2015年9月30日
Pythonや機械学習、そして言語の競争について – 極めて主観的な見地から

(2015-08-24)by Sebastian Raschka
本記事は、原著者の許諾のもとに翻訳・掲載しております。
(訳注:2016/1/5、いただいた翻訳フィードバックを元に記事を修正いたしました。)
よくある主観的で痛烈な意見を題名に付けたクリックベイト(クリック誘導)記事だろうと思われた方、そのとおりです。以前指導してくれた教授から教わったある洞察/処世術は、些細でありながら私の人生を変えるマントラとなったのですが、私がこの記事を書いたのはそれによるものです。「同じタスクを3回以上繰り返す必要があるなら、スクリプトを書いて自動化せよ」
そろそろ、このブログはなんだろうと思い始めているのではないでしょうか。半年振りに記事を書いたのですから。ツイッターで書いた Musings on social network platforms(ソーシャル・ネットワークプラットフォームについてじっくり考える) はさておき、この半年の間書き物をしていないというのはうそです。正確には、400ページの 本 を書きました。これは、私にとって素晴らしい旅となりました。そして、「なぜ機械学習にPythonを選ぶのか」という質問を最近よく目にします。とうとう、私の スクリプト を書く時が来たのだと思いました。
この記事では、Pythonを使用するべきだと言うつもりはありません。「どの○○がベストか?」(○○に”プログラミング言語やテキストエディタ、統合開発環境、OS、パソコンメーカー”などを挿入してください)と聞く質問が、正直、大嫌いです。質問としても議論内容としても無意味だと私は思います。時には楽しく面白い議論になることもあると思いますが、このような質問は仕事仲間や友人との飲み会やお茶をする時の話題として取っておくことをお勧めします。
目次
• 難しい問題の簡潔な答え
• お気に入りのPythonツール
• MATLABに対する個人的見解
• 見た目は最高なJulia
• 本当は問題がない R
• Perlはどうなったのか
• 他の言語
• Pythonは危機言語なのか
• 結論
• フィードバックや意見
難しい問題の簡潔な答え
簡潔な答えから始めましょう。この段落で私はこの記事の核心を書いているので、この段落以降を読むのをやめてもかまいません。私は科学者なので、始めたことは終わらせるのが好きです。プロトタイプを迅速に作り上げ、モデルやアイデアなどをメモできる環境を好みます。また、私が解決するのは、とても特殊な問題ばかりです。データセットを分析し結論を出します。私にとって重要なのは、どうすれば生産性の高い仕事ができるかなのです。”生産性”とは何か。私の場合、分析は1回しか行いません(異なるアイデアのテストやデバッギングは別です)。ある特定のコードを24時間実行することもありません。私はエンドユーザのためのソフトウェアアプリを開発していません。私は”生産性”を定量化する際、(1)アイデアをコードで書き出す時にかかった時間、(2)デバッギングにかかった時間、(3)実行にかかった時間の合計時間を想定します。私にとって”高い生産性”は”結果を出すまでにかかった時間”を意味します。長年の経験から、自分にはPythonが合っていることが分かりました。全てではありませんが、多くの場面で使います。他の全てのことにも当てはまるように、Pythonは”特効薬”ではありません。全ての問題に適用できる”万能な”解決策ではありません。しかしながら、プログラミング言語を共通の問題やそうでない問題の範囲で比較してみると、もしかしたらベストな解決策になりうるのではないかと思えます。おそらく、Pythonはプログラミング言語の中でもあらゆる場面で、最も柔軟性と適応性が高いのではないでしょうか。

(引用元: https://xkcd.com/974/ )
訳:
「塩を取って」
「だからさ……」
「分かってる。どんな調味料でも渡せるシステムを開発してるんだ。」
「20分も待ってるんだけど。」
「長い目で見たら役に立つから。」
Donald Knuthが言うように、”早まった最適化は悪の根源”であることを忘れないでください。もしあなたがソフトウェアエンジニアチームの一員で、機械学習とデータサイエンス部の革新的な高頻度取引モデルを最適化する場合、Pythonは適していないでしょう(しかし、データサイエンス部で使用されている言語かもしれないので、知っておくとプログラムを読む際に役に立つと思います)。言語を選ぶ際には、まず自分にとって常に問題となるタスクやニーズを見極めることをお勧めします。”金づちしかないと、あらゆる物が釘に見えてしまう”、このような状況に陥らないことです。ただし、バランスを保つことも念頭に置いてください。時と場合によっては、スクリュードライバーの方が”より良い”解決策であっても、金づちがベストな選択になり得るのです。繰り返しになりますが、最終的には生産性の問題です。
