2016年10月31日
DRYと不当な抽象化によるコストについて

(2016-09-17)by r31gN_
本記事は、原著者の許諾のもとに翻訳・掲載しております。
本記事は、もう随分と長い間、私がToDoリストに記したままになっていたものです。ですが今日だけは、その考えを実行に移すエネルギーと時間があったようです。私は今、少し前に最初の記事を投稿した時と同じカフェにいます。たまたまなのか、それとも……。店員が私に出した飲み物に何か入れていたに違いありません。
ベストプラクティスにならえ、という古き良きアドバイスがありますよね。そうした情報は常に耳に入ってきます。私たちは、どういうわけかテクニカルな会話の中で DRY とか KISS といった頭字語を第一の原則としてきました。熱心に、まずそうした概念に従っています。たまたま、知識欲があるために、あるいは知識がなかったために、そうした概念から外れたことをする人がいようものなら、確実にその人に嵐のような批判を浴びせます。この原則にとらわれすぎていて、そこに背を向けることを拒んでいるのです。
念のためですが、私は DRY などの原則が悪いと言いたいわけではありません。断じて違います。ただ、 その時の状況の問題 だと思っています。その問題が大きいと。こう考えると、とりわけ DRY については、次の論理的な結論が出せます。実際のところ、私は時として抽象化よりむしろ重複の方を勧めているのです。
そう、言葉の通りです。コードが重複すること(つまり コピー&ペースト )が 良い 場合もあり得ます。はっきり言いましょう、それはコードの繰り返しを抽象化に置き換えると理解しにくくなる時です。
プログラミングに要する時間はどのように配分されるのか
私が自分の仕事について話すと、みんな私のことを1日に10時間以上もキーボードを叩き続けている変人か何かに違いないと思うようです。
まあ、私はそれなりの変人ではあるかもしれませんが、それでも10時間ぶっ続けでコードを書くということはありません。それは確かです。もっと本当のことを言えば、私たちプログラマはコードを書くことよりも、 コードを読むこと にずっと多くの時間を費やしているのです。これまでに皆さんが何らかの形でこの時間を計ったことがあるかどうかは分かりませんが、研究や Robert C. Martin によると、これについてはちょっとした比率が出ているそうです。私の個人的な見解としては、そこには驚くべき差があると認識しています。私たちプログラマは1時間コードを書くごとに、 10時間 コードを読んでいるのです(読むコードは自分が書いたものや他人が書いたもの)。
これは非常に重要です。私たちが仕事をする日にしている努力は、ほとんどがコードを読むことに注がれているのです。もちろん、読むだけではダメです。 理解 しなければなりません。明確で簡潔、かつ読みやすいコードを書くためにベストを尽くさなければならないということなのです。みんなの利益のために。長い目で見れば、自分たちのためでもあります。後で、この考え方に戻って話をしますから、覚えておいてくださいね。
DRYについて
DRYとは何か、なじみのない方もいるでしょう。これは、もともと Don’t Repeat Yourself (繰り返しをするな)の頭文字を取ったものです。プログラミングにおけるこの原則、別の言い方をすればベストプラクティスは、コードベースの繰り返し部分全てをまとめるような抽象化をするように勧めています。
DRY には利点がたくさんあります。例えば、抽象化しておけば、後になって変更する必要性が生じた場合、ある場所だけ、すなわち抽象化した部分だけを変更すればよいということになります。
他のモジュールの機能や他人のAPIなどを扱う時、関心があるのはもっぱらインターフェース(または抽象化)がどのようなものであるかです。基本的な実装については気にしません。従って Facadeパターン のようなソフトウェアデザインのパターンなら、他人が抽象化を使う際の邪魔になることなく、実装における簡単なリファクタリングができるのです。
というわけで、抽象化は良い考えですし、 DRY は完全に理にかなったものです。それでは、私はなぜまだ、いくつかのシナリオではコードを繰り返すのが良いと主張しているのでしょうか?
