他のデータと組み合わせ、競合サイトや自社プロジェクトのどこでパフォーマンスが遅くなり、どこに盲点があり、非効率な部分があるのかを迅速に見つけ出したい場合です。Harry Robertsは、自分の仕事にSite-Speed Topographyスプレッドシートを利用しています。 彼はこのスプレッドシートを、主要なページの種類ごとにパフォーマンスを分析し、主要指標がどのように変わるかを追跡するのに使っています。 Google Sheets、Excel、OpenOfficeドキュメント、CSV形式でスプレッドシートをダウンロードできます。
 Topography。主要指標がサイトの主なページごとに表示されている。(プレビューを拡大)
Topography。主要指標がサイトの主なページごとに表示されている。(プレビューを拡大)
徹底的に追求したい場合は、(Lighthouse Paradeを通じて)サイトのすべてのページに対してLighthouseのパフォーマンス監査を実施することができます。結果はCSV形式で保存可能です。 これは、競合サイトのどの特定のページ(またはページのタイプ)のパフォーマンスが悪い(または優れている)かや、何に重点的に取り組むべきかを特定するのに役立ちます(ただし、自社サイトなら分析エンドポイントにデータを送信する方が良いでしょう)。
 Lighthouse Paradeを使用すれば、サイトのあらゆるページに対してパフォーマンス監査を実施し、結果をCSV形式で保存できます。(プレビューを拡大)
Lighthouse Paradeを使用すれば、サイトのあらゆるページに対してパフォーマンス監査を実施し、結果をCSV形式で保存できます。(プレビューを拡大)
このようにデータを収集し、スプレッドシート(※訳注:原文指定URL消失)を設定し、時間を20%削減することで、目標(パフォーマンスバジェット)を確立します。 これで、テストで測定を行う準備ができました。 バジェットを気にかけながら、インタラクティブになるまでの時間(TTI)を高速化するためにペイロードを最小限にしようとしている場合、これが合理的な方法であると言えます。
始めるのにリソースが必要なら、以下を利用してみましょう。
- Addy Osmaniは、パフォーマンスバジェット作成の始め方、新機能の影響を定量化する方法、バジェットを超過している場合にどこから手をつけるべきかについて、とても詳しい記事を執筆しています。
- Lara Hoganのパフォーマンスバジェットからデザインにアプローチするためのガイドは、デザイナーにとって便利なヒントを提供します。
- Harry Robertsは、Request Mapを使用して、サードパーティのスクリプトがパフォーマンスに与える影響を表示するためのGoogle Sheetsの設定ガイドを公表しています。
- Jonathan FieldingのPerformance Budget Calculatorや、Katie Hempeniusのperf-budget-calculatorとBrowser Calories(※訳注:原文指定URL消失)は、バジェット作成の助けとなります(この情報を教えてくれたKarolina Szczurに感謝します)。
- 多くの企業では、パフォーマンスバジェットは、特定のポイントを超過しないための目安となるように、野心的ではなく現実的な内容に設定すべきです。この場合、過去2週間で最悪のデータを基準値として選び、それを出発点とするのも方法の一つです。Performance Budgets, Pragmaticallyという記事では、そのための戦略が紹介されています。
- また、ビルドサイズを示したグラフ付きのダッシュボードを設定することで、パフォーマンスバジェットと現在のパフォーマンスの両方を可視化できます。そのためのツールは数多く存在しており、例を挙げるとSiteSpeed.ioダッシュボード(オープンソース)、SpeedCurve、Calibreなどがあります。perf.rocksでは、さらに多くのツールを探すことができます。
 Browser Caloriesは、パフォーマンスバジェットを設定し、ページがその数値を超過しているかどうかを測定するのに役立ちます。(プレビューを拡大)
Browser Caloriesは、パフォーマンスバジェットを設定し、ページがその数値を超過しているかどうかを測定するのに役立ちます。(プレビューを拡大)
バジェットを設定したら、Webpack Performance HintsとBundlesize、Lighthouse CI、PWMetricsやSitespeed CIを利用してビルドのプロセスに組み込み、プルリクエストに対してバジェットを実行し、PRコメントにスコアの履歴を表示するようにします。
パフォーマンスバジェットをチーム全体に浸透させるには、Lightwalletを通じてLighthouseにパフォーマンスバジェットを統合するか、LHCI Actionを使用してGitHub Actionsに手早く統合しましょう。何らかのカスタマイズが必要な場合は、webpagetest-charts-apiを利用できます。 これはWebPageTestの結果から図表を作成するエンドポイントのAPIです。
しかし、パフォーマンスバジェットだけでは、パフォーマンスに対する認識を高めることはできないでしょう。 Pinterestのように、カスタマイズされたESLintのルールを定めることで、依存関係が多く、バンドルのサイズを膨張させるファイルやディレクトリからのインポートを禁止できます。 また、チーム全体で共有できる「安全な」パッケージの一覧を設定しましょう。
さらに、ビジネスにとって最もメリットが大きい必要不可欠なカスタマータスクについて考えてみてください。 必要不可欠なアクションについて、許容できる速度の基準値に関する調査と議論を行い、その基準値を決定しましょう。 さらに、組織全体が承認した「UXを考慮した」User Timingの測定ポイントを設定しましょう。 多くの場合、ユーザジャーニーは多様な部門の業務に関係します。 そのため、許容できる速度について合意できるか次第で、今後のパフォーマンスに関する議論が促進されるか妨げられるかが変わってきます。 追加的なリソースと機能による追加コストを可視化し、把握するようにしてください。
パフォーマンスに関する取り組みと、その他の技術的な取り組み(製品の新機能の開発、リファクタリング、世界中の新たなターゲット層へのリーチなど)の整合性を取るようにしましょう。 そうすれば、今後の展開について議論をするたびに、パフォーマンスについても一緒に議論することができます。 コードベースが新しい場合や、リファクタリングされたばかりの場合は、パフォーマンス目標を達成するのがはるかに簡単になります。
また、Patrick Meenanが提案しているとおり、デザインプロセスの間に、読み込みのシーケンスとトレードオフについて計画することは考慮に値します。 早いうちに必要不可欠な部分に優先順位をつけ、それが表示される順番を定めれば、表示を遅らせて構わないものも把握できます。 この順番はCSSとJavaScriptのインポートシーケンスも反映し、ビルドプロセスでこれらを扱いやすいようにするのが理想的です。 また、ページ読み込み中の「中間」の状態(例えば、Webフォントの読み込みが終わるまで)における視覚的なユーザ体験がどのようなものであるべきかについても検討しておきましょう。
パフォーマンスを重視する強固な文化を組織内で確立したら、過去の自社サイトに比べて20%高速化することを目指し、時が経っても優先順位を忘れないようにしましょう(Guy Podjarnyに感謝します)。 ただし、顧客のタイプと利用行動がさまざまであること(Tobias Baldaufはカデンスとコホートと呼んでいます)や、ボットのトラフィックと季節的な影響も考慮してください。
とにかく計画することが大切です。プロジェクトの初期に、「手の届く所にある」最適化を即座に実行するのは魅力的で、すぐに成果を上げたい場合は良い戦略かもしれません。 しかし、計画を立てず、自社に合った現実的なパフォーマンス目標を定めない限り、パフォーマンスを優先し続けることはとても困難になるでしょう。
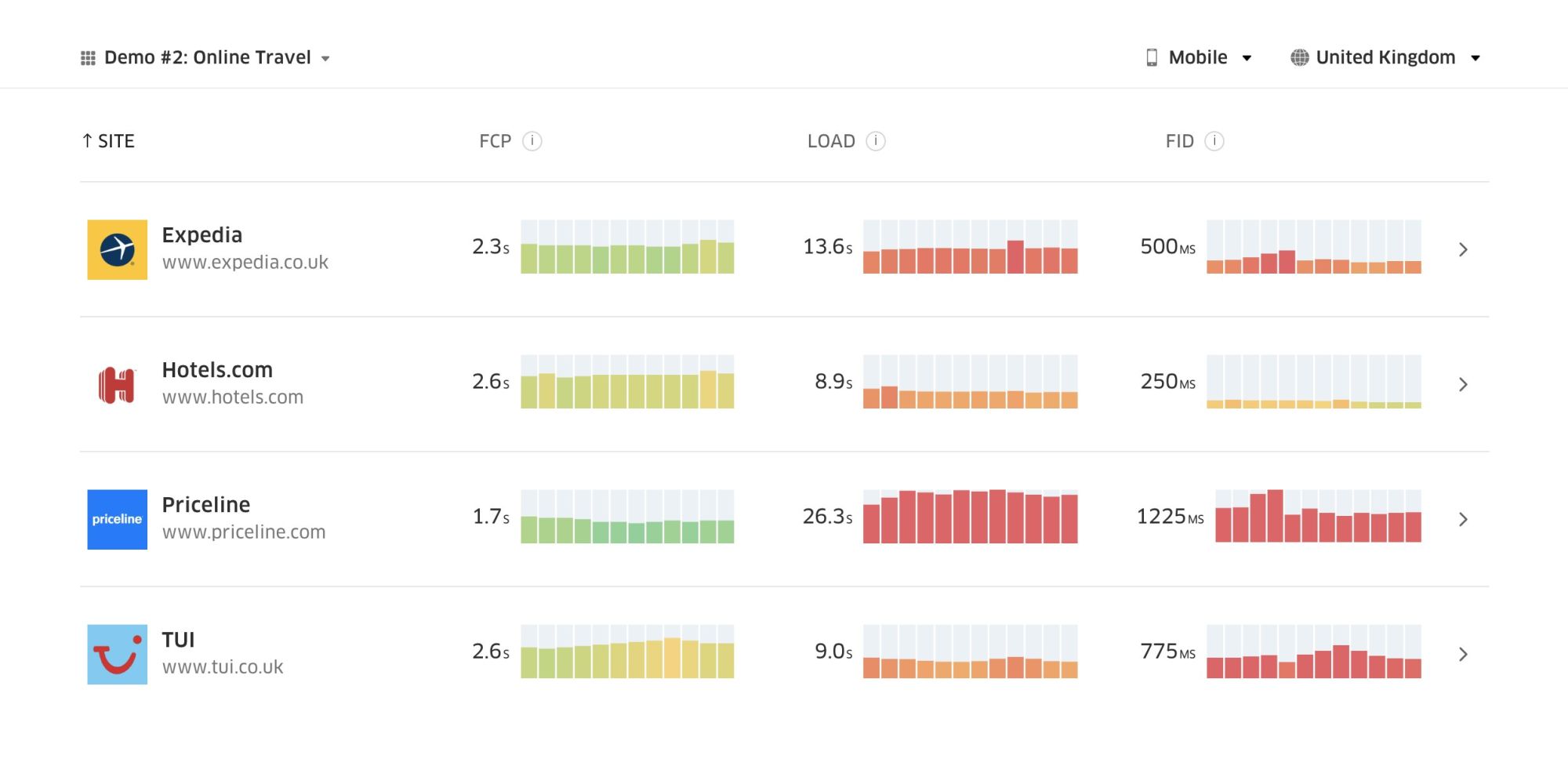 Treoは現実のデータに基づく競合分析を提供します。(プレビューを拡大)
Treoは現実のデータに基づく競合分析を提供します。(プレビューを拡大)
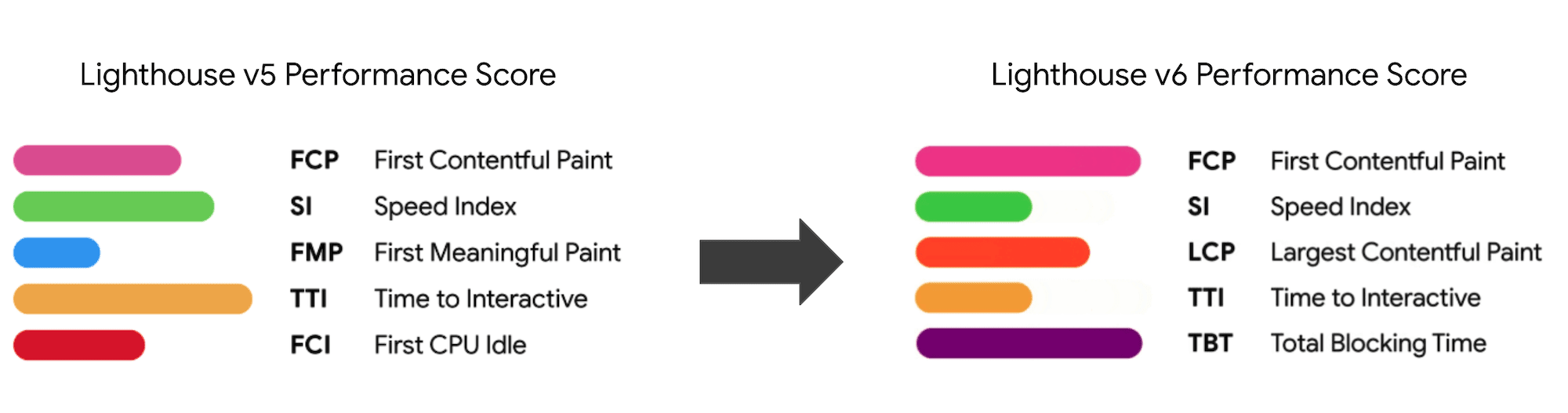
 2020年初頭に新たな指標がLighthouse v6に導入されました。(プレビューを拡大)
2020年初頭に新たな指標がLighthouse v6に導入されました。(プレビューを拡大)
03. 適切な指標を選択する。
すべての指標が同等に重要なわけではありません。 自社のアプリケーションにとって、どの指標が最も重要であるかを調査しましょう。 通常は、インターフェースの最も重要なピクセルのレンダリングをどれだけ速く開始できるかや、これらのレンダリングされたピクセルへの入力に対してどれだけ速く応答できるかが重要となります。 何が重要な指標であるかを知ることで、現在の取り組みに対する最善の最適化目標が分かります。 最終的には、ユーザ体験の決め手となるのは読み込みイベントでもサーバの応答時間でもなく、UIがどれだけサクサク動くと感じられるかです。
どういうことかというと、ページ全体の読み込み時間(例えばonLoadやDOMContentLoadedなど)に注目するよりも、顧客の印象に合わせてページの読み込みに優先順位を付けるべきだという意味です。 つまり、注目すべき指標が微妙に異なっているのです。 実際、適切な指標の選択というプロセスにおいて、明確に選択すべき指標は存在しません。
Tim Kadlecの調査と、Marcos Iglesiasの講演のメモによれば、従来の指標はいくつかのグループに分けられます。 通常、パフォーマンスを完全に把握するにはすべての指標が必要ですが、個別のケースでは一部の指標が他の指標よりも重要となります。
- 数量ベースの指標は、複数のリクエスト、ウェイト、パフォーマンススコアを測定します。 アラートを設定したり、時系列の変化をモニタリングしたりするのには向いていますが、ユーザ体験の把握には向いていません。
- マイルストーン指標(例えばTime To First ByteやTime To Interactiveなど)は、プロセスが読み込まれるまでの状態を利用します。 ユーザ体験の把握やモニタリングには向いていますが、複数のマイルストーン間で何が起きているかを把握するのには向きません。
- レンダリング指標(例えばStart Render TimeやSpeed Indexなど)は、コンテンツのレンダリングの速さの推定値を提供します。 レンダリングのパフォーマンスの測定や修正には向いていますが、重要なコンテンツが表示されるタイミングや、そのコンテンツとのインタラクションが可能になるタイミングの測定には向きません。
- カスタム指標(例えばTwitterのTime To First TweetやPinterestのPinnerWaitTimeなど)は、ユーザごとにカスタマイズされた特定のイベントを測定します。 ユーザ体験を正確に描写するのには向いていますが、指標を拡張したり、競合サイトと比較したりするのには向きません。
全体像を把握するには、通常はこれらすべてのグループの有用な指標に注目します。 一般に、最も特別な意味を持ち、重要とされる指標を以下に紹介します。
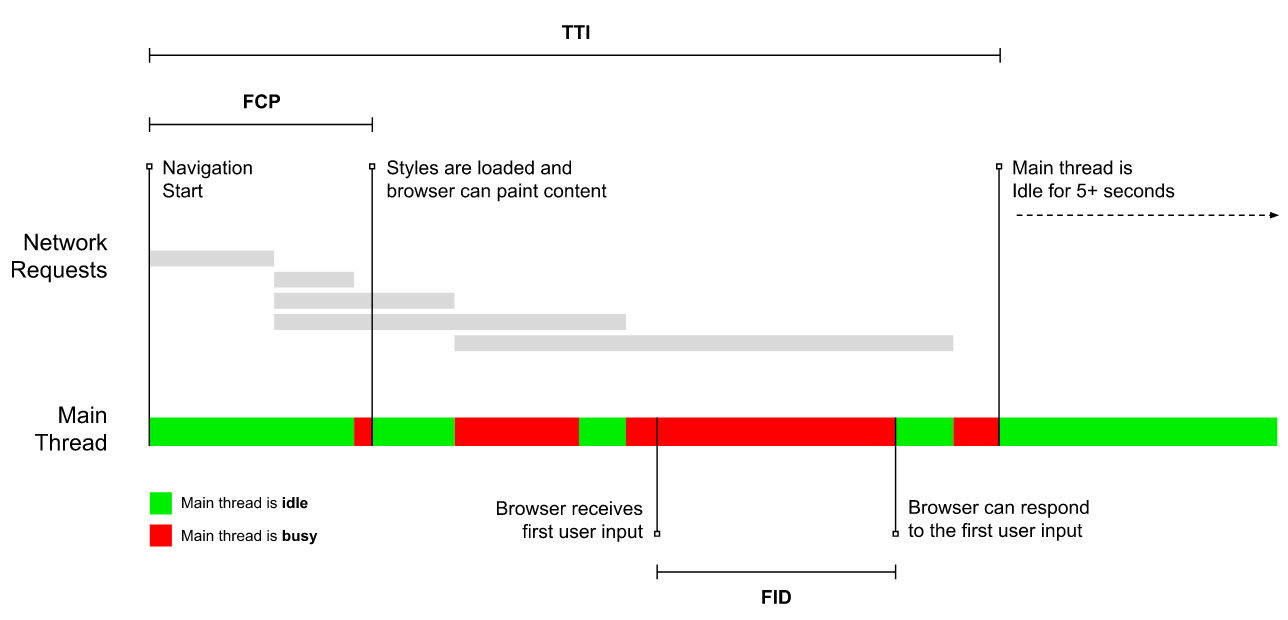
- Time to Interactive(TTI)
レイアウトが安定し、主要なWebフォントが表示され、メインスレッドがユーザの入力を十分に処理できるようになるまでの時間を表します。 つまり、ユーザとUIのインタラクションが可能になるまでの時間です。 ユーザがタイムラグなしでサイトを利用するためにどの程度待つ必要があるかを把握するための主要な指標です。 Boris Schapiraは信頼性が高いTTIの測定方法に関して詳細な記事を書いています。 - First Input Delay(FID)、またはInput responsiveness
ユーザが最初にサイトとのインタラクションを実施してから、ブラウザが実際にそのインタラクションに対して応答できるまでの時間です。 ユーザがサイトと実際にインタラクションをするときに何が起きるかを把握できるため、TTIでは捕捉できない部分を補完する指標としてとても優れています。 これはRUMの指標としてのみ使用されることを意図しています。 ブラウザでFIDを測定するためのJavaScriptライブラリも存在します。 - Largest Contentful Paint(LCP)
