2018年4月26日
Dockerコンテナが遅くなるもう一つの原因
本記事は、原著者の許諾のもとに翻訳・掲載しております�。
前回の ブログ記事 では、Kubernetesの話と、 ThoughtSpot がKubernetesを開発インフラのニーズに合わせてどのように取り入れたかをご紹介しました。今回はその続報として、最近の興味深いデバッグ経験について少々駆け足になりますがお話ししていきます。本記事も「コンテナ化と仮想化はノットイコールである」という事実に基づいており、たとえcgroupの上限がどれも高くない値に設定されホストマシンで十分な演算能力が利用できるとしても、コンテナ化されたプロセス同士がリソースの競合を起こす場合があることを示したいと思います。
ThoughtSpotでは内部のKubernetesクラスタで 多数のCI/CDや開発関連のワークフロー を稼働させており、ある1点を除いては全てが順調でした。唯一問題だったのは、ドッカー化された製品コピーを起動すると、パフォーマンスが期待を極端に下回るレベルに落ちてしまうことです。コンテナにはそれぞれ、Podの設定によって5CPU、30GB RAMという潤沢なCPU、最大メモリを割り当てていました。仮想マシン(VM)であれば、ささやかな(10KB)テストデータセットに対して各種クエリを実行するには十二分なリソースでしょう。しかしDockerとKubernetesの構成では、72CPU、512GB RAMマシン上で3~4個の製品コピーしか起動できず、パフォーマンスは非常に悪くなっていきました。以前は数ミリ秒で完了していたクエリが1~2秒もかかるようになったことで、CIのパイプラインに様々な問題を引き起こしていました。そこで、私たちはついにデバッグに着手したのです。
