2015年8月20日
Pythonにおけるプロファイリング ― コードの高速化のために
(2015-07-28)by HumanGeo
本記事は、原著者の許諾のもとに翻訳・掲載しております。
ここHumanGeo社ではPythonを使うことが多く、それは極上の楽しみでもあります。美しく機能的なコードを短時間で記述するのにPythonはうってつけで、私個人にとっても一押しの言語です。仕事に限らずプライベートでも使っています。そんな素晴らしいPythonですが、欠点がないわけではありません。それはあまりにも遅いことです。幸いPythonには、コードをプロファイリングするための優れたツールがいくつかあるので、コードの美しさと速さを共存させることができます。
HumanGeoで働き出した頃、実行に長時間を要すプログラムのボトルネックを探り、何とかしてそれを速くさせるという仕事を担当しました。その内容は、 cProfile や PyCallGraph ( ソース )、はたまたPyPy(高速なPython用代替インタプリタ)などの各種ツールを使って、プログラムを最適化するためのベストな方法を見つけるというものです。この投稿では、PyPyを除く(制作時のインタプリタの一貫性を維持するため除外しました)これらのツールを私がどのように使ったか、そしてコード最適化の方法を探し出すにあたり、熟練の開発者をも含めた全ての開発者にとって、それらがどのように役立つかを見ていきたいと思います。
注意:時期尚早な最適化は しない でください。 理由はこちらでご確認いただけます。
ツール
まず、Pythonのコードをプロファイリングできる便利なツールを見てみましょう。
cProfile
CPythonディストリビューションには、profileとcProfileという2つのプロファイリングツールが付属しています。両者は同一のAPIを使用しており同じような動作をするはずですが、前者の方はランタイム・オーバーヘッドが大きいため、この投稿ではcProfileについて話すことにします。
cProfileは便利なツールで、grep可能な形でコードをプロファイリングし、問題となる部分がどこなのか大体のヒントを与えてくれます。遅いコードを例に見ていきましょう。
-> % cat slow.py
import time
def main():
sum = 0
for i in range(10):
sum += expensive(i // 2)
return sum
def expensive(t):
time.sleep(t)
return t
if __name__ == '__main__':
print(main())ここでは time.sleep を呼び出すことで、実行時間の長いプログラムをシミュレートし、プロファイリングの結果に重要性があるように装っています。それでは、早速これをプロファイリングしてみましょう。
-> % python -m cProfile slow.py
20
34 function calls in 20.030 seconds
Ordered by: standard name
ncalls tottime percall cumtime percall filename:lineno(function)
1 0.000 0.000 0.000 0.000 __future__.py:48(<module>)
1 0.000 0.000 0.000 0.000 __future__.py:74(_Feature)
7 0.000 0.000 0.000 0.000 __future__.py:75(__init__)
10 0.000 0.000 20.027 2.003 slow.py:11(expensive)
1 0.002 0.002 20.030 20.030 slow.py:2(<module>)
1 0.000 0.000 20.027 20.027 slow.py:5(main)
1 0.000 0.000 0.000 0.000 {method 'disable' of '_lsprof.Profiler' objects}
1 0.000 0.000 0.000 0.000 {print}
1 0.000 0.000 0.000 0.000 {range}
10 20.027 2.003 20.027 2.003 {time.sleep}ごく平凡なコードで、思ったほど役に立ちそうにありません。呼び出しがアルファベット順に並べられていますが、さほど重要ではないでしょう。それよりも私が見たいのは呼び出しの回数、あるいは累積実行時間でソートされたリストの方です。幸い、引数 -s があるので、それでリストをソートすればコードの問題箇所を見つけることができます。