ページを読み込む過程において、ページの重要なコンテンツが読み込まれる可能性が高い時点を示します。 前提として、ページの最も重要な要素は、ユーザのビューポートに表示される最も大きな要素であると想定しています。 スクロールしなくても見える範囲と、スクロールしなければ見えない範囲の両方で要素がレンダリングされる場合、見える範囲の部分のみが重要とみなされます。 - Total Blocking Time(TBT)
ページとのインタラクションが確実に可能になる前の時点で、そのページとのインタラクションが不可能である度合いの深刻さを定量化することに役立つ指標です(インタラクションが確実に可能であるとは、メインスレッドに、50ミリ秒以上を要するタスク(ロングタスク)が存在しない時間が5秒以上続くことを指します)。 この指標は、最初の描画からTime to Interactive(TTI)までの間において、メインスレッドが一定時間にわたってブロックされており、入力への応答が妨げられていた時間の合計を測定するものです。 そのため、当然ながら、TBTが小さいことは良いパフォーマンスの目安となります。(ArtemとPhilに感謝します)。 - Cumulative Layout Shift(CLS)
この指標は、ユーザがサイトにアクセスしたときに、予期しないレイアウトシフト(ブラウザによるリフロー)(※訳注:ページ閲覧中に広告等の要素が読み込まれて、ガタンとコンテンツの位置がずれること)を体験する頻度を測定します。 これは、不安定な要素と、それが全体的なユーザ体験に与える影響を検証するものです。 このスコアは低いほど優れています。 - Speed Index
ページのコンテンツがどれだけ速く目に見える形で表示されるかを測定します。 スコアが低いほど優れています。 Speed Indexのスコアは、視覚的な表示の速度に基づいて計算されますが、あくまで計算上の値です。 このスコアはビューポートのサイズにも影響されるため、ターゲット層に合わせてテスト上のさまざまな設定を定める必要があります。 LCPがより重要な指標となるにつれて、Speed Indexの重要性が低下していることに注意してください(Boris(※訳注:原文指定URL消失)とArtemに感謝します)。 - CPU使用時間
メインスレッドが描画、レンダリング、スクリプティング、読み込み作業のためにブロックされた頻度と時間の長さを表す指標です。 CPU使用時間が長いことは、低品質なユーザ体験の明確な指標となります。 つまり、ユーザがアクションとレスポンスの間に、はっきりと分かるタイムラグを体験するということです。 WebPageTestでは、"Chrome"タブで"Capture Dev Tools Timeline"を選択することで、WebPageTestを使用している端末上で実行されるメインスレッドの内訳を明らかにすることができます。 - Component-Level CPU Costs
Stoyan Stefanovが提案したこの指標は、CPU使用時間と同様に、JavaScriptがCPUに与える影響を測定します。 基本的な考え方は、コンポーネント当たりのCPUインストラクションの回数を利用して、全体的なユーザ体験に対する影響を独立に把握するというものです。 PuppeteerとChromeを利用して実装できます。 - FrustrationIndex
上記の指標の多くは特定のイベントが発生したタイミングを明らかにするものですが、Tim VereeckeのFrustrationIndexは指標を個別に見るのではなく、指標の間のギャップに注目します。 これは、Title is visible、First content is visible、Visually ready、Page looks readyなどのエンドユーザが体験する主要なマイルストーンに注目し、ページ読み込み中のフラストレーションの水準を示すスコアを算出します。 ギャップが大きいほど、ユーザがイライラする可能性は高くなります。 恐らく、ユーザ体験の優れたKPIになるでしょう。 Timは FrustrationIndexとその機能に関する詳しい記事を公表しています。 - Ad Weight Impact
サイトが広告収入に依存している場合、広告関連のコードの重さを調べることは役に立ちます。 Paddy Gantiのスクリプトは、2つのURL(1つは通常のURL、もう1つは広告をブロックしたもの)を構築し、WebPageTestを通じた比較動画の作成を促し、両者の差に関するレポートを生成します。 - 偏りに関する指標
Wikipediaのエンジニアが述べているとおり、測定結果にどれだけの変動があるかというデータは、ツールをどこまで信頼すべきか、データの偏りと外れ値にどこまで注意すべきかに関して、有益な情報をもたらす可能性があります。 大きな変動は、設定を調整する必要があるというサインです。このデータは、例えばサードパーティのスクリプトが大きな変動の原因となっているなどの理由により、特定のページの測定値の信頼性が比較的低いことを把握するのにも役立ちます。 また、ブラウザの新しいバージョンが導入されたときに、パフォーマンスに支障がないか確認するために、ブラウザのバージョンを追跡するのも良い考えかもしれません。 - カスタム指標
カスタム指標は、ビジネス上のニーズと顧客体験によって決まります。 それには、重要なピクセル、不可欠なスクリプト、必要なCSS、重要なアセットを特定し、それらがユーザにどれだけ速く提供されるかを測定する必要があります。 例えば、Hero Rendering Timesをモニタリングしたり、Performance APIを使用したりすることで、ビジネスにとって重要なイベントについて特定のタイムスタンプを示すことができます。 また、テストの終了時に任意のJavaScriptを実行すれば、WebPageTestでカスタム指標を収集する(※訳注:原文指定URL消失)ことも可能です。
なお、First Meaningful Paint(FMP)が上記の概要に含まれていないことに注意してください。 FMPは、サーバが何らかのデータをどれだけ速く出力するかに関する情報を提供してきました。 FMPの時間が長いことは通常、JavaScriptがメインスレッドをブロックしていることを表していましたが、バックエンドやサーバの問題に関連している可能性もありました。 しかし、この指標は最近、約20%のケースで正確ではないとみられることが判明し、非推奨とされています。 FMPは、信頼性が高く、解釈しやすいLCPにほとんど取って代わられています。 現在はLighthouseでもサポートされていません。 最新のユーザ中心のパフォーマンス指標と推奨事項をダブルチェックし、自社のページに問題がないことを確認しましょう(Patrick Meenanに感謝します)。
Steve Soudersはこれらの指標の多くについて詳しく説明しています。 重要な点として、Time-To-Interactiveはいわゆるラボ環境で自動化された監査を実行することによって測定されますが、First Input Delayは実際のユーザ体験を示すものであり、現実のユーザがはっきりと分かるタイムラグを体験したことを意味しています。 一般的には、両方を常に測定・追跡するのが良いでしょう。
アプリケーションの状況に応じて、好ましい指標は変わる可能性があります。 例えば、Netflix TVのUIにとってはキー入力への応答性、メモリ使用、TTIが特に決定的な意味を持ち、Wikipediaにとっては、最初と最後の視覚的表示の変化と、CPU使用時間の指標がより重要となります。
注記:FIDとTTIはともに、スクロールの挙動を考慮していません。 スクロールはメインスレッド外で処理されるため、独立的に発生する可能性があります。 そのため、コンテンツを消費するサイトの多くでは、これらの指標の重要性は大幅に低くなるかもしれません(Patrickに感謝します)。
 ユーザ中心のパフォーマンス指標は、実際のユーザ体験について、優れた情報を提供します。First Input Delay(FID)は、まさにこれを実現することを目指す新たな指標です。(プレビューを拡大)
ユーザ中心のパフォーマンス指標は、実際のユーザ体験について、優れた情報を提供します。First Input Delay(FID)は、まさにこれを実現することを目指す新たな指標です。(プレビューを拡大)
 新たなCore Web Vitalsの概要。LCP < 2.5秒、FID < 100ミリ秒、CLS < 0.1(Core Web Vitals、Addy Osmaniのツイートより引用)。
新たなCore Web Vitalsの概要。LCP < 2.5秒、FID < 100ミリ秒、CLS < 0.1(Core Web Vitals、Addy Osmaniのツイートより引用)。
04. Core Web Vitalsを測定・最適化する。
長い間、パフォーマンス指標はかなり技術的なものであり、サーバがどれだけ速く応答するか、ブラウザの読み込みがどれだけ速いかといったエンジニア側の視点に重点を置いていました。 こうした指標は、サーバのタイミングではなく、実際のユーザ体験を把握する方法を見つけ出すために、時とともに変化してきました。 2020年5月、GoogleはCore Web Vitalsを発表しました。 これはユーザに重点を置いた一連の新しいパフォーマンス指標で、各指標が別個のユーザ体験の要素を表します。
各指標について、Googleは許容できる速度の範囲の推奨目標を示しています。 この評価に合格するには、すべてのページビューの75%以上で「Good」の範囲を超える必要があります。 Core Web Vitalsは急速に広まり、2021年5月にはCore Web VitalsがGoogle検索ランキングシグナルに導入されたことで(ページエクスペリエンスのランキングアルゴリズムのアップデート)、多くの企業がパフォーマンススコアに関心を向けるようになりました。
ここでは、Core Web Vitalsを一つずつ見ていくとともに、これらの指標を考慮してユーザ体験を最適化するための便利なテクニックとツールを紹介します(この記事の一般的なアドバイスに従うことで、Core Web Vitalsスコアを改善できるでしょう)。
-
Largest Contentful Paint (LCP)< 2.5秒。
ページの読み込みを測定し、ビューポートに表示される最大の画像またはテキストブロックのレンダリング時間を報告します。 したがって、LCPは、サーバ応答時間の遅さ、ブロッキングCSS、実行中のJavaScript(ファーストパーティかサードパーティかを問わない)、Webフォントの読み込み、重いレンダリングや描画作業、読み込みが遅い画像、スケルトンスクリーン、クライアントサイドのレンダリングなど、重要な情報のレンダリングを遅らせるあらゆる要素の影響を受けます。
優れたユーザ体験を実現するには、LCPは、ページの読み込みが最初に開始されてから2.5秒以内とすべきです。 これは、ページ内で最初に表示される部分を可能な限り早くレンダリングする必要があることを意味します。 そのためには、各テンプレート向けにクリティカルCSSをカスタマイズし、
<head>の順番を調整し、クリティカルなアセットを先読みすることが必要となります(これらの点については後で説明します)。LCPスコアが低い主な理由は、通常は画像です。 Fast 3Gで2.5秒未満のLCPを達成するには(十分に最適化されたサーバでホスティングし、レンダリングはすべて静的で、クライアントサイドでのレンダリングは行わず、画像は専用の画像CDNによるものである場合)、理論上の画像の最大サイズはわずか約144KBとなります。 これが画像の応答性の高さや、(preloadによる)クリティカルな画像の早期の先読みが重要である理由です。
簡単なtips:ページ上で何がLCPの対象となるかを特定するには、DevToolsのパフォーマンスパネルの"Timings"のLCPバッジにカーソルを合わせてください(Tim Kadlecに感謝します)。
-
First Input Delay(FID)< 100ミリ秒。
UIの応答性、すなわちユーザによる独立した入力イベント(タップやクリックなど)に反応できるようになる前に、ブラウザが他のタスクによってビジー状態となる時間の長さを測定します。 この指標は、メインスレッドが(特にページの読み込み中に)ビジー状態となることによる遅れを把握できるように設計されています。
目標はすべてのインタラクションにつき50~100ミリ秒を維持することです。 これを達成するには、ロングタスク(50ミリ秒を超える時間にわたってメインスレッドをブロックするタスク)を特定してそれを分割すること、バンドルを複数のまとまりにコード分割すること、JavaScriptの実行時間を短縮すること、データ取得を最適化すること、サードパーティのスクリプト実行を延期すること、WebワーカーによってJavaScriptをバックグラウンドスレッドに移動すること、プログレッシブハイドレーションを活用してSPAにおけるリハイドレーションコストを削減することが必要です。
