2016年3月7日
Amazon AWSでユーザ数1100万以上にスケーリングするためのビギナーズ・ガイド
本記事は、原著者の許諾のもとに翻訳・掲載しております。
あるシステムを、1人のユーザから1100万人以上にスケーリングするにはどのようにすれば良いのでしょうか。Amazonのウェブサービスソリューションアーキテクトである Joel Williams が AWS re: Invent 2015 Scaling Up to Your First 10 Million Users でスケーリング方法について素晴らしいプレゼンをしています。
AWS上級者のユーザには適さないプレゼンですが、AWS初心者やクラウド初心者、Amazonが次々と送り出す新機能の流れについていけていない人が始めるには素晴らしい内容だと思います。
おおよその見当は付いていると思いますが、このプレゼンはAmazonによって提供されているため、どの問題についても解決策として提案されているものは全てAmazonのサービスになります。amazonのプラットフォームの役割は、印象深く、分かり易いものです。一つ一つのサービスが全体としていかに上手く噛み合っているかを見れば、「Amazonはユーザが何を必要としているかきちんと把握し、それを提供できる製品を用意することに成功している」というのは明らかです。
得られる面白い教訓としては、以下のものがあります。
- 最初はSQLを使い、必要がある時のみNoSQLに移行すること。
- 通底するテーマは、「構成要素はそれぞれ分けておく」ということ。そうすれば、それぞれの構成要素単独でスケーリングできるし、スケーリングの失敗をも単独で済むことになる。ティアの分割やマイクロサービスの作成にも適応することができる。
- 他のビジネスと差別化を図ることのできる仕事だけに投資しましょう。無駄な努力はしないこと。
- スケーラビリティと冗長性は全く別の概念ではない。大抵の場合、同時に実現することはできる。
- 費用については触れられていない。(AWSソリューションに対する批判の多くは費用のため、プレゼンに入れておくべきだったと思います)
基本
-
AWSは世界の12のリージョンで展開されています。
- リージョンとは、Amazonがサービスを提供できる複数のアベイラビリティゾーン(以降AZ)を持つ、世界の地理的に離れた領域です。これら リージョンは 、北米、南米、欧州、中東、アフリカ、アジア太平洋にあります。
- AZは1つのデータセンタを指しますが、複数のデータセンタによって構成される場合もあります。
- AZはそれぞれ離れた場所に位置し、それぞれが別の電力とインターネット接続を使います。
- それぞれのAZは低遅延ネットワークでのみつながっています。それぞれのAZは8キロから24キロ離れていたりします。ネットワークが速く、AZがまるで1つであるかのようにアプリケーションが動作するため、ユーザは気になりません。
- それぞれのリージョンには最低2つのAZが置かれています。全部でAZは32あります。
- AZを使用することで、高可用性アーキテクチャのアプリケーション作成を可能にします。
- 2016年に、AZを9つ、リージョンを4つ、最低でも増やす予定です。
-
AWSは世界中に53のエッジロケーションがあります。
- エッジロケーションは、Amazonのコンテンツ配信ネットワーク(以降CDN)CloudFrontやAmazonのDNSサービスのRoute53によって使用されています。
- エッジロケーションは、世界中のどこにいても、ユーザは超低遅延でコンテンツにアクセスできることを実現しています。
-
ビルディングブロックサービス
- AWSには、高可用性と耐障害性を実現するため、内部で複数のAZを使用して提供するサービスがいくつかあります。サービスの一覧は こちら 、サービスの提供場所は こちら 。
- これらのサービスを有料でアプリケーションに使用すれば、苦労して自前で高い可用性を実現させる必要がありません。
- 次のサービスは1つのAZでホストされています。CloudFront、Route 53、S3、DynamoDB、Elastic Load Balancing、Elastic File System(EFS)、Lambda、Simple Queue Service(SQS)、Simple Notification Service(SNS)、Simple Email Service(SES)、Simple Workflow(SWF)。
- これら1つのAZでホストされているサービスを使用しても高可用性アーキテクチャは実現できます。
ユーザ数 1
- このシナリオでは、たった1人のユーザが自分で自身のWebサイトを運営したいとします。
- システムのアーキテクチャは次のようにします。
