2017年4月28日
私が書いた最速のハッシュテーブル – PART 3
(2014-09-14)by Malte Skarupke
本記事は、原著者の許諾のもとに翻訳・掲載しております。
テーブルを、異なるmax_load_factor()と比較する
先に示した最後のグラフは、私のテーブルとgoogle::dense_hash_mapがmax_load_factorに0.5を使う一方で、std::unordered_mapとboost::multi_indexが1.0を使って動作検証を行っていました。もしかすると他のテーブルも、低いmax_load_factorの値を使えば、より速くなるのではないでしょうか? それを確かめるため、最初のグラフ(成功したルックアップ)に使ったのと同じベンチマークを実行しました。ただし、どのテーブルもmax_load_factorは0.5に設定しました。そして、テーブルの再割り当ての直前に測定を行いました。もう少し詳しく説明しますが、まずは次のグラフをご覧ください。
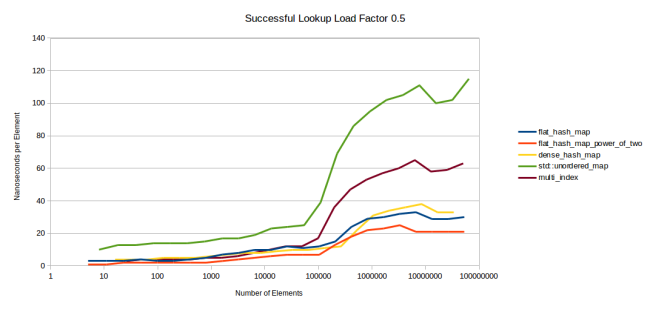
注釈:
成功したルックアップの占有率(load factor) 0.5
(縦軸)ナノ秒/要素
(横軸)要素の数
これは、全てのテーブルでmax_load_factorを0.5にしていること以外は、この記事の最初のグラフと同じものです。この後、これらのテーブルが全く同じファクタを実際に持っている時に測定したいと思いました。そうすれば、内部のストレージを再割り当てする前に各テーブルを測定できるからです。では、この記事の最初のグラフをもう一度見て、1つの頂点から次の頂点に線を引くと想像してみてください。もしハッシュテーブルのパフォーマンスを直接比べたいなら、そして異なるmax_load_factorの値や、再割り当ての際に異なる戦略を使った異なるハッシュテーブルの要素を排除したいのなら、これは適切なグラフです。
このグラフでは、flat_hash_mapはdense_hash_mapよりも速いことが分かります。最初のグラフと同じです。しかし、ノイズが全て消されたお陰で、より明確になっています。ところで、dense_hash_mapの方が速くなるわずかな時間は、dense_hash_mapがより少ないメモリを使っていることの結果です。その点では、dense_hash_mapは未だに私のL3キャッシュの中に収まっていますが、flat_hash_mapはありません。これを知れば、最初のグラフでも同じことが見られはしますが、こちらの方がだいぶはっきり分かります。
しかし、ここでの主なポイントは、max_load_factorの1.0を使うboost::multi_indexとstd::unordered_mapを、max_load_factorの0.5を使うflat_hash_mapとdense_hash_mapと比べることです。ご覧のとおり、全てのテーブルで同じmax_load_factorを使ったとしても、フラットなテーブルの方が速くなります。