簡単なtips:一般に、FIDスコアを改善するための信頼性が高い戦略は、大規模なバンドルを小規模なバンドルに分割して、ユーザが必要なときにバンドルを提供することで、メインスレッドの作業を最小化し、ユーザインタラクションの遅延を防ぐことです。この点については後で詳しく説明します。
-
Cumulative Layout Shift(CLS)< 0.1。
UIの視覚的な安定性を測定することで、円滑で自然なインタラクションを確実にします。 この指標では、ページのライフスパン全体で発生したあらゆる予期しないレイアウトシフトについて、すべての個々のレイアウトシフトのスコアを合計します。 すでに表示されている要素のページ内の位置が変化した場合は常に、個々のレイアウトシフトが発生したとみなされます。 このスコアは、コンテンツのサイズと、移動した距離に基づいています。
シフトが発生するたびに(例えば、フォールバックフォントとWebフォントのフォントメトリックが異なる場合、広告、エンベッドやインラインフレームが遅れて表示される場合、画像や動画のアスペクト比が保存されない場合、CSSが遅いために再描画が必要になる場合、JavaScriptが遅いために変更が挿入される場合など)、CLSスコアに影響を与えます。 優れたユーザ体験として推奨されるCLSの値は0.1未満です。
Core Web Vitalsが、予測可能な年1回のサイクルで、時とともに変化すると見込まれていることは注目に値します。 初年度のアップデートの可能性としては、First Contentful PaintがCore Web Vitalsに昇格すること、FIDの基準値が引き下げられること、シングルページアプリケーションのサポートが改善することなどが考えられます。 また、セキュリティ、プライバシー、アクセシビリティ(!)に関する考慮事項とともに、読み込み後のユーザ入力に対する応答のウェイトが大きくなる可能性もあります。
Core Web Vitalsに関しては、一見の価値がある有用なリソースや記事が数多く存在します。
- Web Vitals Leaderboardでは、モバイル、タブレット、デスクトップ、3Gと4Gでスコアを競合と比較することができます。
- Core SERP Vitalsは、CrUXのCore Web VitalsをGoogle検索結果に表示できるChromeエクステンションです。
- Layout Shift GIF Generatorは、シンプルなGIFでCLSを可視化します(コマンドラインでも利用できます)。
- web-vitalsライブラリでは、Core Web Vitalsを収集し、それをGoogle - Analytics、Google Tag Managerなどの分析エンドポイントに送信できます。
- Analyzing Web Vitals with WebPageTestでは、Patrick Meenanが、WebPageTestがCore Web Vitalsに関するデータをどのように明らかにするかを説明しています。
- Optimizing with Core Web Vitalsは50分間の動画です。この動画では、Addy Osmaniが、eコマースのケーススタディでCore Web Vitalsを改善する方法を明らかにしています。
- Cumulative Layout Shift in PracticeとCumulative Layout Shift in the Real Worldは、Nic Jansmaによる総合的な内容の記事です。これらの記事では、CLSに関するほとんどのテーマと、それが直帰率、セッションタイム、レイジクリック(狭いエリアでのクリックやタップの連打)などの主要な指標とどのように関係しているかについて扱っています。
- What Forces Reflowは、JavaScriptでリクエストされたときや呼び出されたときに、ブラウザが同期してスタイルとレイアウトを計算するトリガーとなるプロパティやメソッドの一覧です。
- CSS Triggersは、レイアウト、ペイント、コンポジットをトリガーするCSSプロパティの一覧です。
- Fixing Layout Instabilityは、WebPageTestを使用して不安定なレイアウトの問題を特定・修正するためのガイドです。
- Cumulative Layout Shift, The Layout Instability Metricは、Boris Schapiraが執筆したCLSに関するとても詳細なガイドで、CLSの計算、測定、最適化の方法を取り扱っています。
- How To Improve Core Web Vitalsでは、各指標(FCP、TTI、TBTなどの他のWeb Vitalsを含む)や、それがいつ、どのように測定されるのかをSimon Hearneが詳細に説明しています。
では、Core Web Vitalsとは追跡すべき究極の指標なのでしょうか?そうとは限りません。確かにCore Web Vitalsは、Cloudflare、Treo、SpeedCurve、Calibre、WebPageTest(すでにフィルム型のビューに追加済み)、Newrelic、Shopify、Next.js、すべてのGoogleツール(PageSpeed Insights、Lighthouse + CI、Search Consoleなど)やその他数多くのソリューションやプラットフォームを含め、ほとんどのRUMソリューションとプラットフォームにすでに導入されています。 しかし、Katie Sylor-Millerが説明しているとおり、Core Web Vitalsには、対応ブラウザが限られていること、実際はユーザ体験のライフサイクル全体を測定していないこと、FIDとCLSの変化をビジネスの成果と結びつけるのが困難であることといった大きな問題があります。
Core Web Vitalsには進化を期待すべきですが、当面の間は、パフォーマンス面の状況をよく把握できるように、Core Web Vitalsとカスタマイズ指標を常に組み合わせるのが賢明でしょう。
05. ターゲット層の代表的な端末でデータを収集する。
正確なデータを収集するには、テストを行う端末を徹底的に選び抜く必要があります。 ほとんどの企業では、最も一般的な端末のタイプに基づいてアナリティクスを検証し、ユーザプロファイルを構築すべきです。 しかし、アナリティクスだけでは全体像が分からないことはよくあります。 ターゲット層の大部分は、反応が遅すぎるというだけでサイトを離れる(そして戻ってこない)可能性があります。 その場合、こうしたユーザの端末は、アナリティクスで最も一般的な端末として表示される可能性は低いでしょう。 そのため、ターゲット層の一般的な端末に関して、追加調査を実施するのは良いアイデアかもしれません。
IDCによれば、2020年の世界のスマートフォン出荷台数全体の84.8%(※訳注:原文執筆時)はAndroid端末でした。 消費者は平均で2年ごとにスマートフォンをアップグレードしており、米国ではスマートフォンの買い替えサイクルは33カ月となっています。 世界で最もよく売れているスマートフォンの平均コストは200ドル未満とみられます。
上記よりもやや悲観的な想定に基づくと、代表的な端末は、2年以上使用されているAndroid端末で、価格は200ドル以下、通信規格は低速の3G、RTTは400ミリ秒、通信速度は400kbpsとなります。 これは当然、企業によって大きく異なる可能性がありますが、世の中の大部分の顧客に十分に近い想定であると言えます。 さらに、ターゲット市場の現在のAmazonベストセラーを確認するのは良いアイデアかもしれません。(このアドバイスをくれたTim Kadlec、Henri Helvetica、Alex Russellに感謝します)。
 新たなサイトやアプリを開発するときは、現在のターゲット市場のAmazonベストセラーを必ず最初にチェックしましょう。(プレビューを拡大)
新たなサイトやアプリを開発するときは、現在のターゲット市場のAmazonベストセラーを必ず最初にチェックしましょう。(プレビューを拡大)
では、どの端末をテストに選べばよいのでしょうか。その答えは、上記のプロファイルによく一致した端末です。少し古いMoto G4/G5 Plus、中価格帯のSamsung端末(Galaxy A50、S8)、Nexus 5X、Xiaomi Mi A3、Xiaomi Redmi Note 7などの優良な中級レベルの端末、Alcatel 1XやCubot X19などの遅い端末を、オープンデバイスラボなどでテストするのは良い選択肢の1つです。サーマルスロットリング済みのさらに遅い端末でのテストには、Nexus 4が利用できます。価格はわずか約100ドルです。
また、各端末で使用されているチップセットを確認し、1つのチップセットに対するテストを過剰に行わないようにしましょう。 SnapdragonやApple、ローエンドのRockchipやMediatekは数世代で十分です(Patrickに感謝します)。
手元に端末がない場合は、スロットリングした3Gネットワーク(例:RTTは300ミリ秒、下り1.6Mbps、上り0.8Mbps)とCPU(5倍減速)でモバイルのユーザ体験をデスクトップでエミュレートしてみましょう。 その後、通常の3G、遅い4G(例:RTTは170ミリ秒、下り9Mbps、上り9Mbps)、Wi-Fiへ徐々に切り替えていきます。パフォーマンスへの影響をより明確にするには、2G Tuesdaysを導入したり、スロットリングした3G/4Gネットワークをオフィスに設定してテストを高速化したりすることもできます。
モバイル端末では、デスクトップマシンに比べてスピードが4~5倍遅くなると予想されることに注意しましょう。 モバイル端末のGPU、CPU、メモリ、バッテリーの特性はさまざまです。 そのため、平均的な端末のプロファイルを把握し、常にそうしたデバイスでテストを行うことが重要です。
 1週間で接続が最も遅い日を決めるという手段もあります。Facebookは、接続が遅い環境への認識と感度を高めるため、2G Tuesdaysという取り組みを導入しました。(画像の出典)
1週間で接続が最も遅い日を決めるという手段もあります。Facebookは、接続が遅い環境への認識と感度を高めるため、2G Tuesdaysという取り組みを導入しました。(画像の出典)
幸運にも、データ収集を自動化したり、上記の指標に従ってWebサイトのパフォーマンスを時系列で測定したりするための素晴らしい選択肢は数多く存在します。パフォーマンスをよく把握するには、ラボデータとフィールドデータの両方の複数のパフォーマンス指標をカバーする必要があることに注意しましょう。
- 合成テストツールは、事前に定めた端末とネットワークの設定に基づき、再現可能な環境でラボデータを収集します(Lighthouse、Calibre、WebPageTestなど)。
- リアルユーザモニタリング(RUM)ツールは、ユーザのインタラクションを継続的に評価し、フィールドデータを収集します(SpeedCurve、New Relicなど。これらのツールでは合成テストも可能です)。
前者は、サービスを開発しつつ、パフォーマンスに関する問題を特定、分離、修正することに役立つので、開発中は特に便利です。 後者は、生のデータ、つまりユーザが実際にサイトにアクセスしたときのデータを測定し、パフォーマンスのボトルネックを把握するのに役立つので、長期的なメンテナンスに向いています。
Navigation Timing、Resource Timing、Paint Timing、Long TasksなどのビルトインRUM APIを利用することで、合成テストツールとRUMは一体となってアプリケーションのパフォーマンスの全体像を明らかにします。Calibre、Treo、SpeedCurve、mPulse、Boomerang、Sitespeed.ioを利用することもできます。これらはいずれも、パフォーマンスをモニタリングするための素晴らしい選択肢です。 さらに、Server Timingヘッダでは、バックエンドとフロントエンドのパフォーマンスを1カ所でモニタリングすることも可能です。
注記:スロットリングについては、ブラウザ外のネットワークレベルで設定を行う方が常に安全です。 その理由の1つとして、DevToolsには、導入方法の関係上、HTTP/2のプッシュとのインタラクションに問題があることが挙げられます(YoavとPatrickに感謝します)。 Mac OSではNetwork Link Conditioner、WindowsではWindows Traffic Shaper、Linuxではnetem、FreeBSDではdummynetを利用できます。
