2015年3月11日
モノモーフィズム(単相性)について – JavaScriptのパフォーマンスを例に
(2015-01-11)by Vyacheslav Egorov
本記事は、原著者の許諾のもとに翻訳・掲載しております。
JavaScriptのパフォーマンスに関する講演やブログ記事では、よく単相的コードの重要性が強調されています。しかしながら、モノモーフィズム(単相性)/ポリモーフィズム(多相性)とは何なのか、それがどうパフォーマンスに影響してくるのかということについては、あまり分かりやすく説明されていません。私自身の講演でも、<< 1.良い型、2.悪い型 >>的な二者択一のスタイルに要約してしまうことが少なくありません。パフォーマンスに関するアドバイスを求められることがありますが、そういう時に最もよくリクエストされるのは、 モノモーフィズムとは実際のところ何なのか 、ポリモーフィズムがなぜ生じ、それがなぜ悪いのか、ということを説明して欲しいというものです。
困ったことに、そもそも「ポリモーフィズム」という用語そのものが相当に多重定義されています。昔ながらのオブジェクト指向プログラミングにおいては、 ポリモーフィズム と言えば通常 派生型 のこと、つまり基底クラスのふるまいをオーバーライドできるということを意味しています。一方Haskellのプログラマは パラメトリック多相 のことを思い浮かべるでしょう。しかし、JSのパフォーマンスについての講演などで言及される、避けるべきポリモーフィズムはこれらとは別のもので、 コールサイトのポリモーフィズム というものです。
今まで私はこの概念について様々な方法で解説をしてきたのですが、ついにこれをブログ記事にしようと決めました。そうすれば毎回その場で考えなくても、次からはここにリンクを張ればいいですからね。
[今回は新しい解説方法も取り入れてみることにしました。VMのいろいろなパーツ同士のやりとりを短いマンガで表現しています。これは私にとっても新しい試みなので、ぜひフィードバックを送ってください。分かりやすいですか? むしろ分かりづらいですか? それとこの記事では、余談や、本筋から外れたようなあまり重要ではないと思われることについては詳細を省いています。もし知りたかったことが省略されていると感じたら、どうぞ質問を送ってください。]
動的参照の初歩
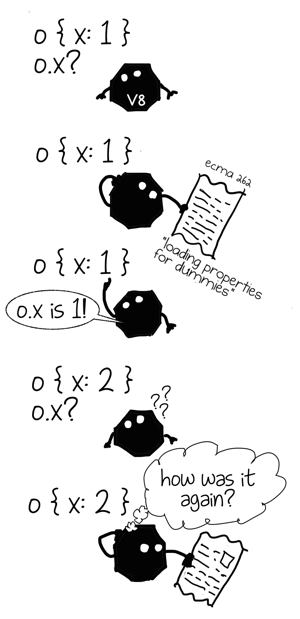
分かりやすいよう、この記事ではJavaScriptの最もシンプルなプロパティアクセスを主に使用します。以下のコードのo.x のようなものです。それと、理解していただきたいのは、これからする話は全ての 動的バインディング の演算に当てはまります。プロパティの参照や算術演算子についてもそうですし、JavaScript以外の話に及ぶこともあります。
function f(o) {
return o.x
}
f({ x: 1 })
f({ x: 2 })想像してみてください。あなたは今Interpreters Ltd.で素晴らしい職に就くために面接を受けています。面接官がJavaScript VMのプロパティ参照を設計し、実装するように言いました。この問いに対する、最もシンプルで正攻法の答えは何でしょうか。
もちろんECMAScriptの言語仕様書(ECMA-262)に書いてあるJSのセマンティクスを採用するのが一番シンプルな方法ですね。つまり [[Get]] のアルゴリズムを逐一、英語からプログラム言語へと書き写せばいいのです。C++、Java、RustやMalbolgeなど、面接時に選んだ言語です。
実際、無作為にJSインタプリタを開いてみれば、下記のような記述を発見することになるでしょう。
jsvalue Get(jsvalue self, jsvalue property_name) {
// 8.12.3 [[Get]] implementation goes here
}
void Interpret(jsbytecodes bc) {
// ...
while (/* has more bytecodes */) {
switch (op) {
// ...
case OP_GETPROP: {
jsvalue property_name = pop();
jsvalue receiver = pop();
push(Get(receiver, property_name));
// TODO(mraleph): throw exception in strict mode per 8.7.1 step 3.
break;
}
// ...
