2018年9月27日
分岐予測の簡単な歴史 – Part 2
本記事は、原著者の許諾のもとに翻訳・掲載しております。
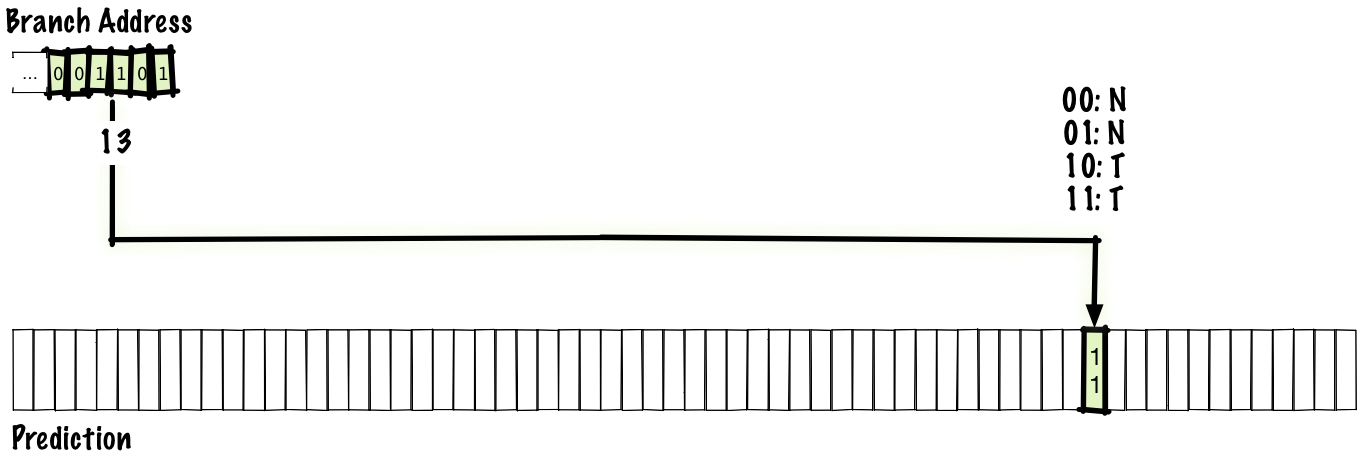
2ビット方式
1ビット方式は TTTTTTTT… や NNNNNNN… といったパターンにはうまく働きますが、 ...TTTNTTT... のような「ほとんど成立するが1回だけ不成立」のような分岐の流れでは予測ミスが起きてしまいます。それを改善するために登場したのが、各アドレスに対してもう1ビット追加した飽和カウンタです。では仮に、分岐が不成立だった時はマイナス1、成立した時はプラス1するとしましょう。バイナリ値で見ると以下のようになります。
00: Not(不成立)と予測
01: Not(不成立)と予測
10: Taken(成立)と予測
11: Taken(成立)と予測飽和カウンタの「飽和」とは、 00 にマイナス1した場合はそれ以上値が小さくならずに 00 のまま、 11 にプラス1した場合も 11 のままという動作を取ることを指しています。この方式は1ビット方式とほぼ同一ですが、唯一違うのは予測テーブルの各エントリが1ビットでなく2ビットであるという点です。
1ビット方式に比べると、2ビット方式は同じサイズ/コストで半分のエントリしか持てませんが(飽和カウンタのロジックに必要なコストは無視して記憶領域のコストだけ考えた場合)、それでも手頃なテーブルサイズの場合は大抵、2ビット方式の方が精度が高くなります。
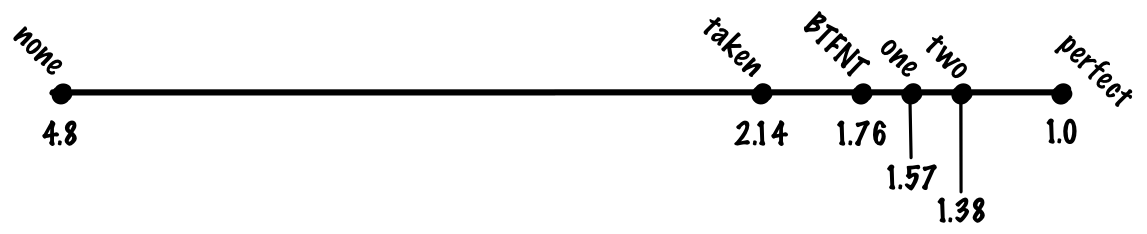
