2017年5月15日
私が書いた最速のハッシュテーブル – PART 4
(2017-02-26)by Malte Skarupke
本記事は、原著者の許諾のもとに翻訳・掲載しております。
要素の削除についても測定してみましょう。ここでも、キーを整数にして3つのテストを、キーを文字列にして3つのテストを行いました。使ったのは4バイト値、32バイト値、1024バイト値です。4バイト値の図は前掲のとおりです。32バイト値の図はほとんど同じなので省略します。1024バイト値の図は以下のようになります。
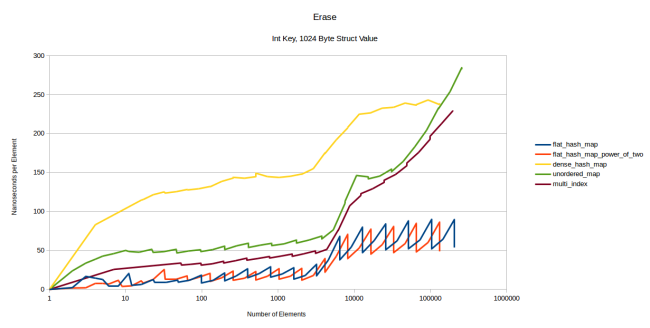
注釈:
削除
整数キー、1024バイト構造体値
(縦軸)ナノ秒/要素
(横軸)要素の数
大きく違う点は、dense_hash_mapがかなり遅くなったことです。これは、大きな値タイプでテストした他の図の時と同じ問題です。他のテーブルは、単純に要素が削除されたと見なし、デストラクタ(私の構造体ではno-op)を呼び出します。一方、dense_hash_mapは”空の”キーと値のペアでその値を上書きしますが、1024バイトのデータを持っている場合にはそれが大きな操作となるのです。
他に上の図から分かる大きな違いは、flat_hash_mapからの削除が他のテーブルの場合よりもはるかにギザギザの激しいグラフになっており、線がかなり上昇してノードベースコンテナの場合とほぼ同じくらいコストが高くなっているということです。この理由は、flat_hash_mapはある要素が削除される際に各要素を移動する必要があり、各要素が1028バイトのデータの時にコストが高くなっているからだと思います。
文字列削除のグラフは、お見せする必要がほとんどないくらい整数削除のグラフと似ていますが、以下のとおりです。
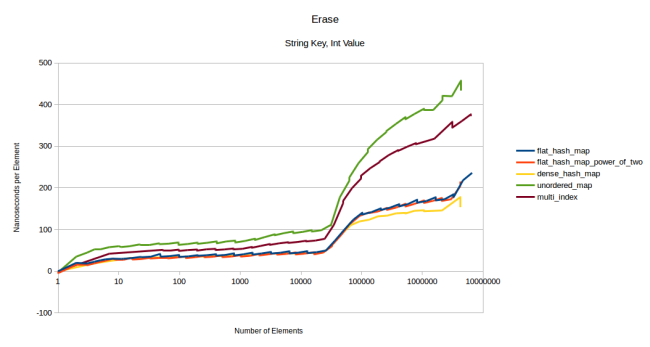
注釈:
削除
文字列キー、整数値
(縦軸)ナノ秒/要素
(横軸)要素の数
整数削除の場合と非常に似ています。値のサイズを1024バイトにした場合は、このグラフの前のグラフとそっくりになりますので、そちらを再度ご覧ください。
最後のテストは「挿入、削除、再び挿入」です。前に、挿入と削除をランダムな順序で行ったテストです。1028バイトの要素1000万個で実行してみたらメモリが使い果たされてしまったため、要素数は1万個に減らしました。また、要素数が少ない時の方がグラフの作成時間ははるかに短くなります。32バイトの値タイプから見てみましょう。
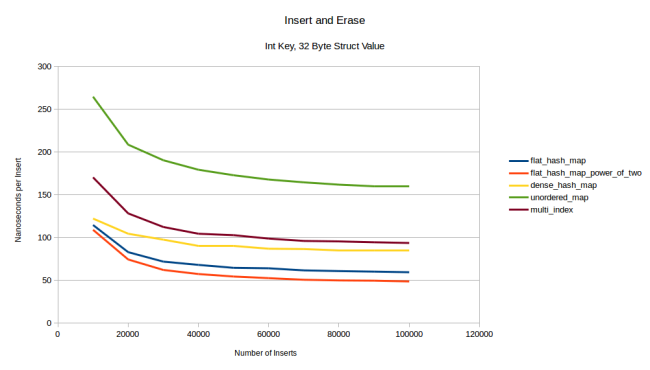
注釈:
挿入、削除
整数キー、32バイト構造体値
(縦軸)ナノ秒/挿入
(横軸)挿入の数
今回はflat_hash_mapがdense_hash_mapにまさっています。値のサイズを更に大きくすると、この差は広がります。
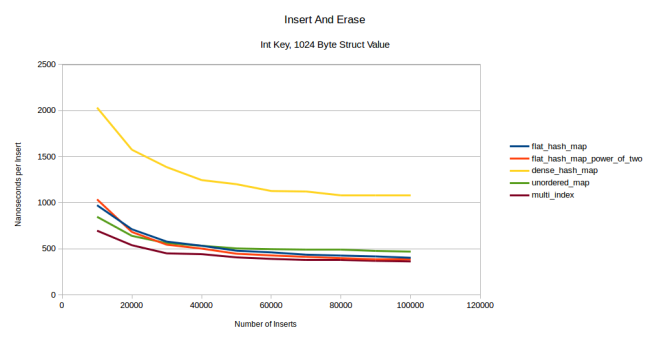
注釈:
挿入、削除
整数キー、1024バイト構造体値
(縦軸)ナノ秒/挿入
(横軸)挿入の数