}
}
}これはもちろんプロパティの参照を実装するのに有効な方法ですが、1つ重大な問題があります。もし最新のJS VMのプロパティ参照とこの実装を競わせれば、パフォーマンスが悪すぎるということに気付くでしょう。
このインタプリタは記憶ができないのです。つまりプロパティの参照を行うたび、一般的なプロパティ参照のアルゴリズムを実行する必要があり、前の作業から何も学ぶことなく、毎回、全作業を行う必要があるのです。ですから、パフォーマンスを重視したVMでは、違う方法でプロパティの参照を実装します。
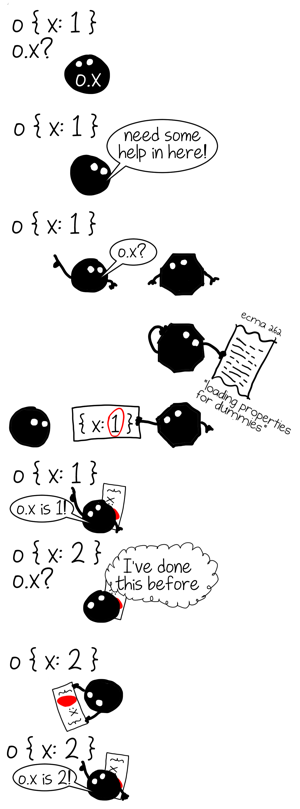
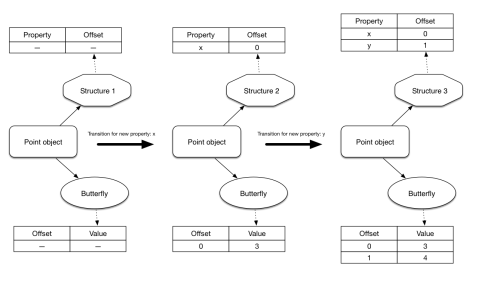
このプログラムのプロパティアクセスが、参照したことのあるオブジェクトから学習し、類似のオブジェクトに対してその知識を応用できるとしたらどうでしょうか。そうすればコストのかかる汎用の参照アルゴリズムを避け、大いに時間が節約できる可能性があります。代わりにある特定の shape のオブジェクトにだけ適用できる、より高速なものを使用するのです。
任意のオブジェクト内で、特定のプロパティがどこにあるのか見つけ出すのにはコストがかかりますよね。ですから、一度参照したらこのプロパティへのパスをキャッシュに記録しておきたいのです。 オブジェクトのshape をキーとして用います。次に同じshapeのオブジェクトを参照する時は、一から計算するのではなく、キャッシュからパスを取り出せばよいのです。
この最適化のテクニックは インライン・キャッシュ(IC) として知られており、以前、私は このことについて記事を書きました 。今回の記事では、具体的な実装の詳細などについては省いて、代わりに前回触れなかった側面について重点的に述べるつもりです。全てのインライン・キャッシュは、 キャッシュ の先頭に位置します。そして、他のキャッシュと同様にサイズ(現在キャッシュされているエントリの数)と キャパシティ (キャッシュできるエントリの最大数)を持ちます。
もう一度例を見てみましょう。
function f(o) {
return o.x
}
f({ x: 1 })
f({ x: 2 })o.xのICで予測されるキャッシュエントリ数の値はいくつでしょう?