- 単一のインスタンスで実行します。例えば t2.micro 型で。インスタンス型は、CPU、メモリ、ストレージ、ネットワーク容量の異なる組み合わせで構成され、自分のアプリケーションに合うリソースの組み合わせを自由に選択することができます。
- 単一のインスタンスで Webスタック 全体を実行します。例えば、Webアプリ、データベース、管理などになります。
- DNSには、 Amazon Route53 をします。
- 単一の Elastic IP アドレスをインスタンスに設定します。
- しばらくの間はこれでうまく動くでしょう。
垂直スケーリング
- より大きな箱が必要となります。スケーリングする一番簡単な方法は、より大きなインスタンス型を選ぶことです。例えば、 c4.8xlarge や m3.2xlarge のように。
- この手法は 垂直スケーリング と呼びます。
- 実行中のインスタンスを停止し、より強力なインスタンス型を新たに選択し、実行します。
- ハードウェアの設定については幅広い選択肢の中から組み合わせることができます。システムをRAM 244GB(近々2TBのRAM型が登場する予定)や40コアにして使用することができます。高速I/Oや高速CPU、大容量のストレージなどもあります。
- Amazonのサービスの中には、パフォーマンスを保証するための プロビジョンドIOPS オプションがついてくるものがあります。考え方としては、小さめのインスタンス型を使用しながら、スケーラビリティのあるサービスを実現してくれるDynamoDBのようなAmazonのサービスを使用することで、スケーリングする手間を省くということです。
- 垂直スケーリングにはフェイルオーバーや冗長性がないという大きな問題があります。インスタンスに問題が生じれば、Webサイトも停止してしまいます。リスクを分散できていない状況にあたります。
- 単一のインスタンスで動かすのには限界があります。何が手を打つ必要が出てくるでしょう。
ユーザ数 10~
- シングルホストをマルチホストに分割します。
- Webサイトに1つのホストを設定します。
- データベースに1つのホストを設定します。データベースは何を使ってもかまいませんが、必ずデータベース管理は怠らないでください。
- ホストを分けることでWebサイトとデータベースのスケーリングをそれぞれ独立して実行することができます。例えば、データベースのスケーリングは必要でもWebサイトのスケーリングは不要な場合があるかもしれません。
- 自らデータベースを持つのではなく、データベースサービスを利用することも選択肢の1つかもしれません。
- あなたはデータベース管理者?バックアップの心配する状況にいたい?高可用性の心配は?パッチは?OSは?
- データベースサービスを利用する大きな利点は、クリック1回でマルチAZ構成のデータベースができることです。レプリケーションの心配は一切ありません。データベースの高可用性と信頼性を実現することができます。
- ご想像どおり、Amazonには完全に管理されたデータベースサービスが有料で提供されています。
- Amazon RDS (リレーショナルデータベースサービス)には多数のオプションがあります。Microsoft SQL ServerやOracle、MySQL、PostgreSQL、MariaDB、Amazon Auroraです。
- Amazon DynamoDB は、完全マネージド型のNoSQL データベースです。
- Amazon Redshift は、ペタバイト規模のデータウェアハウスシステムです。
- さらに Amazon Aurora について
- 64TBまで自動でストレージをスケーリングできます。データストレージを自分でプロビジョニングする必要はありません。
- 最大15までのリードレプリカが可能です。
- 継続的に(インクリメンタルに)Amazon S3にバックアップすることが可能です。
- 3つのAZにかけて6つのレプリケーションが可能です。これにより障害に対応できます。
- MySQLと互換性をもっています。
- NoSQL データベースではなく、最初はSQLデータベースを使用しましょう。
- まずはSQLデータベースの使用を推奨します。
- 技術は確立されています。
- 既存のコードやコミュニティ、サポートグループ、書籍やツールが多く存在します。
- 最初の1000万ユーザでSQLデータベースが破壊されることはありません。(データベースが大規模でない限り)壊れることはないでしょう。
- スケーラビリティの明確なパターンがあります。
- NoSQL データベースが必要になるのはいつなのでしょうか。
- 5TB以上のデータを初年に格納する必要がある場合や信じられないほどのデータベース集中型のワークロードの場合。
