2016年7月18日
OSを書く:初歩から一歩ずつ

(2016-6-8)by Nicholas Day
本記事は、原著者の許諾のもとに翻訳・掲載しております。
(注:2017/9/27、いただいたフィードバックを元に翻訳を修正いたしました。)

(傑作映画 『おつむて・ん・て・ん・クリニック』 に登場する著書です)
このチュートリアルは、アセンブリで とても 簡単なオペレーティング・システムを皆さんが自分自身で書けるようになるために書きました。元々は、 OSDev wiki でこのチュートリアルのベースとなるものを見つけたのがきっかけです。しかし、そこには何がどのように、どうして行われているのかという説明が一切ありませんでしたので、このチュートリアルを書くことを決めました。ということで、起動プロセスの基礎と、実行するのに必要なツールについて紹介していきます。
OSXやLinux、Windowsなどのよく使われているオペレーティング・システムはドライバを持っており、ハードウェアとの間のインタフェースを提供し、一定レベルの安全性とセキュリティを保証します。さらに、プロセス同士がお互い争わないように調整し、コンピュータを使うためのプログラムに基本的なライブラリを提供しています。しかし、これから私たちが取り組むものはそんなに複雑なことはありません。チュートリアルが終わる頃には、オペレーティング・システムができあがり、スクリーンにメッセージをプリントすることもできていることでしょう。
可能な限りシンプルに説明をしていこうと思いますが、間違いがあったり、記事を修正したほうがいいと思う所があれば遠慮せず、Githubで issueを作成 するか、私までメールしてください。
ソースコードはこちらの Githubリポジトリ でも確認できます。
目次
前提条件
このチュートリアルはDebianベースのLinuxがインストールされていることを前提として書きます。しかし、インストール方法は別として、大部分では他のLinuxディストリビューションとそれほど変わりはありません。もし、お持ちでない場合は、 仮想マシンでUbuntuをインストールする か Michali Sarris氏のコメント を使って、Docker Toolboxを使用することで、話についてくることができるはずです。
必要なのは、 nasm と build-essential と qemu です。
$ sudo apt-get install nasm build-essential qemu-
nasmはアセンブラ。アセンブリコードをバイナリコードに変換し、コンピュータが直接実行できるようにする。 -
build-essentialは、他のプログラムをビルドするのに必要な多くのプログラムとコンパイラをインストールする。makeを使ってオペレーティングシステムをビルドし、実行することをほぼ自動化する。 -
qemuは、コンピュータをエミュレートする、簡単に使える仮想マシン。コンピュータをうっかり壊わすこともなくなり、オペレーティング・システムを開発する時に絶えず再起動する必要がない。qemuが提供する仮想マシンで直接コードをテストすることができる。起動プロセス
コンピュータは電源を初めに入れた時、リアルモードと呼ばれるプロセッサモードで起動をします。このモードは16ビットのコンピュータを使っていた時代の名残で、このモードの状態の時にはプロセッサは16ビットを使うようになっています。1バイトは8ビットで、各ビットの数字は1か0で表現され、2進数でエンコードされます。例えば10010101は1つのバイトです。コンピュータはビットとバイトを使い、命令やデータを処理します。なぜなら、バイナリ形式はオン/オフの切り換えに似ているからです。コンピュータは基本的に非常に高密度の電子回路なので、2進数をプログラムに使用すると、ハードウェアにほぼ直接対応させることができるのです。このモードはあまり多くのRAMにアクセスできません。ビット数が少ないほど、RAMをアクセスするために使えるアドレスの数が少なくなることを意味するからです。現在のほとんどのコンピュータは32ビットか64ビットですが、少なくとも4GBのRAMメモリにアクセスできます。一方で、16ビットのコンピュータは1MB相当のRAMしかアクセスできません。今回は、リアルモードで問題ありません。BIOSの機能を使えるのはこのモードしかありませんし、比較的シンプルなコードを使っていくからです。