これは予想されていたことですが、それでも測定する価値があったと思っています。ある意味、これはハッシュテーブルのパフォーマンスの最も正確な測定です。というのも、ここでは全てのハッシュテーブルが同じ方法で環境設定され、同じ占有率(load factor)を持っているからです。各データポイントは現行の占有率0.5を持っています。私は他のグラフの測定にこのメソッドを使いませんでしたが、現実的には、おそらく皆さんがmax_load_factorを変えることはないからです。さらに実際には、似たようなテーブルで異なる結果が見られている最初のグラフで、どれだけハッシュの衝突があるかによりますが、ギザギザの結果が見られるでしょう(2のべき乗と素数についての部分で示したように、占有率は、実はこの一部分に過ぎないのです)。そしてこのグラフには、私のテーブルの利点が一つ隠されています。探索回数の制限はより一貫したパフォーマンスにつながり、他のテーブルの行と比べてhash_mapの行のギザギザを減らすのです。
異なるキーと値
これまで、全てのグラフは、整数から整数のマップのパフォーマンスを測定するものでした。しかし、異なるキーやより大きな値を使えば、パフォーマンスに違いが出てくる可能性があります。まずは、キーとして文字列を使った場合の、ルックアップが成功した例と失敗した例から見ていきましょう。

注釈:
文字列のルックアップが成功した例
(縦軸)ナノ秒
(横軸)要素の数
既にキャッシュにテーブルが入っているバージョンのグラフを使いました。こちらの方が、作成が簡単です。ここで分かるのは、文字列を使うということは全てのラインを少しずつ上に動かすだけだということです。これは予想どおりです。というのも、ここでの主なコストはハッシュ関数の変更であり、比較にはより多くのコストがかかるからです。それでは、成功しなかった例も見てみましょう。
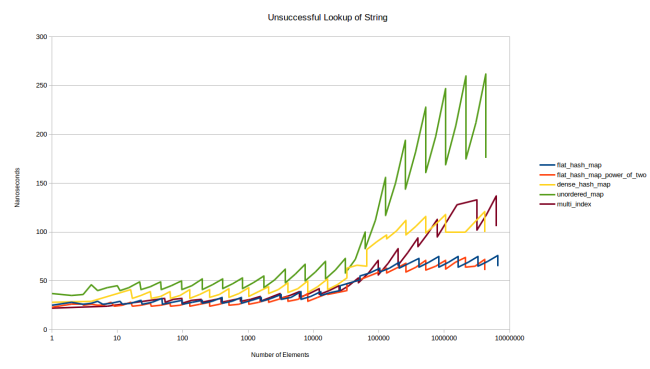
注釈:
文字列のルックアップがうまくいかなかった例
(縦軸)ナノ秒
(横軸)要素の数
これはとても面白い結果になりました。テーブルの中にない要素を探すことは、boost::multi_indexよりもgoogle::dense_hash_mapの方で多くのコストがかかるようです。この理由は、興味深いものです。dense_hash_mapを作る際にはスロットが空であることを示す特別なキーと、スロットがtombstoneになっていることを示す特別なキーを供給する必要があります。私はそれぞれ、std::string(1, 0)とstd::string(1, 255)を使いました。しかし、これはつまり、このテーブルはスロットが空であることを確かめるために文字列の比較をしなくてはいけないということです。他のテーブルは全て、スロットが空であることを確認するために整数の比較をするだけで済むのにです。
とは言ったものの、1文字だけを比較する場合の文字列の比較コストはとても低いはずです。そして、実際、オーバーヘッドはそれほど大きくありません。各ルックアップがキャッシュヒットであるため、上記に示したグラフでは大きく見えるだけです。キャッシュミスのグラフでは違って見えます。

注釈:
失敗したルックアップにおける文字列のキャッシュミス
(縦軸)ナノ秒
(横軸)要素の数
このグラフを見てみると、テーブルがまだキャッシュに存在しない段階においては、dense_hash_mapが速いままであることがわかります。一方で、テーブルが非常に大きくなった時(100万エントリを超えた時)に、遅くなるようです。なぜそうなるのか、私には分かりませんでした。
次に私が試したのは、値のサイズを変えることでした。整数から整数のマップではなく、整数から32バイトの構造体、または整数から1024バイトの構造体を使ったら、どうなるでしょうか? ルックアップのために作ったグラフは合計12個です([整数値, 32バイト値, 1024バイト値] × [整数キー, 文字列キー] × [成功したルックアップ, 失敗したルックアップ])。そしてこれらのグラフのほとんどが、上記のグラフそっくりの形になります。文字列のルックアップは、値のサイズに関係なく同じ形になっていますし、ほとんどの整数のルックアップも同じです。ただし、例外が1つあります。それは整数キーと1024バイト値の失敗したルックアップです。