その理由は、次に続きます。
抽象化のコスト
どの抽象化にもコストが伴います。すぐには明らかにならないコストかもしれませんが、やがて姿を現すのです。
抽象化がなされると、知識のレイヤが追加されます。そもそもの存在理由を自分が必ずしも理解できていないかもしれない知識です(特に、自分が行った抽象化でない場合)。そして新しい情報を取り入れる時は必ず、認識するための負荷が脳にかかります。このため、今度はそのコードを 読む 時間が増えることになるのです。
迷宮へ
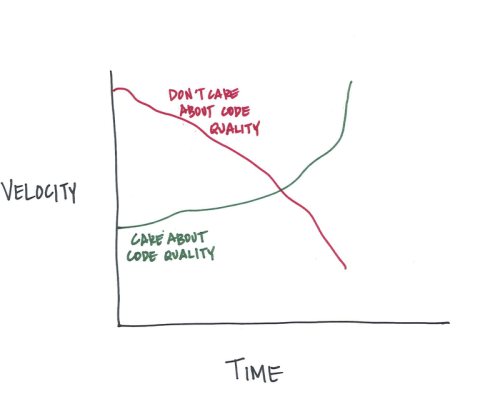
DRY と、この原則を熱心に守ることの問題点は、小規模のプロジェクトでは表面化しません。しかし、中規模や大規模のプロジェクトでは明らかです。
中規模以上のプロジェクトでは、1つの重複につき1つの抽象化だけを行うというのは非常にまれなケースです。なぜなら、プロジェクトが進展して新たな要件が生じるにつれて、古いコードは常に調整されなければならないからです。
自分が新しいプロジェクトに加わって、コードベースを初めて眺めるという状況を想像してみてください。コードベースに何があるか把握してなじんでから、機能の実装や古い機能の変更などに取り掛かります。既存のコードと既存の抽象化に関わっていくようになるのです。自分で書いたものではありませんが、コードベースに存在しているからです。そして多分、存在するもっともな理由があるはずです。
Sandi Metz も、次のように述べています。
既存のコードは強い影響力を持つ。存在自体が、そのコードが正確かつ必要であることを物語っている。
ですので、既存のコードには触りたくありません。
必要性が出てきたばかりの新機能を実装する際、既にある巧みな抽象化は確実に利用できるでしょう。ですが、その抽象化は少々調整が必要であることが分かっています。今回の特定のユースケースは想定されていなかったからです。少し調整を加えるだけでよいでしょうか。それとも、その抽象化の上に、他の反復的なロジックもカプセル化できる新たな抽象化を行うべきでしょうか。それが正解のように思えますよね? それこそ、いずれにせよ DRY の言っていることなのです……。
こうして無我夢中に突き進むと、非常に極端な状況になりがちです。何もかも抽象概念の中でカプセル化されてしまうのです。その抽象化が、今度は独自の抽象化を上位にまとい、さらにその上位へと積み重なっていきます。
上記のようなケースでは、抽象化の価値は既に失われています。プログラマが原則にやみくもに従った結果もたらされたものだからです。よって、それは 不当な抽象化 です。抽象化が可能だったから抽象化されただけなのです。
前述したように、抽象化は、それに関連する認識のコストを伴います。たとえメリットが加わったとしても、そのコストのせいで、コードを理解するための時間は大抵増えるでしょう(プログラマは、コードを書く時間より読む時間の方が長いとお話ししましたね)。しかし、妥当な抽象化よりもっと問題なのは、不当な抽象化です。
不当な抽象化は急所を突いてくるものだ。しかも、あざ笑いながら。
DRYを実践すべきケース、すべきでないケース
では、反復的なコードをカプセル化するケースとしないケースを、どう判断すればよいでしょうか。
その答え自体はシンプルです。ただ現実的にきちんと実践するのは難しいのですが、経験からも納得のいく指針です。
抽象化のコストがコードを重複させるコストを上回らない限り、必ず抽象化する。
つまり、自分の行った抽象化をプロジェクトの新メンバーが理解するのに何時間もかかるようなら、おそらく何かまずい点があるということです。抽象化できるという理由だけで抽象化してはいけません。その特定の箇所に関してコードの重複が再び必要になるか否かを予測し、それに応じて判断しましょう。
時には、コードを繰り返す方が、様々なメソッドに対するネストした呼び出しのツリーをたどってパラメータや副作用を追跡するよりも、ずっと短時間で済むかもしれないのです。
終わりに:自己弁護
この記事が「 DRY なんかくそくらえ!」と声高に主張したものになっていないことを願っています。間違いなく、DRYは非常に優れたプログラミング原則だと思います。しかし、やみくもに守るべき原則ではないということもお伝えしたいのです。学んだことを状況の中で正しく捉え、考えや行動の妥当性を常に問いかけるようにしましょう。それが、より優れたプロフェッショナルになるための唯一まっとうな方法です。
皆さんからのコメントをお待ちしています。笑顔を心掛け、どんなベストプラクティスにも問いかけの姿勢を持ちましょう。
追記:恐ろしい意味のあるサボテンの絵文字「????」のことが忘れられませんでした。

株式会社リクルート プロダクト統括本部 プロダクト開発統括室 グループマネジャー 株式会社ニジボックス デベロップメント室 室長 Node.js 日本ユーザーグループ代表
- X: @yosuke_furukawa
- Github: yosuke-furukawa
関連記事