コンピュータの電源を入れたら、マザーボード上の専用の不揮発性フラッシュメモリ・チップからBIOS(ベーシック・インプット/アウトプット・システム)をリアルモードでロードします。BIOSは、コンピュータのハードウェアにアクセスや変更をすることが可能である基礎的なライブラリとして機能します。また、BIOSはPOST(パワーオンセルフテスト)を行い、全てのシステムが問題なく実行されているか確認をします。そして、MBR(マスターブートレコード、ブートセクタとも言われる)を検索します。MBRは長さが512バイトで、ハードドライブやフロッピー、DVD、USBドライブなどの起動可能な媒体の先頭位置にあります。これを見つけ出すと、BIOSがリアルモードのMBRでそのコードを実行します。
MBRは内部に多くの機能を備えています。ハードドライブに内の異なるパーティションの位置と情報を保持することができ、また、コンピュータが実行するコードを保持することもできます。MBRは512バイトしかなく、大半のオペレーティング・システムはこの容量に収まらないため(LinuxとWindowsは数百万行のコードを格納しています)、多くのオペレーティング・システムはブートローダを使用し、さまざまなファイルシステムからOSカーネルコードをロードし、実行します。これで、コンピュータのセットアップが終わりました。
しかし、今回作る小さなOSカーネルは512バイトの中に収まるので、ブートローダを使用して、ディスクからさらにコードをロードする必要はありません。
ではこれから、いくつかコードをお見せしていくので、1つずつ丁寧に見ていきましょう。すべてを理解することができなくても心配ありません。今回の記事は、コンピュータがどのように機能しているのかおおざっぱな知識を理解してもらうのが目的です。また、コマンドと情報も示していきますので、ご自身のコンピュータで一緒に試してみてください。
コード
好きなテキストエディタで以下の短いコードを boot.asm として入力してみてください。
; boot.asm
hang:
jmp hang
times 510-($-$$) db 0
; This is a comment
db 0x55
db 0xAAhang:はコード内の単なる名前つきマーカ。jmp hangはマーカhangにジャンプするという意味。- これで無限ループになる。
times 510-($-$$) db 0は残りのバイトを0で埋めるための、nasmの構文。$は、現在の行の先頭という意味。$$は、ファイルやセクションの先頭を指す。($-$$)は、ファイルの先頭から現在の位置を引くという意味。- MBRの残りの512バイトを埋めるのに512という数を使わないのは、2つのdbコマンドが2バイトを最後に格納するから。
;のあとにくるものはコメントで、ソースコードファイルをアセンブルしている時はアセンブラによって無視される。0x55と0xAAはBIOSに「はい、これは実行可能なMBRです」というふうに知らせてくれる“魔法のバイト”。
ご覧のとおり、アセンブリコードは、命令が他のコードにジャンプをする位置以外では、たいていは連続して実行されます。
以下をコマンドラインに入力し、このファイルをアセンブルしバイナリファイルを作り、コンピュータが実際に実行できるようにしてみます。
$ nasm -f bin boot.asm -o boot.bin-f binによりnasmが、linuxで一般的なプログラムで使われるようなelfなどではなく、バイナリフォーマットにアセンブルするようにする。boot.asmは、nasmがアセンブルしようとしているソースコードアセンブリファイル。boot.binは出力ファイル名。
では、このファイルでqemuをスタートさせましょう。
$ qemu-system-x86_64 boot.binqemu-system-x86_64が使われているのは、64ビットのコンピュータを提供しているqemuのバージョンを使用したいから。boot.binはqemuに起動可能な媒体としてboot.binを使えと命令する。
正常に起動したら、以下のような画面がプリントされ、qemuが起動します。
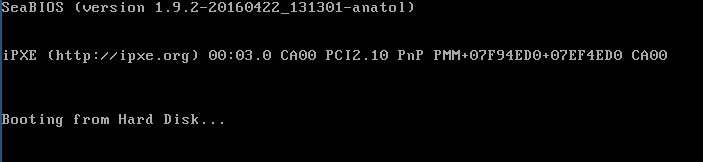
つまり、このプラグラムは、コンピュータを無限ループさせ、ハングさせています。悪くないでしょ?