{x: 1} と {x: 2}が同じshape(すなわちhidden classまたはmap)なので、答えは1です。このようなキャッシュの状態のことをまさに単相型と呼ぶのです。単一のshapeのオブジェクトだけを参照したからです。
[モノ- (“単”) + -モーフィック (“相”)]

違うshapeのオブジェクトを持つfを呼び出したらどうなるでしょうか。
f({ x: 3 })
// o.x cache is still monomorphic here
f({ x: 3, y: 1 })
// what about now?{x: 3} と {x: 3, y: 1}は違うshapeのオブジェクトですから、キャッシュはもはや単相型ではありません。キャッシュエントリが2つ、つまり1つは{x: *} 、もう1つは{x: *, y: *}というshapeとなっています。この演算は現在、多相的な状態にあり、ポリモーフィズムの度合いは2だと言えます。
もし違うshapeのオブジェクトでfを呼び出し続ければ、ポリモーフィズムの度合いは大きくなり続け、いつかは定義済みしきい値に到達してしまいます。インライン・キャッシュにとっての最大のキャパシティ(例えばV8におけるプロパティのロードは4)です。そしてそうなるとキャッシュは メガモーフィック(megamorphic) な状態に移り変わります。
f({ x: 4, y: 1 }) // polymorphic, degree 2
f({ x: 5, z: 1 }) // polymorphic, degree 3
f({ x: 6, a: 1 }) // polymorphic, degree 4
f({ x: 7, b: 1 }) // megamorphic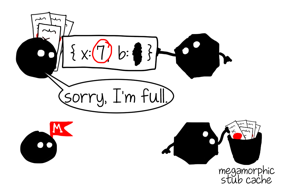
メガモーフィックは多相的なキャッシュが際限無く増え続けることを防止するために存在する状態です。つまり、「shapeがたくさんありすぎるから、もう把握はやめた」という意味です。V8では、メガモーフィックICは引き続きキャッシュすることができますが、ローカルにキャッシュするのではなくグローバルハッシュテーブルにキャッシュします。このハッシュテーブルはサイズが決まっていて、衝突があれば、エントリは単に上書きされます。
さて理解できたかどうか演習してみましょう。
function ff(b, o) {
if (b) {
return o.x
} else {
return o.x
}
}
ff(true, { x: 1 })
ff(false, { x: 2, y: 0 })
ff(true, { x: 1 })
ff(false, { x: 2, y: 0 })- 関数ffの中にはいくつのプロパティアクセスのインライン・キャッシュがあるでしょうか。
2.その状態は何でしょうか。
答え:キャッシュは2つで、両方ともそれぞれ1つのshapeのオブジェクトを参照しているので、両方とも単相型です。
パフォーマンスへの影響
さて、これでいろいろなICの状態によるパフォーマンスの違いについてははっきりしたと思います。
- もしキャッシュへのアクセスが多いなら、単相型が最もパフォーマンスの良いICの状態である( 1.良い型 )。
- 多相型の状態のICは、キャッシュエントリの間を線形探索する。
- メガモーフィック状態のICは、グローバルハッシュテーブルを探索するので、最もパフォーマンスが悪い。でも完全にICに失敗するよりはグローバルキャッシュにアクセスする方がまだマシ。
- ICの失敗は高くつく。通常の演算のコストの他に実行環境を移すコストがかかるから。
しかし、これだけではありません。インライン・キャッシュはあなたのコードを高速にするだけでなく、とても有能な最適化コンパイラの監視役としての役割を果たしています。それが最終的にコードを更に高速化することにつながります。
推測と最適化
以下の2つ問題があって、インライン・キャッシュだけでは最大のパフォーマンスを打ち出すことはできません。
- それぞれのICは近傍のことは全く知らないまま独自に動作する。
- それぞれのICがインプットを処理できなかった場合、最終的には実行時間に跳ね返る。つまり、本質的には一般的な副作用を伴う汎用演算で、よく未知の型が返されることがある。
function g(o) {
return o.x * o.x + o.y * o.y
}
g({x: 0, y: 0})例えば上の関数では、それぞれのIC(.x、.x、 、.y、 .y、 *、+の7つ)は独自に動作します。プロパティによりロードされたICは同じキャッシュのshapeとoを照合します。+の算術ICは入力値が数値かどうかチェックします(V8は内部では異なった数表現をするため、どのような数値かも)。もちろん ICの状態から導かれたものかもしれませんが。
[asm.jsはこの型の継承を使って、非常に制限されたJavaScriptのサブセットを定義します。これは完全に静的型付けで、推測に基づいたコンパイルが必要ないため、事前に最適化することができます。]