私の経験を例として話しましょう。 ある仮説に特化した問題を特定するために、150万もの小さい化合物を”スクリーニング”できる新型アルゴリズムを開発する必要がありました。私はコンピュータに精通していますが、共同開発していた生物学者はコンピュータとは縁のない実験を行っていました(”ウェットラボ”の実験といいます)。目標としていたのは、膨大な数の化合物を、実験可能な100種類に絞り込むプログラムでした。実験を行う時間が限られているため、実験結果を迅速に出せることが要求されました。とにかく、時間の”制限”がありました。助成金申請が受理されて研究資金の交付を受けてから、研究結果を収集するまで数週間しかありませんでした(共同開発の内容は春にだけ放卵する魚の稚魚の実験でした)。そのため、”最短で実験結果を出せる方法”を考えました。まず、私はC++とFORTRANを知っていたので、Pythonにアルゴリズムを実装して”スクリーニング”を実行するよりも速く実行できるのではないかと考えました。これは、あくまでも経験に基づく推測なので、実際に実行速度に差が出てくるのかは分かりません。しかし、Pythonを使用してプログラム開発を進めれば、数日で完成できるということは確信していました。しかし、C++では1週間かかるだろうと思いました。効率の良い実装は後で考えることにしました。”早まった最適化は悪の根源”というように、この時は、最適化よりも結果を届ける事が重要でした。一連の考えはデータ保存ソリューションにも適用できることをここで書き添えておきます。データベースにはSQLiteを使用しました。特定の分子にアノテーションを付けて回収する動作を繰り返し実行しなければならなかったため、CSVを使用する意味はありませんでした。メモリ容量の問題は別として、分子の特定や入力操作のたびに、毎回最初から最後までスキャンしたり書き直したりするのは避けたかったのでCSVを使用しませんでした。MySQLを使用した方が良かったのかもしれませんが、厳しい期限があったので迅速にプログラムを完成するには、SQLサーバを追加設定する時間はありませんでした。この場合、SQLiteで十分でした。

(引用元: https://xkcd.com/1319/ )
*訳注:
「このタスクに時間がかかり過ぎる。自動化するプログラムを書かないと!」
上:理論
(自動化のコードを書くことで一時的に仕事が増えるが、それが完了して使えるようになると本来の仕事の量が減り、最後には自由時間が生まれる。)
下:現実
(自動化のコードを書くことで仕事が増え、自動化部分のデバッグや再考を経てもなお開発は続く。本来の仕事をする時間がなくなる。)
自分の ニーズに合った言語を選ぶこと が正しい判断なのです。ただし、少し注意が必要です。プログラマ初心者には、それぞれの言語を学ばなければ、言語の長短やどの言語が役に立つのかを知ることができません。問題に直面した時、私は自分の直面している問題に関係する特定のアプリケーションやソリューションをGoogleや GitHub で検索します。コードを読める必要も理解する必要もありません。成果物を見ればいいのです。他の人にもどんどん聞いてください。ただし、具体性、目標、プログラミングを学ぶ理由を説明せず、一般的に”一番良い”プログラミング言語は何かと、単純に質問するのはやめましょう。MacOS X用のアプリを開発したいのであれば、Objective CやSwiftについて知りたいでしょうし、Android用であればJavaを学びたいはずです。
お気に入りのPythonツール
私が気に入っていて、頻繁に使うPython”ツール”をご紹介しますので、もし興味があればご覧ください。私は、このほとんどを日常的に利用しています。
- NumPy :列構造と線形代数を用いたベクトル方程式を使う際に好んで利用するライブラリ。 SciPy で拡張されています。
- Theano :手間がかかり、GPUコア全体に分散している数値計算のための機械学習アルゴリズムを実装するライブラリ。
- scikit-learn :日常的に、より基本的な機械学習タスクを扱う際、最も便利なAPI。
- matplotlib :プロッティングする場合に使うライブラリ。プロットの種類によって、 seaborn を使うこともあります。一例として、seabornのヒートマップはとても優れています!
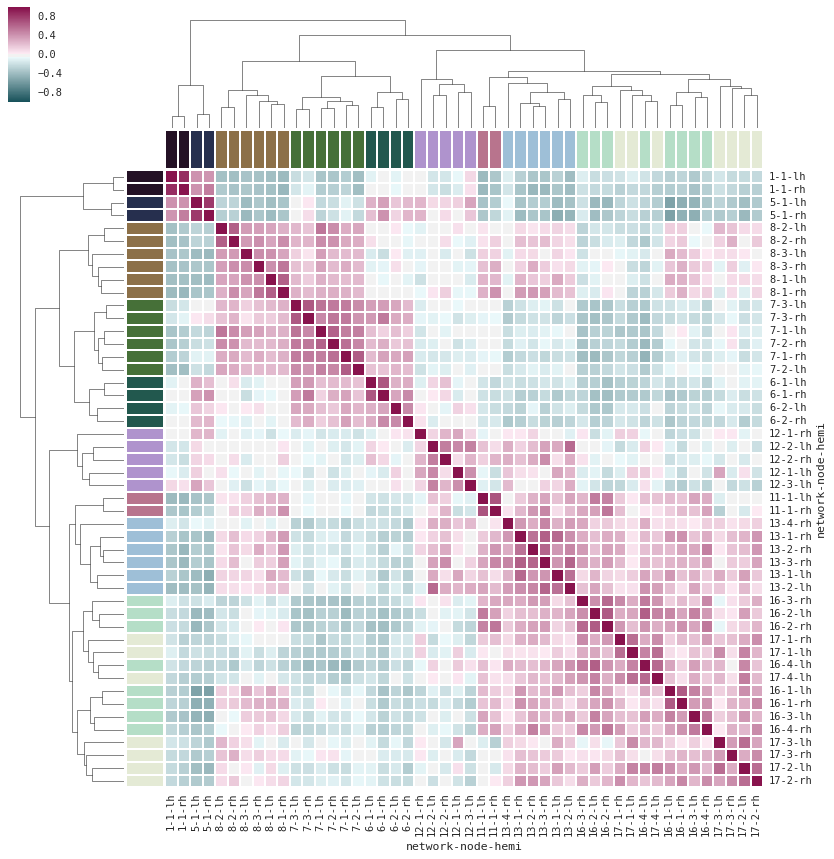
(引用元: http://stanford.edu/~mwaskom/software/seaborn/examples/structured_heatmap.html )
- Flask (Django) :私にはあまり機会がありませんが、Webアプリを開発するときはFlaskが便利です!
