2017年10月10日
SQLトランザクション分離 実践ガイド

(2017-08-01)by Joe Nelson
��本記事は、原著者の許諾のもとに翻訳・掲載しております。
(注:2017/10/16、いただいたフィードバックを元に翻訳を修正いたしました。)
(注:2017/10/11、いただいたフィードバックを元に翻訳を修正いたしました。)
データベースのドキュメントで分離レベルを目にして、軽く不安を感じつつ、あまり考えないようにしたことはないでしょうか。トランザクションの日常の使用例できちんと分離について言及しているものはほとんどありません。多くはデータベースの初期設定の分離レベルを利用しており、後は運頼みです。しかし、本来、理解しておくべき基本的なトピックであり、いくらか時間を投入してこのガイドの内容を学習すれば、もっと快適に作業できるようになるでしょう。
私はこの記事の情報を学術論文、PostgreSQLドキュメンテーションから集めました。分離レベルの 何たる かだけでなく、適用の正確さを保持しつつ最大速度で使うにはいつ使うべきか、という疑問に答えるべく、同僚と議論もしました。
基本的な定義
SQL分離レベルを適切に理解するには、まずトランザクションそのものについて考えるべきでしょう。トランザクションという発想は、契約法から来ています。法律のトランザクション(取引)は、原子性(atomic: 全規定が適用されるか、全く適用されないかのいずれか)、一貫性(consistent: 法的手続きを遵守)、永続性(durable: 一度コミットしたら、各当事者は誓約を破ることはできない)の要素を備えていなければなりません。これらの特性はA、C、Dの頭文字を取ってデータベース管理システムの “ACID” として知られています。最後の文字、独立性・分離性(isolation)の “I” がこの記事のテーマです。
法律とは対照的に、データベースにおけるトランザクションとは、データベースを1つの一貫した状態から別の一貫性のある状態に変換する一連の操作です。つまり、トランザクションを実行する前に、データベースの一貫性の制約が満たされていれば、実行後もそれが満たされているということになります。
データベースはこの発想をさらに押し進め、それぞれ、あらゆるSQLデータ変更ステートメントで制約を強制できたでしょうか。既存のSQLコマンドでは不可能です。ユーザが各ステップで一貫性を保てるほどの表現力はありません。例えば、ある銀行口座から別の口座にお金を振り替えるという古くからあるタスクには、片方の口座から引き落とされたものの、他方の口座に振り込まれる前、という、一時的に一貫性のない状態が含まれます。このため、ステートメントではなく、トランザクションが一貫性の単位として扱われます。
この時点で、データベース上で連続的に実行されているトランザクションが、それぞれデータへの排他的アクセスの順番が来るのを待っていることが想像できます。この秩序だった世界において、データベースは、無害とはいえ矛盾のある短い区間を通過しながら、一貫した状態から別の一貫性のある状態に移行するようになっています。
直列的なトランザクションは理想的ですが、事実上どのようなマルチユーザデータベースシステムでも実行不可能です。航空会社のデータベースで、1人の顧客がフライトを予約している間、他の人は誰もアクセスできければどうなるか、想像してみてください。
ありがたいことに、本当の意味で直列化されたトランザクション処理は、できなくても問題ない場合がほとんどです。多くのトランザクションは互いに影響を及ぼしません。完全に分離された情報を更新したり読み込んだりするからです。そのようなトランザクションを同時に走らせた(コマンドをインタリーブした)結果は、1つの全てのトランザクションを別のトランザクションの前に実行した場合と何ら変わりはありません。このケースは、 直列化可能 と呼びます。
しかし、トランザクションを並列に実行すると、確実にコンフリクトの危険が生じます。データベース監視がなければ、トランザクション同士が互いの作業データに干渉し、不正なデータベースの状態が生じる可能性があります。それは、不正なクエリ結果、および制約違反も引き起こします。
現代のデータベースは、干渉を防ぐために、トランザクション内のコマンドを自動的かつ選択的に遅延または再試行する手段を備えています。データベースには干渉を防ぐための厳密さを上げるいくつかのモードがあり、それを分離レベルと呼びます。 「高い」レベルであればあるほど、コンフリクトを検出、または解決するために、より効果的、しかしコストがかかる手段を採用します。
