2018年9月20日
分岐予測の簡単な歴史 – Part 1
本記事は、原著者の許諾のもとに翻訳・掲載しております。
※これは、 RC(The Recurse Center:プログラマ教育施設) によって組織された講演シリーズである”localhost”を始動するために、Two Sigma(ツーシグマ)での2017年8月22日の分岐予測に関する講演の原稿を仮に書き起こしたものです。
コードで分岐を使われている方は、どれくらいいらっしゃいますか? ifステートメントやパターンマッチングを使われているという方、よろしければ手を挙げてください。
ほとんどの聴衆が手を挙げる
次の質問に関しては手を挙げてもらうつもりはありませんが、もしそうお願いした場合、恐らく手を挙げる人の数は少なくなるのではないでしょうか。その質問とは、「分岐を実行する際、CPUが何をして、そのパフォーマンスは何を意味しているのかを十分に理解しているか」、そして「分岐予測に関する最新の論文を理解できるか」というものです。
この講演の目的は、CPUがどんな理由でどのように”分岐予測”を行うのかを説明すること、そして分岐予測に関する最新の論文が読めるよう、基本的な分岐予測アルゴリズムについて十分に説明し、その仕組みを理解してもらうことです。
分岐予測について話をする前に、まずはなぜCPUが分岐予測を行うのかについて話していきましょう。そのためには、CPUの仕組みについて少しばかり知っておく必要があります。
はじめに、この話においては、コンピュータを、CPUにメモリを加えたものとして考えてください。命令はメモリ内に存在し、CPUはメモリから命令のシーケンスを実行します。ちなみにここで言う命令とは、”2つの数字を追加する”、”メモリからプロセッサにデータのまとまりを移動する”といったようなものです。通常は、命令が1つ実行されると、CPUは次のシーケンシャルアドレスにある命令を実行します。一方で、次の命令を読み込むアドレスを変更する”分岐”と呼ばれる命令もあります。
以下は、命令を実行するCPUを抽象的に示した図です。x軸は時間、y軸は各命令を示しています。

ここでは、 A 、 B 、 C 、 D の順に命令は実行されます。
CPUを設計する1つの方法として、ある単一の命令をCPUに一度に実行させて、それが終わったら次の命令に移り、次の命令のための全ての作業をさせ、それが終わったらその次の命令に移って…、というものがあります。これ自体には何の問題もありません。昔のCPUの多くはこんな感じでしたし、今でも低価格帯のCPUの中には、この方法を採用しているものもあります。しかし、もし皆さんがより高速なCPUを作ろうした場合、組み立てラインのような感じで動くCPUを作るのではないでしょうか? どういうことかと言うと、CPUを2つの部分に分割するのです。そうすると、CPUは組み立てラインのようにそれぞれ別々に、半分が命令の”前半”を実行し、半分が命令の”後半”を実行できるようになります。俗に言うパイプライン型CPUです。
この型を採用したCPUの実行プロセスを示したのが上の図です。命令Aの前半が完了すると、CPUは命令Bの前半が実行されている間でも、命令Aの後半に取りかかることができます。そしてAの後半が終わった時には、Bの後半とCの前半の両方に着手できます。この図によると、パイプライン型CPUは前述のアンパイプライン型CPUと比べて、同じ単位時間あたり2倍の命令を実行できることが分かります。
CPUの分割が2つだけしかダメなんてことはありません。厳密には違いますが、3分割すれば3倍に、4分割すれば4倍にスピードアップします。厳密に違うというのは、通常は、3段パイプラインでは3倍よりも、4段パイプラインでは4倍よりも少し遅くなるからです。その理由は、CPUを分割し、より深いステージにすることでオーバーヘッドが生じるからです。
オーバーヘッドの1つの原因として、分岐の処理をどうするかというのが挙げられます。命令に対して、CPUが最初に行うべきことの1つは、その命令を取得することです。そのためには、命令がどこにあるのかを知らなければなりません。例えば、次のコードを考えてみましょう。
if (x == 0) {
// Do stuff
} else {
// Do other stuff (things)
}
// Whatever happens laterこれは例えば、以下のようなアセンブリに発展することがあります。
branch_if_not_equal x, 0, else_label
// Do stuff
goto end_label
else_label:
// Do things
end_label:
// whatever happens laterこの例では、まず x と0を比較します。そして if_not_equal の場合、 else_label に分岐してelseブロックのコードを実行します。逆にその比較が失敗した場合(つまり x が0の場合)、 if ブロック内のコードを実行し、 else ブロック内のコードの実行を避けて end_label にジャンプします。
パイプライン処理の命令のシーケンスで、特に問題となるのが以下のような例です。
branch_if_not_equal x, 0, else_label
???CPUは、これが
branch_if_not_equal x, 0, else_label
// Do stuffなのか、
branch_if_not_equal x, 0, else_label
// Do thingsなのか、分岐が完了(またはほぼ完了)するまで知ることができません。命令においてCPUが最初に行うべきことの1つはメモリから命令を取得することですが、どっちの命令 ??? かが分からなければ、前の命令がほぼ終わりに近づくまで、 ??? を始めることさえできないのです。
先ほど、3段パイプラインでは3倍、20段パイプラインでは20倍のスピードアップが見込めると言いましたが、それは毎回新しい命令をスムーズに始めることができた場合を想定してのものです。しかしこの場合だと、2つの命令はほぼ直列化されています。