- SymPy :記号を用いた数式を扱う際に利用します。私はWolframAlphaをやめてSymPyを使うようになりました。
- pandas :比較的、小規模なデータセットを扱う際に利用します。ここで扱うデータセットのほとんどがCSVファイルから抽出されたものです。
- SQLite3 :”中規模”のデータセットでアノテートやクエリを行う際に利用します。
- IPython notebooks :私はリサーチの90%をIPython notebooksで行っています。この環境は、全てを1つの場所に集約するのに大変優れています。アイディア、コード、LaTeX、方程式、イラスト、プロット、アウトプットなどを全て含むことができます。
近頃は、IPythonプロジェクトが Project Jupyter へと進歩していることを覚えておいてください。今ではPythonだけでなく、RやJuliaなどを始め、多くの場合でJupyter notebookの環境を利用することができます。
MATLABに対する個人的見解
数年前、私はMATLAB(もしくはOctave)を非常に広範囲で利用していました。ほとんどのコンピュータ科学のデータサイエンスの授業がMATLABを使って教えられていたのです。私は、なんだかんだ言っても、プロトタイプのための環境としては悪くないと本気で思っていました。線形代数で構築することを念頭に置いているので(MATrix LABoratoryのためのMATLABとして)、機械学習アルゴリズムを実装するにはMATLAB を使う方が、PythonやNumPyを使うよりも、少しだけ”自然”だと思っていたのです。公平に言うと インデックスが1から始まる プログラミング言語はプログラマにとって少し奇妙に見えました。しかし、MATLABは高額であることを忘れてはいけません。また、少しずつMATLABは業界からも教育の現場からも姿を消していっているように思えます。私は結局のところオープンソースが大好きなんです。加えて、下のベンチマークを見ると、MATLABのパフォーマンスは他の生産性の高い”言語”と比べてそんなに強力というわけでもありません。
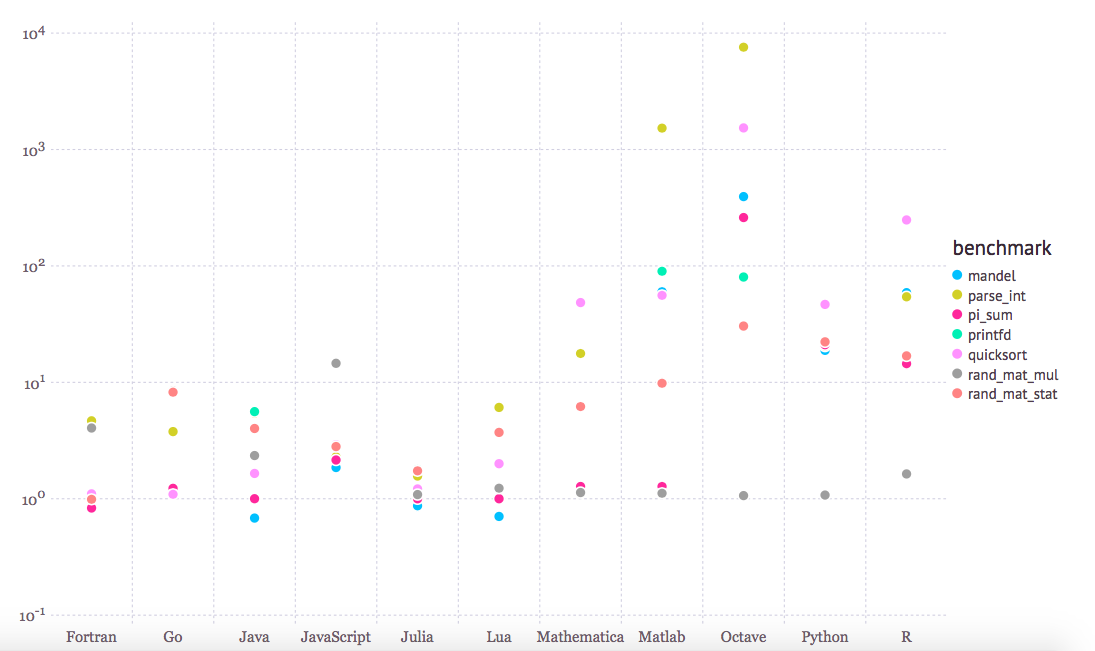
(C言語と比較した場合のベンチマークタイム。小さい方が良い。C言語のパフォーマンスを1.0とする。引用元: http://julialang.org/benchmarks/ )
しかし、Pythonには簡潔なTheanoライブラリもあることを忘れてはいけません。2010年、CPU上でコードを実行した際、NumPyの1.8倍のパフォーマンスを実現したとTheanoの開発者が報告しました。また、対象をGPUとした場合はNumPyの11倍も速くなるとも報告されました(J. Bergstra, O. Breuleux, F. Bastien, P. Lamblin, R. Pascanu, G. Desjardins, J. Turian, D. Warde-Farley, and Y. Bengio. Theano: A CPU and GPU math compiler in Python. In Proc. 9th Python in Science Conf, pages 1–7, 2010)。また、このTheanoのベンチマークは2010年のものであることを注意してください。それからの数年間でTheanoは飛躍的に進歩し、モダンなグラフィックスカードの能力も同様に進歩してきました。
私は、多くのギリシャ人が「万物の生みの親は数である」というピタゴラスの言葉を信じていると学びました。この主張は難解に見えます。存在していないものが生み出されることを、想像するのは困難です-クロトーネのTheano(紀元前6世紀の哲学者)
追記:NumPyの dot メソッドを好きになれない場合は、次の Python 3.5 の登場を楽しみにしてください。行列乗算のための組み込みの 演算子 が使えます!