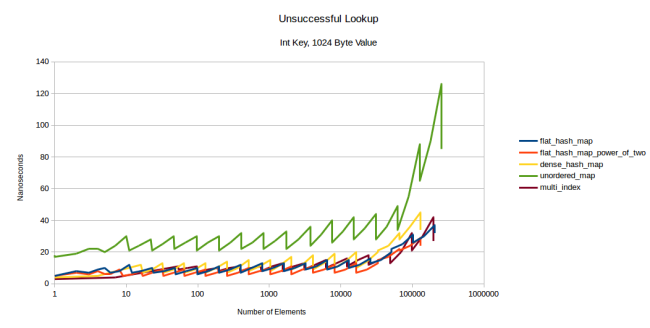
注釈:
失敗したルックアップ
整数キー、1024バイト値
(縦軸)ナノ秒
(横軸)要素の数
このグラフから分かるのは、1024バイト値においてmulti_indexはフラットなテーブルと同じような速さになるということです。これは、失敗したルックアップでは最大値の探索を行わなければならないこと、そして1024バイトといった巨大なサイズの型を使うと、プリフェッチするのに多大な負荷がかかるということが理由として挙げられます。私のテーブルはまだ大丈夫なように見えますが、これほどの大きさの値になると、基本的にすべてがノードベースのコンテナになるのです。
その他のルックアップのグラフがすべて同じに見える(そしてなぜ私がそれらのグラフを皆さんにお見せしないのか)理由は以下のとおりです。ノードベースのコンテナについては、値の大きさは関係ありません。どちらにしろ、すべて分割ヒープ領域なのです。フラットなコンテナについては、さらに多くのキャッシュミスがあるのではないかと予想していたことでしょう。しかし、max_load_factorが0.5のため、テーブルに存在する要素を素早く見つけることができます。最もよくあるのはルックアップが1回だけのケースです。つまり、最初の探索での発見が可能なこと、または最初の探索でテーブルに存在しないと分かっているといったケースです。2回ルックアップがあることもよくあることですが、ルックアップが3回重なることはほとんどありません。また、少なくとも私のテーブルでは、探索は単なる線形探索になっています。要素の大きさにかかわらず、線形探索で次の要素をプリフェッチする時に、CPUは素晴らしい仕事をするのです。
ルックアップを行う場合は、型のサイズによって変化はありません。しかし、挿入や消去のグラフは大きく変わります。以下に整数をキーとし、32バイトの構造体を値とする挿入のグラフをお見せしましょう。
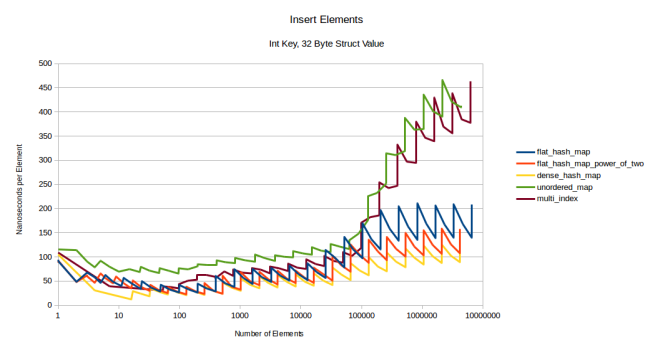
注釈:
挿入要素
整数キー、32バイト構造体の値
(縦軸)ナノ秒/要素
(横軸)要素の数
グラフは、全て少し上に上がっていますが、フラットなテーブルの各グラフの上がり幅が大きく、ギザギザの幅も大きくなっています。つまり、より多くのデータを移動させなければいけない状況になるほど、再割り当てが影響するということです。一方、ノードベースのコンテナはこの影響を受けませんし、boost::multi_indexは長期間の競争力を保っています。では、非常に大きな型である1024バイトの構造体ではどうなるか、見てみましょう。
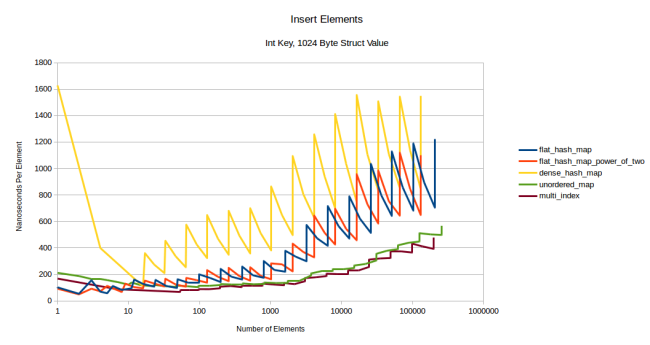
注釈:
挿入要素
整数キー、1024バイト構造体の値
(縦軸)ナノ秒/要素
(横軸)要素の数
順番が完全に逆転していますね。フラットなコンテナのコストが上がり、振れ幅も非常に大きくなりました。ノードベースのコンテナの速度には変化がありません。この時点では、再割り当てのコストが完全に支配していることが分かります。