-> % python -m cProfile -s calls slow.py
20
34 function calls in 20.028 seconds
Ordered by: call count
ncalls tottime percall cumtime percall filename:lineno(function)
10 0.000 0.000 20.025 2.003 slow.py:11(expensive)
10 20.025 2.003 20.025 2.003 {time.sleep}
7 0.000 0.000 0.000 0.000 __future__.py:75(__init__)
1 0.000 0.000 20.026 20.026 slow.py:5(main)
1 0.000 0.000 0.000 0.000 __future__.py:74(_Feature)
1 0.000 0.000 0.000 0.000 {print}
1 0.000 0.000 0.000 0.000 __future__.py:48(<module>)
1 0.003 0.003 20.028 20.028 slow.py:2(<module>)
1 0.000 0.000 0.000 0.000 {method 'disable' of '_lsprof.Profiler' objects}
1 0.000 0.000 0.000 0.000 {range}どうですか? expensive 関数の部分に問題があることが分かりますね。不快な速度低下を招いてしまうほど、 time.sleep が呼び出されています。
-s パラメータの有効な引数のリストは、 Pythonのドキュメンテーション で確認できます。結果を異なるファイルに保存したい場合は、必ずアウトプットオプションの -o を使ってください。
基本的なことが分かったところで、別のプロファイリングツールを使って、問題となっているコードを見つけ出す方法を見てみましょう。
PyCallGraph
PyCallGraphは、cProfileを視覚的に機能拡張したものと言えます。優れた Graphviz のイメージを調べることで、全体のコードの流れを追うことができます。PyCallGraphは、Pythonの標準設定には含まれていませんが、次のように簡単にインストールできます。
-> % pip install pycallgraphインストールしたグラフィックアプリケーションであるPyCallGraphを実行するには、次のコマンドを使います。
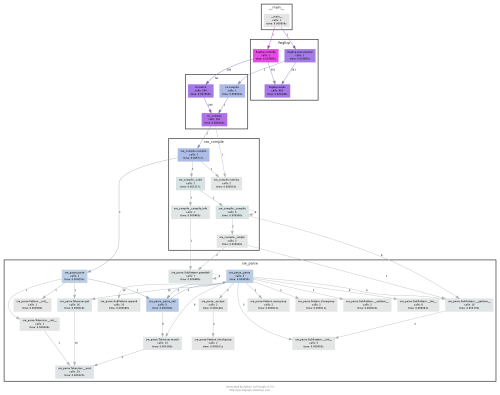
-> % pycallgraph graphviz -- python slow.pypycallgraph.pngファイルがスクリプトを実行するディレクトリに作成され、(もし既にcProfileを実行していれば)似たような結果が得られます。出力される数値はcProfileの結果と同じですが、PyCallGraphの利点は、呼び出される関数の関係が視覚化されている点です。
どんな図なのか見てみましょう。

これはとても便利ですね。プログラムの流れや実行される関数、モジュール、ファイルが分かり、ランタイムと呼び出し回数も表示されます。これを大規模なアプリケーションに対して使えば、大きな図が生成されますが、色分けされているので問題となるコードを見つけるのはとても簡単です。下の図は、PyCallGraphのドキュメンテーションから引用したもので、正規表現による複雑な呼び出しに関するコードの流れが図示されています。
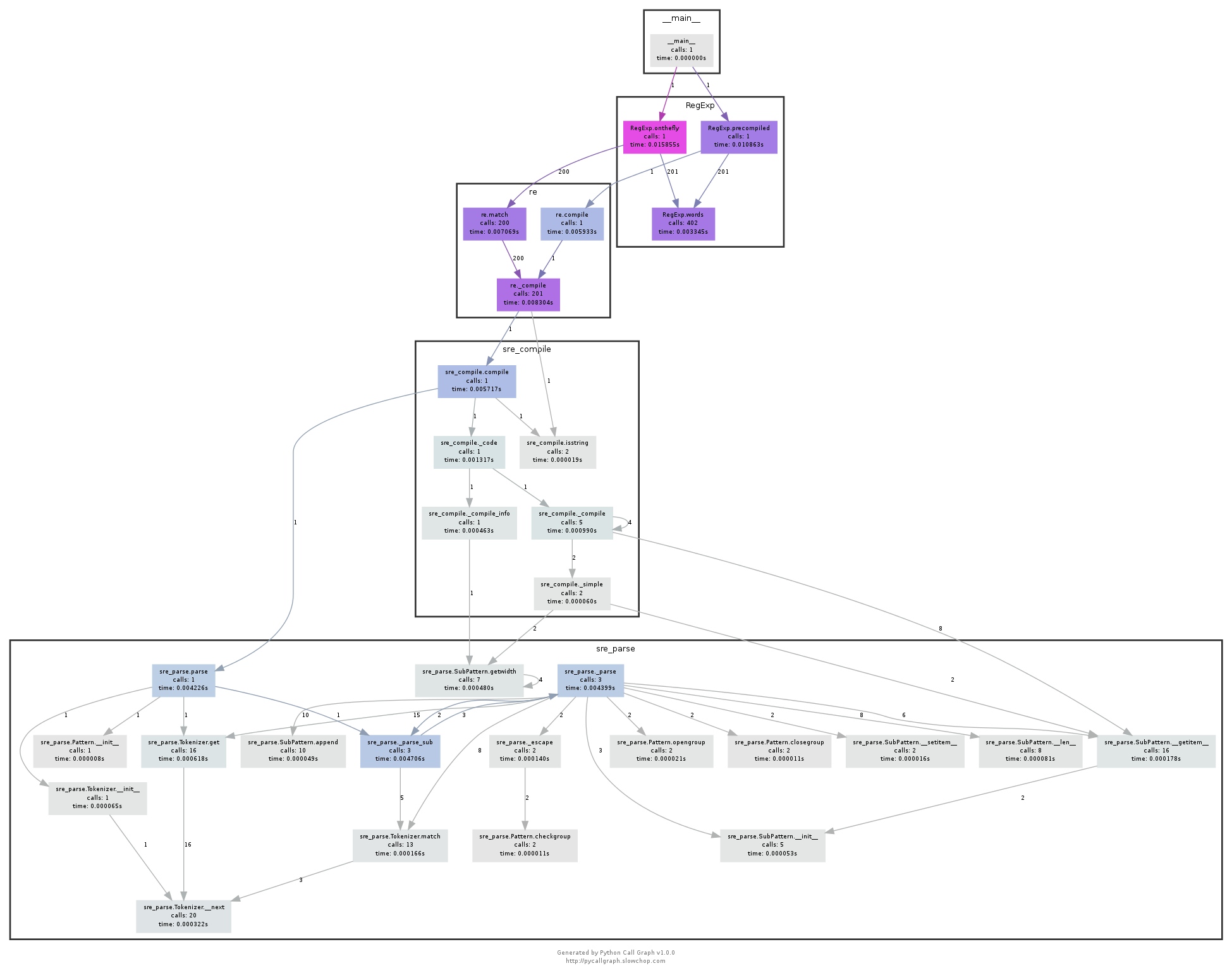
こうした情報を元に何ができるのか
コードの処理が遅くなる原因を見つけ出したら、スピードアップするための適切な対策を選択します。コードの低速化に対する解決策を、課題ごとにいくつか検討してみましょう。
I/O
たくさんのwebリクエストを出すなどして、コードがI/Oに大きく依存している場合は、Pythonの標準 スレッド モジュールを使って解決できるかもしれません。I/O関係ではないスレッドに関しては、コード中心のタスクが一度に複数のコアを使うことを防ぐcPythonのGILが原因なので、Python向きのケースではありません。
正規表現