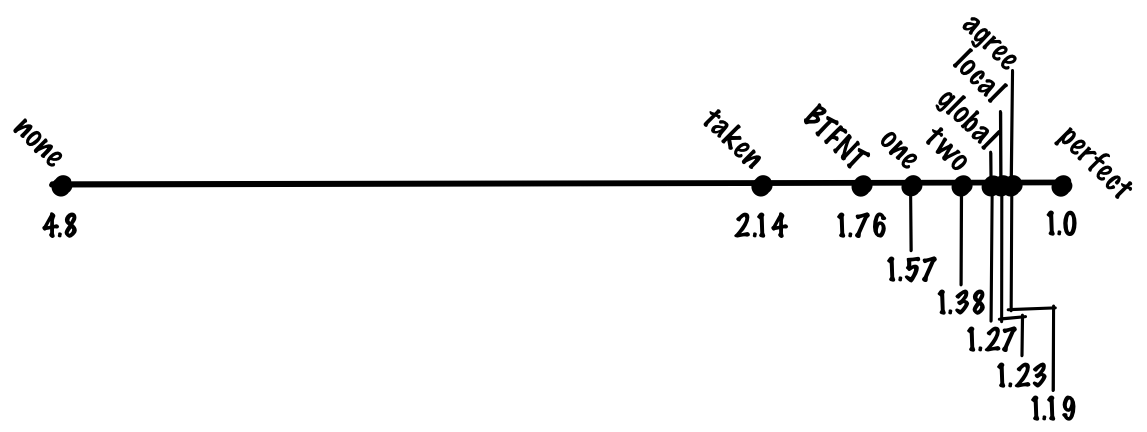
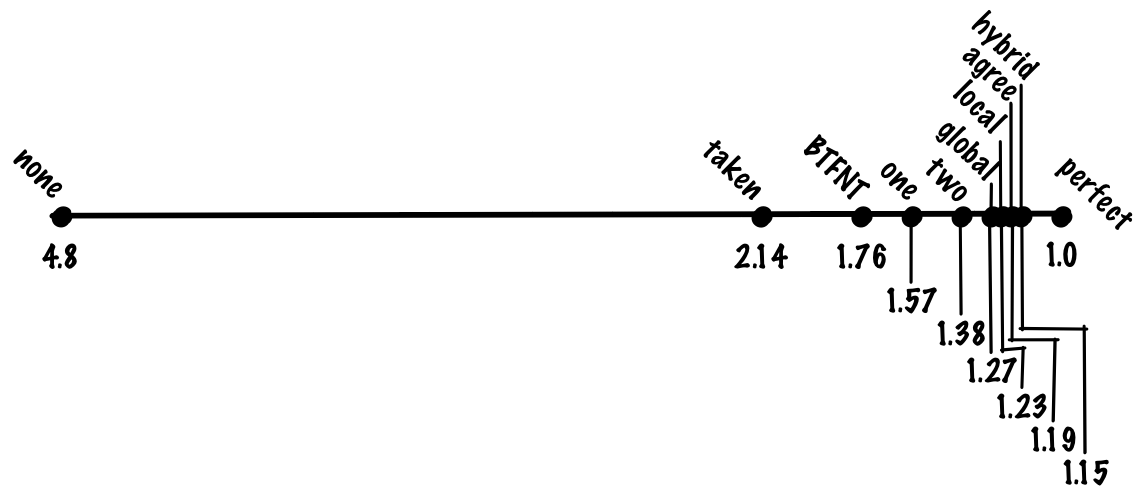
この2ビット予測器は単純ながらもかなりうまく働き、精度はおおむね90%、1命令当たりのコストは1.38サイクルとなります。
普通に考えると、この方式を一般化してnビットの飽和カウンタを導入できそうですが、ビット数をさらに増やしても精度の上では比較的小さな効果しか得られないことが分かっています。分岐予測器のコストについてはきちんと触れていませんでしたが、1分岐当たり2ビットから3ビットに増やすとテーブルサイズが1.5倍になる割にメリットはほとんどなく、多くの場合そのコストに見合いません。2ビット方式でうまく予測できない最も単純かつ一般的なパターンは NTNTNTNTNT... や NNTNNTNNT… ですが、これらはnビットに増やしたとしてもうまく予測できないのです。
使用
- LLNL S-1(1977)
- CDC Cyber?(1980年代初め)
- Burroughs B4900(1982):状態が命令ストリーム中に格納される。ハードウェアは命令を上書きして、分岐状態を更新する
- Intel Pentium(1993)
- PPC 604(1994)
- DEC EV45(1993)
- DEC EV5(1995)
- PA 8000(1996):正確には、多数決回路の3ビットシフトレジスタ
グローバル履歴2レベル適応型 (1991)
次のようなコードがあるとします。
for (int i = 0; i < 3; ++i) {
// code here.
