2016年10月21日
情報理論を視覚的に理解する (4/4)
(2015-10-14)by Christopher Olah
本記事は、原著者の許諾のもとに翻訳・掲載しております。
小数のビット
情報理論の非直感的な点として、小数のビットがあるということが挙げられます。少しおかしな気もしますが、例えば0.5ビットの存在にどんな意味があるのでしょうか。
簡単な答えは次のとおりです。多くの場合、私たちが重視するのは特定のメッセージの長さではなくメッセージの平均的な長さです。送信メッセージの半分が1ビットで残りの半分が2ビットの場合、平均すると1.5ビットになります。こうして見ると、平均値が小数を含むのはおかしなことでも何でもありません。
しかし実際には、その答えは問題の核心を避けています。多くの場合、コードワードの最適な長さは小数ですが、それはどういうことなのでしょうか。
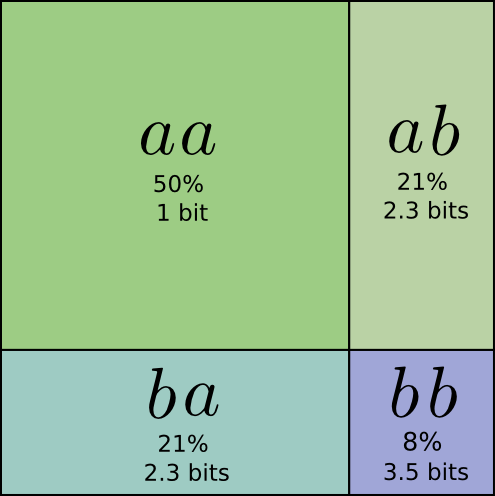
具体的に説明します。あるイベント \(a\) が71%の確率で発生し、 \(b\) が29%の確率で発生するような確率分布を考えてみてください。
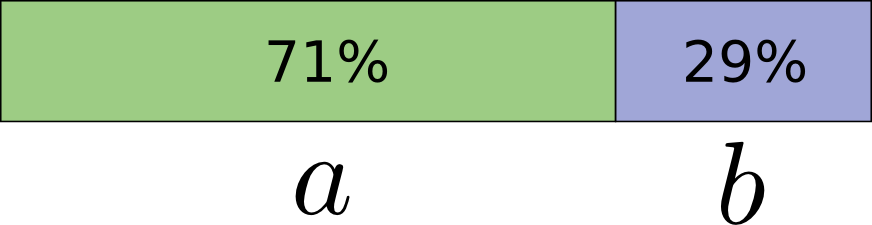
\(a\) を表すのに最適なコードは0.5ビットで、 \(b\) は1.7ビットとなります。これらのコードワードを単一で送信するのは単純に無理な話で、送る場合はビットを整数に丸めて平均1ビットにしなければなりません。
しかし、複数のメッセージを同時に送る場合、もっと効率をよくすることが可能です。この分布から2つのイベントを送ることを考えてみましょう。個々のイベントを別々に送ると2ビットが必要になりますが、もっといい方法はあるでしょうか。
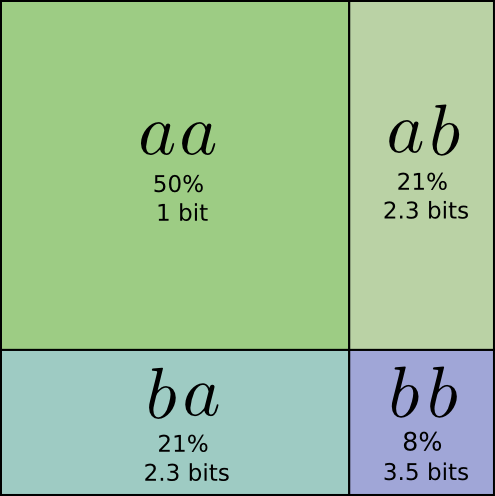
送る頻度は \(aa\) が50%、 \(ab\) と \(ba\) が21%、そして \(bb\) が8%です。ここでも、理想的なコードは大半が小数のビットです。