もちろん、原因として考えられたのは例によって設定エラーで、製品をDockerにパッケージングする際のミスが疑われました。しかし、VMやベアメタルのインストールと比べても、遅延を引き起こすようなエラーは見つかりません。何の問題もないように見えたのです。次に、 Sysbench パッケージの様々なテストを実行してCPU、ディスク、RAMのパフォーマンスをチェックしたものの、ベアメタルとの違いは見当たりませんでした。製品内のサービスの中には、全動作の詳細なトレースを保存するものもあり、のちにパフォーマンスプロファイリングに利用できるようになっています。リソース(CPU、RAM、ディスク、ネットワーク)の1つが不足している場合は大抵、何らかの呼び出しのタイミングに著しいスキューが発生しているもので、そこから遅延の出所を判断することができます。しかし、このケースでは何の問題も見当たりません。タイミングの配分は全て好適な設定の場合と同じで、唯一の問題はどの呼び出しもことごとくベアメタルより大幅に遅いことでした。現に起きている問題を指し示すサインは何もなく諦めかけていた時に発見したのが、 https://sysdig.com/blog/container-isolation-gone-wrong/ の記事です。
著者はこの記事で、類似の不可解なケースを分析しています。リソースの上限はごく控えめな値にセットされていたにもかかわらず、同一マシンのDocker内部で稼働している2つのプロセス(おそらく軽量)が互いを強制終了してしまうというものです。私たちのケースに関連しては、以下2点が参考になりました。
- 著者の問題の根本的原因は、結局Linuxカーネルにあった。カーネルのdentryキャッシュの設計によって、1つのプロセスの振る舞いが
__d_lookup_loopカーネルコールを大幅に遅くしており、それがもう1つのプロセスのパフォーマンスに直接影響を及ぼしていた。 - 著者はカーネルバグの追跡に
perfを使った。素晴らしいデバッグツールのようで、もったいないことに私たちは一度も使ったことがなかった。