}これを実行すると、 TTTNTTTNTTTN... のような分岐パターンを取ります。
この分岐の直近3回の実行結果が分かっていれば、次回の実行結果も予測できるはずです。
TTT:N
TTN:T
TNT:T
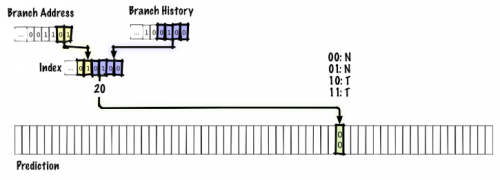
NTT:T前述の方式は、分岐アドレスのインデックスをテーブルに登録し、最近の履歴を基に分岐の成否を予測するものでした。それで分岐の偏りの方向は予測できるものの、繰り返しパターンの最中かどうかまでは分かりません。その点を改善するために、直近の分岐結果の履歴と予測テーブルを持つようにするのです。
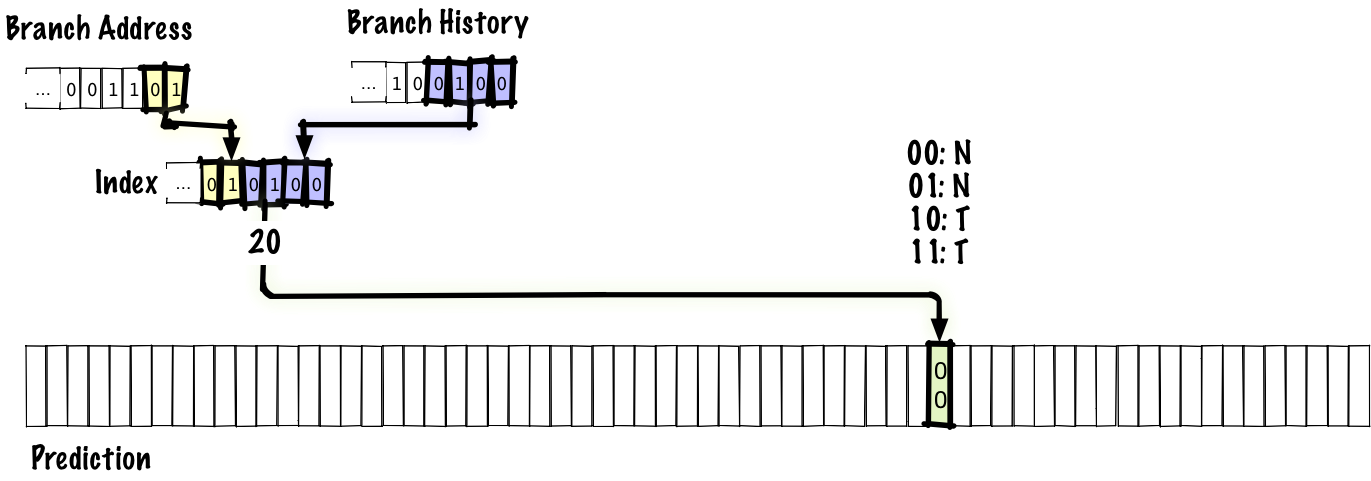
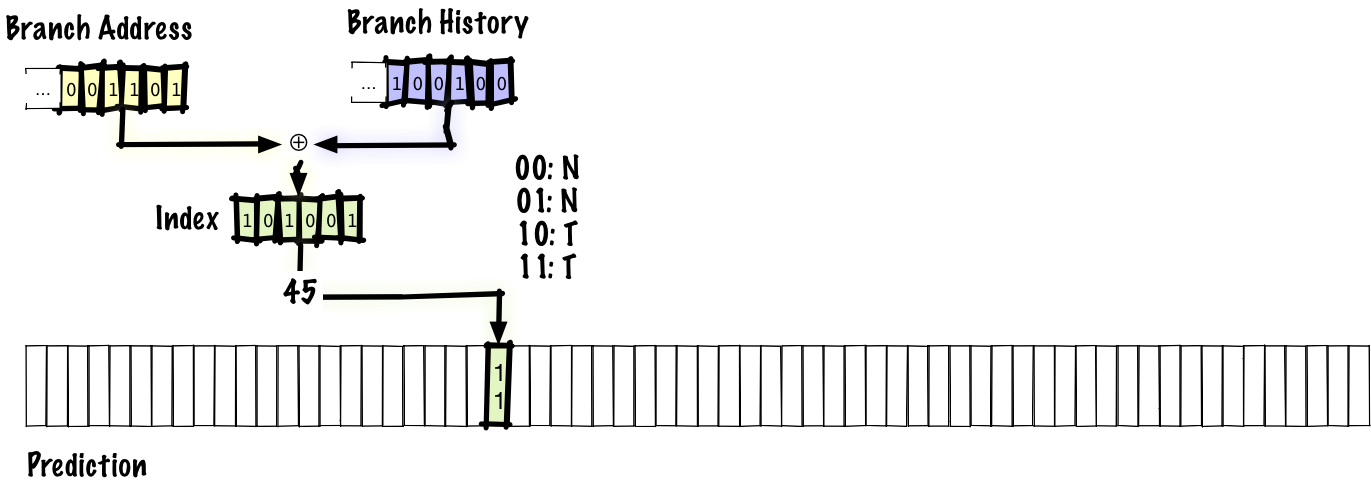
この例では、分岐履歴の4ビットと分岐アドレスの2ビットを連結し、予測テーブルにインデックス付けしています。これまでと同様、予測は2ビット飽和カウンタで行います。分岐履歴は、単に予測テーブルにインデックス付けするだけにはしたくありません。そうした場合、履歴の同じ2つの予測がどれも、同じテーブルエントリにエイリアスされてしまうからです。実際の予測器ではもっと大きなテーブルともっと多くの分岐アドレスを使うことになるでしょうが、スライド内に収まるよう、長さが6ビットしかないインデックスで説明していきます。
以下は、分岐を実行した時の更新の様子を示した図です。
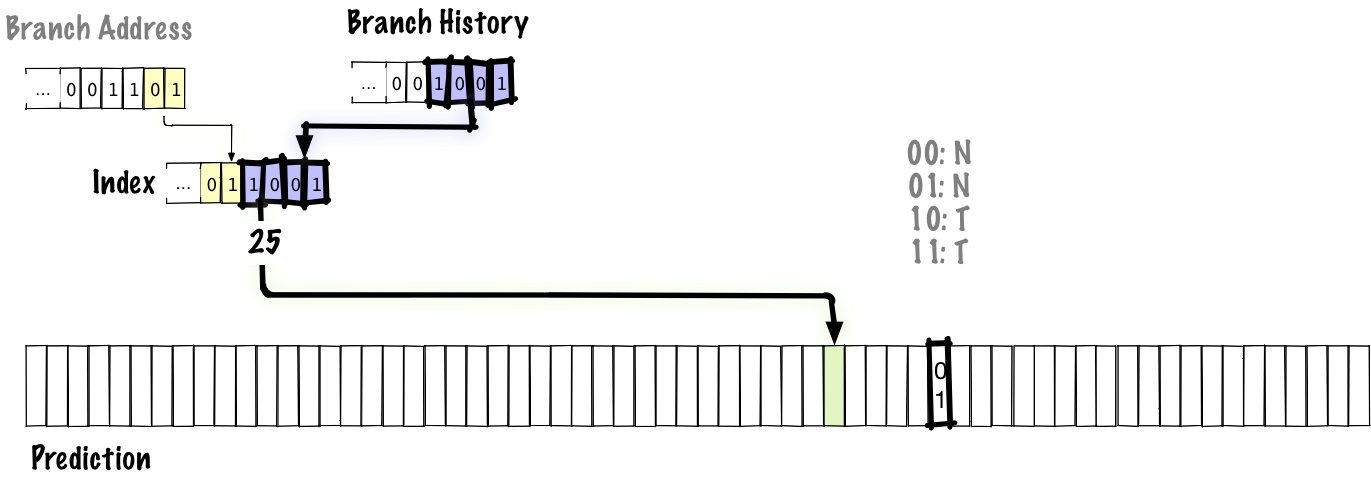