“手動”の行列-行列乗算(NumPy、BLAS、LAPACKなどの力を借りなければ時間ばかりかかって、とても非効率的です)。
[[1, 2], [[5, 6], [[1 * 5 + 2 * 7, 1 * 6 + 2 * 8],
[3, 4]] x [7, 8]] = [3 * 5 + 4 * 7, 3 * 6 + 4 * 8]]線形代数と最適化されたライブラリがあるなら、入れ子になったforループを使った表現を実装したい人なんていません。
>>> X = numpy.array()
>>> W = numpy.array()
>>> X.dot(W)
[[19, 22],
[43, 50]]この dot を使ったプログラムがあまり魅力的じゃない場合は、Python 3.5ではどのようになるか、以下を見てみてください。
>>> X @ W
[[19, 22],
[43, 50]]正直、行列の演算子として”@”マークを使うことについては、あまり好きだとは言えません。しかし、長い間、これに代わる記号を真剣に考えてきましたが、”未使用”でこの役割を果たせる、より良い記号を見つけることはできませんでした。もし、良いアイディアをお持ちの方がいたら、是非教えてください!
理論上は最高なJulia
Juliaは素晴らしい言語だと私は思います。そして、これからプログラミングや機械学習をやろうとしている人にお勧めしたい言語です。でも本当にそうなのか確信はありません。なぜなら、プログラミング言語に力を注ぐ時に、悲しくてどこか矛盾する事実があるからです。この先数年のうちにJuliaに”人気が出る”かどうかは分からないのです。待ってください。素晴らしく、使い勝手のいいプログラミング言語を定義する時に、”人気”は関係あるのでしょうか? これだけは言わせてください。これはジレンマですが、最も使い勝手のいい言語はよくデザインされたものではなく、人気があることが条件になります。では、それはなぜでしょう。
- 世の中にはたくさんの(ほとんどが無料の)ライブラリが存在するからです。ですから、あなたは自分の時間を有効活用でき、わざわざライブラリを初めから作る必要はありません。
- オンライン上で役に立つ情報や、やり方、例を探すのはとても簡単だからです。
- 言語は改良され、アップデートされて、”さらに良く”するために頻繁に修正が行われるからです。
- 協力し合ったほうがいいですし、チームで一緒に取り組むほうが容易だからです。
- 多くの人が、あなたの考えたコードを活用することができるからです(例えば、GitHubでコードをシェアしたりすれば)。
個人的には、Julia自体はとても気に入っています。私の興味のある分野に完璧にフィットしているからです。しかし、私はPythonを使います。一番の理由は、Pythonを扱いやすくしてくれる素晴らしいものが世間にあふれているからです。Pythonのコミュニティは素晴らしく、この先(少なくとも)5~10年でより身近になり、繁栄していくと私は信じています。Juliaに関しては、確信は持てません。Juliaのデザインはとても好きですし、素晴らしいものだと思います。しかしながら、人気がなければ、”未来を保証された”とは言えません。この先2年ほどで発展が止まってしまったらどうでしょう。私は、いつかは”死ぬ”であろうものに投資してきたことになります。ただし、全ての人がこう考えてしまったら、新しい言語が発展できなくなってしまいますね。
本当は問題がないR
さて、私がかつてRの使用者であったことは別にたいした秘密ではないでしょう。Rに関しての本さえも執筆したことがあります(正確に言うと「 Heat maps in R 」という本です。これは数年前に、ggplot2が使い物になる前に書いたものだということは言っておきましょう。この本を読んでほしいという説得力のある理由は言えません。しかし、もしどうしても読みたければ、5分間で読める無料の 短いバージョンの記事 がありますのでどうぞ)。話が主題からそれました。では、話を元に戻しましょう。Rに問題はあるか。私は何も問題がないと思います。言い換えれば、Rは”データ科学”ではやはり、とてもパワフルで有能な”人気のある”言語であると言えます。MicrosoftがRにかなりの関心を示したのもそう昔の話ではありません。 Microsoftは、統計的計算や予測分析向けの、オープンソースであるR プログラミング言語に関するサービスを提供している商業ベンダーのRevolution Analytics社を買収しました 。