異なる分離レベルで並行トランザクションを実行すれば、アプリケーション設計者は並行性とスループットのバランスを取ることができます。分離レベルを低くするとトランザクションの並行性は向上しますが、トランザクションにある種の不正なデータベース状態が生じるリスクは高まります。
適切なレベルを選ぶには、どの並行インタラクションがアプリケーションの要求するクエリに脅威を及ぼすのかを理解しなければなりません。これから見ていきますが、アプリケーションによっては、明示的なロックをかけるなどの手動操作によって、標準よりも低い分離レベルで間に合ってしまう場合もあります。
分離レベルを検証する前に、動物園に立ち寄って既に見つかっているトランザクションの問題を見てみましょう。この問題は「トランザクション副作用」と呼ばれています。
トランザクション副作用の動物園
それぞれの副作用について、インタリーブされたコマンドの指示パターンを調べ、それがどう問題になるのかを確認します。そして、許容されたり、さらには望ましい効果を得るべく意図的に使われたりする場合はそれを記録します。
2つのトランザクションのアクションには、T1とT2の短縮表記を使用します。以下、一例です。
r1[x]– T1は値/行 x を読み込む。w2[y]– T2は値/行 y を書き込む。c1– T1をコミットする。a2– T2をアボートする。
ダーティライト
トランザクションT1がアイテムを変更、T1をコミットまたはロールバックする前にT2がさらにアイテムを変更することです。

パターン
![w1[x]…w2[x]…(c1 or a1)](../wp/wp-content/uploads/2017/10/isolation-diagram-dw.png)
危険性
ダーティライトが許されると、データベースはトランザクションのロールバックを必ずしも実行できない状態になります。以下を考えてみてください。
- {db in state A}
- w1[x]
- {db in state B}
- w2[x]
- {db in state C}
- a1
状態Aに戻るべきでしょうか? 違います、そうするとw2[x]を失ってしまいます。では状態Cに留まりましょう。c2が起これば問題ありません。しかし、a2が起こったらどうしましょうか? Bを選ぶことはできません。さもなければa1が元に戻ってしまいます。しかし、a2が元に戻ってしまうので、Cを選ぶこともできません。背理法です。
ダーティライトはトランザクションの原子性を破ってしまうので、たとえ最も低い分離レベルであっても関係データベースはそれらを許可しないのです。抽象的に問題を検討するのが良いのは、単にそうすると勉強になるからです。
さらにダーティライトは整合性違反も許容してしまいます。例えば、制約がx = yであるとしましょう。トランザクションT1とT2は個別には制約を守るかもしれませんが、ダーティライトで一緒に実行すると違反をします。
- 開始、x = y = 0
- w1[x=1] … w2[x=2] … w2[y=2] … w1[y=1]
- 結果、 x = 2 ≠ 1 = y
合法な使用法
ダーティライトが有用な状況はまずないでしょう。ショートカットとしてでさえも役に立ちません。だからデータベースはこの使用を許可していないのです。
ダーティリード(非コミット依存)
トランザクションがコミットされていない並列のトランザクションのデータを読み取ってしまうことです。(前の副作用と同様、コミットされていないデータを「ダーティ」と呼びます)

パターン
![w1[x]…w2[x]…(c1 or a1)](../wp/wp-content/uploads/2017/10/isolation-diagram-dr.png)
危険性
T1が行を変更し、T2がそれを読み取ると、T1がロールバックします。するとT2が「存在したことのない」行を保持することになります。存在しないデータによって将来の決定をくだすのは賢い考えではないでしょう。
ダーティリードはさらに制約違反にも門戸を開いてしまいます。制約x = yを仮定しましょう。また、T1がxとyの両方に100を足し、T2がその両方を2倍にするとします。どちらのトランザクションもx = yを保持します。しかし、w1[x += 100]、w2[x *= 2]、w2[y *= 2]、w1[y += 100] のダーティリードは制約に違反します。