ビルドプロセスを短縮する
先ほど、オペレーティング・システムを実行させるためだけに、コマンドラインにたくさんのコマンドをタイプしました。この作業を短縮させましょう。
それには make を使います。これは、ほとんどあらゆる種類のコンパイルに対応するビルドツールチェーンをセットアップするためのプログラムです。
まず、 Makefile というファイルを作成し、その中に以下のように入力します。
boot.bin: boot.asm
nasm -f bin boot.asm -o boot.bin
qemu: boot.bin
qemu-system-x86_64 boot.bin
clean:
rm *.binコロンの前の値は、のちに登場するコマンドのリストに使用する名前です。 make clean と make をタイプすると、 rm *.bin が実行され、すべてのアセンブルされたファイルを削除します。
コロンの後の値は、依存関係です。 make qemu とタイプすれば、 make は boot.bin のコマンド( nasm -f bin boot.asm -o boot.bin )を実行したあと、 qemu-system-x86_64 boot.bin を実行します。
スクリーンにプリントする
boot.asm アセンブリファイルを、以下のように変更します。
; boot.asm
mov ax, 0x07c0
mov ds, ax
mov ah, 0x0
mov al, 0x3
int 0x10
mov si, msg
mov ah, 0x0E
print_character_loop:
lodsb
or al, al
jz hang
int 0x10
jmp print_character_loop
msg:
db 'Hello, World!', 13, 10, 0
hang:
jmp hang
times 510-($-$$) db 0
db 0x55
db 0xAAでは、 make clean と make qemu を使って、オペレーティング・システムを削除・アセンブルし、実行します。
一見、難しそうですよね。でも大丈夫。丁寧に一行一行見ていきましょう。
コードを周囲の命令に対応している部分ごとに分けました。では、それぞれの部分と、使われた命令を見ていき、どのようにしてオペレーティング・システムが画面にプリントをしているのか探りましょう。
これらの命令をいくつか見てみると、それぞれである程度の情報を持っていることが分かります。これらをオペランドと呼びます。nasm構文では、右のオペランドはソースオペランドで、左のオペランドはディスティネーションオペランドです。文字のオペランドはCPUのレジスタを指します。CPUのレジスタは、コンピュータがそれに基づいて動作することのできる情報が格納される特別な場所です。
mov は、データをあちこちに動かすことのできる命令です。バイトをレジスタから別のレジスタに、そして、コード内の位置をレジスタへと移動させることができます。
それでは、この知識を使って、コードの最初の部分を解説します。
mov ax, 0x07c0
mov ds, ax最初の行では、 0x07c0 という値をレジスタ ax に移動させました。 0x07c0 は16進値という別の形式で、アセンブリプログラマにとって2進数の 1 と 0 を使うよりも便利なのです。
そして、レジスタ ax からレジスタ ds に値をコピーします。こう思う人もいるかもしれません。「なぜ 0x07c0 を直接レジスタ ds にコピーしないんだ?」と。それは、 ds がとても特殊なレジスタだからです。 ds はデータセグメントのことを表しており、一般的なレジスタから移動してきた値しか持たないのです。その理由はインテルの開発者しか知りません。
セグメントとは?
セグメンテーションは、Intelが同社の16ビットプロセッサを維持するために作った、リアルモードの特殊機能であり、これでユーザがより多くのメモリにアクセスできるようにしました。昔からコンピュータが16ビットの時は、アドレッシング行では16ビットしか使いませんでした。アドレッシング行は、データストレージデバイスをアドレス(2進数で)と一緒に呼び出し、ストレージデバイスの中のアドレスに格納されている特定の値を取得します。コンピュータは2進数を使うので、16ビットのアドレス指定方式が意味するところは、「バイトを格納するのに使えるスロットが2^16個しかない」ということです。つまり、これは64KBのRAMメモリに相当します。賢いIntel開発者はセグメンテーションを実装し、コンピュータが20ビット相当のアドレッシングスペースにアクセスできるようにしていたのです。つまり、2^20個のアドレス、もしくは1MBのメモリに相当します。
しかし、これにはセグメンテーション機能を使用するという手間がかかります。16ビットとの互換性を保つため、プロセッサは セグメント と オフセット を格納する2つのレジスタを使う必要があります。セグメントを保有しているレジスタは、16進値の最後にもう1つ0を追加することで 0x10 倍(10進法で16。普段私たちが数を数えるのに使うのは10進法)されます。 0x10 倍すると、2進値の数の最後に4つの0が追加されます。つまり、16ビットの数字が20ビットになります。そして、次にセグメントにオフセットが加算されて、実際の位置が得られます。ですから、セグメントにオフセットを加えると、アドレスの最後の4ビットのゼロを任意の値に変更することができるので、20ビットのアドレススペースのすべてのアドレスにアクセスできるようになるのです。