- アプリケーションの要件が超低遅延である場合。
- 高いスループットが必要な場合。読み込みや書き込みの際の出入力にかなり手を加える必要があります。
- リレーショナルデータがない場合。
ユーザ数 100~
- Webティアには個別のホストを使用します。
- データベースをAmazon RDSに格納します。
- 上の2点だけです。
ユーザ数 1000~
- アプリケーションには構造上の可用性の問題があります。Webサービスのホストに不具合があると、Webサイトにも不具合が生じます。
- そのため、別のAZに別のWebインスタンスが必要になります。あたかも並んで設置されているかのように、AZ間の遅延はミリ秒単位一桁と低いので問題はありません。
- 異なるAZのRDSにスレーブのデータベースが必要になります。マスタのデータベースに問題が生じた際に、スレーブのデータベースに自動的に切り替わります。常にアプリケーションは同じエンドポイントを使用するため、フェイルオーバー用にアプリケーションを変更する必要はありません。
- 設定にElastic Load Balancer (ELB)を追加します。これは、2つのAZにある2つのWebインスタンス間のユーザの負荷を分散します。
- Elastic Load Balancer (以降ELB)とは
- ELBは高可用性のマネージド型ロードバランサ(負荷分散装置)です。ELBは全てのAZに配置されています。アプリケーションの唯一のDNSエンドポイントとなります。Route53に置くだけで、Webホストのインスタンスの負荷を分散してくれます。
- ELBはヘルスチェック(健全性の確認)で不具合のホストにトラフィックが流れるのを防ぎます。
- 特別なことをしなくても、スケーリングしてくれます。トラフィックの追加を背後で感知し、水平方向にも垂直方向にもスケーリングしてくれます。管理する必要はありません。アプリケーションのスケーリングと共にELBもスケーリングします。
ユーザ数 1万~10万
- 前述の設定でELBの背後にあるのは2つのインスタンスでしたが、実際には、ELBの背後に1000以上のインスタンスを配置することができます。これが、 水平スケーリング です。
- RDSやデータベースにリードレプリカを増やす必要があります。これはマスタへの書き込みの負荷を軽減します。
- トラフィックを移行してWebティアのサーバの負荷を軽減するといった方法でパフォーマンスや効率を挙げることを検討してください。静的コンテンツをWebアプリからAmazon S3やAmazon CloudFrontに移動してください。CloudFrontはAmazonのCDNで世界53つにあるエッジロケーションにデータを格納してくれます。
- Amazon S3はオブジェクトベースストレージです。
- Elastic Block Store (以降EBS)とは異なりEC2インスタンスに関連するストレージではありません。オブジェクトストレージであって、ブロックストレージではありません。
- JavaScriptやCSS、画像や動画のような静的コンテンツを格納するには最適です。これらのコンテンツをEC2インスタンスに設定する必要はありません。
- 耐久性が高く、99.999999999パーセントの信頼性を実現しています。
- 無限にスケーリングが可能なため、望むデータ量を格納することができます。利用者は数ペタバイト規模のデータをS3に格納しています。
- オブジェクトのサイズは最大で5TBまでサポートされています。
- 暗号化を実現しています。暗号化には、Amazonのものや独自のもの、暗号化サービスを使用することが
できます。
- Amazon CloudFrontはコンテンツのためのキャッシュです。
- エッジロケーションでキャッシングされたコンテンツはエンドユーザに低遅延で配信されます。
- CDNがない場合、エンドユーザはコンテンツにアクセスする際に遅延を感じてしまうかもしれません。コンテンツの配信やWebリクエストの処理でサーバにも負荷がかかってしまいます。
- ある顧客が60ギガビット毎秒でコンテンツを配信する必要がありました。Webティアで感知されることなく、CloudFrontが処理してくれたそうです。
- Webティアからセッション状態を移行して負荷を軽減することも可能です。
- ElastiCache やDyanmoDBにセッション状態を格納することができます。
- この手法を使用すると、将来必要になるかもしれないシステムのスケーリングの自動化が可能になります。
- データベースからElastiCacheへデータをキャッシングすることでも負荷を軽減することができます。
- データベースで全てのデータ処理を行う必要はありません。多くをメモリキャッシュに処理させ、データベースには重要なトラフィックを処理させることができます。