さて、Rに関する私の意見をどのようにまとめましょうか。以下の引用文がどこから来たものか正確には知りませんが(ちょっと前に、どこかの誰かから聞いたものです)、RとPythonの違いをよく説明しているのでご紹介します。”Rは統計学者が統計学のために発展させたプログラミング言語で、Python はコンピュータ科学者が発展させた、統計学の技術をプログラマが扱えるようにした言語である。”ここで言いたいことはRとPythonは両方とも”データ科学”のタスクに似たような形で活用できますが、Pythonの構文のほうが、私にはより自然に感じられます。個人的な好みの問題ですが。
Python に有益な、TheanoとGPUにおけるコンピューティングについて話したいと思いましたが、Rもとても有能であると言うことを Parallel Programming with GPUs and R (GPUとRで並列コンピューティング)という記事を読んで気付きました。ここで皆さんはきっとこう言いたいはずです。”では、私が開発中のモデルをいい感じに輝いたWebアプリケーションにするにはどうしたらいいんですか? Rではそんなことできませんよね!”と。自信を打ち砕くようで申し訳ないですが、それは間違っています。 Shiny by RStudio A web application framework for R.(RStudioによるshiny RのWebアプリケーションのフレームワーク) をご覧ください。これを読めば、私の言いたいことが分かるはずです。どっちが正解とも言えません。おそらく、その先も正解は見つからないでしょう。
私の大好きなPythonに関する言葉を元の文章から一部引用します。”みんな大人なんだからさ。”つまり、言語戦争で時間を無駄にするのはやめようということです。自分にピンとくるツールを選んで使ってください。また、求人という視点からも、言語には良いも悪いはないと言えます。例えば、あなたを”データ科学者”として雇った会社が、あなたが使っているお気に入りのツールボックスにケチを付けることはないでしょう。プログラミング言語は、結局はただの”道具”にすぎません。最も重要な能力は”データ科学者”のように考え、正確な質問をし、問題を解決する力です。難しいのは数学と機械学習のセオリーで、新しいプログラミング言語を学ぶことは比較的簡単です。考えてみてください。釘を金づちで打つやり方を学んだとします。では、他のメーカの金づちで同じことをやるのに難しいことはあるでしょうか? これでもまだ興味のある方は、例に以下のTIOBE Programming Community Indexを見てください。プログラミング言語の人気の尺度の1つです。
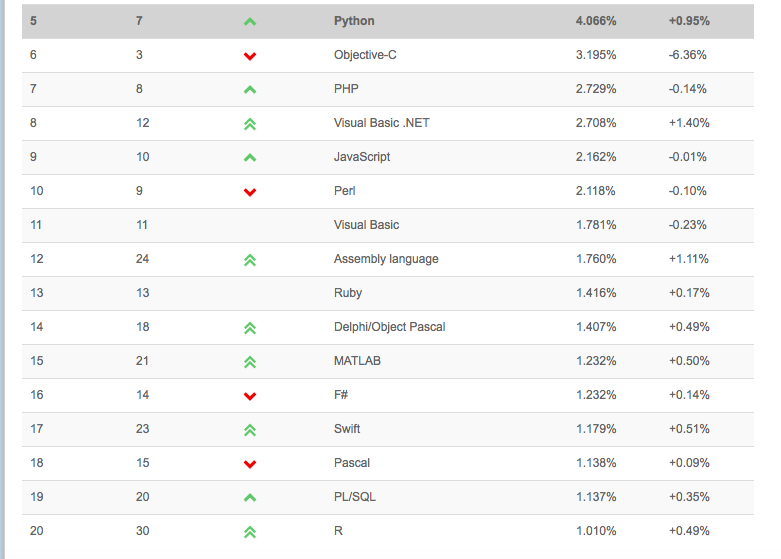
(引用元: http://www.tiobe.com/index.php/content/paperinfo/tpci/ )
しかし、Spectrum IEEE が発表している The 2015 Top Ten Programming Languages (2015年のプログラミング言語のトップ10)を見ると、R言語は急激に順位を上げています(左の列が2015年で、右の列が2014年のランキングです)。
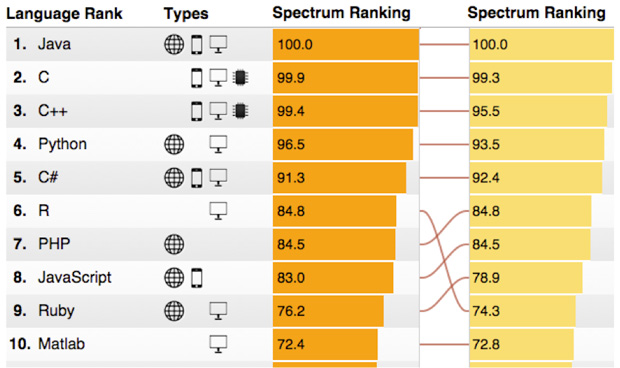
(引用元: http://spectrum.ieee.org/computing/software/the-2015-top-ten-programming-languages )
これでお分かりいただけたでしょうか? PythonとRでは、今やそんなに違いはないのです。さらに言えば、あなたが1つの言語を選んで使っていたとしても、仕事の採用には影響ありませんので心配しないでください。
Perlはどうなったのか
Perlは私がこの仕事をし始めて最初に使った言語です(高校生で、Basic、Pascal、Delphiを使っていたのは別として)。私がドイツで大学院生だった頃にPerlのプログラミングの授業を取っていました。当時はPerlをとても気に入っていました。その時には他と比較するような知識を持ち合わせていなかったんです。日々のプログラミングにPerlを積極的に使っている人は、私の知る限りほんの一握りの人だけです。生物情報学の分野ではまだPerlがよく使われていると私は聞きました。Perlが安らかに眠れるように、ここの項目はこのくらいにしておきましょう。以下の記事を参考にしてください。 “Perl は死んだ。Perl万歳!”