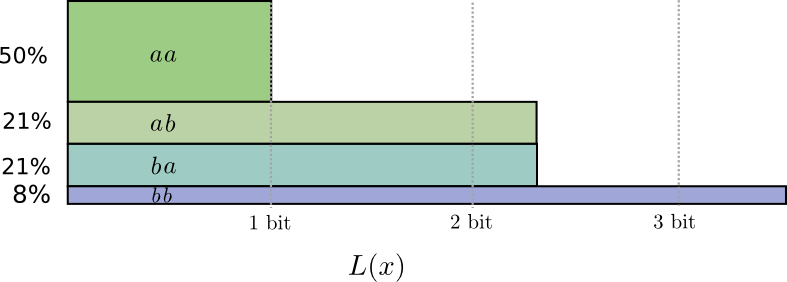
コードワード長を丸めると、次のようになります。
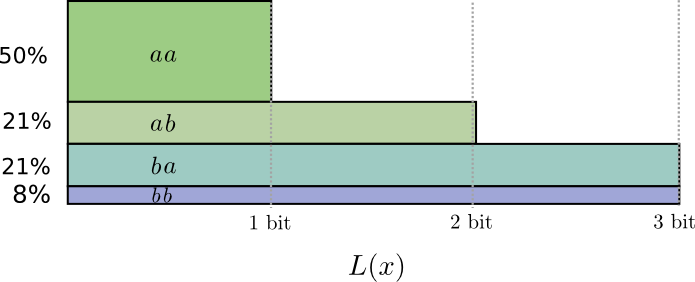
コードの平均メッセージ長は1.8ビットです。個別に送った時の2ビットよりも少ない結果となりました。別の見方で考えると、それぞれのイベントで平均して0.9ビットを送っていることになります。もし同時に送るイベント数が増えれば、ビット数はまだ小さくなるでしょう。 \(n\) が無限大に近づくほど、コードを丸めることに起因するオーバーヘッドはゼロに近づき、コードワード当たりのビット数はエントロピーに近づきます。
さらに、 \(a\) の理想的なコードワード長は0.5ビットで、 \(aa\) の理想的なコードワード長は1ビットでした。理想的なコードワードは小数のビットであっても加算されます。つまり、多くのイベントを同時に送れば、長さは増えるのです。
小数の情報ビットがあるということには、たとえ実際のコードが整数しか扱えないとしても、現実的な意味があることが分かっていただけたでしょうか。
(実際に一般で使われているのは、異なる領域で効果的な特定の符号スキームです。 ハフマン符号 は、基本的にここで述べたのと同じタイプのコードですが、小数ビットの扱いに長けてはおらず、エントロピー限界に近づくためには、上で行ったようにシンボルをグループ化するか、もっと複雑なトリックを使わなくてはなりません。これに対して 算術符号 は小数ビットをうまく扱い、徐々に最適になるようにします。)
まとめ
最小ビットで送りたいと思う場合、上記の考えは基本的なものです。データの圧縮を気に掛けるなら、情報理論はその問題の核心に迫ることができますし、それにより基礎的で正しい抽象化が得られます。しかし、そうでない場合、つまりデータの圧縮を気にするとかでない場合―情報理論とは好奇心以上のものにはならないのでしょうか?