非常に大きな値タイプでは、私のテーブルがdense_hash_mapにまさっています。一方、今回は初めのうちはノードベースコンテナが私のハッシュテーブルを上回っていますが、次第に私のテーブルが追い付いているようです。その理由は、今回のテストではreserveを呼び出していないからです。よって、最初の挿入時にテーブルは再割り当てを何度も行う必要があるのでフラットコンテナではコストが非常に高くなり、ノードベースコンテナではコストが比較的低くなっているのです。しかし、数個の要素を削除、挿入するにつれて再割り当てのコストは償却され、私のテーブルがunordered_mapを上回っています。ある地点になればmulti_indexにもまさるでしょう。事前にreserveした場合は直ちにmulti_indexを上回っています。

注釈:
reserve、挿入、削除
整数キー、1024バイト構造体値
(縦軸)ナノ秒/挿入
(横軸)挿入の数
これは予想外でした。というのも、事前にreserveしたとしても、私のコンテナはやはり要素を移動する必要があり、それは1028バイトのデータでは非常にコストが高くなるはずだからです。私のコンテナが依然速い理由として唯一考えられるのは、占有率がかなり低く、衝突がめったに発生しないことです。このテストを文字列で測定すると、私のコンテナは予想どおり遅くなり、multi_indexが肩を並べてきます。
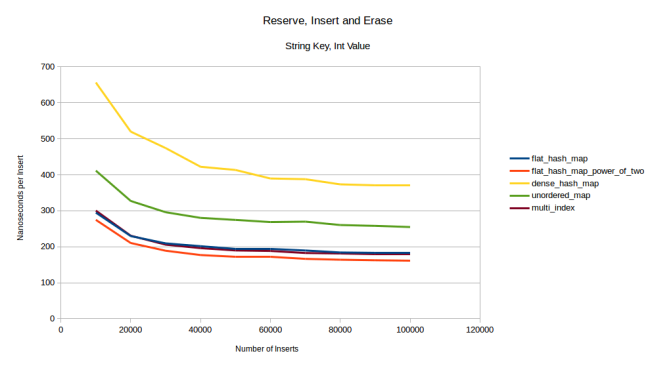
注釈:
reserve、挿入、削除
文字列キー、整数値
(縦軸)ナノ秒/挿入
(横軸)挿入の数
文字列挿入の他のグラフは上掲のものと似た感じになります。32バイトの値タイプの挿入では、この最後のグラフのようになります。1024バイトの値タイプの挿入では、reserveを呼び出した場合と呼び出さなかった場合のいずれも、同じことを整数をキーとして実行した際のグラフのようになります。
パフォーマンスのまとめ
かなり多数の測定を行いました。ハッシュテーブルを測定することは驚くほど複雑です。同一の占有率やデフォルトの設定で全てのテーブルを測定すべきかはまだ十分確信があるわけではありません。今回はデフォルト設定で測定しています。その上、様々なキー、様々な値サイズ、様々なテーブルサイズ、reserve呼び出しの有無など、実に多様なケースが存在します。そして行うべきテストがたくさんあるのです。このブログ記事に何千ものグラフを掲載することもできたのですが、ある程度以上はやり過ぎになるため、まとめに入ります。
- 今回私が書いたテーブルは、私の知るテーブルの中で最もルックアップが速い。
- また、挿入と削除も非常に速い。特に、正しいサイズを事前にreserveした場合。
- 大きな値タイプでは、事前に要素数を把握していない場合はノードベースコンテナの方が速いこともある。フラットコンテナでは再割り当てのコストが負担になる。再割り当てがなければ、私のフラットコンテナは大きな値タイプでのベンチマーク全体で最速となる。
- 文字列挿入では、文字列ハッシュ、比較、そしてコピーのコストが大勢を占め、どのハッシュテーブルを選ぶかはあまり影響しない。
- google::dense_hash_mapは、いくつか意外なケースで速度が落ちる。