最後に、たとえ並列トランザクションがロールバックしなくとも、別のオペレーションの途中で始まるトランザクションは、矛盾したデータベース状態をダーティリードする可能性があります。一貫性のある状態でトランザクションを開始させたいものです。
公正な使用法
ダーティリードは、デバッグや進捗監視など、あるトランザクションに別のトランザクションを見張らせたい時に便利です。例えば、COUNT(*) を1つのトランザクション内のテーブル上で繰り返し実行しながら、別のトランザクションがその中にデータを取り込めば、取り込みの速度や進捗が分かります。しかしダーティリードが使える場合に限られます。
さらにこの副作用は、長く変化していない履歴情報にクエリを投げている間には決して起こりません。書き込まなければ、問題にならないのです。
ファジーリード、そしてリードスキュー
トランザクションが一度読んだデータを再読み込みすると、そのデータは別のトランザクション(最初の読み込みからコミットしていた)によって既に変更されています。
別のトランザクションはコミットをしているという点で、ダーティリードとは異なります。さらに、この副作用が現れるには2回の読み取りが必要です。

パターン
![r1[x]…w2[x]…c2…r1[x]…c1](../wp/wp-content/uploads/2017/10/isolation-diagram-nrr.png)
下の図のように、2つの値を含む形態は リードスキュー と呼ばれます。
![r1[x]…w2[x]…w2[y]…c2…r1[y]…(c1 or a1)](../wp/wp-content/uploads/2017/10/isolation-diagram-rs.png)
ファジーリードはリードスキューの退化した場合であり、b = aを満たすような状態です。
危険性
ダーティリードと同様、ファジーリードにおいてもトランザクションは矛盾した状態を読み込むことができます。ただ、発生の過程はやや異なっています。制約がx = yであると仮定しましょう。
- 開始、 x = y = 0
- r1[x] … w2[x=1] … w2[y=1] … c2 … r1[y]
- T1の観点では、x = 0 ≠ 1 = y
T1はいかなるダーティデータも読み込みませんが、T2が滑り込んで、T1の読み込みの間に値を変更し、コミットします。この違反は、同じ値を再読み込みするT1さえ含んでいないことに注意しましょう。
リードスキューは2つの関連要素の間で制約違反を起こす原因になり得ます。例えば、制約がx + y > 0だとしましょう。すると次のようになります。
- 開始、x = y = 50
- r1[x] … r1[y] … r2[x] … r2[y] … w1[y=-40] … w2[x=-40] … c1 … c2
- T1とT2はそれぞれx + y = 10を守りますが、一緒になると-80を行ないます。
2つの値を含むもう1つの制約違反は、外部キーとそのターゲットの間で起こるものです。リードスキューもそこで大失敗することがあります。例えば、T1はテーブルAから、テーブルBを指す行を読み取るとしましょう。その場合、T2はテーブルBから行を削除し、コミットすることがあるのです。すると、テーブルAは行がテーブルBに存在すると思っていますが、決して読み込みはできないというわけです。
これは、他のトランザクションが実行されている間にデータベースのバックアップを取った場合、致命的になります。制約を守っている状態が矛盾していて復元に適さない可能性があるためです。
合法な使用法
ファジーリードを実行すると、最新のコミットデータにアクセスできます。これは、大量の(または頻繁に繰り返される)集計レポートで、一時的な制約違反の読み取りが許される場合に役立つかもしれません。
ファントムリード
トランザクションが検索条件を満たす行のセットを返すクエリを再実行すると、対象の行のセットが、最近コミットされた別のトランザクションのために変更されてしまっています。
ファジーリードに似ていますが、1つの項目ではなく、予測に一致し、変化するコレクションを伴う点が異なります。

パターン
![r1[P]…w2[y in P]…c2…r1[P]](../wp/wp-content/uploads/2017/10/isolation-diagram-pr.png)
危険性