JavaScriptにおける算術演算は型を継承します。すなわち、a|0はいつでも32ビットの整数を返し、+aはいつでも数値を返します。しかし他のほとんどの演算にはそんな保証はありません。ですから、JavaScriptで事前に最適化を行うコンパイラを書くというのはかなりの難問となります。多くのJavaScript VMは、前もって一度にコンパイルするのではなく、何度かの実行の段階を経ます。例えば、V8のコードは最適化なしで実行を始め、基本的に最適化なしコンパイラでコンパイルされます。その後、よく使われる関数は最適化コンパイラによってリコンパイルされます。
コードがウォームアップするのを待つのには2つの明確な目的があります。
* 起動の待ち時間を減らしてくれる:最適化コンパイラは、最適化なしのものに比べて時間がかかる。つまり最適化の元を取るためには最適化されたコードが十分に使用される必要がある。
* 型のフィードバック を収集するチャンスがインライン・キャッシュに与えられる。
上で強調したように、人が書いたJavaScriptは通常、十分な継承の型情報を備えていないため、完全な静的型付けや事前コンパイルなどは不可能です。JIT(実行時)コンパイラを使用しなくてはなりません。 経験に基づく推測 によって、最適化するコードの使用法やふるまいを想定し、ある特定の想定の元でのみ有効な特別なコードを生成しなくてはなりません。言い換えると、コンパイラは最適化する関数内の特定の場所で、どの種類のオブジェクトが参照されたか、ということを推測する必要があるのです。ラッキーな偶然ですが、まさにそれがインライン・キャッシュの収集する情報なのです。
* 単相型のキャッシュは「型A だけ 参照した」と言う。
* 度合いがNの多相型のキャッシュは「A1、 …、 AN だけ 参照した」と言う。
* メガモーフィックなキャッシュは「たくさんのものを参照した」と言う。
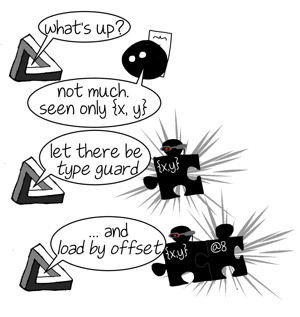
最適化されたコンパイラはインライン・キャッシュによって収集された情報を読み、それに従って中間表現(IR)を構築します。IRの命令は通常、一般的なJSの演算よりも詳細で低水準です。例えば、.xのICが{x, y}というshapeのオブジェクトのみを参照したのであれば、オプティマイザはIRの命令によりオブジェクト内部のフィックスされたオフセットからプロパティをロードし、それを利用して.xをロードします。もちろん任意のオブジェクトに対してそのような命令を応用するのは安全ではありませんから、オプティマイザはその前に型ガードをプリペンドします。型ガードはそれに特化した演算に到達する前にオブジェクトのshapeを照合し、もし期待するshapeと異なる場合は、最適化されたコードの実行は継続 できません 。最適化されていないコードに移動して、そこから実行を続けます。このプロセスは脱最適化(Deoptimization)と呼ばれています。しかし脱最適化をするのは型ガードに違反した場合だけではありません。算術演算は32ビットの整数に特化されている場合があり、もし結果がこの表現からオーバーフローした場合も脱最適化されます。インデックス付きのプロパティロードのarr[idx]がインバウンドアクセスに特化している場合、idxが領域を超えていたり、arrがプロパティidxを持っていない(矛盾点です)場合にも脱最適化されます。
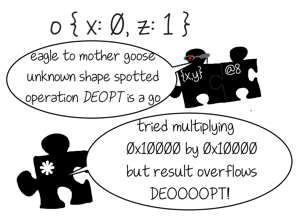
これで、最適化のプロセスにより前述した2つの弱点を解決する努力が為されているということがはっきりしましたね。
| 最適化なし | 最適化あり |
| 汎用で完全なセマンティクスを実装しているため、どの演算も任意で未知の副作用がある。 | コードの特化により、予測不能な事態を制限したり排除したりする。副作用も定義されている(例えばオフセットによるプロパティのロードには副作用がない、など)。 |
| 全ての演算は独自に進められる。個別に学習し、情報を近傍と交換することはない。 | 演算は低水準のIR命令に分解され、一度に最適化される。これにより、冗長性を発見し排除することができる。 |

実際のところ、型のフィードバックに基づいた特別なIRを構築するのは、最適化の道筋の中では最初のステップにすぎません。IRが準備できれば、コンパイラは何度も実行され、不変条件を発見し冗長性を排除しようとします。この時点で実行される解析は大抵手続き内部で行われ、コンパイラはコールに遭遇する度に、最悪の任意の副作用を想定しなくてはなりません。ですから一般的で特化していない演算は本質的にコールそのものなのだということを認識することが大切です。すなわち、+評価がvalueOfを呼び出すと、プロパティアクセスo.x が、ゲッターの呼び出しという結果になってしまうかもしれません。もしオプティマイザが何らかの理由で完全に特化させるのに失敗した場合、その演算は後続の最適化プロセスの障害物になり得るということです。