perf(perf_eventsやperfツールと呼ばれることもある。Performance Counters for Linux<PCL>に由来)はLinuxのパフォーマンス分析ツールであり、Linuxカーネルのバージョン2.6.31以降で利用可能。ユーザ空間制御ユーティリティperfはコマンドラインから利用でき、サブコマンドもいくつか用意されている。システム全体(カーネルとユーザランドコードの両方)の統計プロファイリング機能もある。
perfはハードウェアパフォーマンスカウンタ、トレースポイント、ソフトウェアパフォーマンスカウンタ(hrtimerなど)、動的プローブ(kprobes、uprobesなど)をサポートしている。IBMのエンジニア2人は2012年、perfを(OProfileと並ぶ)Linuxでよく使われる2大パフォーマンスカウンタプロファイリングツールと評価した。
うちのケースと似ているかもしれないと思いました。ThoughtSpotのコンテナ内で稼働している何百種類ものプロセスは、どれも同じカーネルを共有しています。何らかのボトルネックがあるに違いありません。 perf という武器を手にして再びデバッグに挑んだところ、気になる発見がいくつかありました。
以下の画像は、左側が良好(かつ高速)なマシンで稼働しているThoughtSpotをperfで数十秒記録したもので、右側がコンテナ内の様子です。
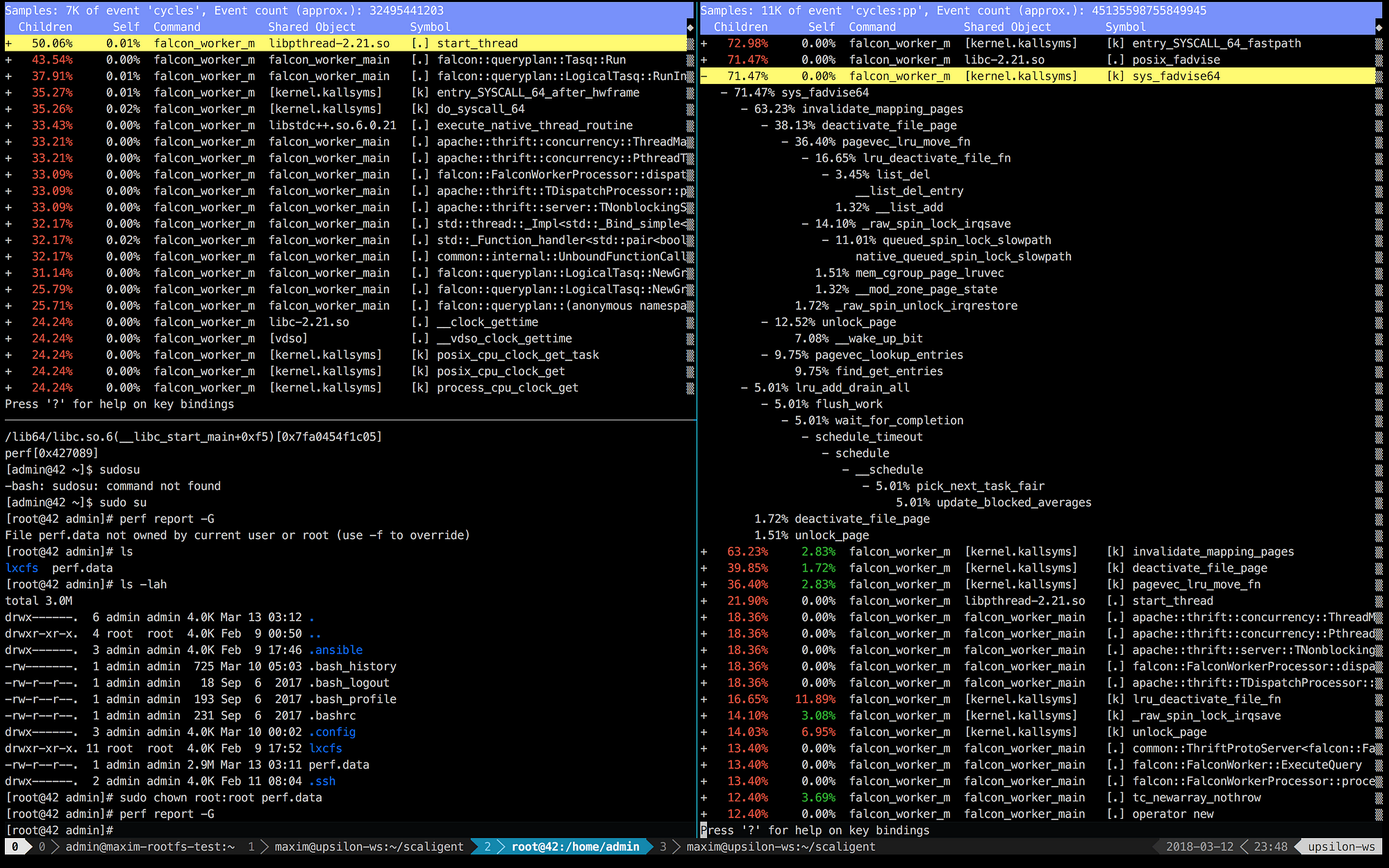
少し見ただけで、右側の上位5つの呼び出しがカーネルに関連しており、多くの時間がカーネル空間で費やされていることが分かります。一方左側では、ユーザ空間で稼働しているThoughtSpotのプロセスに多くの時間が使われています。それ以上に目を引いたのは、 posix_fadvise の呼び出しがかなりの時間を占めていることです。
プログラムはposix_fadvise()を用いることで、のちに特定のパターンでファイルデータにアクセスすると予告できる。それによって、カーネルは適切な最適化を実行できるようになる。
posix_fadvise()は多様な状況で利用できるので、問題の出所をストレートに示すわけではありません。しかし、コードベースを調べた結果、1カ所だけ、システムのどのプロセスも使う可能性のある部分を発見しました。