テーブルがリソースの割り当てを表す行を抱えている時(従業員とその給与など)、1つのトランザクション、「アジャスタ」が別のトランザクションが新しい行を挿入している間に、行ごとのリソースを増加させるような状況はどうでしょう。ファントムリードは新規の行を含めていき、アジャスタが予算を吹き飛ばす原因になります。
関連する事例を挙げましょう。プレディケートが決定する一連のジョブタスクが合計8時間を超えることはできないという制約があるとします。T1はプレディケートを読み込み、合計がたった7時間であると判断し1時間かかるタスクを追加します。その間、並行トランザクションT2も同じことをしているのです。
合法な使用法
ページめくりに伴って新しいアイテムを含めれば、検索結果のぺージ割り付けに有用に使えるかもしれません。ユーザの進行に従って、挿入または削除された項目のうち、どれをどのページに出すかを変えていくことができるからです。
更新データの喪失
T1は1つの項目を読み込みます。T2はそれを更新します。T1は読み込んだ内容次第でそれを更新し、コミットします。T2の更新は失われてしまいました。

パターン
![r1[x]…w2[x]…w1[x]…c1](../wp/wp-content/uploads/2017/10/isolation-diagram-lu.png)
危険性
これのどこが異常なのかと思う人もいるでしょう。データベースの制約に違反することはありません。なぜなら、最終的な結果としては、単にいくつかの作業が実行されなかっただけだからです。また、アプリケーションがやみくもに、しかし連続して同じ値を2回更新する場合にも似ています。
とはいえ、結局のところ異常です。他のトランザクションが更新する機会がゼロで、T2のコミットがロールバックのように振舞うためです。普通の直列実行では、他の誰かが変更を目にすることはあります。少なくとも、確認すれば変更に気づくでしょう。
更新データの喪失は、アプリケーションが実世界で読み取りと書き込みの間でアクションを実行する際にとりわけ悪い影響を及ぼします。
例えば、2人の人が1枚だけ残っているイベントチケットを同時に(並列に)買おうとするとしましょう。「チケット最後の1枚販売中」という情報を読む2つのトランザクションが生じます。別のスレッドのアプリケーションは、印刷用チケットの電子メールを待ち行列に入れ、残りのチケット数をゼロに更新します。両方の更新が起こった後、「残りのチケットはゼロ」は正しい状態です。しかし、顧客の1人は重複したチケットの電子メールを受け取っていることになります。
最後に、更新データの喪失のリスクは、アプリケーション(通常はORMを使用)が、読み込み後に変更された列だけでなく、1行の全列を更新する時に高まることを覚えておきましょう。
公正な使用法
更新データの喪失は、 UPDATE foo SET bar = bar + 1 WHERE id = 123; のような原子的な読み込み、更新のステートメントでは起こりません。バーの読み取りとインクリメントの間に、他のトランザクションが書き込みを差し込むことはできないからです。この副作用は、アプリケーションが項目を読み込み、それに内部的な計算を実行した後、新しい値を書き込む時に発生します。詳しくは後述します。
更新履歴の値が欠落しても、アプリケーションには問題がない場合もあります。おそらく、センサーは複数のスレッドから測定値を迅速に上書きしていますから、合理的に最近の値だけを読めるなら、それでよいのかもしれません。このケースでは、少々不自然ではありますが、更新データの喪失を許容できるでしょう。
ライトスキュー
2つの並列トランザクションのそれぞれが、他方のトランザクションが書き込んでいるものと重複するデータセットを読み取ることによって、何を書き込むかを決定します。
パターン
![r1[x]…r2[y]…w1[y]…w2[x]…(c1 and c2 occur)](../wp/wp-content/uploads/2017/10/isolation-diagram-ws.png)
b = aであれば、更新を1つ失っていることを意味します。
危険性
ライトスキューは非直列のトランザクション履歴を作り出します。だからと言って、トランザクションを次々に実行しても、異常なインタリーブと同じ結果を生成するわけではないことを思い出してください。
これまでに見た中で分かりやすかった例は白黒の行のケースです。PostgreSQL wikiから一字一句コピーします。この場合、 “black” や