- Amazon Dynamoはマネージド型NoSQLデータベースです。
- 希望するスループットをプロビジョニングすることができます。読み込みと書き込みのパフォーマンスを、支払い希望額に合わせて設定することが可能です。
- 高速で予測可能なパフォーマンスを実現しています。
- 完全分散型で耐障害性を実現しています。さらに、複数のAZに配置されています。
- key-value型のデータストアです。JSONがサポートされています。
- ドキュメントサイズは最大で400KBまでサポートされています。
- Amazon Elasticacheはマネージド型のMemchached(分散型メモリキャッシュ)あるいはRedis(key-value型データストア)です。
- メモリキャッシュクラスタの管理で稼ぐことはできないので、Amazonに任せてください。これがセールスポイントです。
- クラスタは自動的にスケーリングされます。自己回復するインフラで、ノードが不具合を起こすと、新しいノードが自動的に起動されます。
- 動的コンテンツをCloudFrontに移行して負荷を軽減することも可能です。
- CloudFrontがファイルのような静的コンテンツを処理することは知られていますが、実は動的コンテンツも処理できるのです。ここでは特に触れませんが、知りたい方は こちら をどうぞ。
Auto Scaling(自動スケーリング)
- 例えばブラックフライデーのようにトラフィックが集中した時でも処理できるよう能力をプロビジョニングするのは、お金の無駄遣いです。コンピューティング能力をトラフィック量に応じて変更できる方がいいでしょう。Auto Scalingは自動的にコンピューティング能力を縮小・拡張してくれます。
- プールのサイズに合わせて、最小能力と最大能力の設定をすることができます。
- CloudWatch は全てのアプリケーションに組み込まれている管理サービスです。
- CloudWatchイベントがスケーリングを実行します。
- CPU利用率に応じてスケーリングしますか?待ち時間に応じてスケーリングしますか?ネットワークのトラフィック量に応じてスケーリングしますか?
- 独自の測定基準をCloudWatchに設定することができます。例えばあるアプリケーションに特化してスケーリングをしたい場合、その測定基準をCloudWatchに設定すれば、Auto Scalingにその条件でスケーリングするよう指示できます。
ユーザ数 50万~
- 前述の設定に加え、 auto scalingグループ をWebティアに追加します。Auto Scalingグループには2つのAZが含まれますが、これを3つや好きな数だけ増やすことは、同リージョン内であれば可能です。スケーラビリティの場合だけでなく、可用性の場合にもインスタンスが複数のAZで発生することは可能です。
- ここでは3つのWebティアインスタンスを例としていますが、インスタンスの数は何千でも可能です。例えばインスタンスの数を最低10、最大1000と設定することができます。
- ElastiCacheはデータベースからの使用頻度の高い読み込みの負荷を軽減してくれます。
- DyanmoDBはセッションデータの負荷を軽減してくれます。
- モニタリングやメトリクス、ロギング機能の追加が必要になってきます。
- ホストレベルのメトリクスはAutoscaling グループ内の1つのCPUインスタンスを見て、何が不具合を起こしているのか確認できます。
- 集約レベルのメトリクスはElastic Load Balancerを見てインスタンスセット全体のパフォーマンスを確認できます。
- ログ解析で CloudWatch のログを見てアプリケーションの状態を確認できます。 CloudTrail はログの解析と管理を助けてくれます。
- 外部サイトのパフォーマンスを知ることで、自分のサイトがエンドユーザにどのように見えているか確認してください。New RelicやPingdomnのようなサービスを利用してください。
- 自分の顧客の声を理解する必要があります。待ち時間は酷いのか。Webサイトにアクセスするときにエラーは生じていないか。
- できるだけ設定でパフォーマンス向上を図りましょう。Auto Scalingが役に立つでしょう。CPU利用率が20パーセントのシステムに用はありません。
自動化
- インフラが大規模になると、インスタンス数が1000にまで増える可能性もあります。リードレプリカがあり、水平スケーリングもありますが、まとめて管理するために何らかの自動化が必要です。インスタンスを個別に管理したくはありません。
- 自動化ツールには階層があります。
- 自分でやる:Amazon EC2、AWS CloudFormation