太い線で示したのが更新された部分です。この図では、分岐履歴の新しいビットが右から左にシフトインされ、分岐履歴が更新されています。分岐履歴が更新されると、予測テーブルに登録されるインデックスの下位ビットが更新されます。よって、次に同じ分岐を再び実行する際には、インデックスが分岐アドレスで固定されていた前述の方式とは異なり、テーブル内の別のエントリを使って予測を行います。古いエントリの値は更新されるので、次に同じ分岐履歴で同じ分岐を再び実行する時には予測が更新されていることになるのです。
この方式で使われるのはグローバル履歴であることから、内側のループ内の NTNTNTNT… といったパターンは正しく予測できるものの、上位レベルの分岐については必ずしも正しく予測できないかもしれません。グローバル履歴は他の分岐からの情報によって汚染されてしまうからです。その一方、ローカル履歴のテーブルを保持するよりもグローバル履歴の方がコストが低いという利点もあります。その上、グローバル履歴を使うと、相関のある複数の分岐を正しく予測できます。例えば、以下のコードがあるとしましょう。
if x > 0:
x -= 1
if y > 0:
y -= 1
if x * y > 0:
foo()最初の分岐と2つ目の分岐の一方が不成立なら、3つ目の分岐は明らかに不成立となるのです。
この方式では、精度はおおむね93%、1命令当たりのコストは1.27サイクルとなります。
使用
- Pentium MMX(1996):4ビットのグローバル分岐履歴
ローカル履歴2レベル適応型 [1992]
前述のように、グローバル履歴方式の問題は、きれいに予測されたローカル分岐の分岐履歴が他の分岐によって汚染されてしまうことでした。
ローカル分岐予測を適切に行うための1つの方法は、別の分岐には別の分岐履歴を記憶するようにすることです。
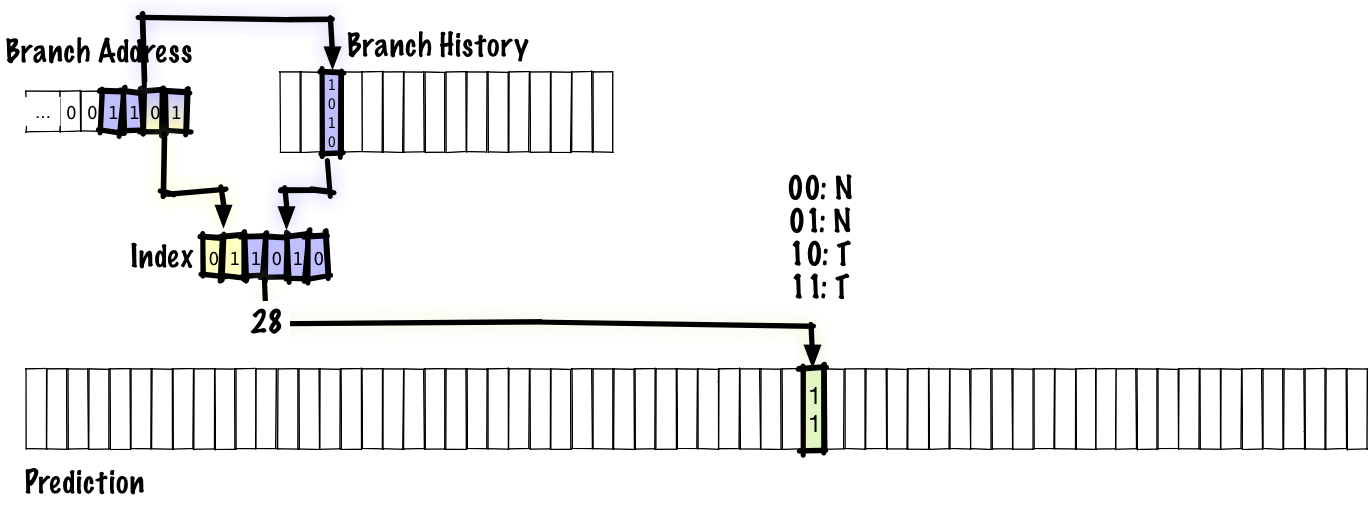