“white” などの色の列を伴う行があります。2人のユーザが同時に(並列に)全ての行に一致する色の値を持たせようとしますが、その試みは逆の方向に進みます。1人は白色の行全てを黒に更新しようとし、他方は黒色の行全てを白色の行に更新しようとするのです。
もしこれらの更新が連続して実行されれば、全ての色が一致するでしょう。ただし、データベースの保護手段がない場合、インタリーブされた更新が互いに逆転し、色が混ざってしまいます。
ライトスキューは制約も破ります。x + y ≥ 0の制約があるとしましょう。すると以下のようになります。
- 開始、x = y = 100
- r1[x] … r1[y] … r2[x] … r2[y] … w1[y=-y] … w2[x=-x]
- 結果 x+y = -200
どちらのトランザクションもxとyが100の値を持っていることを読み取るので、個別に、各トランザクションが1つの値を無効にしても、合計はマイナスにならず問題はありません。しかし、両方の値を否定すると、x + y = -200という結果が出て、制約違反になります。分かりやすい例を挙げると、これは銀行口座の枠組みに例えられることが多いようです。つまり、一般の残高の合計が非負のままである限り、口座残高がマイナスになるのは許容されるということです。
読み取り専用の直列化異常
トランザクションは、制御レコードが更新され、バッチが完了したのを確認することがあるかもしれませんが、論理的にバッチの一部である詳細レコードを見ることはありません。制御レコードの以前のリビジョンを読み込んでいるためです。
前述の異常は、並行トランザクションが2つあれば引き起こされましたが、この件の場合には3つのトランザクションが必要です。2004年にこの副作用の発見が関心を集めたのは、書き込みをしない3つのトランザクションのうちたった1つで現れただけでなく、スナップショット分離レベル(後述します)の弱点を明らかにしたからでした。

パターン
トランザクションは競うように次の3つの処理をします。
- T1: 現行バッチのレポートを生成する。
- T2: 現行バッチに新規レシートを加える。
- T3: 新規バッチを “現行” バッチにする。
![r2[b]…w3[b++]…r1[b]…r1[S_b]…w2[s in S_b]](../wp/wp-content/uploads/2017/10/isolation-diagram-ro.png)
危険性
上記の履歴は直列化できません。トランザクションを連続して実行すると、レポートトランザクションが特定のバッチの合計を表示した後、後続のトランザクションがその合計を変更できないという不変性があります。
データベースの一貫性がこの異常で損なわれることはありませんが、レポートの結果は不正になります。
合法な使用法
2004年に至るまで誰もこの副作用に気づかなかったのなら、動物園にも記載されている前述の副作用のような問題は起こるとは思えません。これが本当に役立つような機会はありませんが、同時にそれほど深刻でもないでしょう。
その他には?
以上で起こり得るトランザクション副作用を全て確認できたでしょうか?説明しにくいこともあります。ANSI SQL-92標準は、ダーティリード、ファジーリード、ファントムリードで全てを網羅できたとみなすようになりました。1995年にBerensonらがその他の直列化異常を特定し、前述したように2004年に読み取り専用の異常が記録されてからのことです。
最初の関係データベースは並行処理の管理にロックを使用していました。SQL標準はトランザクション副作用の観点から、ロックではなく、ロックなしをベースとした標準実装を可能にしました。しかし、標準のライターが他の異常を明らかにできなかったのは、彼らが特定した3つが「偽装のロック」だったのが理由でした。
個人的に、まだ公になっていないトランザクション副作用があるのかは分からないものの、疑わしいと思います。今では、直列化自体の特性を検証した論文は数多く存在し、理論的な土台は整ってきているようです。
分離レベル
商用データベースでは、実際に直列化可能性の違反を制御した様々な分離レベルを使って、並列処理の制御ができます。アプリケーションは、より高いパフォーマンスを実現するために、低めのレベルを選択します。パフォーマンスが高いほど、トランザクションの実行速度が向上し、トランザクション応答の平均時間が短縮されます。