1MB、もしくは1024KBを16で割ると考えるとイメージしやすいかもしれません。答えは64KBです。プロセッサのすべてのアドレスにもセグメントを設定することができ、オフセットを使って64KBのブロックのRAMにアクセスできます。このオフセットで64KBのブロックの中のどんなアドレスにもアクセスが可能なのです。
セグメント化されたアドレスは全体として、 segment:offset で参照されます。
私たちのコードに戻って考える
mov ax, 0x07c0
mov ds, axさて、このコードの部分は、セグメントアドレス指定のために、 0x07c0 をレジスタ ds 、つまりデータセグメントにロードします。でも、なぜそうする必要があるのでしょうか? 一部のBIOS機能では、後でアクセスするためにコードの位置を ds レジスタに格納しておく必要があります。コードは必ず 0x07c0:0x0000 の位置にあります。その理由は、BIOSは毎回ここにMBRをロードするからです。
コードの次の部分を見ましょう。
mov ah, 0x0
mov al, 0x3
int 0x10ここで、 int という命令が登場します。これは割り込みを意味し、CPUに割り込みをかけて、割り込みハンドラと呼ばれる、ある種のコードを呼び出します。通常、この割り込みハンドラはレジスタ内のコードを使用して、レジスタ内の文字を取り出して画面にプリントするなどの動作を行います。私たちのコードでは、この割り込みは、BIOSが私たちに代わって初期にセットアップしてくれた機能にすでに割り当てられています。
int 命令は、ただ1つのオペランドをとり、これは割り込み番号を指します。 0x10 はビデオサービスを管理するBIOS割り込みで、ビデオサービスは、 ah に格納されている値に応じて、画面に文字を書いたり、消したり、ビデオのモードとサイズを設定したりする機能です。BIOS機能の動作に影響する番号は普通、合理的な理由なく選ばれているだけなので、ぜひ、自分が使っているBIOS割り込みの情報をオンラインで検索してみてください。
- レジスタ
ah内の0x0は、この命令でビデオのモードとサイズを設定することを示す。 - レジスタ
al内の0x3は、ビデオサイズを80×25文字とすることをint 0x10に伝える。
次の2行で、文字プリントのループをセットアップします。
mov si, msg
mov ah, 0x0E1行目で、プリントしたいメッセージのアドレスへのポインタを si レジスタに入れます。 si を使用する理由は、 loadsb 命令が、セグメント化されたアドレス ds:si を使用して、その位置からバイトをロードするからです。
mov ah, 0x0E は、もう一度 ah レジスタを使用します。レジスタ ah 内に 0x0E を指定することにより、画面に文字をプリントするために 0x10 割り込みを使用することができます。これはテレタイプライターの機能を模倣するので、テレタイプ出力とも呼ばれ、タイプライターに似た動作を行いますが、コンピュータまたはプリンタにテキストを送ることができます。
最後に、実際に画面に文字をプリントする部分を見ましょう。
print_character_loop:
lodsb
or al, al
jz hang
int 0x10
jmp print_character_loop lodsb 命令は、セグメント化されたアドレス ds:si からレジスタ al に1バイトロードして、 si レジスタを次のバイトに進めます。プリントしたいメッセージの文字列が格納されている位置は msg: なので、ここからバイトをロードしたいのです。便利なことに、ASCII標準(American Standard Code for Information Interchange)には、英語の文字と句読点に対応する番号が標準化されたリストがあります。
or al, al は、 al レジスタとそれ自体との or 演算を行います。OR命令は、第1オペランドの各ビットを他方のオペランドの対応するビットと比較します。次に、どちらかのビットが1であれば、宛先オペランドのその位置のビットが1になります。
ここで、 101 と 010 を比較してみると、最初のビットは 1 と 0 です。
- 片方のビットが1なので、最初のビットは宛先オペランドでも1のままになる。
- 次に第2のビットを見ると、
0と1となっていて、ここにも1があるので、宛先オペランドの第2ビットは1に変更される。 - 最後に第3のビットの
1と0を比較すると、ここにも1があるので、第3ビットもまた、1に変更される。
最終的な宛先オペランドは 111 になります。
文字列はNULL文字で終了し、この文字はASCII標準ではバイナリでゼロのバイトです。 0 と 0 を比較するとゼロになるので、 or 命令を使用して、文字列が終わりに来たかチェックします。
or 命令で al レジスタを「変更」した後も、そのレジスタを使用していることにお気づきになったと思います。これが使える理由は、ビット列が、それと or 演算されるビット列と同じであれば、第1のオペランドに格納される結果のビット列もまた、同じだからです。したがって、 al レジスタ内のバイトがゼロならば、 or al,al はゼロフラグを設定するのと同じことになります。
or al, al
jz hangでは、なぜこの2つの命令を一緒に使うのでしょうか?
