2016年9月2日
『なぜUber EngineeringはPostgresからMySQLに切り替えたのか』について : RavenDB創始者の見地から
本記事は、原著者の許諾のもとに翻訳・掲載しております。
(訳注:2016/9/28、頂きましたフィードバックを元に記事を修正いたしました。)
Uber Engineering グループは、ブログでPostgresからMySQLに切り替えたことについて 非常に素晴らしい報告 (訳注:弊サイトでの和訳は こちら )をしました。ディスク上のフォーマットやパフォーマンスへの影響予測などの詳細まで踏み込んでおり、文字通り、読み応えがあります。
話のネタとしては、Uberからもう1つ素晴らしい記事が出ています。 MySQLからPostgresへの切り替え についてで、こちらも興味深い内容です。
ぜひ、両方読んでみてください。読み終えたら、意見交換しましょう。ブログ内での議論を私たちがこれまで取り組んできたことと比較したいと思います。
一般に、Uberの問題は、複数の広いカテゴリーに入ります。
- セカンダリインデックスの書き込みコスト
- 複製フォーマット
- ページキャッシュ vs バッファプール
- 接続処理
セカンダリインデックス
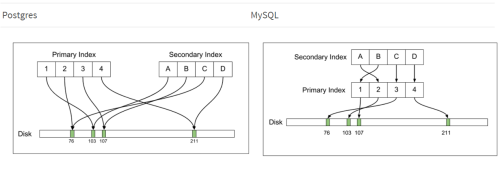
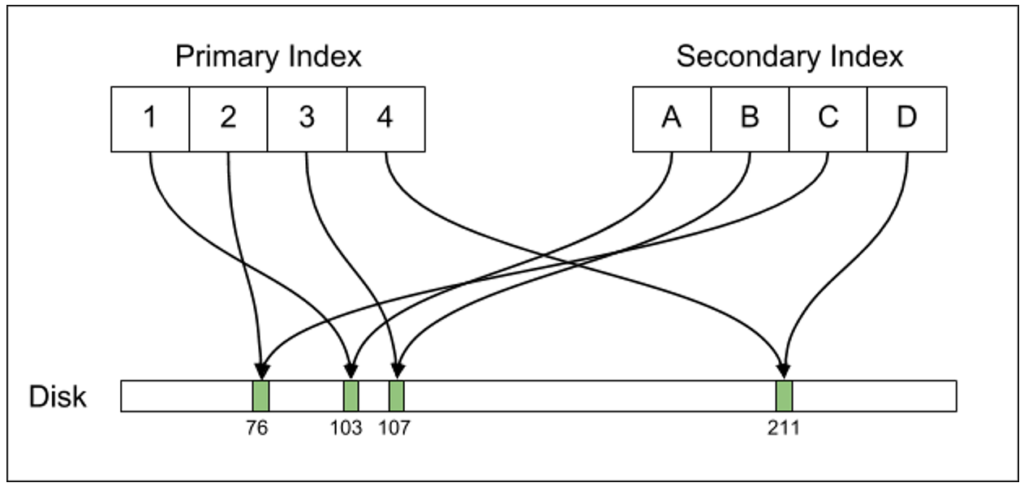
Postgresは、直接ディスク上のデータを指し示すセカンダリインデックスをメンテナンスします。一方、MySQLは、別の間接的なレベルを介したセカンダリインデックスを持っています。下の図を見ていただくと、違いが明確です。
| Postgres | MySQL |
 |
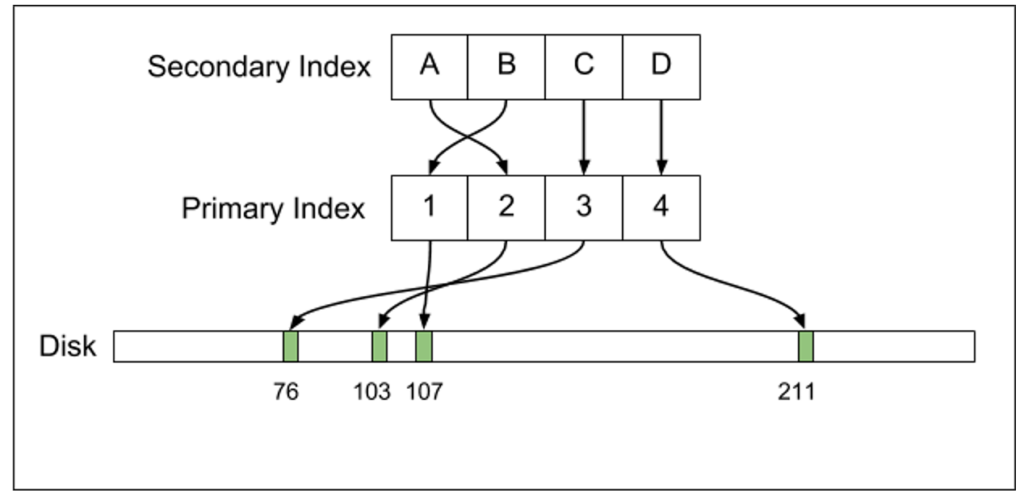 |
この間接的な方法に利点があるのかもしれないと考えたのは、実はこれが初めてです。大抵のシナリオでは、セカンダリインデックスのスキャンはO(N *logN)のコストとなります。すると、パフォーマンスが著しく低下する可能性があります。Voronについて言えば、「セカンダリインデックスにプライマリキーを保持する」というやり方から「ディスク上の位置を保持する」というやり方に移行したのは4.0でした。パフォーマンスにおける利点が非常に大きかったのです。
ということは、Uberが感じている多くの問題は、Postgresが多版型同時実行制御(MVCC)を実装した方法と関係があるのです。新しいレコードを常に書き込んでいるので、全てのインデックスをその度に更新する必要があり、その後さらに、そのレコードの旧バージョンを削除するという作業があります。それに対して、Voronを使うと、(サイズの変更がない限り)レコードを移動させる必要がなく、他のインデックスは、全て変更なしです。その仕組みを書き込みの複製とページ変換テーブルによって実現しているので、同じレコードに対して複数の複製を持ってはいますが、それらは全て論理的に同じ”場所”にあり、見方が変わるだけです。
私の意見では、この形が実装を最もシンプルにする方法で、このお陰で、複数の領域で利益が得られます。
複製フォーマット
Postgresは、回線を通じてログ先行書き込み(WAL)を送りますが(簡略化しています。しかし、説明がより簡単になります)、MySQLはコマンドを送ります。Voronで回線を通じた複製をどのように実装するか選択しなければならなかった時に、私たちはWALも送りました。わかりやすいですし、非常に堅牢ですし、またいずれにせよそういったコードを書く必要があったからです。レプリケーションでもそのコードを使うようにすれば、滅多に起こらないクラッシュリカバリの時だけでなく日常的に走らせられます。