単一のグローバル履歴を記憶するのではなく、分岐アドレスでインデックス付けされたローカル履歴テーブルを保持するのです。この方式は直前に見たグローバル方式とほぼ同一で、唯一違うのは複数の分岐履歴を保持するということです。見方によっては、グローバル履歴を持つことはローカル履歴の特殊ケース、つまり追跡する履歴の数が 1 のケースと考えることもできます。
この方式では、精度はおおむね94%、1命令当たりのコストは1.23サイクルとなります。
使用
- Pentium Pro(1996): 4ビットのローカル分岐履歴。PCの下位ビットをインデックスに使用 。ただしこれには異論があり、Agner FogはPPro以降のプロセッサが4ビットのグローバル履歴を用いていると主張
- Pentium II(1997):PProと同様
- Pentium III(1999):PProと同様
gshare
グローバル履歴2レベル方式で妥協が必要となるのは、予測テーブルのサイズが固定されるため、分岐履歴専用のビットと分岐アドレス専用のビットを決めておかなくてはならないことです。分岐履歴に当てるビットを増やせば、より遠距離の相関を扱うことができ、より複雑なパターンも追跡できます。一方、分岐アドレスに当てるビットを増やせば、相関のない分岐間の干渉を回避することができます。
その両方を実現させる方法は、分岐履歴と分岐アドレスを連結するのではなく、両者をハッシュすることです。最初に提案された仕組みは、非常にシンプルで合理的なものでした。両者の xor を取るのです。ビットを xor するこの2レベル適応型方式は、 gshare と呼ばれています。
この方式の精度はおおむね94%です。先ほど見たローカル履歴方式と同等ですが、gshareではローカル履歴の大きなテーブルを保持する必要はありませんから、追跡すべき状態が少ない上で同等の精度が得られるというのは大幅な向上です。
使用
- MIPS R12000(1998): 2Kエントリ、PCに11ビット、履歴に8ビット