よくある冗長性のケースは、型のガードが何度も同じshapeに対して同じ値を照合してしまうということです。その時、関数g(上記参照してください)に対する最初のIRはこのようになっていたかもしれません。
CheckMap v0, {x,y} ;; shape check
v1 Load v0, @12 ;; load o.x
CheckMap v0, {x,y}
v2 Load v0, @12 ;; load o.x
i3 Mul v1, v2 ;; o.x * o.x
CheckMap v0, {x,y}
v4 Load v0, @16 ;; load o.y
CheckMap v0, {x,y}
v5 Load v0, @16 ;; load o.y
i6 Mul v4, v5 ;; o.y * o.y
i7 Add i3, i6 ;; o.x * o.x + o.y * o.y このIRは同じshapeに対してv0を4回照合しています。v0のshapeに影響するようなものは照合と照合の間には何もありません。注意深い方なら、v2とv5のロードも冗長だと気付いたかもしれません。対応するプロパティに何も書かれていないからです。幸運なことに、 大域値番号付け のパスが後からIRに適用され、冗長な照合とロードを排除してくれます。
;; After GVN
CheckMap v0, {x,y}
v1 Load v0, @12
i3 Mul v1, v1
v4 Load v0, @16
i6 Mul v4, v4
i7 Add i3, i6 しかし、上で注目したように、冗長な演算の間に障害となる副作用がないからこそ、このような排除が可能なのです。v1とv2の間にコールがあったとしたら、私たちは慎重に想定し次のように考えなくてはなりません。つまり呼ばれる側がv0にアクセスがあり、プロパティを追加、削除、または変更できる可能性があるということです。ですからv2のアクセスやそれをガードするCheckMapを削除することができなくなってしまいます。
さて、最適化コンパイラについて基本的な部分は理解できたと思います。また最適化に適したもの(特化した演算)と適していないもの(呼び出しと汎用演算)もお分かりいただけたと思います。あと一点説明させてください。最適化コンパイラによって非単相型の演算を扱うことについてです。
もし演算が非単相型であれば、最適化コンパイラでは前述したような(型ガード+ 特化した演算)シンプルな特殊化ルールを使うことができません。単純に1つの型の型ガードや、1つの特化した演算を選ぶことができないからです。ICはコンパイラに、この演算では違う型やshapeの値を参照しているから、そのうち1つだけを選んで他を無視すれば、脱最適化のリスクがあるということを告げます。これは避けたい事態です。代わりに、コンパイラ最適化は決定木を構築しようとします。例えば、多相型のプロパティアクセスo.x.がshape A、B、Cを参照する時、このように展開されます(これは疑似コードです。最適化コンパイラは本当はCFG構造を構築します)。
var o_x
if ($GetShape(o) === A) {
o_x = $LoadByOffset(o, offset_A_x)
} else if ($GetShape(o) === B) {
o_x = $LoadByOffset(o, offset_B_x)
} else if ($GetShape(o) === C) {
o_x = $LoadByOffset(o, offset_C_x)
} else {
// o.x saw only A, B, C so we assume
// there can be *nothing* else
$Deoptimize()
}
// Note: at this point we can only say that
// o is either A, B or C. But we lost information
// which one.ここで注目してほしいのは、多相型のアクセスには、単相型のアクセスが持っているような便利なプロパティが無い、ということです。単相型のアクセスを特化した後と、邪魔をする副作用が起こるまで、私たちはそのオブジェクトがある特定のshapeを持っていると保証できます。これにより、単相型のアクセス間での冗長性を排除することができるのです。多相型のアクセスでは”オブジェクトのshapeがA、B、Cのどれかだ”という保証では弱く、この情報を元にして連なった2つの類似した多相型のアクセスの間の冗長性を排除することはできません。(せいぜい最後の比較を削除して、脱最適化を防ぐ程度ですが、V8はこれを行いません)。
しかしV8は、プロパティが 全ての shapeで同じ箇所に配置されていれば、より効率的な中間表現を構築します。この場合、決定木の代わりに多相型の型ガードが発行されることになります。
// Check that o's shape is one of A, B or C - deoptimize otherwise.