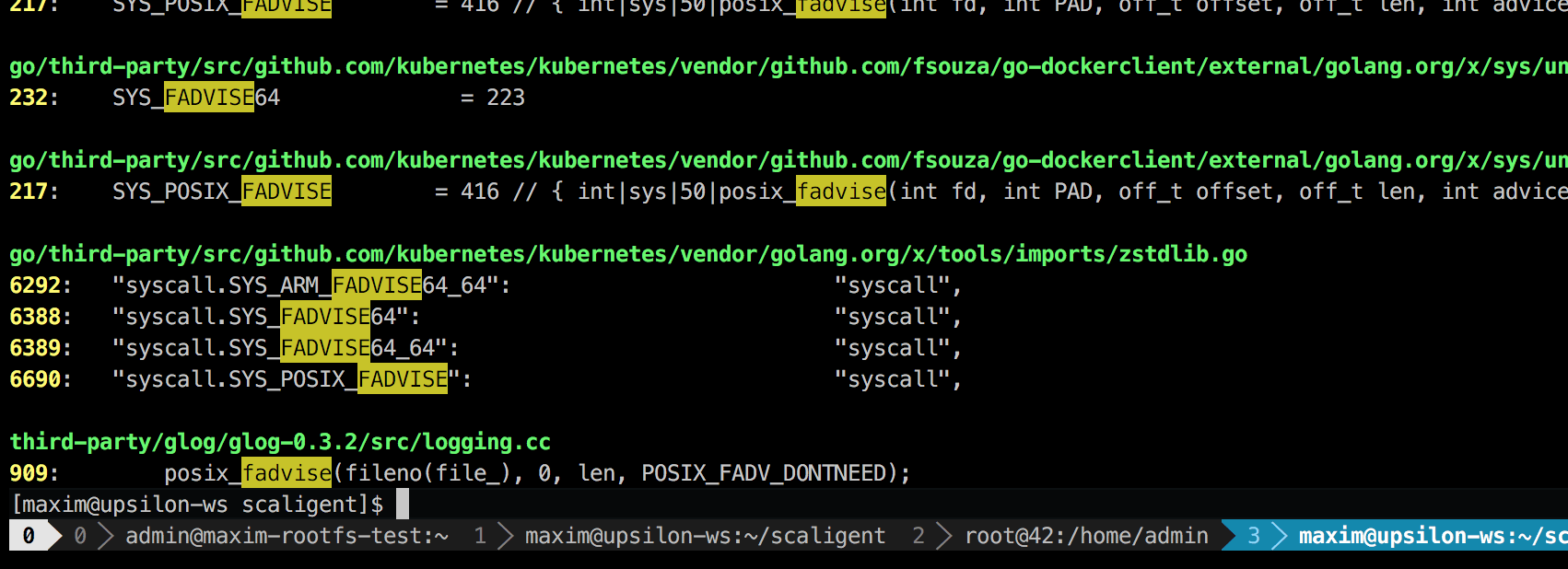
場所は、 glog というサードパーティ製のロギングライブラリです。プロジェクトの至る所で使っている問題の行は、 LogFileObject::Write 内にありました。ライブラリ全体で最も決定的なパスかもしれません。その行は「ログをファイルに書き出す」イベントの度に呼び出され、製品の複数のインスタンスが非常に高頻度でロギングしている可能性が浮上しました。ソースコードをざっと見たところ、 fadvise の部分は --drop_log_memory=false フラグをセットすることで無効にできそうです。
if (FLAGS_drop_log_memory) {
if (file_length_ >= logging::kPageSize) {
// don’t evict the most recent page
uint32 len = file_length_ & ~(logging::kPageSize — 1);
posix_fadvise(fileno(file_), 0, len, POSIX_FADV_DONTNEED);
}
}すぐさま試してみたところ……予想的中です!
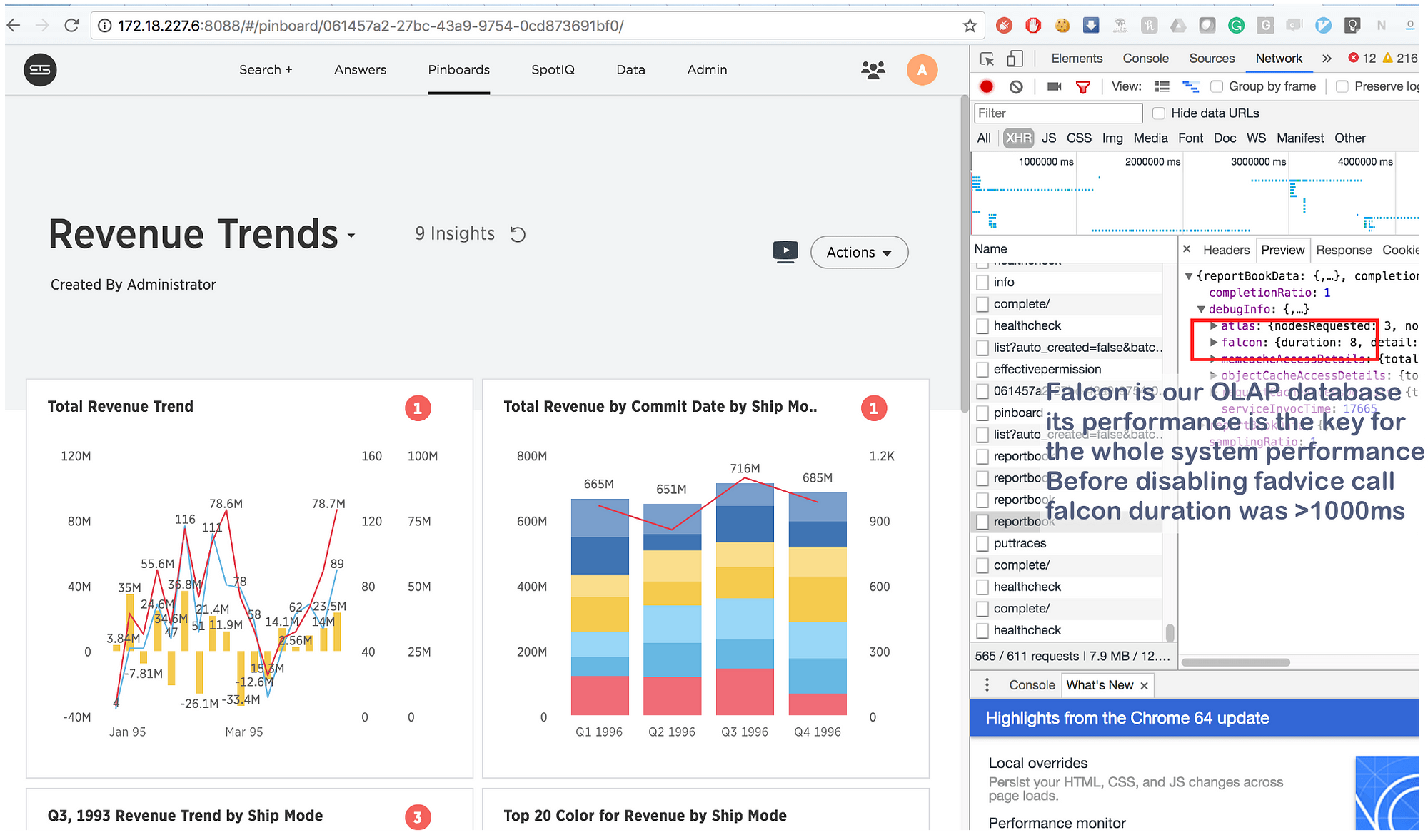
注釈:
falconとはThoughtSpotのOLAPデータベースで、falconのパフォーマンスはシステム全体のパフォーマンスを左右します。fadviseの呼び出しを無効にする前は、falconの所要時間は1000ミリ秒を超えていました。
最大数秒もかかっていた処理が、何とたったの8ミリ秒に短縮されたのです。Googleでざっと検索してみると、 https://issues.apache.org/jira/browse/MESOS-920 と https://github.com/google/glog/pull/145 が見つかり、fadviseの呼び出しこそ遅延の根本的原因であることがあらためて確認できました。