テストはLighthouseで実施する可能性が高いでしょう。 その場合は以下に留意してください。
- Lighthouse CIを使用することで、Lighthouseスコアを時系列で追跡できます(とても素晴らしい機能です)。
- GitHub ActionsでLighthouseを実行することで、PRのたびにLighthouseレポートを取得できます。
- (Lighthouse Paradeを通じて)サイトのすべてのページに対してLighthouseのパフォーマンス監査を実施することができます。結果はCSV形式で保存されます。
- Lighthouse Scores CalculatorとLighthouse metric weightsを使用することで、必要に応じて詳細な情報を把握できます。
- LighthouseはFirefoxでも利用できますが、内部でPageSpeed Insights APIを利用し、ヘッドレスChrome 79 User-Agentに基づいてレポートを作成します(※訳注:原文指定URL消失)。
 Lighthouse CIはとても素晴らしいツールで、Lighthouseの継続的な実行、その結果の保存と取得、結果に対するアサーションが可能です。(プレビューを拡大)
Lighthouse CIはとても素晴らしいツールで、Lighthouseの継続的な実行、その結果の保存と取得、結果に対するアサーションが可能です。(プレビューを拡大)
06. テスト用の「クリーン」な「顧客」プロファイルを設定する。
パッシブなモニタリングツールでテストを実行する場合、(Firefox(※訳注:原文指定URL消失)とChromeにおいて)偏った結果を避けるために、アンチウイルスソフトやバックグラウンドのCPUタスクをオフにする、バックグラウンドの帯域幅転送を除外する、ブラウザ拡張機能がインストールされていないクリーンなユーザプロファイルでテストを行うといった戦略がよく使われます。
 DebugBearのレポートは、パスワードマネージャ、アドブロッカ、EvernoteやGrammarlyといった人気のアプリケーションなど、遅い拡張機能ワースト20を明らかにしています。(プレビューを拡大)
DebugBearのレポートは、パスワードマネージャ、アドブロッカ、EvernoteやGrammarlyといった人気のアプリケーションなど、遅い拡張機能ワースト20を明らかにしています。(プレビューを拡大)
しかし、顧客がどのブラウザ拡張機能を頻繁に使用しているかを調査し、専用の「顧客」プロファイルに基づいてテストを実施するのも良いアイデアです。 実際、一部の拡張機能はアプリケーションのパフォーマンスに重大な影響を与える可能性があります(2020 Chrome Extension Performance Report)。 ユーザがその拡張機能を大量に使用する場合、それを事前に織り込んでおくべきかもしれません。したがって、「クリーン」なプロファイルのみによるテスト結果は楽観的過ぎて、現実のシナリオでは悲惨な状況になる可能性があります。`
07. 同僚とパフォーマンス目標を共有する。
今後の誤解を避けるために、チームのあらゆるメンバーがパフォーマンス目標をよく理解するようにしましょう。 デザインにせよ、マーケティングにせよ、その中間の何かにせよ、あらゆる意思決定はパフォーマンスに影響します。 チーム全体に責任とオーナーシップを分配することは、その後のパフォーマンスに重点を置いた意思決定の合理化につながります。 デザインに関する意思決定と、パフォーマンスバジェットや早期に定めた優先事項の対応関係を明らかにしましょう。
現実的な目標の設定 #
08. 応答時間100ミリ秒、60fps。
インタラクションがスムーズに感じられるには、インターフェースがユーザの入力から100ミリ秒以内に応答する必要があります。 それ以上遅いと、ユーザはアプリにタイムラグがあると感じます。 ユーザ中心主義のパフォーマンスモデルであるRAILは、妥当な目標を掲げています。 その目標とは、応答時間を100ミリ秒未満にするには、遅くとも50ミリ秒未満ごとにメインスレッドを解放するようにページを作成しなければならないというものです。 Estimated Input Latencyは、この基準値を満たしているかどうかを明らかにします。 理想的には、この値は50ミリ秒未満であるべきです。 アニメーションなどの負荷が大きい部分では、可能な場合は他に何も処理せず、不可能な場合は処理を絶対的な最小限に抑えるのが望ましいと言えます。
 RAILはユーザ中心主義のパフォーマンスモデル。
RAILはユーザ中心主義のパフォーマンスモデル。
また、アニメーションの各フレームは16ミリ秒未満とし、1秒間のフレーム数が60フレーム(1秒÷60=16.6ミリ秒)となるようにすべきです。 なるべく1フレームを10ミリ秒未満にするのが望ましいと言えます。 ブラウザは新たなフレームを画面に描画するのに時間がかかるため、16.6ミリ秒の基準値に達する前にコードの実行が終了するようにすべきです。 120fpsに関する議論はすでに始まっており(例えば、iPad Proの画面のリフレッシュレートは120Hz)、Surmaは120fpsを実現するためのレンダリングパフォーマンスソリューションについての記事を執筆していますが、現時点では120fpsを目指さなくてもよいでしょう。
パフォーマンスを予想するときは悲観的であるべきですが、インターフェースをデザインするときは楽観的であるべきであり、アイドルタイムは賢明に活用すべきです(idlize、idle-until-urgent、react-idleをチェックしましょう)。 当然ながら、上記の目標は読み込みのパフォーマンスではなく、ランタイムのパフォーマンスに適用されます。
09. 3GでFID<100ミリ秒、LCP<2.5秒、TTI<5秒。クリティカルなファイルの容量は170KB未満(gzip形式で圧縮した場合)。
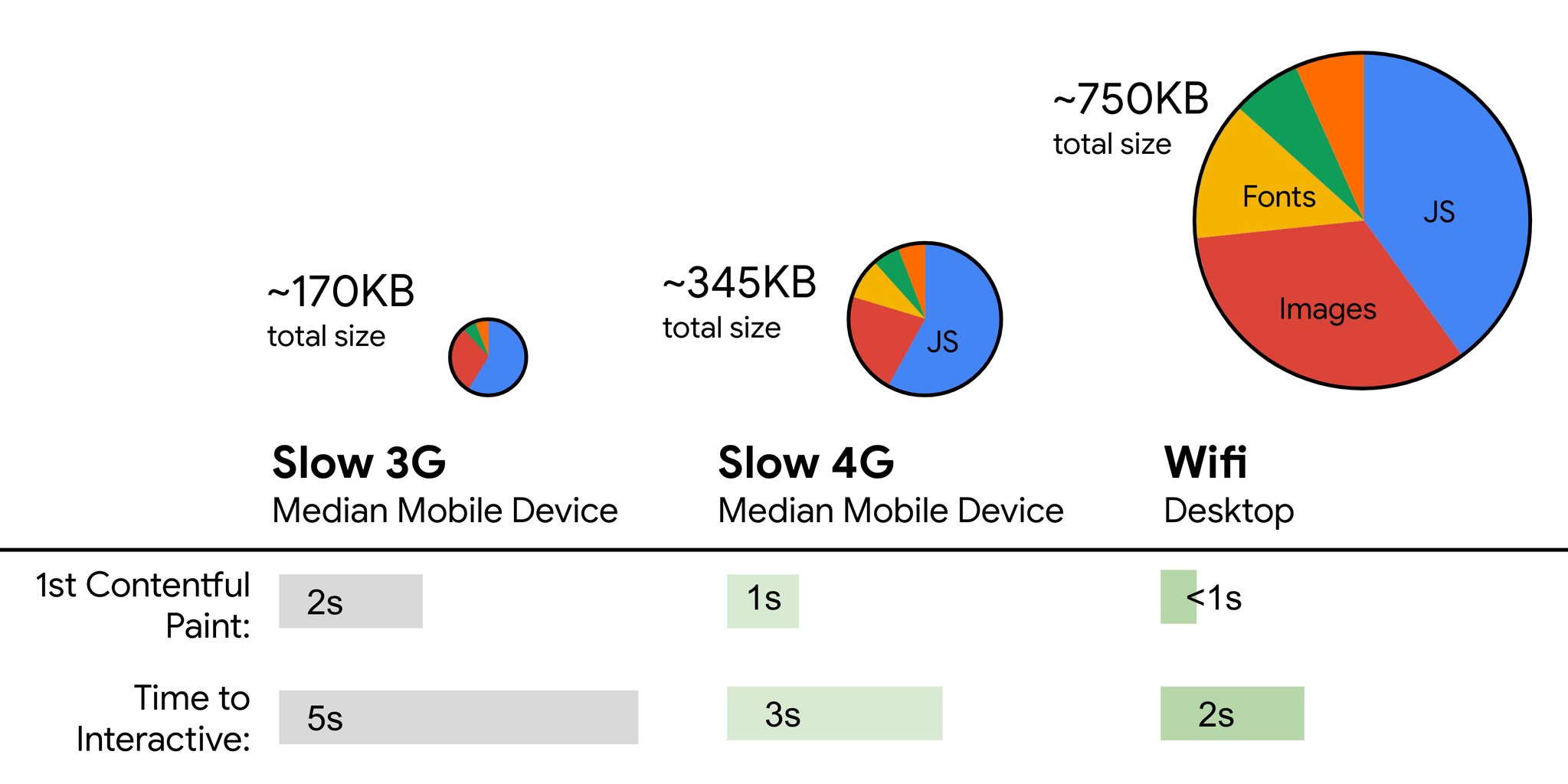
最終的な目標としては、(達成するのはとても困難かもしれませんが)Time To Interactiveは5秒未満、リピート訪問については2秒未満(サービスワーカーによってのみ達成可能)とするのが良いでしょう。 Largest Contentful Paintは2.5秒未満を目指し、Total Blocking TimeとCumulative Layout Shiftを最小化しましょう。 許容できるFirst Input Delayは70~100ミリ秒未満です。 上記のとおり、低速な3Gネットワークに接続された200ドルのAndroidスマートフォン(Moto G4など)を、400ミリ秒のRTTと400kbpsの転送速度によってエミュレートしたものを基準とします。
Web上のコンテンツを迅速に提供するには、2つの大きな制約があり、それが妥当なファイル容量を実質的に決める要因となります。 まず、TCP Slow Startによるネットワークデリバリの制約があります。 HTMLの最初の14KB(10個のTCPパケットが各1460バイトで約14.25 KB。 ただし、鵜呑みにすべきではありません)は、最もクリティカルなペイロードのチャンクであり、バジェットのうち最初のラウンドトリップで提供できる唯一の部分です(モバイルのウェイクアップタイムの関係上、RTTが400ミリ秒の場合に1秒間で受信できるのはこの部分に限られます)。
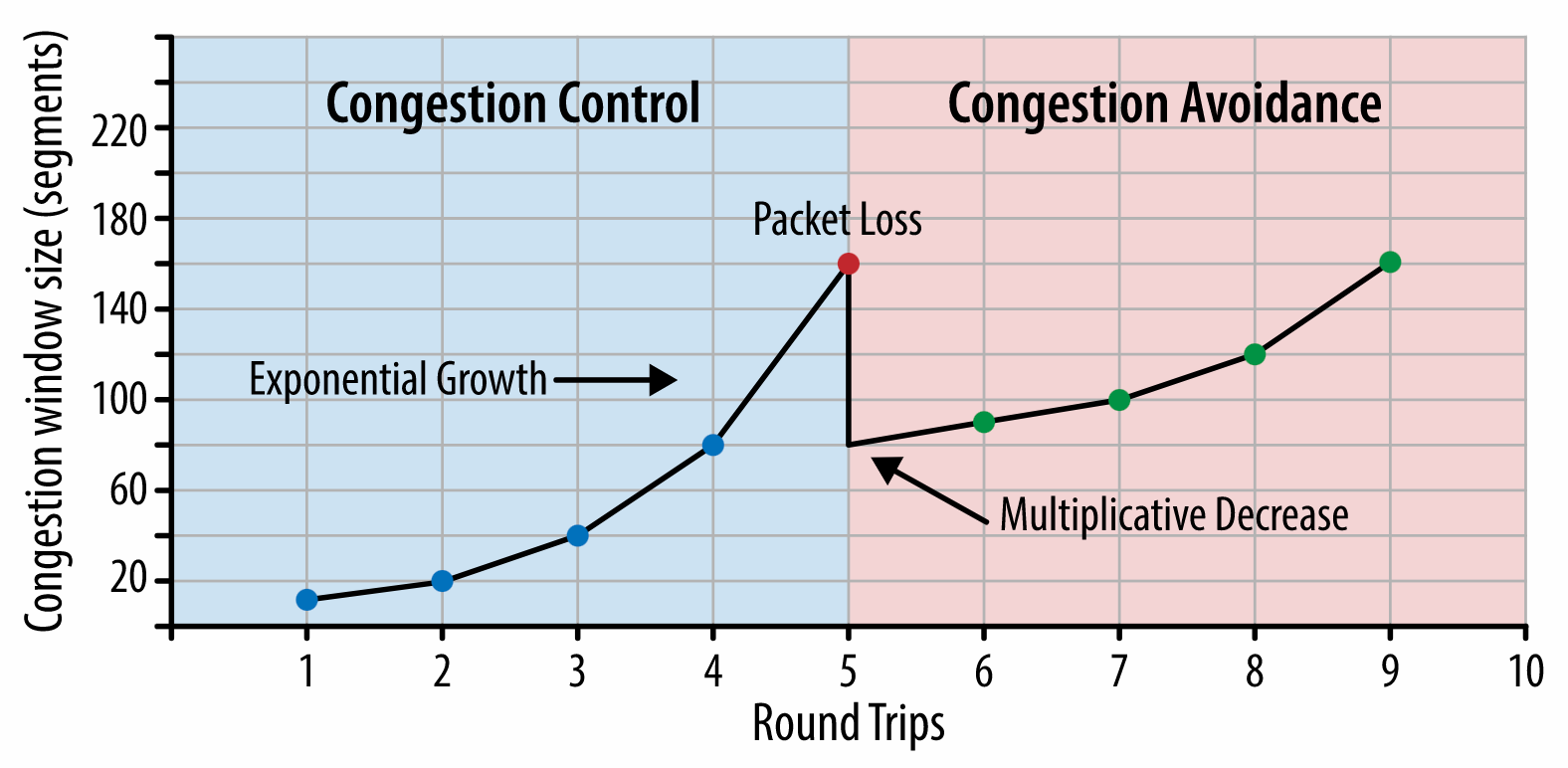 TCP接続では、小規模な輻輳ウィンドウからスタートして、ラウンドトリップごとにウィンドウを2倍に拡大します。最初のラウンドトリップでは14KBを提供することが可能です。出典:High Performance Browser Networking(Ilya Grigorik著)。(プレビューを拡大)
TCP接続では、小規模な輻輳ウィンドウからスタートして、ラウンドトリップごとにウィンドウを2倍に拡大します。最初のラウンドトリップでは14KBを提供することが可能です。出典:High Performance Browser Networking(Ilya Grigorik著)。(プレビューを拡大)
もう1つの制約として、JavaScriptのパーシングと実行時間の関係上、メモリとCPUに対するハードウェアの制約があります(これらについては後で詳しく説明します)。 最初のパラグラフで述べた目標を達成するには、JavaScriptにとってクリティカルなファイルの容量のバジェットを考慮することが必要です。 バジェットの適切な容量についてはさまざまな意見があります(プロジェクトの性質にも大きく依存します)が、170KBのJavaScriptファイルをgzip形式で圧縮した場合、中価格帯のスマートフォンではパーシングとコンパイルに最大で1秒かかります。 170KBのファイルを解凍すると容量が3倍(0.7MB)になると想定すると、それだけでMoto G4/G5 Plusでは「まとも」なユーザ体験が失われかねません。
Wikipediaのサイトの場合、2020年に、コードの実行速度はWikipediaのユーザにとって世界全体で19%速くなりました。 ですから、もしWebパフォーマンスの指標に前年比で変化がない場合、それは通常、環境の継続的な改善に伴って、自社サイトが実質的に後退しているという警戒すべきサインです(詳細はGilles Dubucのブログ記事を参照)。
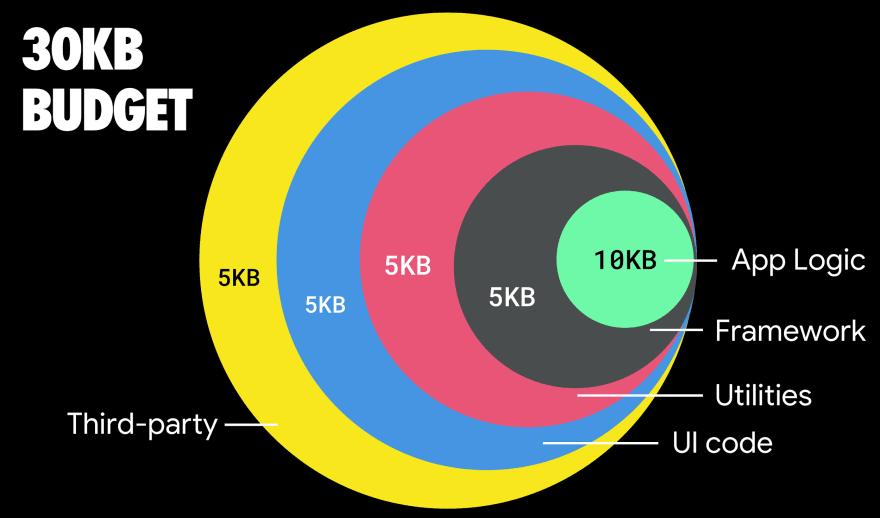
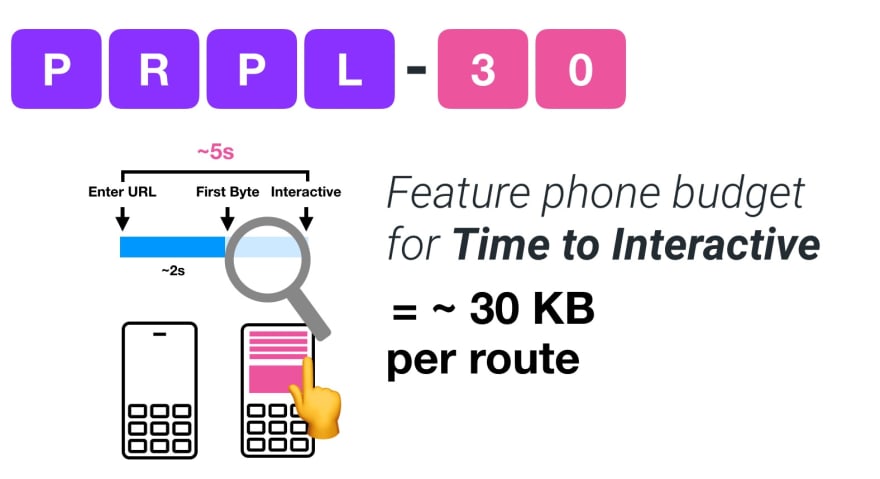
東南アジア、アフリカ、インドなどの成長中の市場をターゲットとする場合、まったく異なる制約に直面することになります。 Addy Osmaniはフィーチャーフォンの主な制約(例えば、低コストの優良な端末は少数、高品質なネットワークは利用できない、モバイルデータ通信のコストが大きい)、PRPL-30バジェット、こうした環境における開発のガイドラインについて述べています。
 Addy Osmaniによれば、遅延読み込み経路における推奨容量も35KB未満です。(プレビューを拡大)
Addy Osmaniによれば、遅延読み込み経路における推奨容量も35KB未満です。(プレビューを拡大)
 Addy Osmaniは、フィーチャーフォンをターゲットとする場合のPRPL-30パフォーマンスバジェット(gzip形式で圧縮・軽量化した初期バンドル30KB)を提唱しています。(プレビューを拡大)
Addy Osmaniは、フィーチャーフォンをターゲットとする場合のPRPL-30パフォーマンスバジェット(gzip形式で圧縮・軽量化した初期バンドル30KB)を提唱しています。(プレビューを拡大)
実際、GoogleのAlex Russellは、妥当な容量の上限としてgzip形式で130~170KBを目指すことを推奨しています。 現実には、ほとんどのサービスはこの上限に近づいてすらいません。 現在のバンドル容量の中央値は約452KBで、2015年初めと比べて53.6%増加しています。 これはミドルクラスのモバイル端末で12~20秒のTime To Interactiveに相当します。
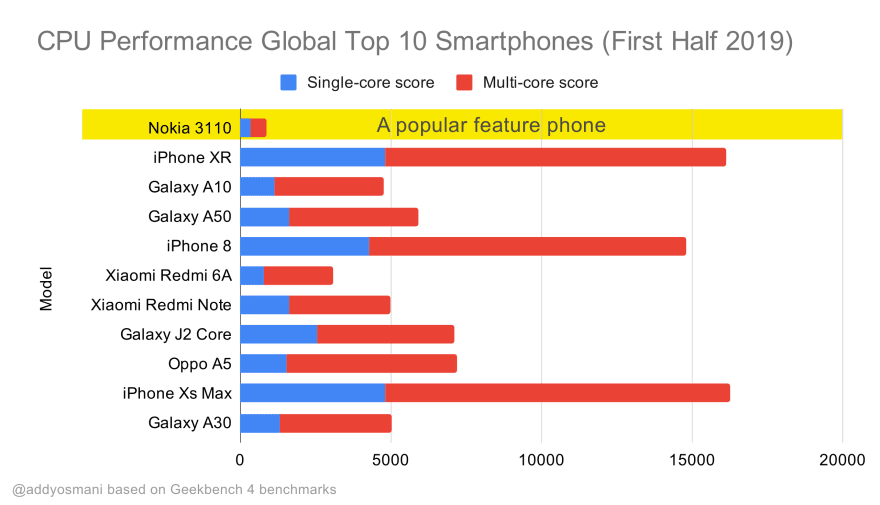
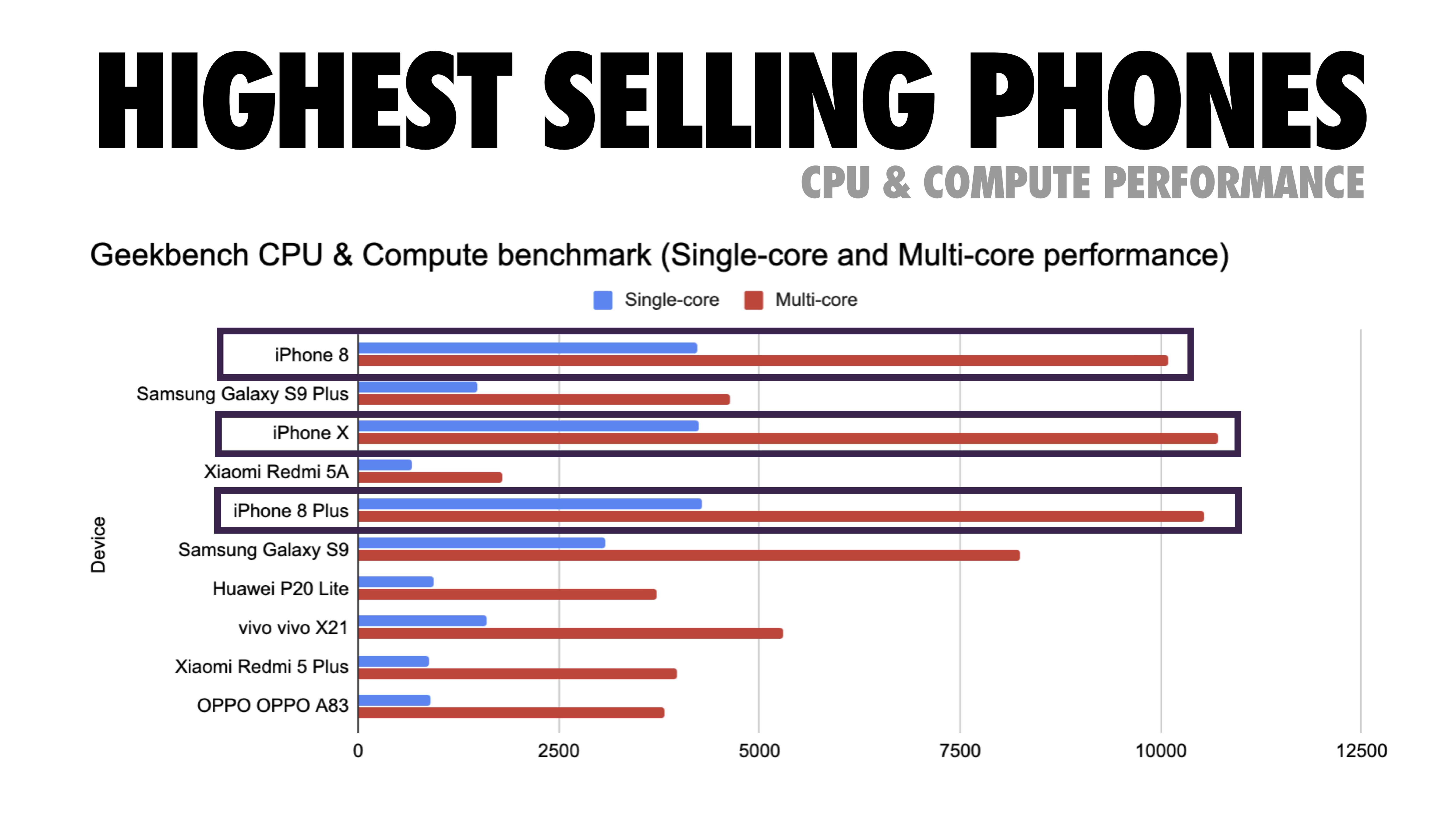
 上記のグラフは、2019年に世界で最も売れたスマートフォンについて、GeekbenchでCPUパフォーマンスのベンチマークを比較したものです。JavaScriptはシングルコアのパフォーマンスにとって負担となり(他のWebプラットフォームに比べて本質的にシングルスレッドとなりやすいことに注意してください)、CPUの制約を受けます。Addyの記事「Loading Web Pages Fast On A $20 Feature Phone」より引用。(プレビューを拡大)
上記のグラフは、2019年に世界で最も売れたスマートフォンについて、GeekbenchでCPUパフォーマンスのベンチマークを比較したものです。JavaScriptはシングルコアのパフォーマンスにとって負担となり(他のWebプラットフォームに比べて本質的にシングルスレッドとなりやすいことに注意してください)、CPUの制約を受けます。Addyの記事「Loading Web Pages Fast On A $20 Feature Phone」より引用。(プレビューを拡大)
しかし、バンドル容量のバジェットを超えることもできます。 例えば、ブラウザのメインスレッドのアクティビティ、つまりレンダリング開始前の描画時間に基づいてパフォーマンスバジェットを設定することや、フロントエンドでCPUに大きな負荷をかけている存在を見つけ出すことが可能です。 Calibre、SpeedCurve、Bundlesizeなどのツールは、バジェットを管理するのに役立ち、ビルドのプロセスに統合できます。