他の言語
機械学習に使える言語は他にもたくさんあります。例えば、 Ruby ( (Thoughtful Machine Learning: A Test-Driven Approach(思いやりのある機械学習:テスト主導のプローチ) )、 Java ( Java-ML )、 Scala ( Breeze )、 Lua ( Torch )などです。しかし、数年前に講座を受けたJavaや、Scalaで書かれたSpark向けのPythonのAPIである PySpark を除いて、私には他の言語はあまり知識がないので、何とも言えません。
Pythonは死にかけの言語なのか
これは冗談抜きの疑問です。Quoraでも最近取り上げられていました。この疑問に関しての素晴らしい意見を聞きたければ、 こちらのスレッド を見てください。ただし、私の意見を聞きたい人は、私の答えはこれです。「いいえ、そうではありません。」Pythonは”比較的に”古い言語です。最初に登場したのは1990年代初期です(仮に1991年としましょう)。そして、他のプログラミング言語と同様に、Pythonも正しい選択をすることと、妥協することが必要でした。どんなプログラミング言語にもそれぞれのクセがあります。より最近の言語は過去の失敗から学んでいる傾向にあります。これはいい傾向です(ちなみに、RのリリースはPythonが登場してからそれほど経過していない1995年でした)。当時のPythonは、他の言語もそうであるように、”完璧”には程遠く、欠点だらけでした。Pythonのコアユーザの私から言わせてみれば、GIL(Global Interpreter Lock)にはイライラさせられました。でも、GILはマルチプロセッシングや、マルチスレッドのモジュールを持ち、特に制限もありません。しかし、ある一部の内容によっては、少しだけ”不便”であるというだけです。
プログラミング言語が”どれだけ素晴らしいか”を測る基準は存在しません。その基準はあなたが何をしたいかによることが大きいのです。作業をする時には自分にこう尋ねてみてください。”私は何を達成したいのか。それを達成するのに一番いいツールはなんだろうか”と。つまり、”金づちしか持っていなければ、すべては釘に見えるでしょう”。金づちと釘の話に戻りましたが、Pythonはとても用途が広い言語です。私は日々の大量のリサーチには、Pythonの機械学習ライブラリである優秀なscikit-learnや、データ変更のためのpandas、可視化のためのmatplotlibとseaborn、これらのものをトラッキングするためのiPython notebookを使用しています。
結論
さて、とてもシンプルな質問だったわりにはとても長い答えとなってしました。この手の話なら私は何時間でも何日でも語り続けられますよ。でも、これ以上話を複雑にするのはやめて、結論にいきましょう。

訳:
「空を飛んでいるじゃないか! どうやったんだ?」
「Pythonだよ!」
「昨日の夜にやり方を覚えたんだ。簡単なんだ。
Hello, world、はただ、 print"Hello, world!" と書くだけでいいんだ。」
「分からないよ。動的型付けは?オフサイドルールは?」
「こっちに来なよ。プログラミングが面白いって改めて分かるよ! ここでは新しい世界が広がっているんだ!」
「でもどうやって飛べばいい?」
「僕はただ import antigravity って打っただけだ。」
「それだけ?」
「比べるために薬箱の中を全部試してみたんだよ。
でも、これがたぶんPython流だと思う。」
(引用元: https://xkcd.com/353/ )
フィードバックと意見
この記事に関して、とても貴重なフィードバックがありました。皆さんにも役に立つ情報だと思います。さまざまな意見を聞くというのは、どんな時でもいいことです。特に”データサイエンス”や機械学習、プログラミングの分野の初心者の方には特におすすめです。覚えておいてください。”一部のアドバイス”は偏った意見の場合があります。お気付きかもしれませんが、私の偏りはPythonを好んでいるということです。ごめんなさい。でもこれが私なんです! さて、それはさておき、以下の貴重なコメントをぜひ読んでください。そして、遠慮せずに質問を投げかけたり、ディスカッションに参加したりしてください。
Python
- rm999さんより hackernews にて
1年前くらいから、主にRではなくPythonを使用している。データパイプラインを一括化するために使用(データソースから始まり、モデル化やフロントエンド、可視化まで)。どんな言語を使うにせよ、最初の数年は「自分が何を知っているかどうか、自分の生産性はどうか」ということはあまり関係ない。標準的なgoogle検索能力だけ。Pythonに移行した主な理由は、自分のチーム以外では尊敬され使われている言語であったからというとても実務的な理由からだった。この言語を使いこなせれば、他のチームとのツールの貸し借りやコードの委託、助言を求めるといった、あらゆる場面で協力が簡単にできる。一部の企業では、「一緒にハッキングして、問題の解決は他人にまかせよう」といった立場でデータサイエンスに取り組んでいる。経験から、Rを使用するとこの概念を増幅してしまうと思う。Rはすごく便利だから、とても残念なことだと思う。
- DrNukeさんより hackernews にて