実は、プロセッサには洗練された動作があります。ある演算の戻り値が 0 なら、プロセッサはゼロフラグをセットします。そして、ゼロフラグがセットされていると、 jz 命令が実行されます。 jz は、「jump if zero」という意味なのです。よって、文字列が終わると、プロセッサはオペランドの位置にジャンプします。これは、文字列内に存在しない文字をさらに探す代わりにプロセッサをハングさせるための hang の位置です。
では、次にループの最後の部分を見ましょう。
int 0x10
jmp print_character_loop最初、レジスタ ah には 0x0E が入っていたことを思い出してください。これは、 al に格納されている文字列を int 0x10 を使ってプリントできることを意味します。
int 0x10で文字列を画面にプリントする。jmp print_character_loopでループの先頭に戻り、文字列が終わりでなければ次の文字をプリントする。
まとめると、ループは次の動作を行います。
- 文字をロードし、アドレスを次の文字に移す。
- 文字がゼロかチェックして、ゼロならプロセッサをハングさせる。
- 文字がゼロでなければ、その文字をプリントする。I
- ループの先頭に戻る。
それでは、最後に残ったコード部分を見ましょう。
msg:
db 'Hello, World!', 13, 10, 0 db は、これらの値を msg: アドレスに格納するよう命じます。カンマは、これらの10進数もバイトとして格納することを意味します。
13は、ASCIIのキャリッジリターン、すなわち\rに変換される。これは、カーソルを行の先頭に移動させる。10は、ASCIIのラインフィード、すなわち\nに変換される。これは、カーソルを次の行に移動させる。0は、そこが文字列の終わりであることをプログラムに知らせる。
(@beernutsからコメントでご指摘いただき、訂正しました。感謝します。)
\n と \r はどちらも、テレタイプライター時代からの遺産で、今でも使われています。
細かく分けて説明してきたので、このオペレーティングシステムは難しく なかった でしょう? OSをプログラムするのは気軽なことではないことはお分かりだと思います(難しい部分にはまだ手を付けていませんから)。最終的にはCやRustなどの高水準言語を使えるようになるかもしれませんが、それは別のチュートリアルでやりましょう。もっと勉強したい人のために、練習問題と推奨文献をいくつか挙げておきます。
練習問題
- 画面に他のものをプリントする。
- 2つの数値を加算する。
- 1から100までの数を合計して解を画面にプリントする。
- あるメモリアドレスの内容をプリントする。
- BIOSを使ってディスクから何かを読み込んでみる。
- BIOSからキー押下情報を取り込む。
推奨文献
このオペレーティングシステムを拡張するために役立つ情報
- Assembly Registers ―プロセッサで使用されるレジスタについて学ぶための便利で簡単なチュートリアルです。
- Guide to x86 Assembly ―このオペレーティングシステムを引き続きアセンブリで書くために不可欠な情報です。
- Bare Bones – OSDev Wiki ―C+かC++を使ってオペレーティングシステムを作り、GRUBなどの既製ブートローダの元でブートする方法が説明されていますが、Bare Bones(骨子)というタイトルが示すように、懇切丁寧なチュートリアルではありません。
- Category:Babystep – OSDev Wiki ―今回のチュートリアル記事は、他の多くのチュートリアルの最初の2ステップをベースにしています。
- Makefiles – Mrbook’s Stuff は、
Makefilesの使い方についての優れた例題チュートリアルです。 - BIOS割り込みルーチン – Wikipedia ―このOSの拡張に使えそうなBIOS割り込みのリストがあります。
他のオペレーティングシステム
* A minimal x86 kernel – Writing an OS in Rust ―優れたチュートリアルで、内容も非常に高質ですが、読者として、ある程度の知識量をもつ人が仮定されていると思います。
* MikeOS – simple x86 assembly langauge operating system ―MikeOSは、アセンブリ言語で書かれた、x86PCのためのオペレーティングシステムです。16ビット、リアルモードの簡単なOSがどのように動作するかを、分かりやすいコメント付きのコードと詳細な文書で学ぶツールです。
詳細なOS理論
* Memory Translation and Segmentation – Gustavo Duarte ―メモリのセグメンテーションについて詳しく説明されています。
* The Kernel Boot Process – Gustavo Duarte ―Linuxカーネルや、他のオペレーティングシステムのカーネルが実際はどのようにブートするのかに興味のある人は読んでみてください。
* How Computers Boot Up – Gustavo Duarte ―コンピュータがどのようにブートするのかに関する詳細な情報があります。
* The Master Boot Record (MBR) and What it Does ―MBRについて、そして、コンピュータがMBRを使って何をするのかについて詳細を学べるチュートリアルです。
* X86 Assembly/Bootloaders ―ブートローダの働きについての優れた理論チュートリアルです。

株式会社リクルート プロダクト統括本部 プロダクト開発統括室 グループマネジャー 株式会社ニジボックス デベロップメント室 室長 Node.js 日本ユーザーグループ代表
- X: @yosuke_furukawa
- Github: yosuke-furukawa
関連記事