前の章で述べた並列処理問題の “動物園ぶり” を理解したなら、アプリケーションにぴったりの分離レベルを判断する知識は十分備えていると言えます。各レベルが様々な副作用を どう 阻むのかはあまり掘り下げず、それぞれが 何 を防ぐのかを見ていきましょう。
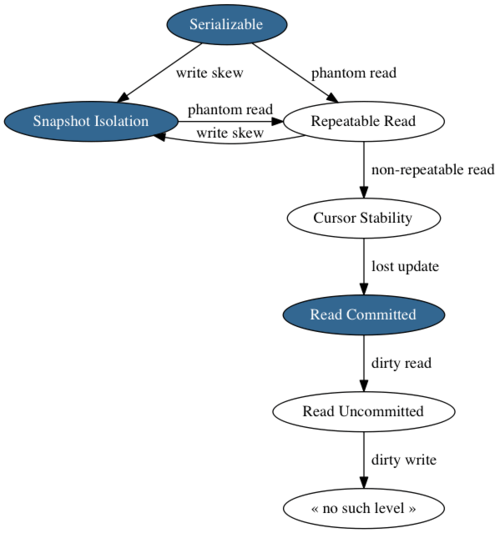
最上位のSERIALIZABLEは、いかなる副作用も起こさせません。矢印の方向に、ラベル付きの異常の保護が解除されていきます。
3つの青色の節に示されているのは、実際にPostgreSQLが提供しているレベルです。分かりにくいのは、SQLの仕様が認識するレベルの数は限られているので、PostgreSQLが仕様の名前をサポートされている実際のレベルに以下のようにマッピングすることです。
| 要求の内容 | 取得できるもの |
|---|---|
| Serializable | Serializable |
| Repeatable Read | スナップショット分離 |
| Read Committed | Read Committed |
| Read Uncommitted | Read Committed |
例:
BEGIN ISOLATION LEVEL REPEATABLE READ;
-- Now we're in snapshot isolationREAD COMMITTEDは初期設定のレベルです。では、予防措置を講じなかった場合、既存のアプリで発生し得る並列処理の問題を考えてみてください。
楽観的 vs. 悲観的
既に述べたように、PostgreSQLの各分離レベルがどのようにして並列性の副作用を防ぐかについては深堀りしません。しかし、一般的に2つのアプローチがあることを理解すべきでしょう。それは楽観的並行性制御と悲観的並行性制御です。重要なのは、それぞれのアプローチに異なるアプリケーションプログラム技術が求められるからです。
悲観的並行性制御は、データベース行をロックすることでトランザクションの読み取りと書き込みの待機を強制します。「悲観的」と呼ばれるのは、陰気なことに「競合は起こる」と仮定し、ロックの取得と解放にいちいち時間をかけるからです。
楽観的並行性制御は、わざわざロックをかけず、各トランザクションをデータベース状態の別個のスナップショットに置き、発生する競合を監視します。もし1つのトランザクションが別のトランザクションに干渉したら、データベースは違反するものを停止し、その作業を消去します。干渉はまれであることが分かっている場合、この方法が効率的でしょう。
遭遇する競合状態の数は、以下のような要因によります。
- 個別の行同士のコンテンション。同じ行の更新を試みるトランザクションの数が増えるにつれ、競合の可能性も高まります。
- ファジーリードを防ぐ分離レベルで読み込まれる行の数。読み込む行が多くなるほど、そのうちのいくつかが並列トランザクションに更新される機会が大きくなります。
- ファントムリードを防ぐ分離レベルが対応するスキャン範囲のサイズ。スキャン範囲が大きいほど、並列トランザクションがファントム行を導く可能性が高まります。
PostgreSQLでは、2つのレベルが楽観的並行性制御を利用しています。Repeatable Readレベル(スナップショット分離)とSerializableレベルです。とはいえ これらのレベルは、危険なアプリに振りかけるだけで問題を解決してしまうような魔法の粉ではありません。 使用にあたり、アプリケーションのロジックを修正する必要があるのです。
楽観的並行性制御を持つ分離レベルを使用してPostgreSQLとやりとりするアプリケーションは、慎重に構築する必要があります。コミットするまでは全てが不確実であり、一瞬の通知だけで全作業が消去されてしまう可能性があることを覚えておいてください。アプリは、エラー40001(別名 serialization_failure )でクエリの停止を検出し、トランザクションを再試行できるように作るべきです。また、そのようなトランザクション中にアプリケーションが不可逆的な現実世界のアクションを実行しないようにしなければなりません。アプリケーションは、悲観的並行性制御なロックでそのような行動を監視するか、成功したコミットの結果を元にアクションを実行する必要があります。