情報理論を元にしたアイデアは、例えば機械学習、量子力学、遺伝学、熱力学、さらにはギャンブルまで、多くの文脈において見ることができます。しかし、これらの分野の人たちは、通常、情報を圧縮したいという理由で情報理論に関心を持つことはありません。彼らが情報理論に関心を持つのは、情報理論が彼らの活動分野に大きな関係を持っているからです。量子もつれは、エントロピーで説明することができます。 ^(1) 統計力学と熱力学の多くの結果は、未知のことについて最大エントロピーを仮定することによって導き出すことが可能です。 ^(2) ギャンブラーの勝敗はカルバック・ライブラー情報量、特に反復的な想定でのケースに直接的な関係があります。 ^(3)
こうした多くの分野で活用されている理由は、私たちが表現したいと思う多くの事物に対して、情報理論が具体的で原理的な形式を提供しているからです。情報理論によって、私たちは「不確定性」「2つの信念がどのように異なっているか」「ある問いに対する一つの答えにより、別の問いについて何がわかるか」などを測定・表現する方法を得ることができるのです。これらはつまり、確率の散漫さや確率分布間の距離、2つの変数の依存度などです。こうしたことを実現できる方法が他にあるでしょうか。もちろんあることはあるでしょう。しかし情報理論の考え方は明快で、その性質は良好であり原則に基づいた起源を有しています。そして、そこから導き出されるものは、ある場合には私たちがまさに関心を持っていたことであり、別の場合には、この乱雑な世界の中での有効な代理の尺度なのです。
私の一番得意な分野は機械学習なので、それに関連して少しお話します。機械学習における一般的なタスクは分類です。例えば写真を見て犬か猫を予測するとしましょう。この予測において、私たちのモデルが「画像は80%の割合で犬、20%の割合で猫」と答えたとします。正しいのは犬だったとして、80%の確率とはどの程度、いい答えだったのでしょうか。また、85%と答えていた場合、それは80%の時に比べどの程度、優れていたのでしょうか。
この問題は非常に重要です。なぜならモデルを最適化するためには、その善し悪しを示す見解が必要だからです。では、一体何を最適化すべきなのでしょうか。正しい答えは、そのモデルが使われる状況(最多の推測が正しければいいのか、正確な答えの確率が重要なのか、明確な間違いがどれほど好ましくないのか)に大きく依存するため1つではありません。あるいはほとんどの場合、正しい答えさえ知ることはできないでしょう。というのも対象の関心事を形式化するために、そのモデルがどのくらい適切な形で使われるかを私たちは知ることができないからです。その結果、交差エントロピーこそが一番の関心事になるような状況が生じてきますが、必ずしもそういった状況だけとは限りません。もっと言えば、何が関心事であるかを確実に対象化できないことも多々あり、そういった場合にも交差エントロピーは代理の尺度になります。 ^(4)
情報は、私たちが世界を考えるための新しい強力なフレームワークを提供してくれます。それが時には直面した問題を完全に解決することもあるし、完全ではないにしろ、有効に機能する時もあるでしょう。この記事では、情報理論の表面を軽くなぞっただけで、主要なテーマである誤り訂正符号などについては触れていませんが、情報理論というものが、特に身構える必要のない素晴らしい題材であることが分かっていただければ幸いです。
今後、記事を書く時の参考にさせていただきたいので、ぜひ フィードバックのフォーム に記入してください。
参考文献
Claude Shannonが書いた情報理論についての最初の論文、「 A Mathematical Theory of Communication(通信の数学的理論) 」は非常に分かりやすいです(これは初期の情報理論の論文における反復パターンのようです。時代なのかページ数の不足なのか、それともベル研究所の文化なのかは分かりません)。
Cover & Thomasの「Elements of Information Theory(情報理論要素)」は標準的な参考文献で、私には非常に参考になりました。
謝辞
この記事に対して多くの時間を割いて信じられないほど詳細かつ広範なコメントを提供してくれた Dan Mané 、 David Andersen 、 Emma Pierson 、Dario Amodeiに感謝の意を表します。同じく Michael Nielsen 、 Greg Corrado 、 Yoshua Bengio 、 Aaron Courville 、 Nick Beckstead 、 Jon Shlens 、Andrew Dai、 Christian Howard 、 Martin Wattenberg のコメントにも感謝します。
この記事のアイデアは、私が最初に担当したニューラルネットワークの2つのセミナーシリーズが試験台として機能することでより強固なものとなりました。
最後に誤字脱字を指摘してくださった読者の皆さん、特にConnor Zwick、Kai Arulkumaran、Jonathan Heusser、Otavio Good、そして匿名でコメントをくれた方に感謝します。
他の記事