最後に、パフォーマンスのバジェットはおそらく固定すべきではありません。 ネットワーク接続に合わせて、パフォーマンスのバジェットは調整すべきです。 ただし、接続が遅くなると、どのように利用してもペイロードは大幅に「重く」なります。
注記:HTTP/2が普及し、5GとHTTP/3の登場が近づき、スマートフォンが急速に進化し、SPAが繁栄するなかで、上記のような厳格なバジェットを設定するのは奇妙に思えるかもしれません。 しかし、ネットワークの輻輳、インフラ開発の遅さ、データ上限、プロキシブラウザ、省データモードから隠れたローミング手数料に至るまで、ネットワークやハードウェアの予測不能な性質に対処するときには、こうしたバジェットは合理的に感じられるはずです。
 Fast By Default:Modern loading best practices(Addy Osmani著)より(スライド19)
Fast By Default:Modern loading best practices(Addy Osmani著)より(スライド19)
 パフォーマンスのバジェットは、平均的なモバイル端末のネットワークの状況に応じて調整すべきです。(画像の出典:Katie Hempenius)(プレビューを拡大)
パフォーマンスのバジェットは、平均的なモバイル端末のネットワークの状況に応じて調整すべきです。(画像の出典:Katie Hempenius)(プレビューを拡大)
環境の定義#
10. ビルドツールを選択・設定する。
現在、流行しているツールに気をとられすぎないようにしましょう。 Gruntにせよ、Gulpにせよ、Webpackにせよ、Parcelにせよ、あるいは複数のツールの組み合わせにせよ、自分のビルド環境にこだわるべきです。 必要な成果を出していて、ビルドのプロセスを維持するのに支障がない限り、それで問題ありません。
ビルドツールのなかでは、RollupやSnowpackの勢いが強まっていますが、最も定評があるのはWebpackのようです。 Webpackでは、ビルドの容量を最適化するために、文字どおり何百ものプラグインが利用できます。 Webpack Roadmap 2021に注目しましょう。
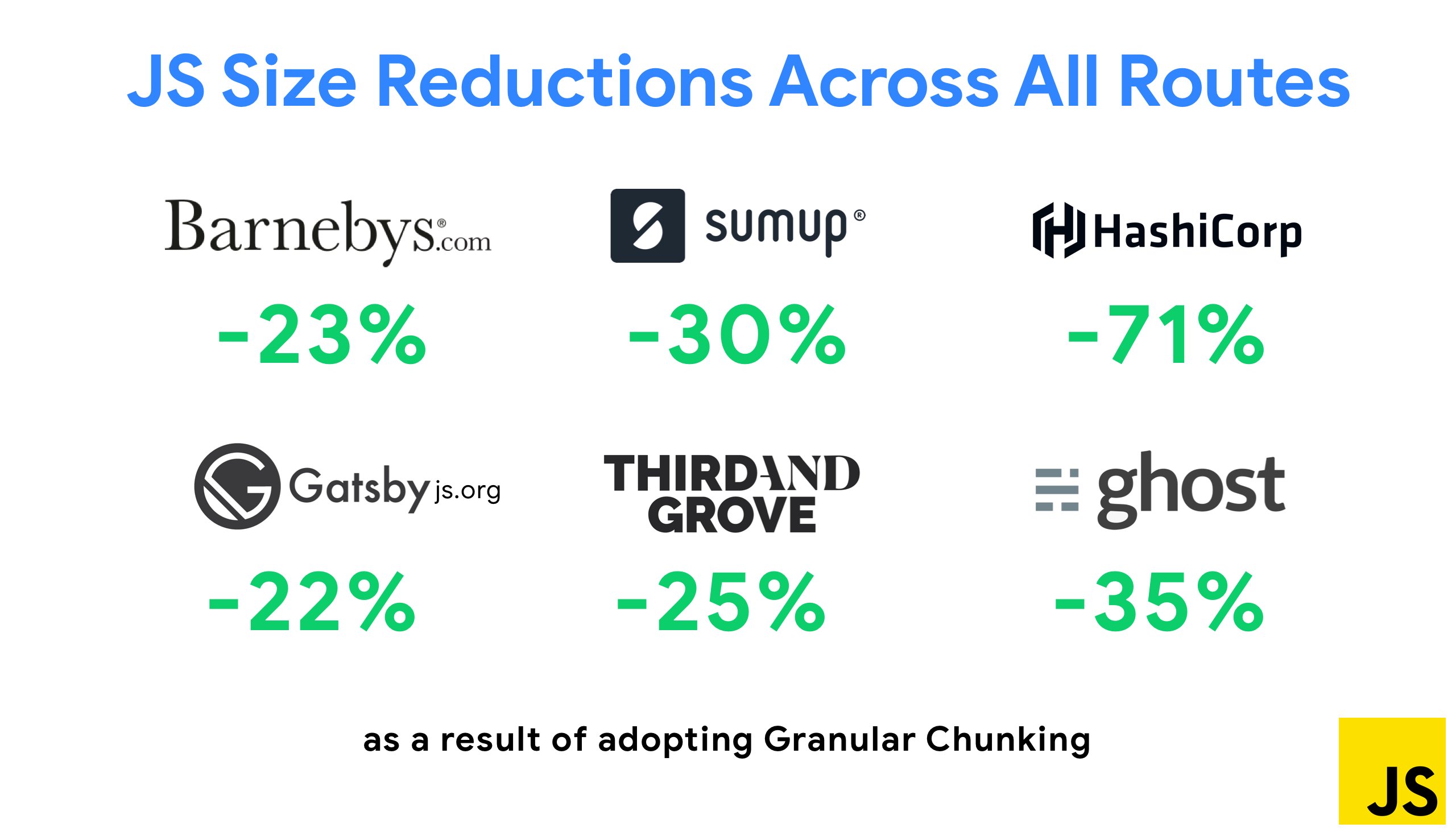
最近登場した特に注目すべき戦略の1つは、Next.jsとGatsbyにおいてWebpackでグラニュラチャンキングを行い、コードの重複を最小化することです。 デフォルトでは、すべてのエントリポイントで共有されていないモジュールは、それを利用しないルートでもリクエストされる可能性があります。 その結果、必要以上にコードがダウンロードされ、オーバーヘッドが発生します。 Next.jsにおけるグラニュラチャンキングでは、サーバサイドのビルドマニフェストファイルを利用して、出力されたどのチャンクをさまざまなエントリポイントで使用するかを決定できます。
 Webpackプロジェクトのコードの重複を削減するためにgranular chunkingを利用できます。Next.jsとGatsbyではデフォルトで有効です。画像の出典:Addy Osmani。(プレビューを拡大)
Webpackプロジェクトのコードの重複を削減するためにgranular chunkingを利用できます。Next.jsとGatsbyではデフォルトで有効です。画像の出典:Addy Osmani。(プレビューを拡大)
SplitChunksPluginでは、いくつかの条件に応じて複数の分割済みのチャンクを作成し、複数のルートで重複したコードを取得することを防ぎます。 これはページの読み込み時間や、操作中のキャッシングを改善します。 この機能はNext.js 9.2とGatsby v2.20.7に搭載されています。
とはいえ、Webpackを始めるのは難しいかもしれません。 そこで、Webpackの世界に飛び込みたい人のために、素晴らしいリソースを紹介します。
- Webpackのドキュメントは、当然ながら、良い出発点となります。Raja RaoのWebpack — The Confusing Bitsや、Andrew WelchのAn Annotated Webpack Configも最初の一歩に適しています。
- Sean LarkinはWebpack:The Core Conceptsという無料の講義を提供しています。Jeffrey WayもWebpack for Everyoneという素晴らしい無料の講義を公開しています。どちらもWebpackの導入として優れた内容です。
- Webpack Fundamentalsは、FrontendMastersが公開したSean Larkinによる4時間の講義で、とても包括的な内容となっています。
- Webpack examplesは、トピックと目的別に、すぐに使えるWebpack設定を数多く公開しています。さらに、基本設定ファイルを生成するWebpack設定のコンフィギュレータもあります。
- awesome-webpackは、Webpackに関する便利なリソース、ライブラリ、ツールを厳選したリストです。記事、動画、講義、書籍や、Angular、Reactやフレームワークを問わないプロジェクトの例も含まれています。
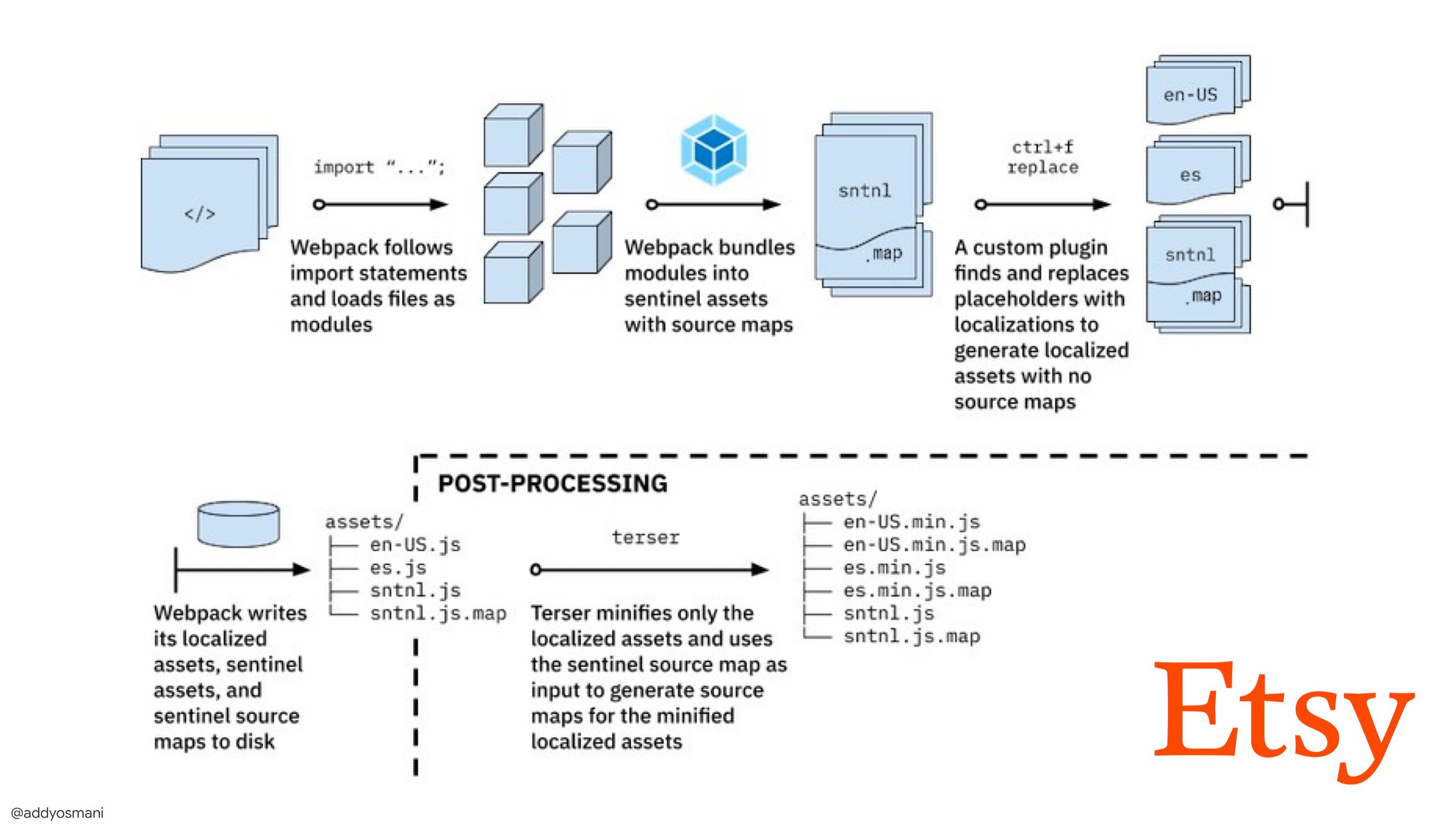
- The journey to fast production asset builds with WebpackはEtsyのケーススタディです。EtsyがどのようにRequireJSベースのJavaScriptビルドシステムからWebpackへ移行し、どうやってビルドを最適化し、13,200を超えるアセットを平均4分で管理しているかを説明しています。 Webpack performance tipsは、Ivan Akulovによる宝の山のようなスレッドです。パフォーマンスに焦点を当てた数多くのtipsを紹介しており、その中には特にWebpackに焦点を当てたものもあります。
- awesome-webpack-perfというGitHubリポジトリは、パフォーマンス向上のための便利なWebpackツールとプラグインの宝庫です。こちらもIvan Akulovがメンテナンスしています。
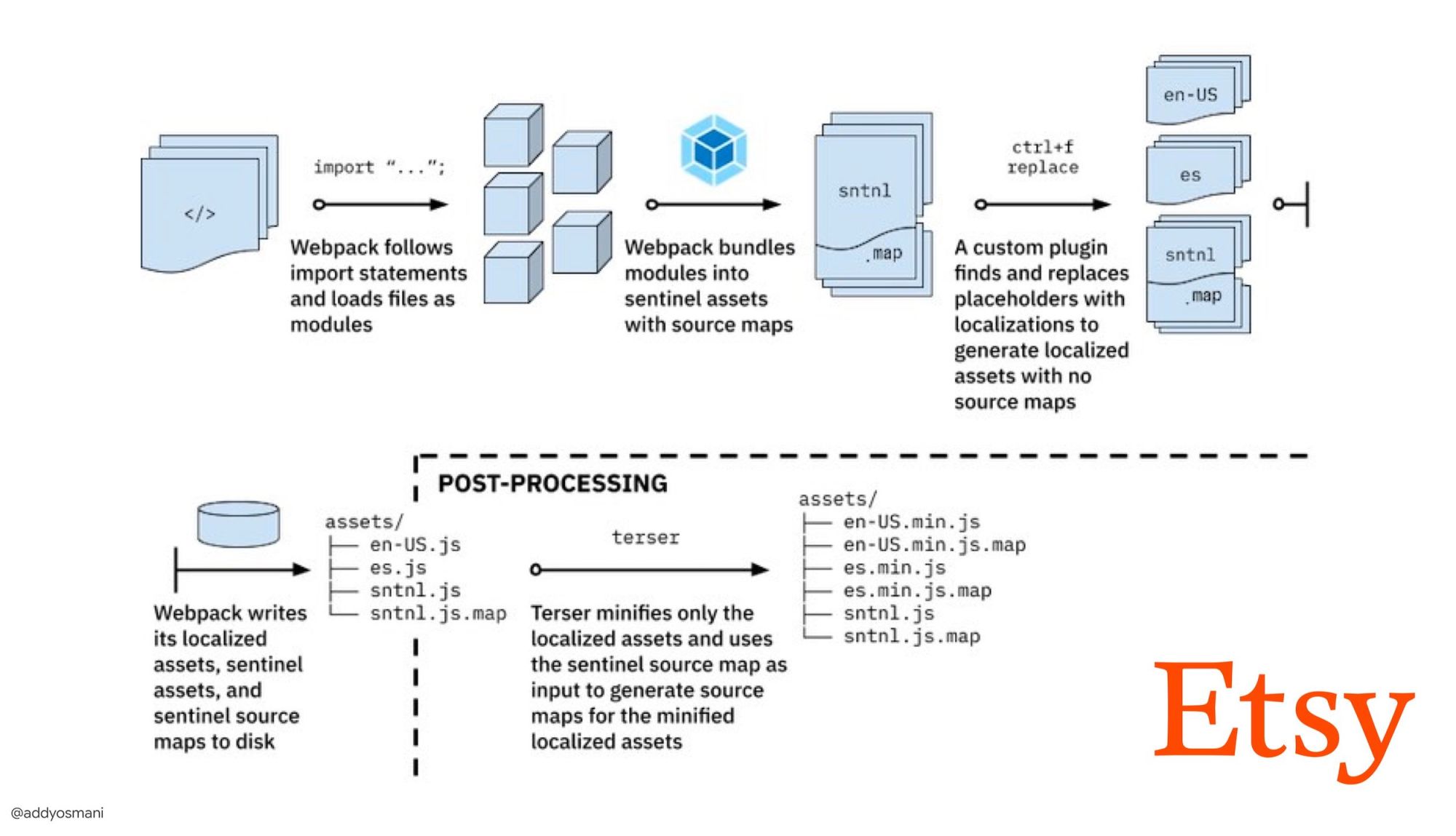 EtsyがWebpackによって本番環境用の高速なビルドを実現するまでの道のり(Addy Osmaniより)(プレビューを拡大)
EtsyがWebpackによって本番環境用の高速なビルドを実現するまでの道のり(Addy Osmaniより)(プレビューを拡大)
11. プログレッシブエンハンスメントをデフォルトで使用する。
プログレッシブエンハンスメントは、提唱されてから何年も経ちますが、それでもフロントエンドのアーキテクチャやデプロイの指針としておくのが無難です。 まずは中心となるユーザ体験の設計・開発を行い、それから先進的な機能によって対応ブラウザのユーザ体験を向上させることで、ユーザ体験を強固にすることができます。貧弱な画面とブラウザを搭載した遅いマシンが、最適化されていないネットワークからアクセスしてもWebサイトの動作が速いのならば、優れたブラウザを搭載した高速なマシンが、真っ当なネットワークからアクセスすればもっと速く動くはずです。
実際、アダプティブなモジュール提供によって、プログレッシブエンハンスメントは新たなレベルに進んだように感じられます。 これは、ローエンドの端末には中核のみの「ライト」なユーザ体験を提供し、ハイエンドの端末では洗練された機能によってユーザ体験を向上させるというものです。 プログレッシブエンハンスメントは、当面は消えないでしょう。
12. パフォーマンスの強固な基準を選択する。
読み込みに影響を与える未知の要因は数多くあります。 例えば、ネットワーク、サーマルスロットリング、キャッシュエビクション、サードパーティのスクリプト、パーサのブロッキングパターン、ディスクI/O、IPCレイテンシ、インストール済みの拡張機能、アンチウイルスソフトウェアとファイアウォール、バックグラウンドのCPUタスク、ハードウェアとメモリの制約、L2とL3のキャッシングの差、RTTSなどです。 その中でもJavaScriptは、レンダリングをデフォルトでブロックするWebフォントや、メモリを使いすぎることが多い画像に次いで、ユーザ体験の中で特にコストが重い部分となっています。 パフォーマンスのボトルネックがサーバからクライアントへ移動していることを踏まえ、私たち開発者はこうした未知の要因のすべてをもっと詳しく検討する必要があります。
170KBのバジェットには、すでにクリティカルパスHTML/CSS/JavaScript、ルータ、状態管理、ユーティリティ、フレームワーク、アプリケーションロジックが含まれているため、選択したフレームワークのネットワーク転送コスト、パース/コンパイル時間、ランタイムコストを徹底的に検証(※訳注:原文指定URL消失)しなければなりません。 幸運なことに、過去数年間で、ブラウザによるスクリプトのパースとコンパイルの速度は大幅に改善しています。 しかし、JavaScriptの実行は依然として主要なボトルネックとなっているため、スクリプトの実行時間とネットワークによく注意すれば大きな効果があるでしょう。
Tim Kadlecは、モダンなフレームワークのパフォーマンスについて素晴らしい調査を実施しており、その内容を"JavaScript frameworks have a cost"という記事にまとめています。 私たちはスタンドアロンのフレームワークの影響についてよく議論しますが、Timが述べているとおり、実際には複数のフレームワークを利用することは珍しくありません。 例えば、モダンなフレームワークにゆっくりと移行しつつある旧バージョンのjQueryと、旧バージョンのAngularを利用したいくつかの古いアプリケーションを併用しているかもしれません。 そのため、JavaScriptバイト数とCPU実行時間の累積コストを調査する方が合理的です。 この累積コストによって、たとえハイエンド端末でも、ぎりぎり利用できるレベルのユーザ体験までたちまち落ち込んでしまう可能性があります。
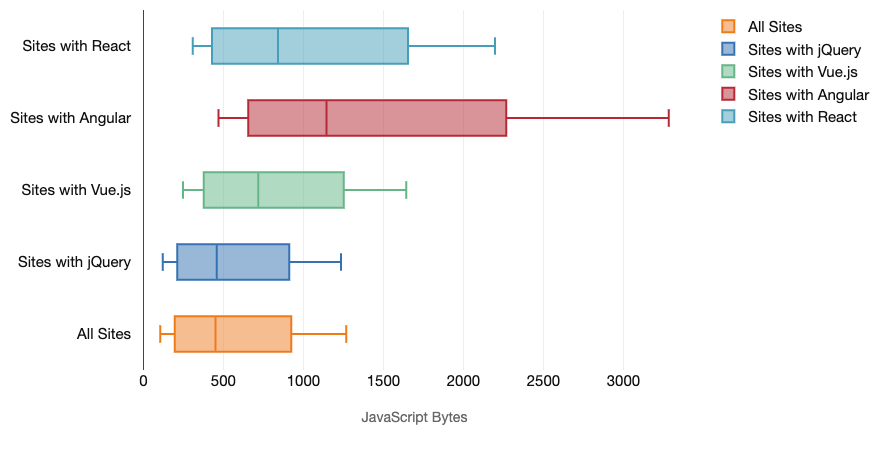
一般に、モダンなフレームワークは、あまり高性能でない端末を重視していません。 そのため、スマートフォンとデスクトップにおけるユーザ体験は、パフォーマンスの面で劇的に異なることがよくあります。 調査によれば、ReactやAngularを利用したサイトは、他のサイトよりもCPU時間が長い傾向があります(当然ながら、必ずしもReactがVue.jsよりもCPUにとって高コストという意味ではありません)。
Timによれば、一つ明確に言えるのは、「サイトのビルドにフレームワークを使用する場合、たとえ最善のシナリオであっても、初期のパフォーマンスに関するトレードオフが発生する」ということです。

 モバイル端末のスクリプト関連のCPU時間と、デスクトップ端末のJavaScriptバイト数。一般に、ReactやAngularを利用しているサイトは、他のサイトよりもCPU時間が長い傾向があります。しかし、これはサイトをビルドする方法によって変わります。Tim Kadlecの調査より。(プレビューを拡大)
モバイル端末のスクリプト関連のCPU時間と、デスクトップ端末のJavaScriptバイト数。一般に、ReactやAngularを利用しているサイトは、他のサイトよりもCPU時間が長い傾向があります。しかし、これはサイトをビルドする方法によって変わります。Tim Kadlecの調査より。(プレビューを拡大)
13. フレームワークと依存関係を評価する。
現在、あらゆるプロジェクトがフレームワークを必要とするわけでも、シングルページアプリケーションのあらゆるページがフレームワークの読み込みを必要とするわけでもありません。 Netflixの場合、「React、複数のライブラリ、対応するアプリのコードをクライアントサイドから削除したところ、JavaScriptの総容量を200KB以上削減し、ログアウト後のホームページにおけるNetflixのTime To Interactiveを50%以上減らすことができました」。 同社のチームは、ユーザがランディングページで消費する時間を利用して、ユーザが次にアクセスする可能性が高いページのReactを先読みするようにしました(詳細はこちら)。
それでは、クリティカルなページから既存のフレームワークを完全に削除した場合はどうなるでしょうか。 Gatsbyでは、gatsby-plugin-no-javascriptによって、Gatsbyが作成したすべてのJavaScriptファイルを静的HTMLファイルから削除できます。 Vercelでは、特定のページについて、本番環境のランタイムJavaScriptを無効化できます(実験的な機能です)。