- ハイレベルなサービス:AWS Elastic Beanstalk、AWS OpsWorks
- AWS Elastic Beanstalk :アプリケーションに代わってインフラを自動的に管理します。便利ですが、コントロールできることは多くありません。
- AWS OpsWorks :アプリケーションをレイヤ構造で構築する環境です。Chefレシピを使ってアプリケーションレイヤを管理します。
- 継続的インテグレーションとデプロイメントを行うための能力も有効になります。
- AWS CloudFormation: :最も長い実績があります。
- スタックがテンプレート化されるので、最も柔軟に自動化が可能です。テンプレートを使ってスタック全体を構築することも、スタックの構成要素のみを構築することもできます。
- スタックを更新するにはCloud Formationテンプレートを更新します。すると、アプリケーションの一部分のみが更新されます。
- 多くのことをコントロールできますが、あまり便利ではありません。
- AWS CodeDeploy :コードを一群のEC2インスタンスとしてデプロイします。
- 1個から数千までのインスタンスにデプロイ可能です。
- .CodeDeployは自動スケーリング設定を示すことができ、コードはインスタンスのグループにデプロイされます。
- Chef やPuppetと併用することもできます。
インフラを切り離す
- サービス指向アーキテクチャ(SOA) や マイクロサービス を使用:ティアから構成要素を取り出して、切り離しましょう。データベースティアからWebティアを切り離したときのように、別々のサービスを作成しましょう。
- 個別のサービスは、その後、個別にスケーリングすることができるので、非常に柔軟なスケーリングが可能になり、高い可用性が得られます。
- SOAは、Amazonが構築したアーキテクチャの重要な要素です。
- 結び付きを緩めれば、自由になります。
- 構成要素が互いのスケーリングや故障に無関係になるようにすることができます。
- もしワーカノードがSQSからのプルワークに失敗したとしても、問題ありません。新たなワークを開始するだけです。ものごとに失敗は付きものです。失敗に対処できるアーキテクチャを構築しましょう。
- あらゆるものをブラックボックスとして設計しましょう。
- 相互作用を切り離しましょう。
- 冗長性とスケーラビリティを自分で構築するのはやめて、それが組み込まれたサービスを選びましょう。
無駄な努力はしない
- ビジネス的に差別化を図れる仕事だけに投資しましょう。
- Amazonの多くのサービスは、複数のAZにまたがっているので、本質的に障害に対する耐性があります。例えば、キューイング、Eメール、コード変換、検索、データベース、モニタリング、メトリクス、ロギング、計算などのサービスがあります。自分で作る必要はありません。
- SQS :キューイングサービス
- 最初に提供されたAmazonのサービスです。
- 複数のAZにまたがっているので、故障への耐性があります。
- スケーラブルで、安全で、シンプルです。
- キューイングによって、インフラの構成要素間でメッセージを受け渡すのが簡単になります。
- 写真CMSを例に取りましょう。写真を収集して処理するシステムは、2つの異なるシステムにして、個別にスケーリング可能になるようにすべきです。システムは緩く結び付くようにします。写真を採取してキューに入れれば、ワーカがキューから写真を取り込んで、何らかの処理を施すことができます。
- AWS Lambda :サーバをプロビジョニングしたり管理しなくてもコードを実行できます。
- アプリケーションを切り離すために非常に役立つツールです。
- 写真CMSの例では、S3ファイルが追加されるとLambdaがS3イベントに応答して、処理を行うLambda機能が自動的にトリガされます。
- もうEC2は使いません。EC2では間に合わないし、管理するOSもありません。
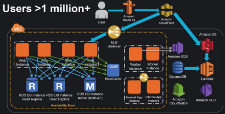
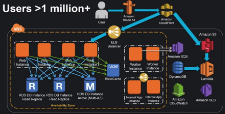
ユーザ数 100万~
- ユーザ数100万以上を達成するには、前述のポイントの全てが必要です。
- マルチAZ
- ティア間でのElastic Load Balancing(弾力的ロードバランシング)。Webティアだけではなく、アプリケーションティア、データティア、その他のあらゆるティアで必要です。
- Auto Scaling(自動スケーリング)
- サービス指向のアーキテクチャ
- S3とCloudFrontを使用したスマートなコンテンツサービス
- DBの前にキャッシングを装備