注釈:
Understanding Convolutions(畳み込みを理解する)
Groups & Group Convolutions(グループとグループの畳み込み)
Neural Networks, Manifolds, and Topology(ニューラルネットワーク、マニホールド、およびトポロジー)
Visualizing Representations(表現の可視化)
Deep Learning and Human Beings(深いレベルの学習と人間)
-
量子情報理論という総合的な領域があります。私自身はその主題について正確には知りませんが、Michaelの別の仕事を考慮すると、Michael NielsenとIssac Chuangの共著、「 Quantum Computation and Quantum Information(量子計算と量子情報) 」は優れた手引きになると思います。 ↩
-
統計物理学についての知識はありませんが、情報理論との関連を私が理解する限りで説明してみます。
Shannonによる情報理論の発見後、多くの研究者たちが熱力学における方程式と情報理論における方程式との間に不確定の類似点があるということを指摘しました。そしてE.T. Jaynesが非常に密接で原則的な関連があることを見つけます。例えばあるシステムがあり、圧力や温度などの測定を行うと仮定してみてください。システムの特定の状態はどのくらいの確率で存在すると思いますか。Jaynesは、測定には制約があることを受け、エントロピーを最大化する確率分布を仮定すべきと提案しています(ちなみに、この”最大エントロピーの原則”は物理学よりもはるかに一般的です)。つまり、最も未知の情報で確率を仮定すべきということです。多くの結果は、この観点から導き出すことができます。
Jaynesの論文の最初の数章( part 1 、 part 2 )を読みましたが、私はそのとっつきやすさに感銘を受けました。
こうした関連性に興味はあるもののオリジナルの論文を通読するのは少し気が引けるという方には、Cover & Thomasの論文にマルコフ連鎖から熱力学第2法則の統計的なバージョンを導き出す章があるので、そちらを参照ください。 ↩ -
情報理論とギャンブルとの間の関連性は、元はJohn Kellyの論文「 A New Interpretation of Information Rate(情報率の新しい解釈) 」で提示されたものです。この記事で紹介していない概念がいくつかありますが、それでも非常に分かりやすいと思います。
Kellyには、彼の仕事において興味深い動機がありました。情報の符号化に関係がない多くのコスト関数でエントロピーが使用されているのに気付いた彼は、その原則的な理由を求めたのです。この記事を書くにあたって、私は同様の問題に悩まされましたが、新たな見地を与えてくれたKellyには本当に感謝しています。とは言うものの、私はその内容に完全に納得したわけではありません。Kellyが結果的にエントロピーにたどり着いたのは、彼がそれぞれの賭けに資金を再投資する賭けの反復を考えたためです。別の状況設定であれば、エントロピーにはたどり着けなかったでしょう。
Kellyによる賭けと情報理論の関連性についての素晴らしい考察は、情報理論の標準的な参考文献であるCover & Thomasの「Elements of Information Theory(情報理論要素)」で見ることができます。 ↩ -
問題の解決にはなりませんが、カルバック・ライブラー情報量に関して少し補足させてください。
Cover & ThomasにおいてStein’s Lemma(シュタインの補題)と呼ばれる結果があります(ただし一般的にStein’s Lemmaと呼ばれる結果には無関係に見えます)。高次のレベルで見ると次のような具合です。
2つの確率分布のうちの1つに起因するあるデータがあると仮定します。そのデータが2つの分布のうちのどちらから来たのか、どの程度の自信を持って断定することができるでしょうか。一般的には多くのデータポイントを取得するほど、自信は指数関数的に増加するはずです。例えば、目の前のデータポイントがどの分布のものかについての自信は、平均して1.5倍になるかもしれません。
どれくらい自信が倍増するかは、分布の違いの度合いによります。2つの分布が大きく異なっていれば、すぐにでも自信が持てるでしょう。対してわずかな違いしかない場合、答えに対して少しの自信を持てるようになるまでにも、多くのデータを見る必要がある場合もあります。
Stein’s Lemmaが大まかに述べるところによると、倍増の度合いはカルバック・ライブラー情報量によって制御されているということです(偽陽性と偽陰性との間のトレードオフについては少し微妙です)。これがカルバック・ライブラー情報量を軽視できない理由になると思います。 ↩

株式会社リクルート プロダクト統括本部 プロダクト開発統括室 グループマネジャー 株式会社ニジボックス デベロップメント室 室長 Node.js 日本ユーザーグループ代表
- X: @yosuke_furukawa
- Github: yosuke-furukawa