- UltraSPARC-3(2001): 16Kエントリ、PCに14ビット、履歴に12ビット
agree (1997)
分岐予測が誤りとなる理由の1つは、同じ位置にエイリアスされた異なる分岐同士に干渉が発生することです。同じ予測器テーブルエントリにエイリアスされた分岐間の干渉を減らす方法はいくつもあります。実は、この講演で1990年代に考案された方式ばかり取り上げることになったのは、干渉を減らすための様々な方式が提案されているため、30分ではご紹介しきれないからです。
干渉低減方式の考え方をつかんでいただけるよう、一例として「agree」予測器を見ていきましょう。2組の分岐履歴が干渉している時、その予測同士は一致する、しないのどちらかです。一致する場合はニュートラルな干渉、一致しない場合は負の干渉と呼ぶことにします。この方式が着目するのは、大抵の分岐は大きく偏りやすい(つまり、予測器テーブルに2ビットエントリを用いれば、多くのエントリは 01 か 10 ではなく大抵 00 か 11 となり、干渉しないと予想される)という点です。そして、プログラムの各分岐について、「バイアス」と呼ばれる1ビットを持ちます。予測テーブルには、絶対的な分岐予測ではなく、予測が偏りに一致するか否かの情報を格納するのです。
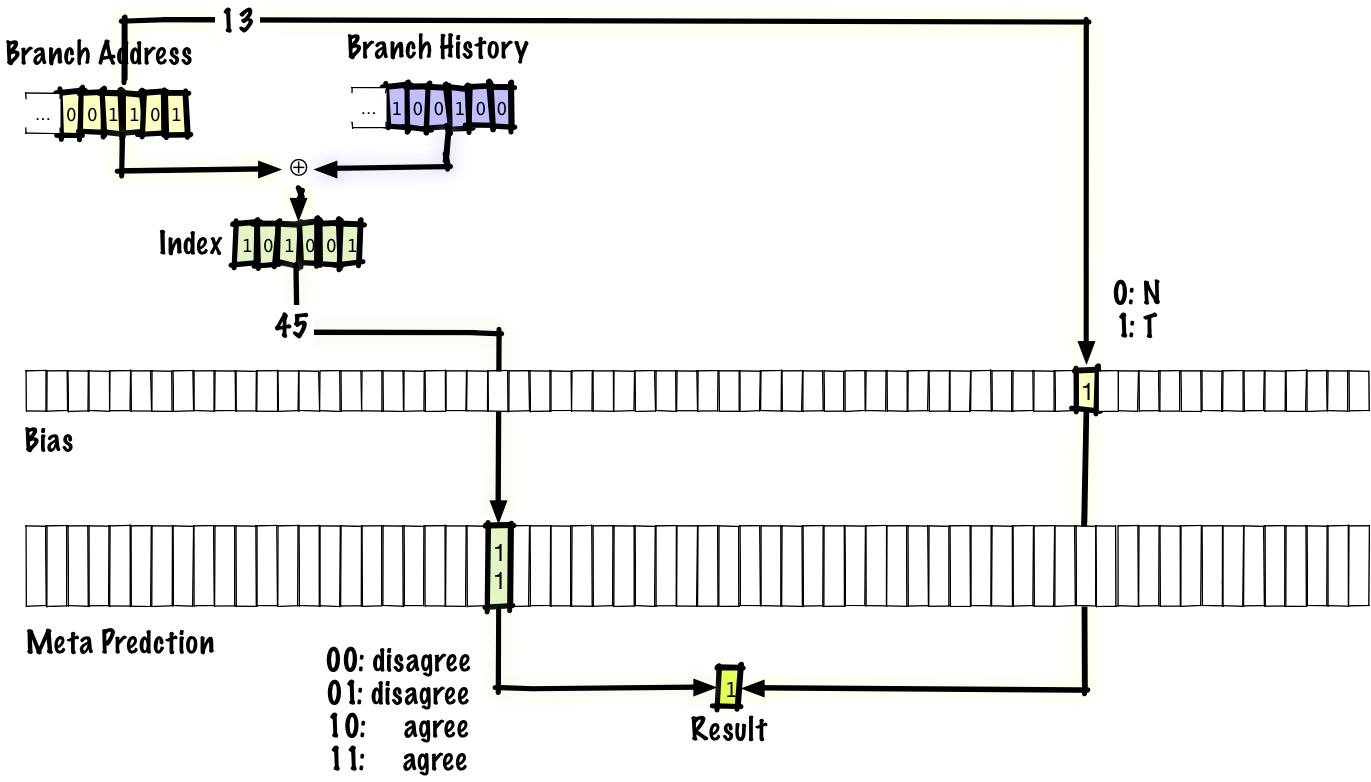
仕組みを見るとこの方式はgshare予測器とほぼ同一で、違うのは上記で述べた点のみです。すなわち、分岐の成立/不成立ではなく一致/不一致を予測し、バイアスビットを持つということです。バイアスビットは分岐アドレスでインデックス付けされ、バイアスビットに示された偏りと予測が一致するか否かを調べます。元の論文では、最初に観測された結果を偏りとすることが提案されました。一方、他の研究では、プロファイルから(基本的にはプログラムを実行しコンパイラにデータをフィードバックして)導いた最適な結果を用いて偏りを設定することが提案されています。