また、直列化の例外をキャッチしてPL/pgSQL関数内で再試行すればいいのでは、と思うかもしれませんが、そこでは再試行はできません。関数全体がトランザクション 内部 で実行され、コミットが呼び出される前に実行の制御は失われます。残念ながら、直列化のエラーが発生するのはほぼコミット時であり、関数がそれをキャッチするには遅過ぎます。
再試行はデータベースクライアントによって行われなければなりません。多くの言語がそのタスクに使えるヘルパーライブラリを提供しています。いくつか挙げてみましょう。
- Haskell: hasql-transaction は自動再試行を行い、反復不可能な副作用を起こさせないモナド内で実行されます。
- Python: psycopg2 再試行の方法
- Ruby: auto-retrying in sequel または、 the transaction_retry gem
トランザクションの再実行は無駄に終わりかねないので、期間を区切った単純なトランザクションが作業の喪失を避けるのに最も効果的であることを覚えておきましょう。
低い分離レベルを補う
一般には、クエリを妨害しかねないあらゆる異常を防ぐような分離レベルの使用が推奨されます。データベースに最大限良い仕事をさせましょう。しかし、置かれている状況において、特定の異常だけが発生すると思われる場合は、悲観的なロックを用いて、低めの隔離レベルを選んでもよいでしょう。
例えば、READ COMMITTEDトランザクションで更新データの喪失を防ぐには、読み取りと更新の間に行をロックします。選択文に “FOR UPDATE” と追加するだけです。
BEGIN;
SELECT *
FROM player
WHERE id = 42
FOR UPDATE;
-- some kind of game logic here
UPDATE player
SET score = 853
WHERE id = 42;
COMMIT;その行を選択して更新しようとする他のトランザクションは、最初のトランザクションが完了するまでブロックされます。この更新トリックの選択は、直列化可能なトランザクションであっても、再試行が求められる直列化エラーを回避するのに便利です。とりわけ、非べき等のアプリケーションのアクションを実行したい場合には有用です。
最後に、低いレベルを選ぶことでリスクを計算できます。スナップショット分離を適用する主な理由は、直列化可能性よりも良いパフォーマンスが得られ、しかも直列化可能性が避けるような並行性の異常の多くを回避するからです。今の状況にライトスキューが期待できないようなら、レベルをスナップショットに下げましょう。
情報源と関連資料
この記事を書くにあたり助言してくれた多くの人たちに感謝します。
- #postgresql Freenode IRCチャネルで: Andrew Gierth (RhodiumToad))と、Vik Fearing (xocolatl)
- 個人的な会話で: Marco Slot、Andres Freund、Samay Sharma、そして Citus Data のDaniel Farina
さらに詳しく知りたい方へ
- Joe Celkoの『SQL for Smarties(賢い人のためのSQL)』 、第2章
- ANSI SQL分離レベルの批評
- 『Transaction Isolation(トランザクション分離)』 (PostgreSQLドキュメンテーション)
- 『A Read-Only Transaction Anomaly Under Snapshot Isolation(スナップショット分離における読み取り専用トランザクション異常)』
- 『Serializable Snapshot Isolation in PostgreSQL
(PostgreSQLの直列化可能なスナップショット分離)』 - 『Data Consistency Checks at the Application Level(アプリケーションレベルにおけるデータの一貫性チェック)』 (PostgreSQLドキュメンテーション)
- 『The Transaction Concept: Virtues and Limitations(トランザクションの概念:その美点と限界)』

株式会社リクルート プロダクト統括本部 プロダクト開発統括室 グループマネジャー 株式会社ニジボックス デベロップメント室 室長 Node.js 日本ユーザーグループ代表
- X: @yosuke_furukawa
- Github: yosuke-furukawa
関連記事