$TypeGuard(o, [A, B, C])
// Load property. It's in the same place in A, B and C.
var o_x = $LoadByOffset(o, offset_x)この中間表現は冗長性の除去に対する重要な利点を持っています。2つの$TypeGuard(o, [A, B, C]) の命令の間に邪魔になる副作用がなければ、単相型の場合と同様に2つ目は冗長となるのです。
最適化コンパイラが受けた型情報のフィードバックが、インラインで扱うにはプロパティアクセスの参照したshapeが多すぎるというものだった場合は、オプティマイザは脱最適化の代わりに汎用演算で終わる少し異なった決定木を構築します。
var o_x
if ($GetShape(o) === A) {
o_x = $LoadByOffset(o, offset_A_x)
} else if ($GetShape(o) === B) {
o_x = $LoadByOffset(o, offset_B_x)
} else if ($GetShape(o) === C) {
o_x = $LoadByOffset(o, offset_C_x)
} else {
// We know that o.x is too polymorphic (megamorphic).
// to avoid deoptimizations leave escape hatch to handle
// arbitrary object:
o_x = $LoadPropertyGeneric(o, 'x')
// ^^^^^^^^^^^^^^^^^^^^ arbitrary side effects
}
// Note: at this point nothing is known about
// o's shape and furthermore arbitrary
// side-effects could have happened.最後に、以下のような場合には、最適化コンパイラが完全に演算の特化を諦めてしまう可能性があります。
- 効率的な特化の方法が未知の場合。
- 演算が多相的で、オプティマイザがこの演算の決定木を正しく構築する方法を知らない場合(例えば、以前はV8の多相型のキーアクセスarr[i]がこのケースに該当していた。しかし現在は違う)。
- 演算が特化に際し実行可能な型情報のフィードバックを持たない場合(演算が実行されない、収集した型情報のフィードバックをGCがクリアしたなど)。
このような(おそらくレアな)ケースでは全て、オプティマイザはIRで汎用演算のバリアントを出してきます。
パフォーマンスへの影響
ここまで学んできたことをまとめてみましょう。
- 単相型の演算は特化が最も容易であり、オプティマイザに最も実行可能な情報を与え、さらなる最適化を可能にする。 1. ガッツのある型 である。
- 多相型の型ガードや、最悪の場合は決定木を必要とするような中程度に多相的な演算は、単相型の演算よりも遅い。
*決定木は制御フローを複雑化し、オプティマイザが型を伝播したり冗長性を除去したりするのを困難にする。多相型の演算がタイトなナンバクランチのループのど真ん中にあると、これらの決定木を構成するメモリ依存の条件付きジャンプは難しくなる。 - 多相型の型ガードはあまり型の流れを遮らず、一部の冗長性の除去を許可するが、やはり単相型の型ガード(1つのshapeしか評価しない)と比べるといくらか遅い。単相型の型ガードにおけるパフォーマンスの損失は、CPUがどれだけうまく条件分岐を処理できるかにかかっている。
- 非常に多相的な、つまりメガモーフィックな演算は、完全に特化されず、結果として最適化されたIRの一部として汎用演算が出されることになる。この汎用演算とはコールである。最適化と未処理のCPUパフォーマンスの両方に、全ての付随的な悪い結果を伴う。
このマイクロベンチマーク を見てみてください。ここではプロパティアクセスについて、上記全てのケースにおける違いを取り上げています。単相型と、プロパティのオフセットが一致している多相型(多相型の型ガードが必要なもの)、プロパティのオフセットが異なる多相型(決定木が必要なもの)、そしてメガモーフィックの比較をしています。
ここには書かなかったこと
対象範囲が広くなりすぎることは避けたかったので、このブログにはあえて実装の詳細を書かなかった部分があります。
Shape
この記事には、shape(hidden classとして知られる)がどのように表現され、計算され、オブジェクトにアタッチされるかについては全く書きませんでした。基本的な考え方を確認したいという方は、私の インライン・キャッシュについてのブログ や AWP2014 などの講演を見てください。
ここで認識しておくべきことは、JavaScriptのVMにおけるshapeは、発見的近似であるということです。プログラムの中に隠れた静的構造を動的に近似しようとする試みなのです。人にとっては同じ形でも、VMが必ずしもそれを同じ形と捉えるわけではないかもしれません。
function A() { this.x = 1 }
function B() { this.x = 1 }
var a = new A,
b = new B,
c = { x: 1 },
d = { x: 1, y: 1 }
delete d.y
// a, b, c, d all have DIFFERENT SHAPES for V8JavaScriptのオブジェクトのふわふわしたディクショナリの性質も、 偶発的な ポリモーフィズムを生じやすくしています。
function A() {
this.x = 1;
}
var a = new A(), b = new A(); // same shape
if (something) {
a.y = 2; // shape of a no longer matches b.