- boost::multi_indexは実に際立ったハッシュテーブルである。ノードベースコンテナとしては非常にパフォーマンスが優れている。
- ハッシュ関数の返す値がうまく分散されると分かっている場合、私のハッシュテーブルのpower_of_twoバージョンを使えば大幅な高速化が可能となる。
例外安全性
私のテーブルを使う場合は、コンストラクタ、コピーコンストラクタ、ハッシュ関数、等値関数、そしてアロケータで例外を投げるようにした方が安全です。ムーブコンストラクタやデストラクタで例外を投げることは許可されていません。その理由は、私としては要素を移動して不変部分を維持する必要があったからです。ムーブコンストラクタで例外を投げる方法は、私は把握していません。
ソースコードと使用法
ソースコードはGitHubにアップロードしてありますので、 こちら からダウンロードできます。Boost Software Licenseの下で利用頂くことができます。ソースコードは単一のヘッダファイルで、ska::flat_hash_mapとska::flat_hash_setの両方を含んでいます。インターフェースはstd::unordered_mapとstd::unordered_setのものと同一です。
power_of_twoバージョンのテーブルを使いたい場合は、1つ厄介な作業があります。その方法については本記事の前の方で説明していますので、参照するには「ska::power_of_two_hash_policy」で検索してください。
私の実行環境におけるmax_load_factorのデフォルト値は0.5であるということも備考として書いておきます。この値は0.9まで上げても安全です。ただし、テーブルはおそらくその数値に達する前に再割り当てを行うということに留意してください。テーブルは、探索回数の上限に達するので70%使用済みになる前に再割り当てを行う傾向があります。しかし、そのことを考慮しておかないと予期せぬ時にテーブルが再割り当てを行うかもしれませんから、max_load_factorの値を上げておけば、パフォーマンスをほとんど損なわずにメモリを少し節約できるのです。
まとめ
今回、実際に最速のハッシュテーブルを書くことができたように思います。ルックアップの速さは明らかに一番ですし、挿入と削除についても非常に高速です。新たに取り入れた最大の秘訣は、探索回数に上限を設定することです。探索回数をlog2(n)に制限すると、最悪のケースでのルックアップ時間がO(n)ではなくO(log(n))になります。これで実際に違いが出てきます。探索回数制限はロビンフッドハッシュ法では大いに効果があり、内部ループでの巧みな最適化が可能になるのです。
このハッシュテーブルは、hash_mapとhash_setの両バージョンとして、Boost Software Licenseの下での利用が可能です。ご活用ください。

株式会社リクルート プロダクト統括本部 プロダクト開発統括室 グループマネジャー 株式会社ニジボックス デベロップメント室 室長 Node.js 日本ユーザーグループ代表
- X: @yosuke_furukawa
- Github: yosuke-furukawa
関連記事