予想できるように、問題解決のために正規表現を使うことにした場合、 2つの問題を抱えることになります 。正規表現を正しく理解し、維持することは難しいものです。正規表現については、全く別の記事で書こうと思えば書こともできますが(書くつもりはありません。正規表現は難しく、私が書くより、もっとうまく説明している記事があるので)、ここでは、簡単なヒントをいくつかご紹介します。
.*を避ける。最長マッチを何でもかんでも使用すると遅くなるので、キャラクタクラスを最大限活用することで、この問題を回避するのに役立ちます。- 正規表現を使わない。多くの正規表現は、
str.startswithやstr.endswithなどのシンプルなstringメソッドで解決することができます。多くの情報が str documentation に掲載されているので確認してみてください。 - re.VERBOSE を使う。Pythonの正規表現エンジンは、素晴らしく、とても便利ですので、ぜひ活用してください!
正規表現に関しては、これくらいにしておきます。更に詳しく知りたいようであれば、素晴らしい情報がインターネットに掲載されていますので、そちらをご確認ください。
Pythonコード
私がプロファイリングしていたコードにおいては、英語の言葉を ステミング するために、何万回もPythonの関数を実行していました。問題の原因を特定することの良いところは、これらの操作が簡単にキャッシュできるという点にあります。関数の結果を保存することができ、最終的に当初よりも10倍早い速度でコードを処理することができました。Pythonでキャッシュを作成するのは、非常に簡単です。
from functools import wraps
def memoize(f):
cache = {}
@wraps(f)
def inner(arg):
if arg not in cache:
cache[arg] = f(arg)
return cache[arg]
return innerこの手法は、 メモ化 と呼ばれており、デコレータとして実装されています。これは以下のように、簡単にPythonの関数に適用することができます。
import time
@memoize
def slow(you):
time.sleep(3)
print("Hello after 3 seconds, {}!".format(you))
return 3この関数を複数回実行しても、結果が計算されるのは一度だけです。
>>> slow("Davis")
Hello after 3 seconds, Davis!
3
>>> slow("Davis")
3
>>> slow("Visitor")
Hello after 3 seconds, Visitor!
3
>>> slow("Visitor")
3これはプロジェクトの高速化に非常に有効で、遅延することなくコードを実行することができます。
注意:ただし、 pure 関数にのみ使用してください。もしメモ化をI/Oなどのようなサイドエフェクトと併せて関数に使用すると、キャッシュは予測外の結果を得ることになります。
その他のケース
コードを容易にメモ化できない場合や、 O(n!) といった、おかしなアルゴリズムではない場合、あるいは、プロファイルが”flat”である(コードに特に問題となる箇所がない)場合には、他のランタイムや言語を検討すべきでしょう。PyPyは優れた選択肢ですし、アルゴリズムの核となる部分をC言語による拡張と併せて書いても良いでしょう。幸いにも、私が行っていたプロジェクトではその必要がありませんでしたが、もし必要な場合は使ってみてください。
結論
コードをプロファイリングすることは、問題となるコードの場所や効率化を図るために開発者として何ができるかなど、プロジェクトの流れを理解するのに役立ちます。Pythonのプロファイリングツールは素晴らしく、非常に簡単で、問題の原因を素早く見つける手助けとなります。Pythonは高速な言語ではありません。しかしだからと言って、遅いコードを書くべきということでもありません。アルゴリズムの管理を行い、プロファイリングすることを忘れないようにしましょう、そして、決して時期尚早な最適化はしないでください。

株式会社リクルート プロダクト統括本部 プロダクト開発統括室 グループマネジャー 株式会社ニジボックス デベロップメント室 室長 Node.js 日本ユーザーグループ代表
- X: @yosuke_furukawa
- Github: yosuke-furukawa
関連記事