- Webティアから状態を排除
- Eメールの送信に Amazon SES を使用しましょう。
- モニタリングにCloudWatchを使用しましょう。
ユーザ数 1000万~
- 規模が拡大すると、データティアで問題が発生します。 書き込みマスター との競争をめぐるデータベースの問題に巻き込まれる可能性があります。この問題は基本的に、大量の書き込みトラフィックを1つのサーバに送信することしかできない、ということを意味します。
- その解決方法には次のものがあります
- フェデレーション
- シャーディング
- 機能の一部を他のタイプのDB(NoSQL、グラフなど)に移行
- フェデレーションとは、データベースを機能に基づいて複数のDBに分割することです。
- 例えば、フォーラムデータベース、ユーザデータベース、製品データベースを作成する場合、以前は1つのデータベースに入れていたかも知れませんが、3つに分けましょう。
- 別々のデータベースを互いに無関係にスケーリングできます。
- 短所:データベース横断クエリを行うことができないので、次の戦略、つまりシャーディングに進むのが遅れます。
- シャーディングとは、データベースを複数のホストにまたがって分けることです。
- アプリケーションレイヤが複雑になりますが、実質的にはスケーラビリティは制限されません。
- 例えば、ユーザデータベースで、ユーザの1/3を1つのシャードに送り、1/3を別のシャード、残りの1/3をさらに別のシャードに送ることができます。
- 機能の一部を他のタイプのDBに移動
- まず、NoSQLデータベースについて考えます
- 例えば、スコアボード、クリックストリームまたはログデータの高速取り込み、一時データ、HOT(Heap Only Tuple)テーブル、メタデータまたはルックアップテーブルのような、複雑なJOINが不要なデータの場合は、そのデータをNoSQLデータベースに移行することを検討してみてください。
- そうすれば、データベースを互いに無関係にスケーリングできるようになります。
ユーザ数 1100万~
- スケーリングは繰り返されるプロセスです。規模が拡大するにつれて、できることは増えます。
- アプリケーションを微調整する。
- 特徴または機能をさらにSOA化する。
- マルチAZからマルチリージョンへスケーリングする。
- 他者がこれまで手がけたことのない、特定の問題を解決するためのカスタムなソリューションの構築を開始しましょう。10億の顧客にサービスを行うには、カスタムなソリューションが必要でしょう。
- スタック全体を念入りに分析しましょう。
まとめ
- マルチAZアーキテクチャを使用して信頼性を高めましょう。
- ELB、S3、SQS、SNS、DynamoDBなどの自己スケーリングサービスを利用しましょう。
- すべての段階に冗長性を組み込みましょう。スケーラビリティと冗長性は別々の概念ではなく、多くの場合で両方を同時に達成できます。
- まずは、従来型のリレーショナルSQLデータベースを使いましょう。
- インフラの内部と外部の両方のデータをキャッシングしましょう。
- インフラ内で自動化ツールを使用しましょう。
- メトリクス、モニタリング、ロギングを適切に配備して、ユーザがアプリケーションでどのような体験をしているか確かめられるようにしましょう。
- ティアを個別のサービスに分けて(SOA)、それぞれのスケーリングや故障が互いに無関係になるようにしましょう。
- できれば、Auto Scalingを使用しましょう。
- 無駄な努力はやめて、本当に必要なとき以外は自分でコーディングせずに管理されたサービスを使いましょう。
- NoSQLへの移行が有意義なら、そうしましょう。
参考記事
監修者
古川陽介
株式会社リクルート プロダクト統括本部 プロダクト開発統括室 グループマネジャー 株式会社ニジボックス デベロップメント室 室長 Node.js 日本ユーザーグループ代表
株式会社リクルート プロダクト統括本部 プロダクト開発統括室 グループマネジャー 株式会社ニジボックス デベロップメント室 室長 Node.js 日本ユーザーグループ代表
複合機メーカー、ゲーム会社を経て、2016年に株式会社リクルートテクノロジーズ(現リクルート)入社。
現在はAPソリューショングループのマネジャーとしてアプリ基盤の改善や運用、各種開発支援ツールの開発、またテックリードとしてエンジニアチームの支援や育成までを担う。
2019年より株式会社ニジボックスを兼務し、室長としてエンジニア育成基盤の設計、技術指南も遂行。
Node.js 日本ユーザーグループの代表を務め、Node学園祭などを主宰。
- X: @yosuke_furukawa
- Github: yosuke-furukawa
関連記事