フレームワークを選択すると、少なくとも数年間はそのフレームワークを使い続けます。 そのため、フレームワークを使用する必要がある場合は、十分な情報に基づき、よく考えて選択しなければなりません。これは私たちが重視する主要なパフォーマンス指標に関して特に当てはまります。
データによれば、フレームワークは、デフォルトではとても高コストです。 Reactページの58.6%には1MB超のJavaScriptが含まれており、Vue.jsのページ読み込みのFirst Contentful Paintが1.5秒未満である割合は36%です。 Ankur Sethiの調査によれば、「Reactアプリケーションは、どんなに最適化しても、インドの平均的なスマートフォンでは読み込みが約1.1秒より速くならないでしょう。 Angularアプリは、起動まで常に2.7秒以上かかります。Vueアプリのユーザは、利用を始められるまで1秒以上待つ必要があります」。 いずれにせよ、インドはあなたの主要なターゲット市場ではないかもしれません。 しかし、最適ではないネットワーク環境からサイトにアクセスするユーザは、同様の体験をするでしょう。
もちろん、SPAを高速化することは可能ですが、最初から速いわけではありません。 そのため、SPAを高速化し、それを維持し続けるための時間と労力を考慮する必要があります。 おそらく、初めはパフォーマンスコストの基準を低めに設定する方が簡単でしょう。
それでは、どのようにフレームワークを選択すれば良いのでしょうか。 選択肢を選ぶ前に、少なくとも容量と初期実行時間の合計コストについて考えると良いでしょう。 Preact、Inferno、Vue、Svelte、Alpine、Polymerなどのコストが軽い選択肢でも、十分役割を果たします。 基準となる容量が、アプリケーションのコードの制約を定めることとなります。
Seb Markbågeが述べているとおり、フレームワークのスタートアップコストを測定する良い方法の1つは、まず画面をレンダリングし、次にそれを削除し、またレンダリングすることです。 それによって、フレームワークがどのように拡大するかが分かります。 最初のレンダリングは、コンパイルが遅いコードのウォームアップとしての役割を果たします。 これらのコードは、拡大する際にツリー全体にメリットをもたらします。 2回目のレンダリングは基本的に、ページの複雑性が増す場合に、ページにおけるコードの再利用がパフォーマンス特性にどのような影響を与えるかをエミュレートするものです。
Sacha Greifの12項目からなるスコアリングシステムでは、例えば機能、アクセシビリティ、安定性、パフォーマンス、パッケージのエコシステム、コミュニティ、学習曲線、ドキュメント、ツール、実績、チーム、互換性、セキュリティなどを調査することで、候補(あるいはJavaScriptライブラリ全般)を評価することまで可能です。
 Perf Trackは、フレームワークのパフォーマンスを広範囲にわたって追跡します。(プレビューを拡大)
Perf Trackは、フレームワークのパフォーマンスを広範囲にわたって追跡します。(プレビューを拡大)
長い時間をかけてWebで収集されたデータに頼ることもできます。 例えば、Perf Trackは広範囲にわたってフレームワークのパフォーマンスを追跡しており、Angular、React、Vue、Polymer、Preact、Ember、Svelte、AMPでビルドしたWebサイトのオリジンのCore Web Vitalsスコアの合計値を明らかにしています。 Gatsby、Next.js、Create React Appや、Nuxt.js(Vue)、Sapper(Svelte)でビルドしたWebサイトを指定し、比較することも可能です。
手始めに、アプリケーションにとって適切なデフォルトのフレームワークを選ぶことから始めると良いでしょう。 Gatsby(React)、Next.js(React)、Vuepress(Vue)、Preact CLI、PWA Starter Kitは、平均的なモバイルハードウェアにおいて初期設定で高速な読み込みを実現できるため、デフォルトとしてちょうど良い存在です。 また、web.devによるReactとAngularのためのフレームワークごとのパフォーマンスガイドも見てみましょう(Phillipに感謝します)。
シングルページアプリケーションを丸ごとビルドするときは、少し目新しいアプローチを実践できるかもしれません。
Turbolinksは15KBのJavaScriptライブラリで、画面のレンダリングにJSONではなくHTMLを使用します。
リンク先にアクセスすると、ページ全体を読み込むコストを発生させることなく、Turbolinksがページを自動的に取得し、 <body> 要素を置き換え、 <head> 要素をマージします。
詳細を手早く知りたい人はこちら、Turbolinksの完全なドキュメントについてはこちら(Hotwire)をご確認ください。
 最も売れているスマートフォンのCPUと演算性能(画像の出典:Addy Osmani)(プレビューを拡大)
最も売れているスマートフォンのCPUと演算性能(画像の出典:Addy Osmani)(プレビューを拡大)
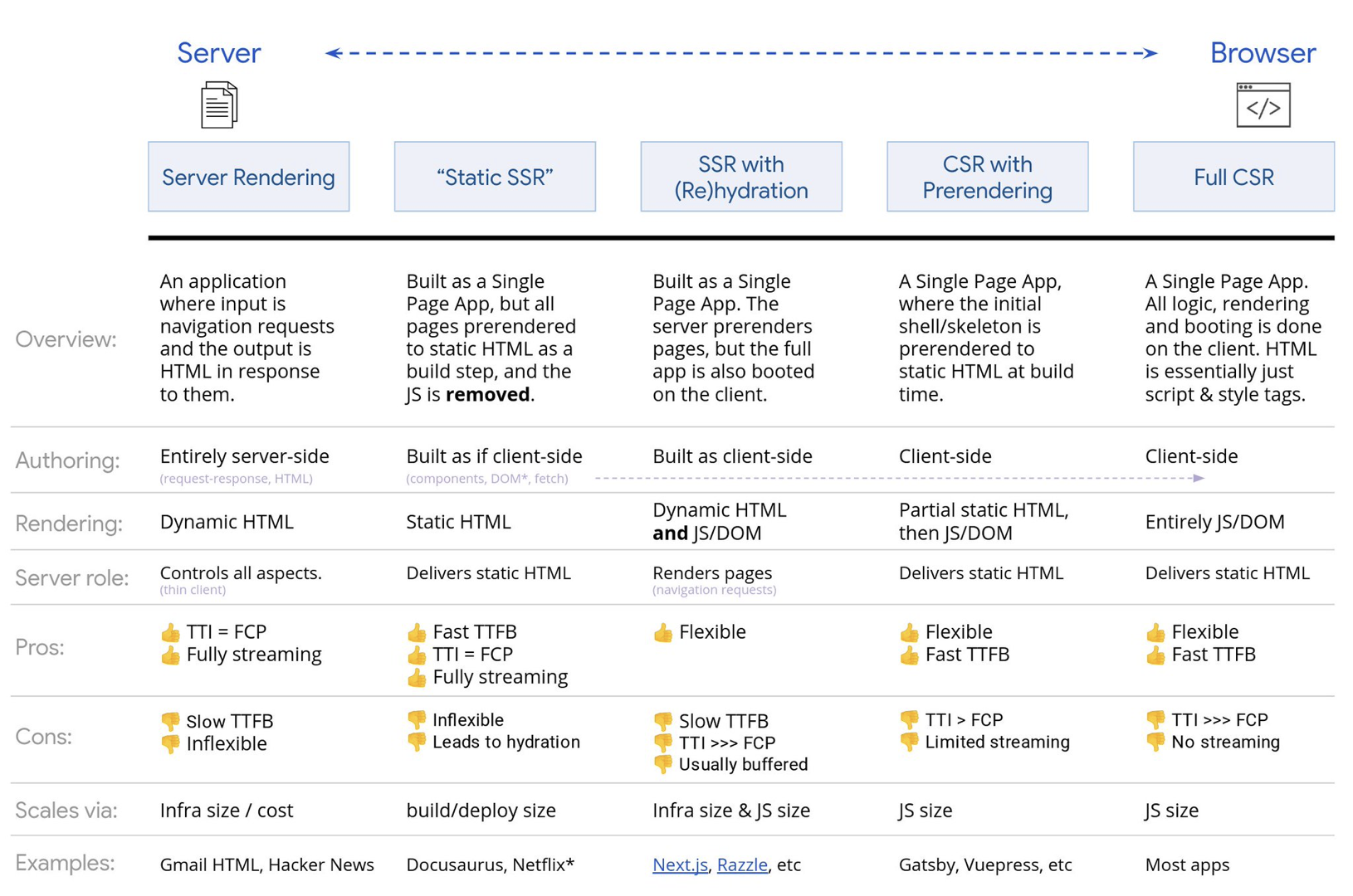
14. クライアントサイドレンダリングか、サーバサイドレンダリングか?答えは両方。
これはとても熱い議論が交わされるテーマです。 究極的なアプローチは、一種の段階的な起動を導入することでしょう。 つまり、サーバサイドレンダリングを使用してFirst Contentful Paintを高速化する一方、必要最低限のJavaScriptを導入し、Time To InteractiveがFirst Contentful Paintと乖離しないようにします。 JavaScriptがFCPよりも遅すぎる場合、ブラウザは、そのJavaScriptをパース、コンパイル、実行する間にメインスレッドをロックするため、サイトやアプリケーションのインタラクティブ性を低下させることとなります。
これを避けるには、関数の実行を個別の非同期タスクに常に分割し、可能な場合はrequestIdleCallbackを使用しましょう。
Webpackの動的なimport()サポートを利用してUIの一部の読み込みを遅延させることで、読み込み、パース、コンパイルのコストを、ユーザが本当に必要になるまで回避できないか検討してみましょう(Addyに感謝します)。
上記のとおり、Time To Interactive(TTI)は、ナビゲーションの時点とインタラクションが可能になる時点までの間の時間を表します。 厳密には、この指標は、最初のコンテンツのレンダリング後、所要時間が50ミリ秒を超えるJavaScriptタスク(ロングタスク)が存在しない状態が初めて5秒間続いた時点として定義されます。 50ミリ秒を超えるタスクが発生すると、5秒間の計測はやり直しです。 その結果、ブラウザが初めてインタラクティブになったかと思えば、すぐにインタラクティブでなくなり、最終的にはインタラクティブな状態に戻るという状況が起きます。
インタラクティブな状態に達すると、必要に応じて、あるいは時間が許す限り、アプリの本質的でない部分を起動することができます。 残念ながら、Paul Lewisが指摘したとおり、フレームワークは通常、開発者にも分かる単純な優先順位の概念を持っていません。 そのため、ほとんどのライブラリとフレームワークでは、段階的な起動を導入するのは簡単ではありません。
それでも、私たちは段階的な起動に近づいています。最近はいくつかの選択肢を検討できるようになりました。 Houssein DjirdehとJason MillerのRendering on the Webという講演と、JasonとAddyのモダンなフロントエンドアーキテクチャに関する記事は、こうした選択肢の全体像が分かる素晴らしい内容です。 以下の概要は、彼らの優れた成果に基づくものです。
-
フルサーバサイドレンダリング(SSR)
WordPressなどの古典的なSSRでは、すべてのリクエストは完全にサーバ上で処理されています。 リクエストされたコンテンツは、完成したHTMLページとして返送され、ブラウザはそれをすぐにレンダリングすることができます。 そのため、SSRアプリは、例えばDOM APIをあまり活用できません。 First Contentful PaintとTime To Interactiveのギャップは通常は小さく、HTMLがブラウザに送信された時点ですぐにページをレンダリングできます。
ブラウザが応答を得る前に処理が行われるため、データを取得し、クライアント側でテンプレートを作成するための追加的なラウンドトリップの必要はありません。 しかし、サーバのシンクタイム、ひいてはTime To First Byteが長くなり、モダンなアプリケーションのレスポンシブでリッチな機能は活用できません。
-
静的レンダリング
プロダクトはシングルページアプリケーションとしてビルドされますが、ビルドのステップの一環として、すべてのページが最小限のJavaScriptによって静的HTMLへとプリレンダリングされます。 このことは、静的レンダリングでは、あり得るすべてのURLに対して個別のHTMLファイルを事前に生成することを意味しますが、これは多くのアプリケーションにとって可能ではありません。 しかし、ページのHTMLをすぐに生成する必要はないため、一貫して高速なTime To First Byteを実現できます。 したがって、ランディングページを速く表示し、その後のページのSPAフレームワークを先読みすることが可能です。 Netflixはこのアプローチを採用し、読み込みとTime To Interactiveを50%削減しています。
-
サーバサイドレンダリングと(リ)ハイドレーション(ユニバーサルレンダリング、SSR + CSR)
SSRとCSRの両方のアプローチの良いとこ取りを目指すことも可能です。 ハイドレーションを利用する場合、サーバから返送されるHTMLページには、クライアントサイドの完全なアプリケーションを読み込むスクリプトも含まれています。 それによって、(SSRのように)高速なFirst Contentful Paintを実現し、それから(リ)ハイドレーションによるレンダリングを続けるのが理想です。 残念なことに、こうしたケースはまれです。 たいてい、ページの準備は整っているように見えるのに、ユーザの入力には応答できず、レイジクリックや離脱につながっています。
Reactでは、ExpressなどのNodeサーバで
ReactDOMServerモジュールを使用し、トップレベルのコンポーネントを静的なHTML文字列としてレンダリングするためにrenderToStringメソッドを呼び出すことができます。Vue.jsでは、vue-server-rendererを使用し、
renderToStringでVueインスタンスをHTMLにレンダリングすることが可能です。 Angularでは、@nguniversalを使用し、クライアントのリクエストを、サーバによって完全にレンダリングされたHTMLページに変換できます。 Next.js(React)やNuxt.js(Vue)では、完全なサーバサイドレンダリング体験を最初から実現可能です。このアプローチにはデメリットがあります。クライアントサイドアプリの完全な柔軟性を実現しつつ、高速なサーバサイドレンダリングを提供できる一方で、First Contentful PaintとTime To Interactiveのギャップが拡大し、First Input Delayが増加するのです。 リハイドレーションはコストがとても大きくなります。 この戦略だけでは、Time To Interactiveが大幅に遅くなるため、通常は十分ではありません。
-
ストリーミングサーバサイドレンダリングとプログレッシブハイドレーション(SSR + CSR)
Time To InteractiveとFirst Contentful Paintのギャップを最小限にするために、複数のリクエストを同時にレンダリングし、コンテンツが生成されるたびにチャンクとして送信します。 そのため、ブラウザにコンテンツを送信する前に完全なHTML文字列を待つ必要がなく、Time To First Byteが改善されます。
Reactでは、renderToString()の代わりにrenderToNodeStream()を使用することで、応答をパイプし、HTMLをチャンクで送信できます。 Vueでは、renderToStream()によるパイプとストリームが可能です。 React Suspenseでは、同じ目的に非同期レンダリングを使用できるでしょう。