この問題を回避する方法の1つは、分岐予測を使用することです。分岐が出てきた段階で、CPUはそれが分岐するかどうかを予測します。

ここでは、CPUは分岐しないと予測し、分岐の後半を実行している間に、 stuff の前半の実行を始めました。予測が正しければ、CPUは続いて stuff の後半の実行を始め、 stuff の後半を実行している最中に、また別の命令を実行できます。これについては、最初のパイプライン図で見たとおりです。

一方、予測が間違っていた場合、分岐の実行が完了すると、CPUは stuff.1 の成果を破棄し、間違った命令の代わりに正しい命令の実行を始めます。ただ、分岐予測をしていなければプロセッサは停止して命令を実行しなかったはずなので、予測しない場合と比べて、予測が間違った場合の速度が落ちるということは(少なくとも、この事例のレベルでは)ありません。

これを実行することによってパフォーマンスにはどのような影響があるのでしょうか? その予測を行うには、パフォーマンスモデルとワークロードが必要です。ここでは便宜的に、CPUはパイプライン型とし、非分岐はクロック当たり平均1命令、予測しない、または予測を誤った分岐には20サイクルが必要で、正しく予測された分岐には1サイクルが必要とします。
“ワークステーション”の整数ワークロードのベンチマークで最も一般的なSPECintを見ると、その構成は恐らく20%が分岐で、80%がその他の動作といったところでしょう。分岐予測をしない場合、”平均的な”命令は branch_pct * 1 + non_branch_pct * 20 = 0.2 * 20 + 0.8 * 1 = 4 + 0.8 = 4.8 cycles となることが予想されます。100%正確な分岐予測であれば、平均的な命令は0.8 * 1 + 0.2 * 1 = 1 cycleとなり、見込めるスピードアップは何と4.8倍です。一方、誤った予測で20サイクルが必要となった場合、理想的なスピードアップに比べると、ほぼ5倍のオーバーヘッドが必要になってしまいます。
これについて、どんな対処方法があるのかを見てみましょう。まずはごく単純なものから紹介し、徐々に精度を向上させます。
予測は成立
ランダムに予測する代わりに、全てのプログラムの実行において分岐を一括して見る方法です。この場合、成立した分岐と成立しなかった分岐が、必ずしも半々でないことが分かると思います。実際には、成立しなかった分岐よりも成立した分岐の方がはるかに多いはずです。この理由の1つは、ループ分岐がしばしば成立するからです。
全ての分岐が成立すると予測した場合、恐らく70%前後の精度が得られることになります。その場合、分岐の30%に対しては、誤予測のコストが必要になり、平均1命令あたり (0.8 + 0.7 * 0.2) * 1 + 0.3 * 0.2 * 20 = 0.94 + 1.2. = 2.14 のコストを支払わなければなりません。ただ、”常に予測が成立”として処理した場合と”予測なし”として処理した場合を、”完全な予測”の結果と比べてみると、”常に予測が成立”の場合は、非常にシンプルなアルゴリズムにもかかわらず、”完全な予測”の利点の多くを実現できていることが分かるでしょう。
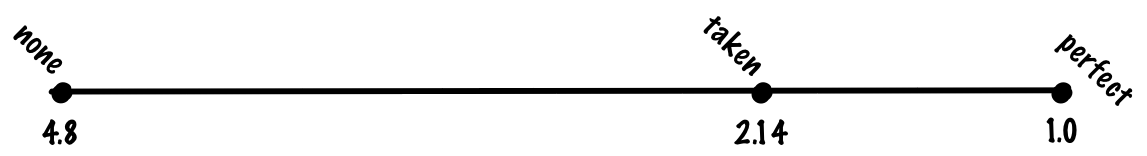
後方で成立し、前方で成立しない(BTFNT)
分岐を”成立する”として予測するのは、ループに対しては非常に相性がいいものの、全ての分岐でそうというわけではありません。そこで次は、分岐が成立するかしないかを、分岐が前方(コードをスキップ)にあるか、それとも後方(前のコードに戻る)にあるかという基準で見てみましょう。この場合、後方の分岐の方が前方の分岐よりも成立している割合が多いことが分かるので、”後方で成立し、前方で成立しない(BTFNT)”を予測変数とすることができます。この方式をハードウェアで実装する場合、成立すると推測される分岐が後方の分岐、成立しないと推測される分岐が前方の分岐となるよう、コンパイラの作者はコンパイラのコードを調整しなければなりません。
この方式では、予測精度はおおむね80%前後となるはずです。コスト関数から、命令当たり (0.8 + 0.8 * 0.2) * 1 + 0.2 * 0.2 * 20 = 0.96 + 0.8 = 1.76 サイクルという数字が導き出せます。
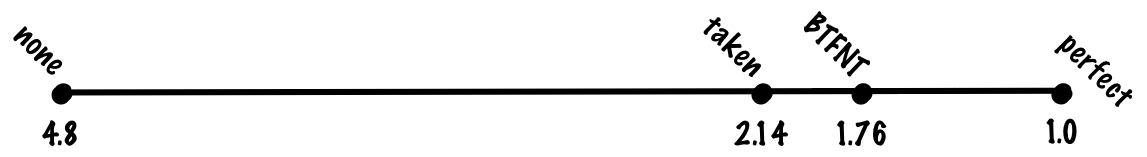
使用
- PowerPC 601(1993):コンパイラ生成の分岐ヒントも使用
- PowerPC 603
1ビット方式
ここまでは、状態を格納していない方式、つまり予測がプログラムの実行履歴を考慮に入れない方式を見てきました。これは文字通り、 静的 分岐予測方式と呼ばれています。この方式はシンプルであるという利点はありますが、時間の経過と共に挙動が変化する分岐を予測することは得意ではありません。ちなみに、時間の経過と共に挙動が変化する分岐に関しては、以下のような例が挙げられます。
if (flag) {
// things
}プログラムの過程には、フラグが設定され分岐が成立するという局面やフラグが設定されておらず分岐が成立しないという局面がある場合があります。こうした分岐に対して、静的方式はうまく予測することができません。そこで、プログラムの履歴に基づいて予測が変更できる 動的 分岐予測方式を考えてみましょう。
最も単純なやり方として、前回の分岐の結果に基づいて予測を行う、というものが挙げられます。つまり、分岐が前回成立していれば今回も成立と予測し、前回成立していなければ成立しないと予測するというものです。
分岐対象の全てに1ビットを持たせるとビット数が多くなり格納できないため、テーブルに入れるのは、すでに確認している一部の分岐とその前回の結果のみとします。なお、ここでは not taken を 0 、 taken を 1 として格納しています。