この記事の「ツールはすごいことをするためだけの道具であり、それ自体が目的ではない」という、ハッキングに対する姿勢が大好きです。データサイエンスが急速に進み、迅速に必ずしもスペシャリストではない人と関わる機会が増えるため、今のPythonの世界では正しいツールを正しい時に使うことが要求されます。
- zzleeperさんより hackernews にて
面白い記事でした。数値を扱う多くのPythonistaが同じ立場にいると思います。Rの構文を少し不自然だと思い、Matlabはマトリクス以外で使用するには物足りないと思い、そしてJuliaに関してはこれ以上進展があるのかと思いながら、多くの言語を我慢しているのだと思います(少なくとも私はそう思います)。
- JanneJMさんより reddit にて
鍵となるのは品質の良いライブラリです。自分含め、多くの知り合いは、Python自体に興味を持っていません。私たちはNumpy、 Scipy、Matplotlib、Pandasなどを使用しています。Pythonはその延長線にあるだけだと思っています。もし、これらのライブラリがRubyやPerl、もしくはLuaで提供されれば、それらを使用すると思います。
Perl
- Leni536さんより hackernews にて
“Perlは生物情報学の分野では未だに一般的だと思います”と書かれていますが、私も同感です。生物情報学では、日常的に行うタスクはプレーンテキストの構文解析で使用されています。Perlはテキスト構文に優れ、すぐに正規表現を使用できます。”私の”世代の生物学者はPythonを使用してデータのクリーンアップや分析(20-30)を行うことがあります。それは、Pythonを使用した方が良いプロッティングができる、言語として習得しやすい、多くの大学でも教えているなど、理由は様々です。上の世代は通常Perlを使用しています。
R
- geomarkさんより hackernews にて
Courseraでデータ科学のコースを受講し、R初心者だった私は達人になりました。以前はWebプログラミングにPythonを使用していました。そのため、統計プログラミングに便利だとは思いましたが、最初はそれ以外の場面で使用するRはあまり好きではありませんでした。しかし、数々の素晴らしいRのパッケージがあり、役に立つことを知りました。例えば、最近Webスクレイピングのためのrvestパッケージを知りました。Rを用いた可視化はとても優れていると思います。私の知る限り、Pythonではそうはいきません(間違っていないと思います)。洗練された統計アプリのアップロードにはshinyまたは RStudio Presenterが使いやすいと思います。しかし、Rでは、大規模なアプリには向いていないと思いませんか。そのため、私はPythonとRの両方を使用する必要があると感じています。追記:ナイスなリストをありがとうLofkin。さらに、この記事で著者はPython構文の方が自然に感じると言っていますが、私もそう思います。しかし、Rのmagrittrやdplyrパッケージを使い始めてみると、良い機能があり、必ずしもPython構文の方が自然とは思わないようになりました。
Adam_Oさんより hackernews にて
学生の視点からすると、オンライン分析やデータ分析、統計コースなどで学ぶ際、ほとんどがRを使用しているため、避けることが難しい。基本的な概念を理解できれば、Pythonへの移行は簡単にできると思う。ただ、可視化にはまだ多くの人がggplot2を好んで使っていると思う。Rを使うと、言語特有の”冷たく硬い”感じが、統計学者になったような錯覚を与える。最終的には、両言語学んでおいた方が役に立つと思う。
MATLAB/Octave
- sampoさんより hackernews にて
Andrew Ng氏によると、経験上、Pythonより、OctaveやMatlabを使用した方が、受講生は宿題を早く実装するとCourseraの機械学習のコースで述べていた。確かに実装して、ちょっとした数値アルゴリズムで遊ぶのがコースの目的ならそうかもしれない。でも、リンク先のブログでは、Pythonを使用して、既存の機械学習ライブラリを呼び出している。
- misiti3780さんより hackernews にて
OctaveやMatlabは”最高”だけど、Webアプリに統合する人はがんばって。できないと思うけど。同じアルゴリズムを2回使用するつもりがなければ、避けた方が良いよ。Matlabのライセンス料は高いし、ツールボックスも追加で料金が取られる。Rは便利だと思う。だって、多くのリソースが長い間存在しているし、統計のコミュニティの多くが使用している。あと、他の言語にはまだない、便利なライブラリも多く存在する(ggmapのように)。でも、Rは実際のWebアプリに統合するのは難しい。HadoopストリーミングはRやOctave、 Matlabをサポートしていない。
- thanatropismより hackernews にて
ここでは、Matlab構文が現代のFortranに実際とても近いことが書かれていない。Matlabプログラムに、型や一般的な冗長性、do-loopの構文などを書き直し、Fortranでプログラムを2個は書いたことがある(異なる場面でモンテカルロ法で)。
Julia
- Lofkinさんより hackernews にて
個人的には、Juliaに言語を変えたくなってきました。でも、遅い高階関数や、コアのデータ・インフラストラクチャの中の高位のchurn、Pymc3がないことがpydataをもう少し使ってみようかなという気持ちにさせます。numbaが私をまだ踏ん切らせてくれません。