クライアントサイドでは、アプリケーション全体を一度に起動するのではなく、コンポーネントを段階的に起動します。 まずアプリケーションのセクションをコード分割によって独立したスクリプトに分割し、次にそれを(優先順位に従って)徐々にハイドレートします。 つまり、クリティカルなコンポーネントを先にハイドレートし、残りは後でハイドレートすることができます。 クライアントサイドとサーバサイドのレンダリングの役割は、コンポーネントごとに異なる形で定義することが可能です。 また、コンポーネントが表示されるまで、またはそれがユーザとのインタラクションに必要になるまで、あるいはブラウザがアイドル状態になるまで、一部のコンポーネントのハイドレーションを遅らせることもできます。
Vueについては、Markus Oberlehnerが、ユーザとのインタラクションに応じたハイドレーションとvue-lazy-hydrationを使用してSSRアプリのTime To Interactiveを削減するためのガイドを公表しています。 vue-lazy-hydrationは、コンポーネントの表示や特定のユーザインタラクションに応じたハイドレーションを可能にする初期段階のプラグインです。 Angularチームは、Ivy Universalを使用してプログレッシブハイドレーションに取り組んでいます。 PreactとNext.jsでパーシャルハイドレーションを実装することもできます。
-
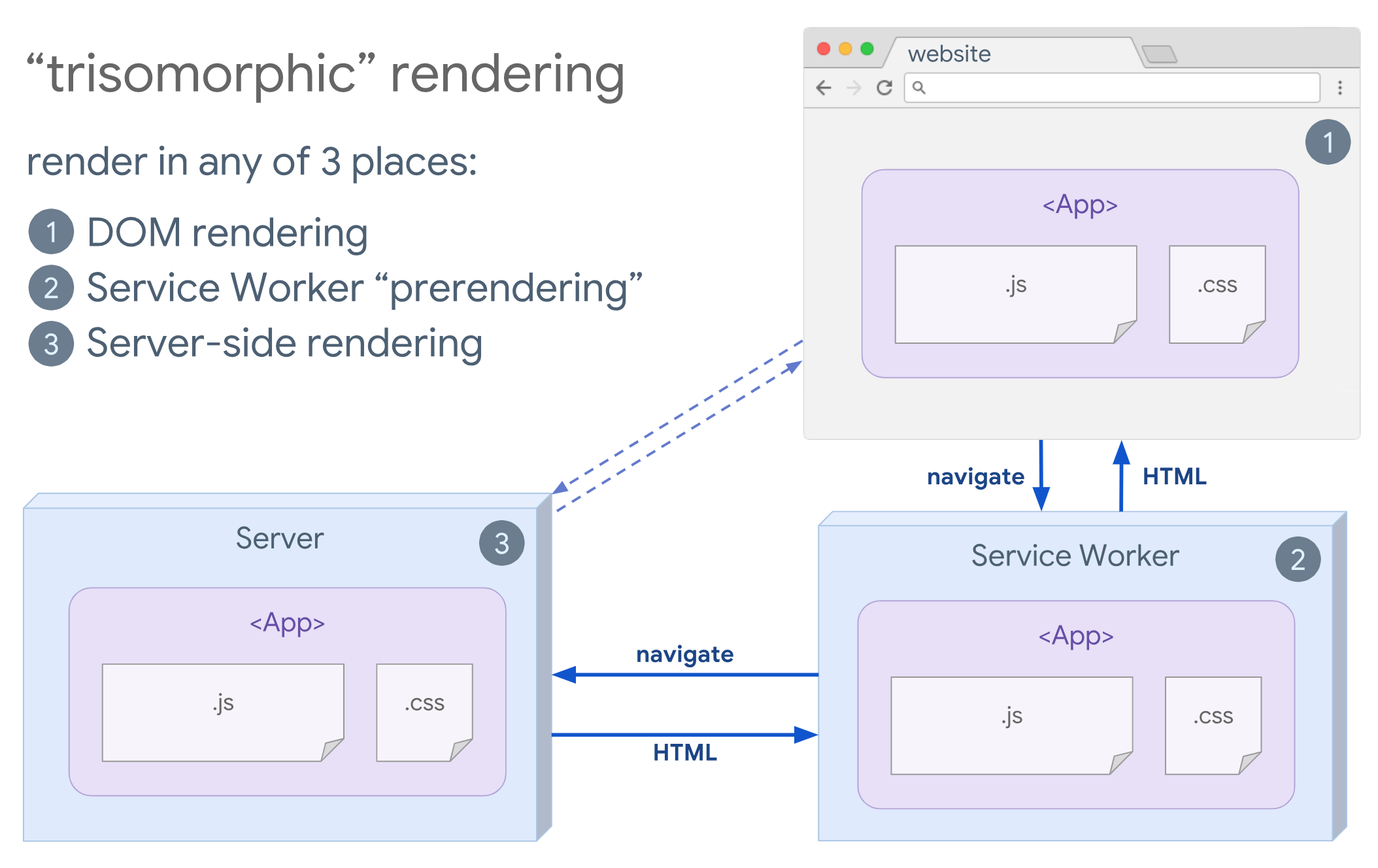
サービスワーカーを導入している場合、初期やJS以外のナビゲーションにはストリーミングサーバレンダリングを使用し、それらがインストールされた後に、サービスワーカーがナビゲーションのためのHTMLレンダリングに取りかかるようにすることができます。 この場合、サービスワーカーはコンテンツをプリレンダリングし、同一セッション内の新規ビューをレンダリングするためのSPAスタイルのナビゲーションを有効にします。 サーバ、クライアントページ、サービスワーカーの間で同じテンプレートやルーティングコードを共有できる場合に効果的です。
 トライソモルフィックレンダリングでは、サーバ、DOM、サービスワーカーの3カ所のどこでも同じコードをレンダリングします。(画像の出典:Google Developers)(プレビューを拡大)
トライソモルフィックレンダリングでは、サーバ、DOM、サービスワーカーの3カ所のどこでも同じコードをレンダリングします。(画像の出典:Google Developers)(プレビューを拡大) -
CSRとプリレンダリング
プリレンダリングはサーバサイドレンダリングに似ていますが、サーバでページを動的にレンダリングするのではなく、ビルドの際にアプリケーションを静的HTMLへレンダリングします。 静的なページは、クライアントサイドのJavaScriptがあまり存在しなくても完全にインタラクティブとなりますが、プリレンダリングの仕組みは異なっています。 基本的に、プリレンダリングは、ビルド時にクライアントサイドアプリケーションの初期状態を静的HTMLとして取得します。 一方で、ページをインタラクティブにするにはアプリケーションをクライアント側で起動する必要があります。
Next.jsでは、アプリを静的HTMLにプリレンダリングすることで、静的HTMLエクスポートを使用できます。 Reactを使用したオープンソースの静的サイトジェネレータであるGatsbyでは、
renderToStringメソッドの代わりにrenderToStaticMarkupメソッドをビルド時に使用しています。 シンプルな静的ページには不要なDOM属性を使わず、メインのJSチャンクをプリロードし、将来のルートをプリフェッチします。Vueでは、同じ目的を達成するためにVuepressを使用可能です。 Webpackではprerender-loaderも使用できます。 Naviも静的レンダリングを提供しています。
その結果、Time To First ByteとFirst Contentful Paintが改善し、両者のギャップが縮小します。 コンテンツが大きく変化すると予想される場合、このアプローチは使用できません。 また、すべてのページを生成するには、事前にすべてのURLを把握する必要があります。 一部のコンポーネントはプリレンダリングを使用してレンダリングできることもありますが、動的な要素が必要な場合は、コンテンツを取得するためにアプリに頼らなければなりません。
-
フルクライアントサイドレンダリング(CSR)
すべてのロジック、レンダリング、起動がクライアント側で実施されます。 そのため、通常はTime To InteractiveとFirst Contentful Paintの間に膨大なギャップが発生します。 結果として、一部をレンダリングするだけでもクライアント側でアプリ全体を起動する必要があるため、アプリケーションが遅く感じることがよくあります。 JavaScriptにはパフォーマンスコストがあるため、アプリケーションに応じてJavaScriptの量が増加すると、その影響を抑えるために、積極的なコード分割とJavaScriptの遅延が絶対に必要になります。 こうしたケースでは、インタラクティブ性があまり必要とされない場合に備え、通常はサーバサイドレンダリングを採用する方が良いアプローチとなるでしょう。 それが不可能な場合は、App Shellモデルの使用を検討してみましょう。
一般に、SSRはCSRよりも高速です。しかし、世の中の多くのアプリは、依然としてCSRを導入していることがよくあります。
結局、クライアントサイドとサーバサイドのどちらが良いのでしょうか。一般に、完全なクライアントサイドのフレームワークを使用するのは、それが絶対に必要なページだけに制限するのが良いでしょう。高度なアプリケーションでは、サーバサイドのレンダリングのみに頼るのも良い考えではありません。サーバレンダリングとクライアントレンダリングのどちらも、不完全だと悲惨なことになります。 CSRとSSRのどちらが好みであるにせよ、重要なピクセルは可能な限り早くレンダリングし、レンダリングとTime To Interactiveのギャップは最小限になるようにしましょう。ページがあまり変化しない場合はプリレンダリングを検討し、可能ならばフレームワークの起動を遅らせてみてください。サーバサイドレンダリングではHTMLをチャンクでストリームし、クライアントサイドレンダリングではプログレッシブハイドレーションを実装しましょう。そして、表示やインタラクションのタイミングで、あるいはアイドルタイムの間にハイドレーションを実施し、両者の良いとこ取りをしましょう。
 クライアントサイドとサーバサイドのレンダリングの選択肢をスペクトルで表しています。また、Google I/OでJasonとHousseinがアプリケーションのアーキテクチャによるパフォーマンスへの影響について議論した内容もチェックしてみましょう。(画像の出典:Jason Miller)(プレビューを拡大)
クライアントサイドとサーバサイドのレンダリングの選択肢をスペクトルで表しています。また、Google I/OでJasonとHousseinがアプリケーションのアーキテクチャによるパフォーマンスへの影響について議論した内容もチェックしてみましょう。(画像の出典:Jason Miller)(プレビューを拡大)
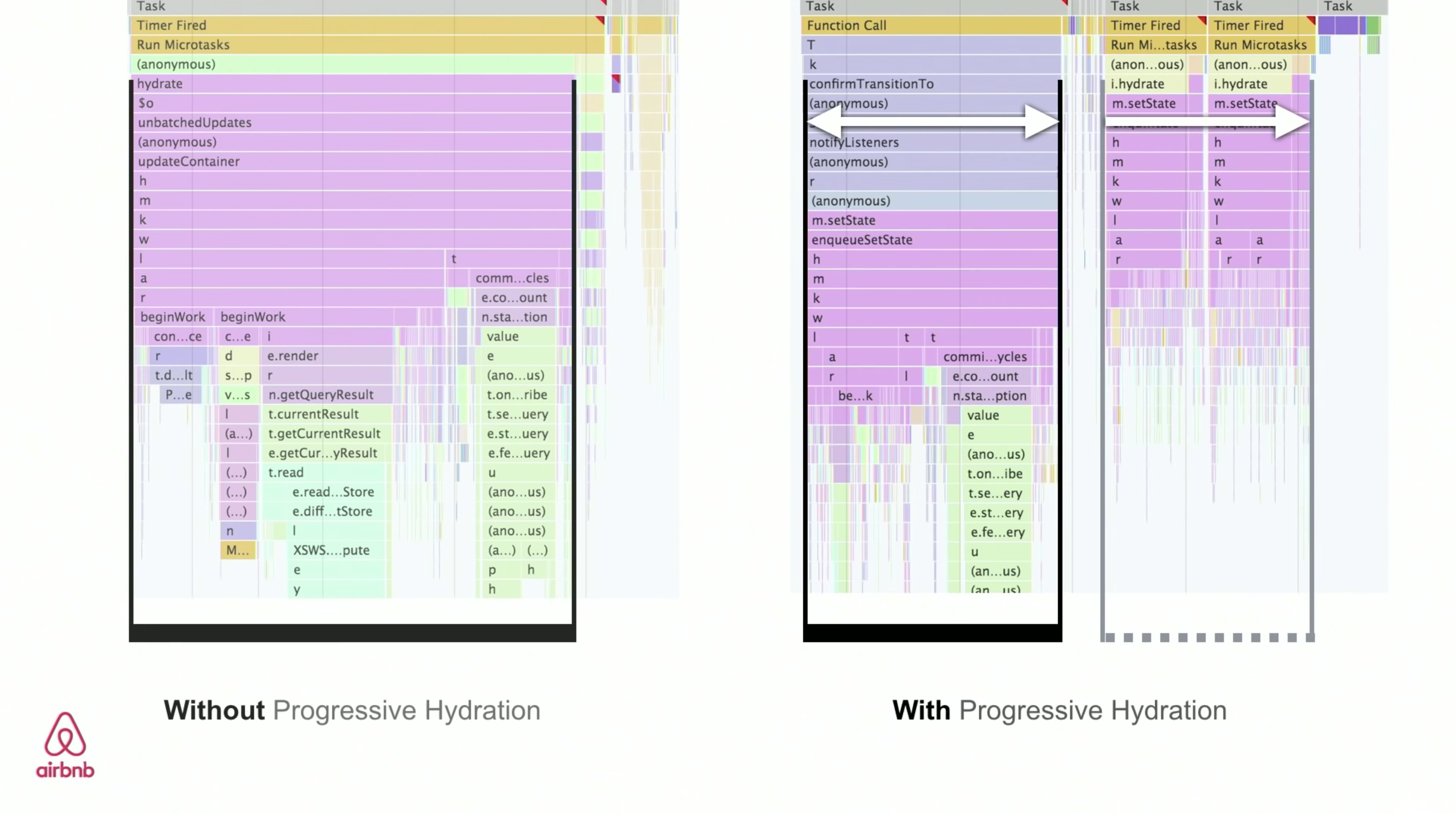
 AirBnBはプログレッシブハイドレーションの実験を実施しています。不要なコンポーネントを遅らせ、ユーザインタラクション(スクロール)に応じて、またはアイドルタイムの間に読み込んでいます。これにより、TTIが改善することがテストで判明しています。(プレビューを拡大)
AirBnBはプログレッシブハイドレーションの実験を実施しています。不要なコンポーネントを遅らせ、ユーザインタラクション(スクロール)に応じて、またはアイドルタイムの間に読み込んでいます。これにより、TTIが改善することがテストで判明しています。(プレビューを拡大)
15. どれだけのコンテンツを静的な状態で提供できるか?
開発しているのが大規模なアプリケーションであるにせよ、小規模なサイトであるにせよ、どのコンテンツなら、実行時に動的に生成するのではなくCDN(JAM Stack)から静的に提供できるかを検討することには価値があります。 無数のプロダクトとフィルタや、数多くのカスタマイズの選択肢があったとしても、クリティカルなランディングページを静的に提供し、あなたが選んだフレームワークからそれらのページを分離したいと思うかもしれません。
世の中には多くの静的サイトジェネレータがあり、ジェネレータが生成するページは通常、とても高速です。 リクエスト時にサーバやクライアントでページビューを生成するのではなく、事前にプリビルドするコンテンツが多いほど、優れたパフォーマンスを実現できます。
Markus Oberlehnerは、Building Partially Hydrated, Progressively Enhanced Static Websitesという記事で、プログレッシブエンハンスメントを実現し、JavaScriptのバンドル容量を最小限にしつつ、静的サイトジェネレータとSPAを使用してWebサイトを構築する方法を説明しています。 MarkusはツールとしてEleventyとPreactを使用しており、ツールの設定、パーシャルハイドレーションの追加、遅延ハイドレーション、クライアントエントリファイル、Preact向けのBabelの設定、RollupによるPreactのバンドルについて、始めから終わりまで解説しています。
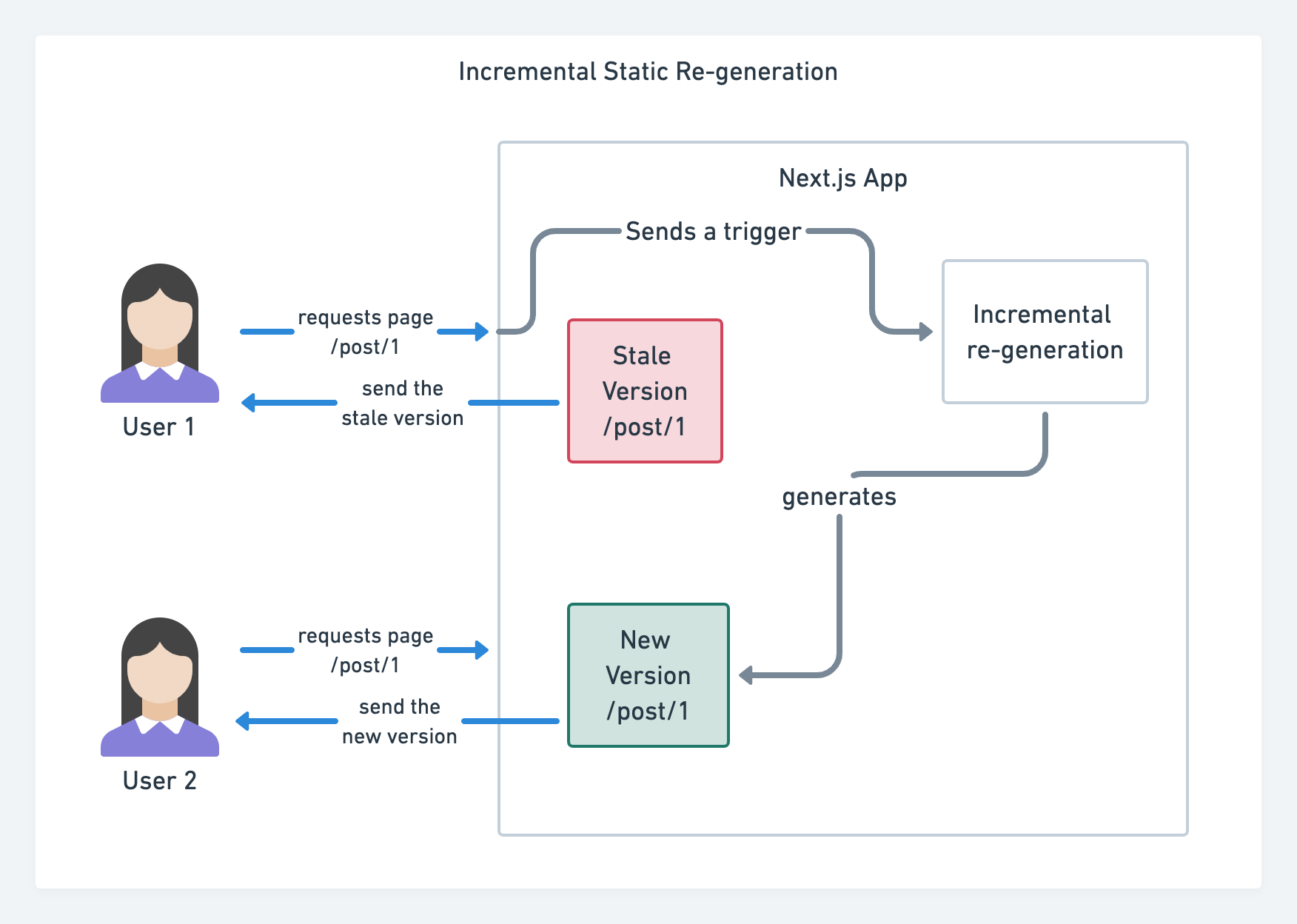
最近は大規模サイトでJAMStackが使用されるようになったことで、パフォーマンスに関して新たに検討すべき問題が出てきました。 その問題とはビルド時間です。 実際、新たなデプロイのたびに無数のページをビルドするのには数分間かかる可能性があります。 そのため、ビルド時間を60倍改善するGatsbyのインクリメンタルビルドを利用すると良いでしょう。 WordPress、Contentful、Drupal、Netlify CMSなどの一般的なCMSソリューションとのインテグレーション機能もあります。
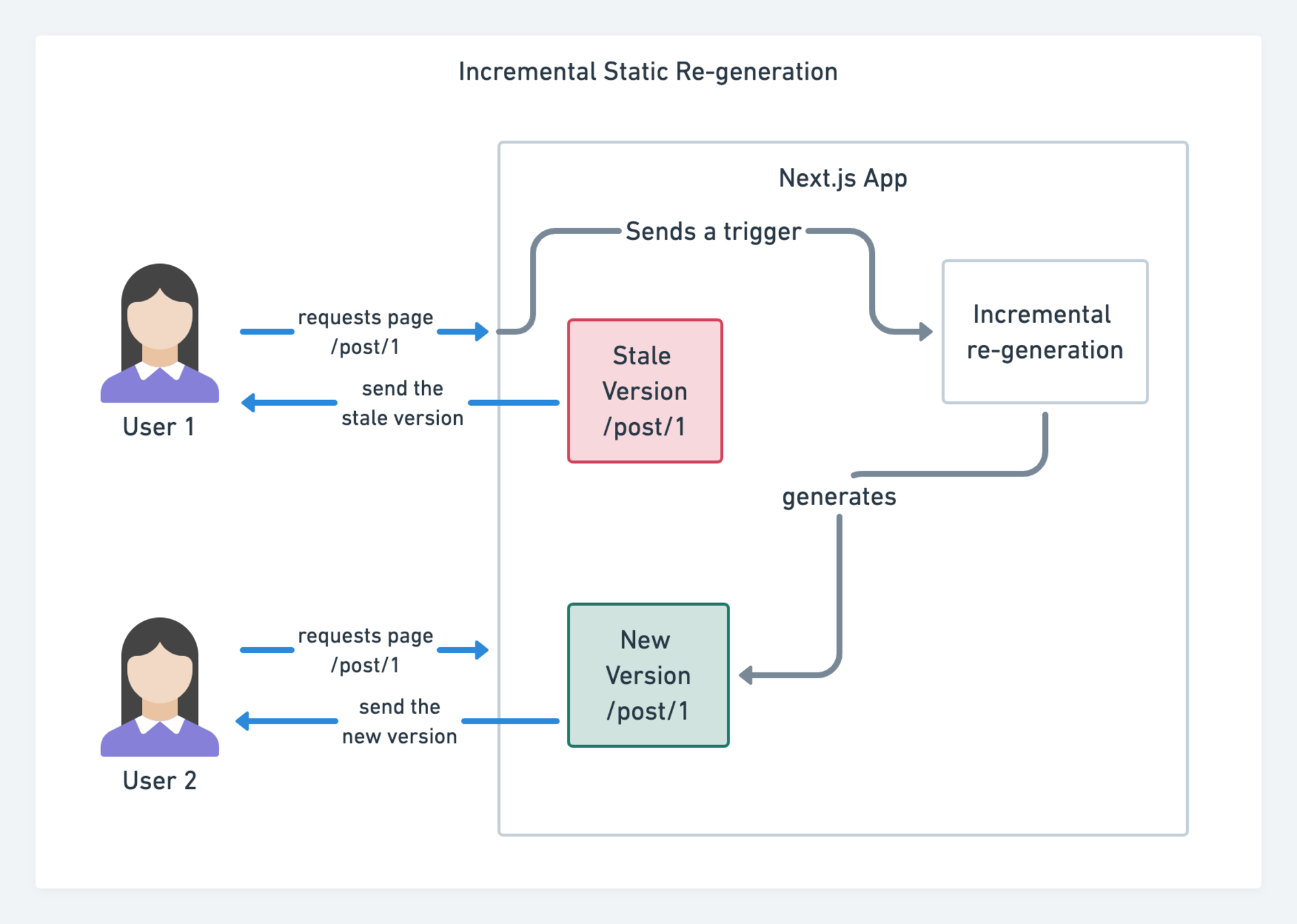 Next.jsによるインクリメンタルな静的サイト再生成。(画像の出典:Prisma.io)(プレビューを拡大)
Next.jsによるインクリメンタルな静的サイト再生成。(画像の出典:Prisma.io)(プレビューを拡大)
また、Next.jsは事前のインクリメンタルな静的サイト生成機能を発表しました。 この機能では、トラフィックの流入に伴い、バックグラウンドで再レンダリングを行うことで、ランタイムに新たな静的ページを追加し、既存のページがすでにビルドされた後も更新できるようになります。
もっとコストが軽いアプローチが必要な場合はどうすべきでしょうか。 Nicola Goutayは、Eleventy, Alpine and Tailwind: towards a lightweight Jamstackという講演で、CSR、SSRや両者の中間にあるものの違いや、コストが軽いアプローチを使用する方法を説明しています。 また、GitHubリポジトリではアプローチの実践方法も紹介しています。
16. PRPLパターンとアプリケーションシェルアーキテクチャの使用を検討する。
フレームワークによって、パフォーマンスに与える影響は違っており、異なる最適化戦略が必要とされます。 そのため、自分が使用するフレームワークの仕組みはすべて明確に理解しなければなりません。 Webアプリを開発するときは、PRPLパターンとアプリケーションシェルアーキテクチャについて検討しましょう。 考え方はとても単純です。 初期ルートが高速にレンダリングされるように、インタラクティブな状態を実現するために必要最小限のコードをプッシュし、サービスワーカーを使用したリソースのキャッシングとプリキャッシングを行います。 その後、必要なルートの非同期的な遅延読み込みを実施します。
 PRPLは、クリティカルなリソースのプッシュ(Pushing)、初期ルートのレンダリング(Rendering)、残りのルートのプリキャッシング(Pre-caching)、残りのルートの必要に応じた遅延読み込み(Lazy-loading)の頭文字を表します。
PRPLは、クリティカルなリソースのプッシュ(Pushing)、初期ルートのレンダリング(Rendering)、残りのルートのプリキャッシング(Pre-caching)、残りのルートの必要に応じた遅延読み込み(Lazy-loading)の頭文字を表します。