}意図的なポリモーフィズム
厳格なクラスから決まった形のオブジェクトのインスタンスしか生成できない言語(Java、C#、Dart、C++など)でプログラミングをしている時でさえも、多相的なコードを書くことは可能です。
interface Base {
void doX();
}
class A implements Base {
void doX() { }
}
class B implements Base {
void doX() { }
}
void handle(Base obj) {
obj.foo();
}
handle(new A());
handle(new B());
// obj.foo() callsite is polymorphic[当然のことながら、JVMはinvokeinterfaceとinvokevirtualの呼び出しの最適化にインライン・キャッシュを用います。]
インターフェース に対してコードを書き、そのコードに異なる実装のオブジェクトを処理させられるというのは、重要な抽象化メカニズムです。静的に書かれたプログラミング言語のポリモーフィズムは、上に書いたのと類似したパフォーマンス含意を持っています。
全てのキャッシュが同じではない
一部のキャッシュはshapeベースではない、及び/または他のものよりキャパシティが低いということを覚えておくとよいかもしれません。例えば、関数の呼び出しに関するキャッシュは、未初期化でも、単相型でも、中程度の多相的状態のないメガモーフィックでもありません。呼び出しに無関係な関数の形をキャッシュするのではなく、 呼び出しの対象 、つまり関数自体をキャッシュするのです。
function inv(cb) {
return cb(0)
}
function F(v) { return v }
function G(v) { return v + 1 }
inv(F)
// inline cache is monomorpic, points to F
inv(G)
// inline cache is megamorphiccb(…) の呼び出しのインライン・キャッシュが単相型の場合、invが最適化されると、最適化コンパイラはこの呼び出しをインライン展開できる可能性があります(これはホットパス上の小さな関数にはとても重要です)。このキャッシュがメガモーフィックの場合は、オプティマイザは何もインライン展開できず(単体の対象がないため、何か分からないのです)、IRに汎用的な呼び出しの演算を残すだけです。
[実際、o.m(…) は2つのICにコンパイルします。1つはLoadICでプロパティのロードを行うものです。もう1つはCallCで、正しいレシーバと引数を伴いロードされたプロパティを呼び出すものです。CallCは上述のcb(…)と同じ類のもので、コールのようなものです。これは単相型をメガモーフィックの状態にしか記録できません。メソッドの呼び出しを最適化する時は状態が無視され、プロパティロードのICの状態のみが使われるのはこのためです。]
これは、プロパティアクセスと似たように扱われる、メソッドを呼び出す式のo.m(…) とは対照的になります。メソッドの呼び出しをする場所のICは、単相型とメガモーフィックの状態の中間の、中程度の多相型の状態を持ちます。V8は単相型、多相型、そしてメガモーフィックの場所でインライン展開が可能で、プロパティの場合と同じ方法でIRを構築します。つまり、関数本体のインライン展開の前に、決定木か、単体の多相型の型ガードかを選択します。しかしこれには1つ制約があります。V8がメソッドの呼び出しをインライン展開するには、 それがshapeの一部 でなくてはなりません。
function inv(o) {
return o.cb(0)
}
var f = {
cb: function F(v) { return v },
};
var g = {
cb: function G(v) { return v + 1 },
};
inv(f)
inv(f)
// here inline cache is monomorpic, have seen only objects with
// a shape like f.