おそらくVMやベアメタルでも影響はあったのでしょうが、その際は1マシンまたはカーネルにつき各プロセスのコピーを1個しか持たなかったので、 fadvise を呼び出すペースは数倍遅く、そのためオーバーヘッドもあまり増えませんでした。一方Dockerでは、3~4倍に増えたロギングプロセスが同じカーネルを共有していたことで、 fadvise が深刻なボトルネックと化していたのです。
まとめ
今回の発見は決して目新しいものではありませんが、コンテナにおいて”隔離された”プロセスが CPU や RAM 、 ディスク 、 ネットワーク だけでなく様々な カーネルリソース についても競合するということは、まだ一般には意識されていません。そして、カーネルは極めて複雑なものであるため、全く思いも寄らない箇所( Sysdigの記事 の __d_lookup_loop など)で非効率が発生する可能性があります。だからといって、コンテナが昔ながらの仮想化より劣るとか勝るとか結論づけるつもりは毛頭ありません。コンテナは仮想化のための優れたツールです。ただし誰もが、カーネルは共有リソースであることを絶えず気に留め、カーネル空間で起こる奇妙な競合のデバッグに備えておいた方がいいでしょう。しかも、そうした競合は、侵入者が”軽量”の隔離を破ってコンテナ間に様々な隠れチャネルを作る格好の環境にもなってしまうのです。最後に、 perf は、システム内で何が起こっているかを提示し、様々なパフォーマンス問題のデバッグに役立つ素晴らしいツールです。Dockerで高負荷アプリケーションを稼働させるつもりなら、ぜひ perf の習得に時間を投じることをお勧めします。

株式会社リクルート プロダクト統括本部 プロダクト開発統括室 グループマネジャー 株式会社ニジボックス デベロップメント室 室長 Node.js 日本ユーザーグループ代表
- X: @yosuke_furukawa
- Github: yosuke-furukawa
関連記事