この場合、図に合わせて考えると、テーブルは64エントリなので6ビットでインデックス付けができます。従って、分岐アドレスの下位6ビットでテーブルにインデックスを作成します。分岐を実行後、予測テーブル(以下でハイライト表示)のエントリを更新します。そして次回の分岐実行時に、同じエントリにインデックス付けをし、更新された値を予測に使用します。

エイリアシングを観察し、異なる場所にある2つの分岐を同じ位置にマップさせることは可能です。これは理想的とは言えませんが、テーブルの速度&コストと引き替えにテーブルのサイズを効率的に制限できます。
1ビット方式を使用した場合、1命令当たりの精度はおおむね85%で、 (0.8 + 0.85 * 0.2) * 1 + 0.15 * 0.2 * 20 = 0.97 + 0.6 = 1.57 サイクルのコストとなります。
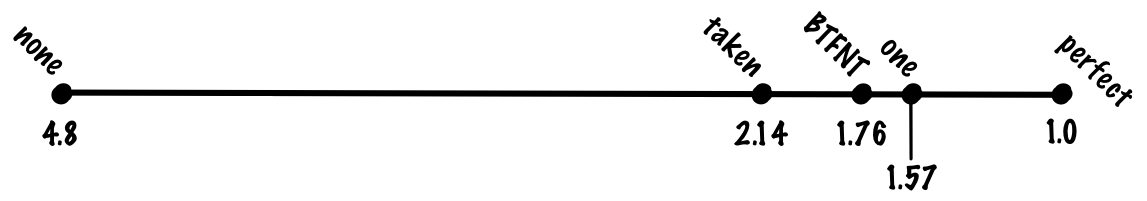
使用
- DEC EV4(1992)
- MIPS R8000(1994)

株式会社リクルート プロダクト統括本部 プロダクト開発統括室 グループマネジャー 株式会社ニジボックス デベロップメント室 室長 Node.js 日本ユーザーグループ代表
- X: @yosuke_furukawa
- Github: yosuke-furukawa