inv(g)
// here inline cache is polymorphic, seen objects with two different
// shapes: like f and like g上記のfとgが異なったshapeを持っているのは意外かもしれませんね。これが起こるのは、私たちが関数をプロパティに割り当てる時、V8が関数を直接オブジェクト上に保存するのではなく、(可能なら)オブジェクトのshapeにアタッチしようとするためです。この例の中では、fは {cb: F} のようなshapeを持っています。つまり、このshape自体が直接クロージャを示しています。前の例では、単に特定のオフセットにおけるプロパティの存在を宣言するshapeしかありませんでしたが、このshapeはプロパティの値をキャプチャすることもできるのです。JavaやC++といった、本質的にクラスがフィールドとメソッドの組み合わせである言語でのクラスと、V8のshapeが似ているのはこのためです。
もちろん、あとから関数のプロパティを他の関数で書き換えたら、V8はそれがクラスとメソッドの関係ではないようだと判断し、これを反映するshapeに切り替えます。
var f = {
cb: function F(v) { return v },
};
// Shape of f is {cb: F}
f.cb = function H(v) { return v - 1 }
// Shape of f is {cb: *}V8がどのようにshape(hidden class)の構築とメンテナンスを行うかという総合的なトピックについては、また別の記事に単独で取り上げたいものです。
パスからプロパティの説明
現時点では、プロパティo.xに関連するICは、Dictionary\<Shape, int>のような、単なるプロパティのオフセットへのディクショナリマッピングのshapeのように思えるかもしれません。この表現では狭すぎて使えないかもしれませんが、プロパティはプロトタイプチェーンの中のオブジェクトの1つに属するか、 アクセサプロパティ (getter及び/またはsetterを持つ)になることができます。ここで興味深いのは、アクセサプロパティはある意味では通常のデータプロパティよりも一般的であるということです。
[Dart VMはこのようにしてフィールドアクセスを実装します。]
例えば、o = {x: 1} は、組み込みVMを使って隠れた内部のスロットにアクセスすることで、getter/setterを持つアクセサプロパティxを含むオブジェクトとして受け取られることが可能です。
// pseudo-code reimagining o = { x: 1 }
var o = {
get x () {
return $LoadByOffset(this, offset_of_x)
},
set x (value) {
$StoreByOffset(this, offset_of_x, value)
}
// both getter and setter are generated internally by VM
// and are invisible to normal JS code.
};
$StoreByOffset(this, offset_of_x, 1)[実際にV8のICは、特別な実行時生成ICスタブを呼び出すパッチ可能なコールサイトです。より明確な説明が欲しい方は このブログ をご覧ください。]
この考察からいくと、ICはもっとディクショナリ<Shape、関数>に類似しているはずだということが分かってきます。実行されるべきアクセサ関数にshapeをマッピングすることにより、ICがヒットされます。このようなICの表現により、極度に単純化された上記の表現(プロトタイプチェーン上のプロパティやアクセサプロパティ、そしてES6プロキシオブジェクト)ではカバーできなかったケースをも最適化することが可能になります。
プレモノモーフィックの状態
実際に、V8の一部のICには、未初期化と単相型の間にプレモノモーフィックと呼ばれる状態があります。これがあるのは、一度しか実行されないICのためにICスタブをコンパイルするのを避けるためです。この状態は少しあいまいな実装の細かい部分なので、ここで踏み込むのはやめておきます。
最後のパフォーマンスに関するアドバイス
パフォーマンスについての1番のアドバイスは、Dale Carnegieの本のタイトル、『How to Stop Worrying and Start Living』(訳注:日本語版があります。デール・カーネギー著/『道は開ける』)の中に隠れています。
実際のところ、ポリモーフィズムを心配するのは、大抵は無駄なことです。代わりに、現実的なデータセットで自分のコードをベンチマークし、プログラムのホットスポットを把握しましょう。もしそのどれかがJS関係だった場合は、 最適化コンパイラが生成したIRを調べてみるのです。
もしタイトなナンバクランチのループの真ん中に XYZGeneric という命令や、赤色の変更[*](“全てを変更する”で知られている)を見つけたら、その時が(その時だけが)心配を始めるべきタイミングなのかもしれません。
おわり

株式会社リクルート プロダクト統括本部 プロダクト開発統括室 グループマネジャー 株式会社ニジボックス デベロップメント室 室長 Node.js 日本ユーザーグループ代表
- X: @yosuke_furukawa
- Github: yosuke-furukawa
関連記事