 アプリケーションシェルとは、ユーザインタフェースの機能に必要な最小限のHTML、CSS、JavaScriptです。
アプリケーションシェルとは、ユーザインタフェースの機能に必要な最小限のHTML、CSS、JavaScriptです。
17. APIのパフォーマンスを最適化しているか?
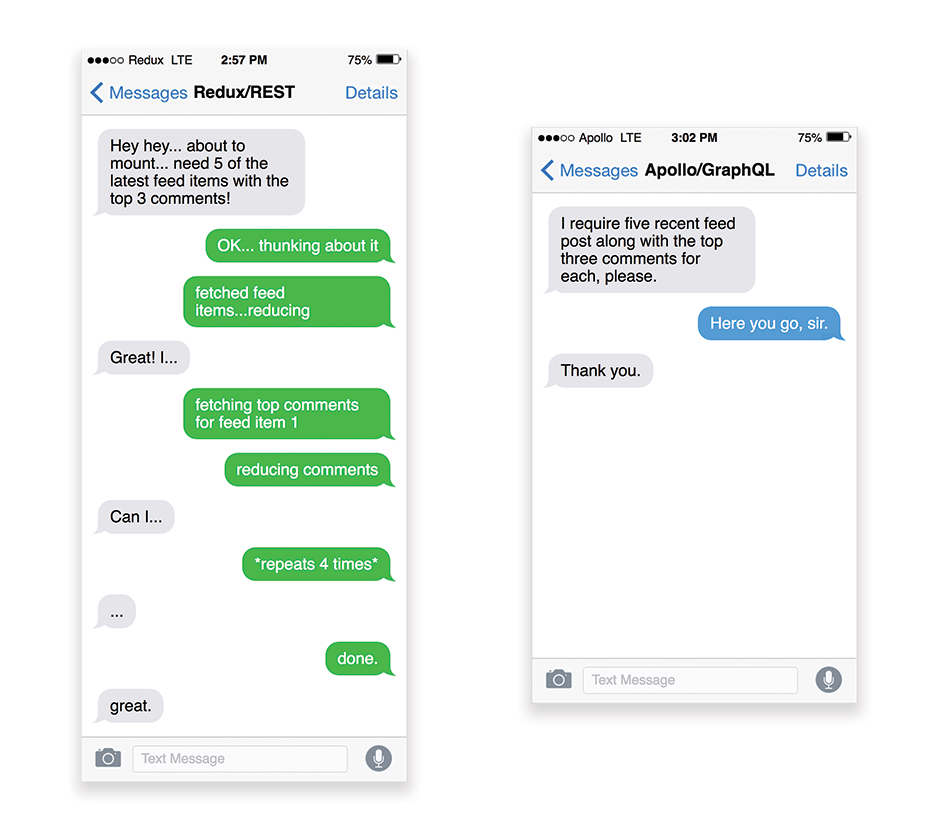
APIは、アプリケーションがエンドポイントを通じて内部やサードパーティのアプリケーションにデータを提供するための通信チャネルです。 APIのデザインとビルドをするときは、サーバとサードパーティのリクエストの間の通信を可能にする妥当なプロトコルが必要です。 Representational State Transfer(REST)は、そのようなプロトコルの中で、定評ある合理的な選択肢です。 RESTでは、パフォーマンスと信頼性が高いスケーラブルな方法でコンテンツをアクセス可能にするために、開発者が従うべき一連の制約を定めています。 RESTの制約に従うWebサービスは、RESTfulなWebサービスと呼ばれます。
古き良きHTTPリクエストと同様に、APIからデータが取得される場合、サーバの応答の遅れはエンドユーザにも波及し、そのためレンダリングが遅延します。 リソースが何らかのデータをAPIから取得する場合、対応するエンドポイントからデータをリクエストする必要があります。 コメント、および各コメントの筆者の写真が付属している記事など、複数のリソースからデータをレンダリングするコンポーネントは、レンダリングが可能になる前に、すべてのデータを取得するためにサーバとの間で複数回のラウンドトリップが必要になるかもしれません。 さらに、RESTを通じて返されるデータの量は、コンポーネントのレンダリングに必要な量を超えていることがよくあります。
多くのリソースがAPIからのデータを必要とする場合、APIがパフォーマンスのボトルネックとなりかねません。
GraphQLは、こうした問題の有効な解決策となります。 GraphQLはいわば、API向けのクエリ言語であり、データ用に定義した型システムを使用してクエリを実行するためのサーバサイドのランタイムです。 RESTとは異なり、GraphQLは1度のリクエストですべてのデータを取得できます。 返されるデータは必要なちょうどの量となっており、RESTでよくある過大なデータや過少なデータの取得は起きません。
さらに、GraphQLはスキーマ(データの構造に関するメタデータ)を使用しているため、好きな構造にデータを組織することが可能です。 例えば、GraphQLなら、状態管理を処理するためのJavaScriptコードを削除することで、以前よりもクリーンなアプリケーションコードを生成し、クライアント側での実行を高速化できます。
GraphQLを始めたい場合や、パフォーマンスに関する問題に直面している場合は、以下の記事が良い参考になるかもしれません。
- A GraphQL Primer: Why We Need A New Kind Of API(Eric Baer著)
- A GraphQL Primer: The Evolution Of API Design(Eric Baer著)
- Designing a GraphQL server for optimal performance(Leonardo Losoviz著)
- GraphQL performance explained(Wojciech Trocki著)
 RESTとGraphQLの差を現した図。左側はRedux + REST、右側はApollo + GraphQLとの対話を表しています。(画像の出典:Hacker Noon)(プレビューを拡大)
RESTとGraphQLの差を現した図。左側はRedux + REST、右側はApollo + GraphQLとの対話を表しています。(画像の出典:Hacker Noon)(プレビューを拡大)
18. AMPとInstant Articlesのどちらを使用するか?
組織の優先課題と戦略に応じて、GoogleのAMP、FacebookのInstant Articles(※訳注:原文指定URL消失)、あるいはAppleのApple Newsの使用を検討すると良いかもしれません。 これらがなくても優れたパフォーマンスを実現することはできますが、AMPは堅固なパフォーマンスフレームワークと無料のコンテンツデリバリネットワーク(CDN)を提供します。 一方、Instant ArticlesはFacebook上の表示とパフォーマンスを改善します。
こうした技術には、パフォーマンスが保証されるというユーザにとって明確なメリットがあるように思われます。 ですから、場合によっては、サイズが膨大な可能性がある「通常の」ページよりも、AMP、Apple News、Instant Articlesのページへのリンクの方が好まれることさえあるでしょう。 大量のコンテンツを搭載し、多くのサードパーティコンテンツを扱うWebサイトにとって、こうした選択肢は、レンダリング時間を劇的に高速化するのに役立つ可能性があります。
しかし、必ずしもそうとは限りません。 Tim Kadlecによれば、例えば「AMPドキュメントは他のドキュメントよりも高速な傾向がありますが、それは必ずしもページのパフォーマンスが高いということを意味しません。 AMPは、パフォーマンスの観点で特に大きな違いをもたらすものではないのです」。
Webサイトの所有者にとってのメリットは明確です。 こうしたフォーマットは、各プラットフォーム上で見つけやすく、検索エンジンにおいて見やすくなります。
少なくとも、以前まではそうでした。 AMPはトップストーリーに表示されるための必要条件ではなくなったため、パブリッシャはAMPから離れ、従来の方式に回帰する可能性があります(Barryに感謝します)。
それでも、AMPをPWAのデータソースとして再利用することで、プログレッシブWeb AMPを構築することも可能です。 デメリットはあるでしょうか。 当然ながら、クローズドプラットフォームでの表示のために、開発者は異なるバージョンのコンテンツを生成・維持する必要があります。 Instant ArticlesとApple Newsの場合は、そのバージョンには実際のURLが存在しないこととなります(AddyとJeremyに感謝します)。
19. CDNを賢く選ぶ。
上記のとおり、データが動的である度合いによっては、コンテンツの一部を静的サイトジェネレータに「アウトソース」できるかもしれません。 これをCDNにプッシュし、そこから静的なバージョンのコンテンツを提供すれば、サーバへのリクエストを回避することが可能です。 もっと言えば、こうしたジェネレータの一部は、実際にはWebサイトのコンパイラであり、最初から多くの自動最適化機能が提供されています。 コンパイラが徐々に最適化を進めるため、コンパイルの出力も時とともに小さく、高速になります。
注目すべき点として、CDNは動的なコンテンツも提供(およびオフロード)することができます。 ですから、CDNを静的なアセットに限定する必要はありません。 利用しているCDNが圧縮と変換(例:エッジでの画像の最適化とサイズ変更)を行っているか、CDNがサーバワーカー、A/Bテスト(CDNのエッジ(サーバがユーザと最も近い部分)でページの静的な部分と動的な部分を組み立てるエッジ処理を含む)などのタスクに対応しているかをダブルチェックしましょう。 また、利用しているCDNがHTTP over QUIC(HTTP/3)をサポートしているか確認しましょう。
Katie HempeniusはCDNの素晴らしいガイドを執筆しており、優れたCDNの選び方、それを微調整する方法、CDNを評価するときに留意が必要なあらゆる細かい事項に関する情報を提供しています。 一般に、コンテンツは可能な限り積極的にキャッシュし、Brotli、TLS 1.3、HTTP/2、HTTP/3などのCDNのパフォーマンス関連機能を有効化すると良いでしょう。
注記:Patrick MeenanとAndy Daviesの調査によれば、HTTP/2における優先度の制御は、多くのCDNでは実質的に機能していないため、CDNを選択するときは気を付けましょう。
Patrickは、自らの講演でHTTP/2における優先度の制御について詳しく説明しています(Barryに感謝します)。
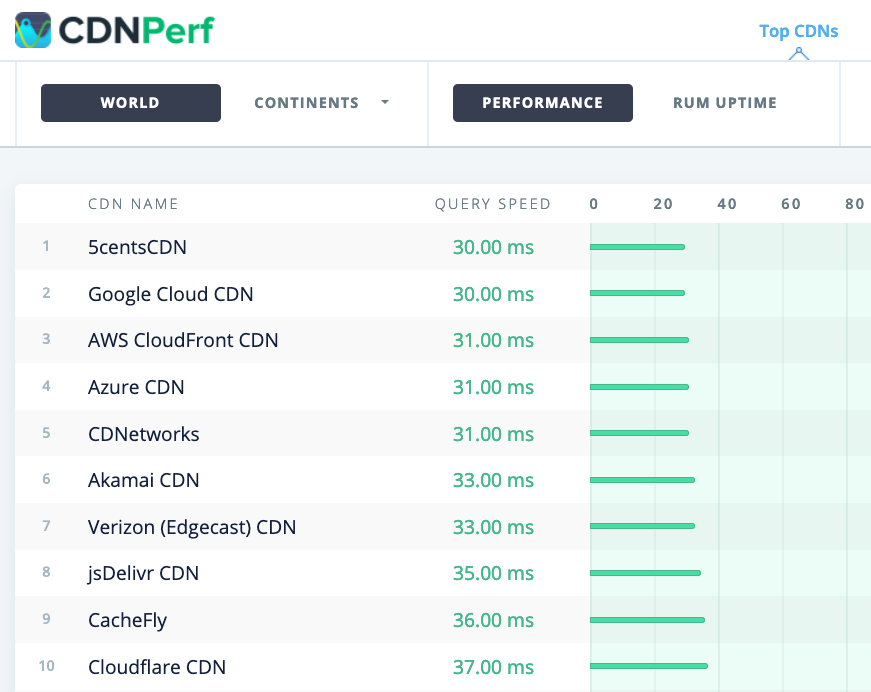
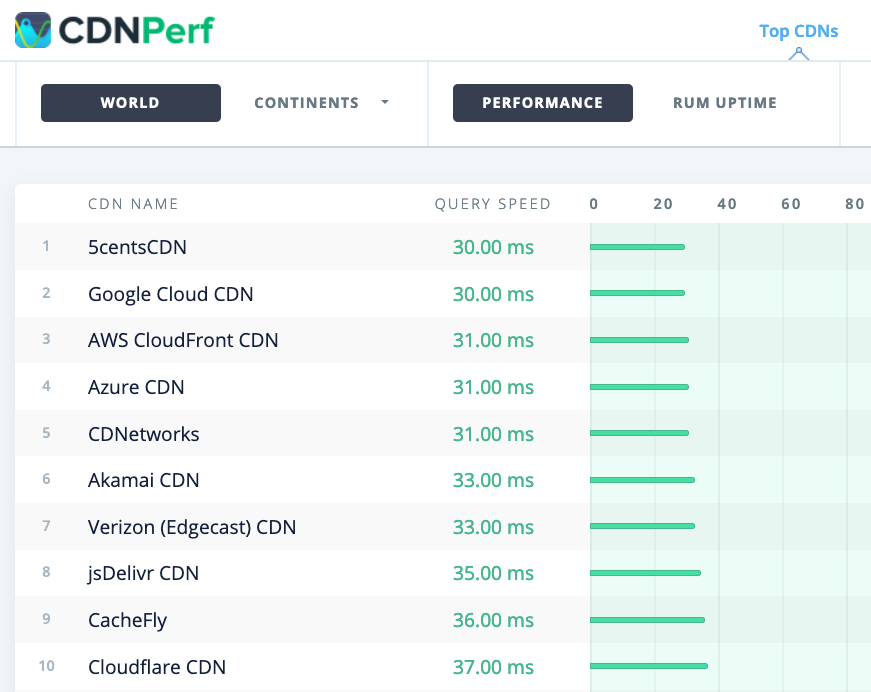 CDNPerfは、毎日3億件のテストを収集・分析することにより、CDNのクエリの速度を測定します。(プレビューを拡大)
CDNPerfは、毎日3億件のテストを収集・分析することにより、CDNのクエリの速度を測定します。(プレビューを拡大)
CDNを選ぶときは、以下の比較サイトで、機能の詳細を確認することができます。
- CDN Comparisonは、Cloudfront、Azure、KeyCDN、Fastly、Verizon、Stackpach、Akamaiなどの数多くのCDNの比較表です。
- CDN Perfは、毎日3億件のテストを収集・分析することにより、CDNのクエリの速度を測定します。すべてのテスト結果は世界中のユーザのRUMデータに基づいています。DNS Performance ComparisonとCloud Peformance Comparisonも確認してみましょう。
- CDN Planet Guidesでは、Serve Stale、Purge、Origin Shield、Prefetch、Compressionなどの個別のトピックに関して、CDNの概要を説明しています。
- Web Almanac:CDN Adoption and Usageは、上位のCDNプロバイダ、そのRTTとTLSの管理、TLSネゴシエーションタイム、HTTP/2の導入などに関する情報を提供します(残念ながら、データは2019年以降のものに限られます)。
<中編に続く>
※編注:本記事は2021年4月時点に公開されていた原文記事を翻訳した内容となります。翻訳記事公開にあたり、2023年6月時点で原文にてリンク切れとなっている箇所の削除や注記、原文に現在表示されていない内容を掲載している場合がございます。ご了承ください。

株式会社リクルート プロダクト統括本部 プロダクト開発統括室 グループマネジャー 株式会社ニジボックス デベロップメント室 室長 Node.js 日本ユーザーグループ代表
- X: @yosuke_furukawa
- Github: yosuke-furukawa
関連記事







{kind=link}
{kind=link}
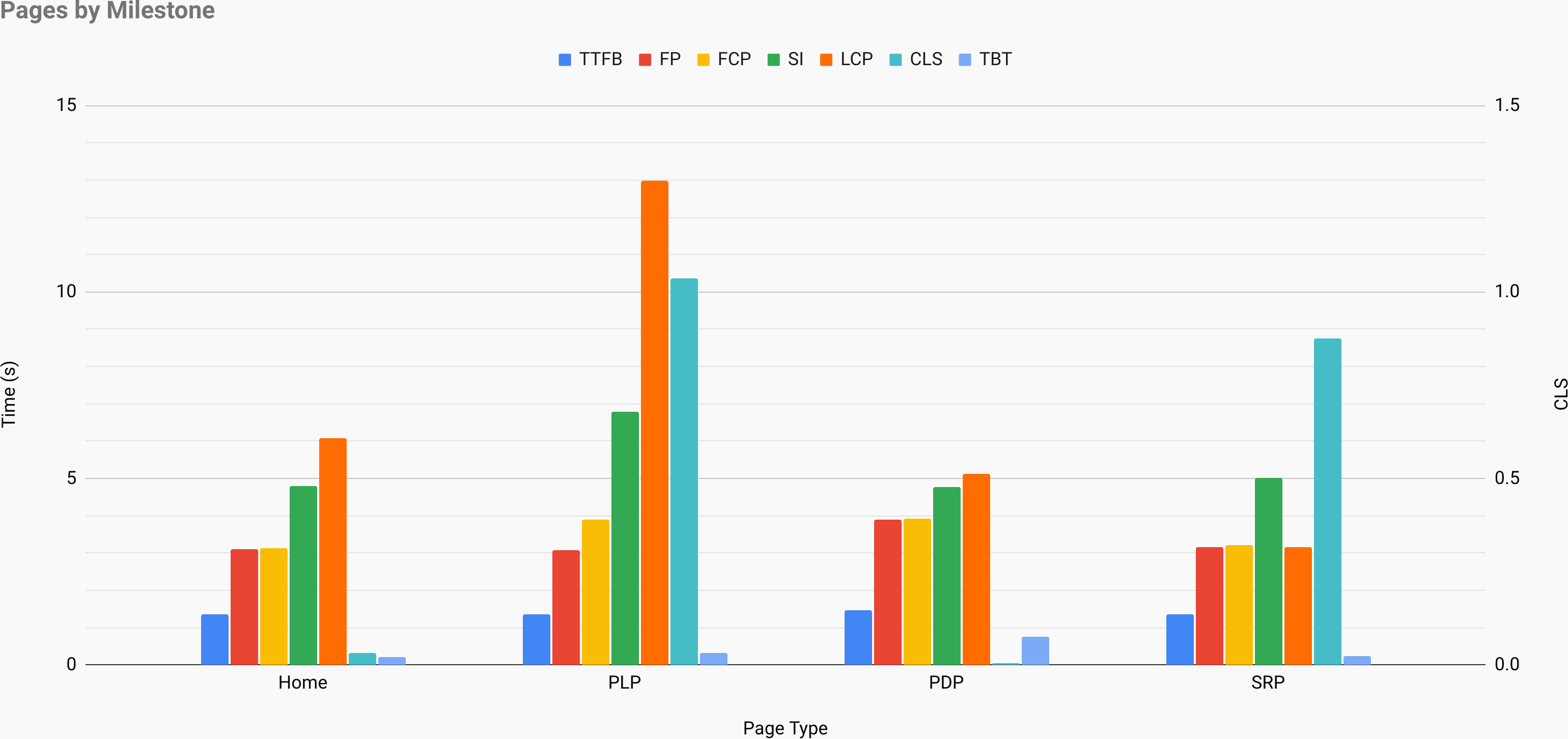{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}