- Buttons 840さんより hackernews にて
私はプロとしてPythonを8年間、使っています。そして、Pythonが私の一番好きな言語です。そして、numpyとscikit-learnを少し使っています。ですが、最近Juliaの使い方を覚え始めて、とても楽しんでいます。習得するのも簡単ですし、うまく動いてくれます(読み出しも速い)。実際は、Juliaを覚えるには、numbaを覚えるのと同じくらいの労力がいると私は思います。でもパフォーマンスは似ています(少しだけJuliaのほうがいい、って言う人もいるでしょうか?)。
- idunningさんより hackernews にて
日々の業務(や別のプロジェクトでも)にほとんどJuliaしか使ってない人は同じ意見だと思いますが、私はこの筆者のJuliaに対しての考え方は正解だと思います。Juliaは最高の言語だと思うし、私の生活をより良いものにしてくれています。比べると他の言語よりも実際に優れているパッケージは存在していると私は思います。その一方で、私は完璧ではない物事に対しての我慢強さは備えているつもりです。自分のことは自分で解決しますし(幸運なことに、そういう時間もあります)、その時点では存在しないものであれば、それをコード化する意思もあります。多くの人が私のようでないのは当たり前ですし、別に問題ではありません。この筆者はJuliaが”生き延びる”ことができなかった時のリスクを負うのを拒否しています。これはフェアな判断です。Juliaはまだ完璧ではありませんが、完璧になるにはあと少しです。私はJuliaが”生き残る”(そして繁栄する)という自信があります。そして、十分なコミュニティを成長させ続けるでしょう。私は、あと2年かそこらで、この筆者がJulia島へ行きつく道筋を発見するだろうと信じています。
- nikskoさんより reddit にて
私はJuliaに関してのこの議題に賛成です。Juliaは大きな可能性を秘めていますし、このような種類のアプリケーション向けにオーダーメイドで作られています。ただ、コミュニティとサポートがまだ整っていないというだけです。私は1学期をかけて、計算の進化ダイナミクスという分野で小さな研究プロジェクトを行いました。その中でも最も退屈で難しかったのは、私のやりたかったことをJuliaでやらせることでした。また、当時はdocstringのサポートがまだありませんでした。Juliaは速くて、手が込んでいますが、まだ成長しきれていないという印象があります。
- KG7ULQさんより reddit にて
コーセラでNg氏の機械学習の授業を受けた後、周りを見回すとPythonを使うのが妥当であるという感じでした。でも、あなたが学んだほうがいいと言っていたものも含めて、大きなライブラリはいくつもありました。それから、Juliaを見てみると、Juliaを学ぶことはJuliaに既に組み込まれている線型代数学やSIMDの全てを学ぶのと同じことだって気付いたんです。ですから、機械学習にとって”最適”な言語であるように感じました。
その他の言語(私が言及し忘れた言語)
- leni536さんより hackernews にて
C++に悪い点はありません。私は線形代数にArmadilloライブラリを使っていますが、LAPACKとBLASのラッパとして、とても良いですよ(そして速い!)。いくつかの理由で科学者はC++を使うのを少しだけ嫌がります。何らかの理由で、”より簡単”な言語でプロトタイプを作らなければ”ならない”とします。インタプリタ言語とは対照的に、C++を計算機として使えないことは明らかです。しかし、プロトタイピング言語で計算に行き詰まっている人を見ることはありますが、最終的に速いプラットフォームに移動するのを目にすることはありません。ポイントは科学的な計算をする際、C++は難しいものではないということです。
- WallyMetropolisさんより reddit にて
Pythonに取って代わる言語があるとしたら、私にとってはScalaが最も有力な候補です。関数型言語は数学的手法に適していると思います。またJVM上にあるため、”至る所”で発生する沢山のオーバーヘッドに悩まされることなく、プロトタイプをプロダクションコードにすることができます。SparkはScalaのキラーアプリケーションです。今では、プロトタイプを作るところから、任意の大規模データセット上で実行するところまで、大きな障害はなく行うことができています。
- rpcope1さんより reddit にて
[Scala]はコンパイルする時は遅いかもしれません。しかしCPythonと比べれば安全かつ格段に速いです(バイトコード以外のコードやCまたはFortranのライブラリを呼ぶ時のコードを除きます)。また、Pythonで使っていた、とても懐かしい数多くのコンセプトを利用できます。例えば、Option[T]、暗黙的な修飾子、map, filter, reduceといった便利な関数、lambda式などです。

株式会社リクルート プロダクト統括本部 プロダクト開発統括室 グループマネジャー 株式会社ニジボックス デベロップメント室 室長 Node.js 日本ユーザーグループ代表
- X: @yosuke_furukawa
- Github: yosuke-furukawa
関連記事