しかし、WALを送ることには問題があります。なぜなら、ディスク上のデータを直接変更するからです。この問題は、データベース全体のダウンを含むデータ破壊など、極めて深刻な事態を引き起こす可能性があります。また、バージョン管理に非常に慎重な対応が求められ、もし不可能ならば、相互に複製する複数のバージョンのサポートを確実にするのが難しいでしょう。さらに、ディスク上のフォーマットの変更は、分散型バージョニングを考えながら、検討する必要があるということも意味します。
致命的なのは、自動的にマスタサーバを置き換えるという状況の処理が、ほぼ不可能だということでした。処理するためには、旧サーバに一切の書き込みを受け入れないようにさせて、新サーバに書き込みの受け入れとWALの送信が可能になったと知らせる必要があります。両方のサーバが重複して書き込みを受け入れてしまう時間があると、WALを全くマージできません。これでは非常に困難なことになります。分散型コンセンサスを利用したWALの実行を試みることもできますが、この方法ではコストが非常に高くなってしまいます(私たちのベンチマークで1秒に約400の書き込みでした。 問題はありませんが 良いとも言えず、長い待ち時間が必要になります)。
このような理由から、並行作業に関しては、より修復機能のある複製フォーマットを使用する方が良いということです。
OSのページキャッシュ vs バッファプール
ブログからの引用:
Postgresでは、カーネルが ページキャッシュ を通して、最近アクセスされたディスクのデータを自動的にキャッシュするようになっています。…このデザインの問題点は、RSSのメモリへのアクセスと比較すると、ページキャッシュを通してのアクセスは少々コストが高いということです。ディスクからデータを検索する際、Postgresのプロセスでは lseek(2) と read(2) のシステムコールでデータを探します。どちらのシステムコールにもコンテキストスイッチの負荷がかかりますが、これによりメインメモリからデータにアクセスするよりも高いコストがかかってしまいます。…比較してみると、InnoDBのストレージエンジンは、 バッファプール と呼ばれる独自のLRUを実装しています。これは理論的にはLinuxのページキャッシュと似ていますが、ユーザ空間に実装されます。Postgresのデザインよりも、かなり複雑な…
PostgresはOSのページキャッシュに依存し、InnoDBは独自のページキャッシュを実装します。しかし問題はOSのキャッシュページに依存していることではなく、 どのように 依存しているのかという点にあります。Postgresはシステムコールで(頻繁に)メモリを読み込むことで依存しています。これではもちろん、コストは高くなるでしょう。
一方でInnoDBは、より少ない情報と非常に複雑なコードでOSと同様の作業をしなければいけません。しかし、それほど多くのシステムコールは必要ないので、速度も速くなります。
そしてVoronは、手間がかかる作業の場合はOSのページキャッシュに依存しますが、一般的にわずかなシステムコールだけです。なぜならVoronのメモリはデータをマップするので、アクセスは通常、ポインタをたどるだけだからです。OSのページキャッシュが関連性のあるデータがメモリ内にあることを確認するので、何も問題ありません。実際にデータをメモリマップしているので、私たちはシステムコールのためにバッファを管理したり、データをコピーしたりする必要はありません。ただ直接、データを供給すればいいのです。つまりこれは、間違いなく最も安上がりなオプションというわけです。
接続処理
接続ごとのプロセスの生成は、CGIの時代以来、目にしていません。この方式はかなりつらい設計だと思いますが、 kill -9 で接続を終了させることができるというのは、恐らく良いことなのでしょう。接続ごとのスレッドもまた、通常なら目にすることはありません。今日の一般的な状況、そしてRavenDBで私たちがすることは、複数の接続を全て同時に管理するスレッドプールの使用です。より良いパフォーマンスのために、同じスレッド上でasync/awaitを使って、複数の接続の実行をインターリーブします。