なお、ある分岐を実行してその後同じ分岐に戻った場合、偏りは分岐アドレスでインデックス付けされるため同じバイアスビットを使います。しかし、予測器テーブルエントリは、分岐アドレスと分岐履歴の両方でインデックス付けされるため、別のものを使います。
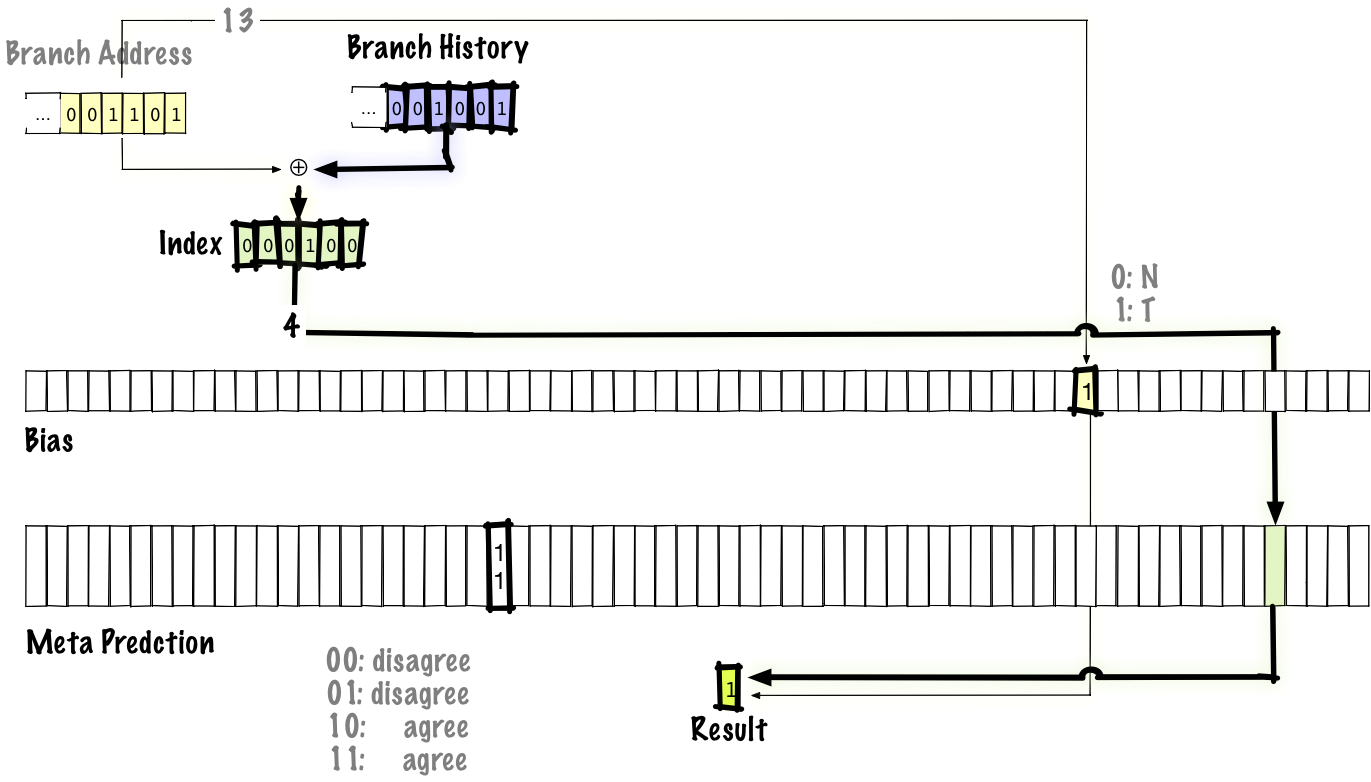
それでうまくいくのかと不思議に思われるかもしれませんので、具体例を見てみましょう。2つの分岐があり、分岐Aは90%、分岐Bは10%の確率で成立するとします。これらの分岐がエイリアスされ、各分岐の成立する確率が独立であるなら、両者が一致せず負の干渉が起こる確率は P(A taken) * P(B not taken) + P(A not taken) + P(B taken) = (0.9 * 0.9) + (0.1 * 0.1) = 0.82 です。
agree方式を用いた場合も、上記の要領で計算すればよいわけですが、2つの分岐が一致せず負の干渉をする確率は P(A agree) * P(B disagree) + P(A disagree) * P(B agree) = P(A taken) * P(B taken) + P(A not taken) * P(B taken) = (0.9 * 0.1) + (0.1 * 0.9) = 0.18 です。別の見方をすると、負の干渉が起こるためには、どちらかの分岐が偏りと不一致とならなくてはなりません。定義上、偏りを正しく設定した場合にそれは起こりにくいのです。
この方式では、精度はおおむね95%、1命令当たりのコストは1.19サイクルとなります。
使用
- PA-RISC 8700(2001)
ハイブリッド方式 (1993)
以上のように、ローカル予測器は内側のループなどをうまく予測でき、グローバル予測器は相関のある分岐などをうまく予測できます。その両方の利点を生かす方法の1つに、両方の予測器を持った上で、ローカル予測器とグローバル予測器のどちらを使うべきか予測するメタ予測器を持つことが挙げられます。単純なやり方は、メタ予測器に前述の2ビット予測器と同様の方式を適用するものの、「成立」か「不成立」かではなく「ローカル予測器」か「グローバル予測器」かを予測するようにすることです。
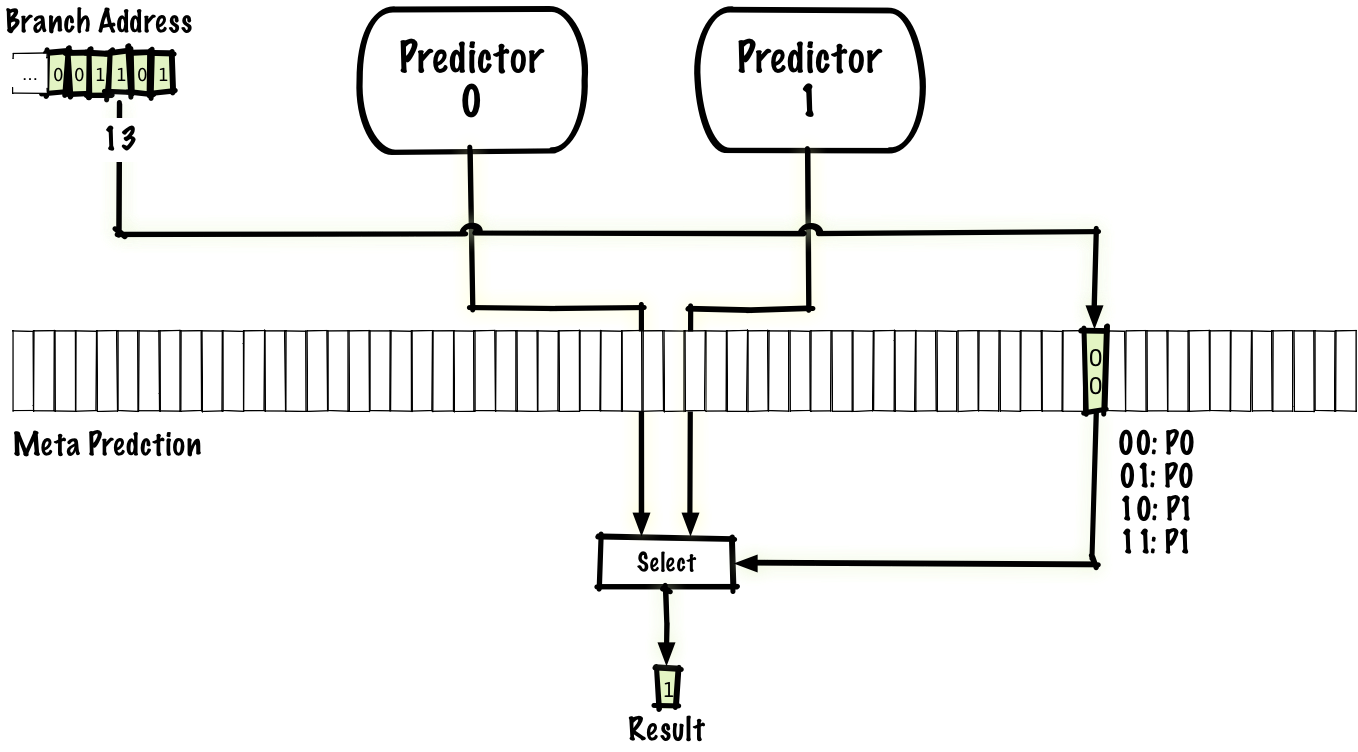
干渉低減方式が前述の agree 予測器などいくつも考えられるように、ハイブリッド方式もいくつも考えられます。ローカル予測器とグローバル予測器に限らずどんな2つの予測器を組み合わせてもいいですし、3つ以上の予測器を用いることも可能です。
ローカル予測器とグローバル予測器を用いた場合、精度はおおむね96%、1命令当たりのコストは1.15サイクルとなります。
使用
- DEC EV6(1998):ローカル予測器(1Kエントリ、10履歴ビット、3ビットカウンタ)とグローバル予測器(4Kエントリ、12履歴ビット、2ビットカウンタ)
- IBM POWER4(2001):ローカル予測器(16Kエントリ)とgshare(16Kエントリ、11履歴ビット、分岐アドレスとのxor、16Kセレクタテーブル)
- IBM POWER5(2004):bimodal(今回取り上げていません)と2レベル適応型予測器の組み合わせ
- IBM POWER7(2010)

株式会社リクルート プロダクト統括本部 プロダクト開発統括室 グループマネジャー 株式会社ニジボックス デベロップメント室 室長 Node.js 日本ユーザーグループ代表
- X: @yosuke_furukawa
- Github: yosuke-furukawa