1つ不可解なのは、dense_hash_mapに1要素を挿入するのに多大なコストがかかるということです。(黄色い線の一番左側がその事象を示しています)。これは、dense_hash_mapが最初に32スロットを配分し、デフォルトでコンストラクトされた型で埋めることが理由です。今回設定した型は1024バイトものサイズがあるため、32キロビットものデータを0に設定する必要がありました。別に気にするポイントではないかもしれませんが、この変な形を説明すべきだと感じたので、言及しておきます。
他に特筆すべき点は、私のハッシュテーブルよりdense_hash_mapの速度が遅いということです。なぜそうなのかという点については詳しく検証することはしませんが、上記で書いた理由と同じ理由であると、私は想像しています。つまり、dense_hash_mapがデフォルトでコンストラクトされた型を使って各スロットを埋めるということです。そうすると、たとえ一切使わない領域であっても、すべてのスロットが初期化されてしまうため再割り当てのコストが高くなってしまいます。
再割り当てのコストが高くなる場合の解決策は、事前にコンテナにreserve()を呼び出すことです。そうすれば、再割り当ては起こりません。最初にreserveを呼び出してから同様の要素を挿入するとどうなるか、見てみましょう。
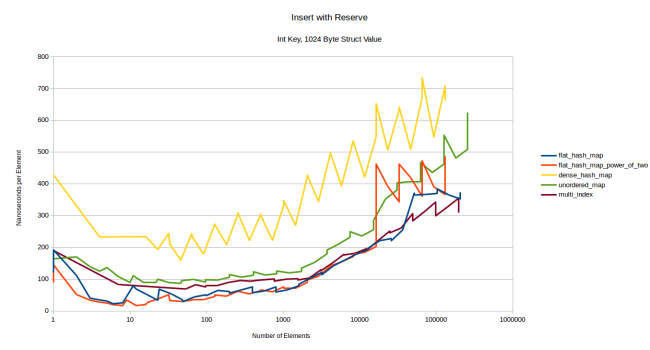
注釈:
reserveした後に挿入
整数キー、1024バイト構造体の値
(縦軸)ナノ秒/要素
(横軸)要素の数
事前にreserveを呼び出した場合の私のコンテナの速度は、最初はノードベースのコンテナよりも速いですが、ある時点から、やはりboost::multi_indexの速度が上回っています。dense_hash_mapは遅いままですが、これは必要以上の要素を初期化しているからでしょう。これほど大きな値では、テーブル全体を”空の”キーと値のペアに初期化するだけでも、かなりの時間がかかってしまいます。値の初期化はせずに、”空の”キーにだけ初期化して最適化すればいいのですが、1024バイトでは、どれだけの値の挿入が行われるのでしょうか? 格納された値が非常に大きくなったときのコンテナの振る舞いを、ベンチマークとしてテストできればうまくいきますが、実際にはそんなことはできないでしょう。
私のコンテナは、大きくなるまでは速かったのです。正確には16385個の要素から、コストは急激に跳ね上がっています。16384個の時点では、通常の速度です。コンテナにある全ての要素は1028バイトなので、コンテナが16メガバイト以上だと、急に速度が低下するということです。私は最初、これは探索数の上限に達したためのランダムな再割り当てだと考えました。それが珍しいことだというのは当記事で説明したのですが、ありがたいことに今回はそのケースではありません。この理由は興味深いものです。測定した時点を見ると、clear_page_c_eで費やされる時間が急激に増加していました。これが一体どういうことなのかを理解するのは簡単ではありませんが、Bruce Dawsonが 彼の記事 の中でメモリの初期化(ゼロ化)のコストについて言及してくれています。それは、clear_page_c_eの関数で起こるというのです。何らかの理由によって、OSがクリアされたメモリのページを提供するために、長い時間がかかったのでしょう。メモリマネージャとOSによっては、このようなことが起こる可能性もあります。
これはつまり、ワンタイムコストだということでもあります。一度コンテナが大きくなれば、もう二度とコストがこのようなギザギザになることはありません。コンテナが存在する時間が長くなると、コストが償却されるのです。
それでは文字列を挿入してみましょう。
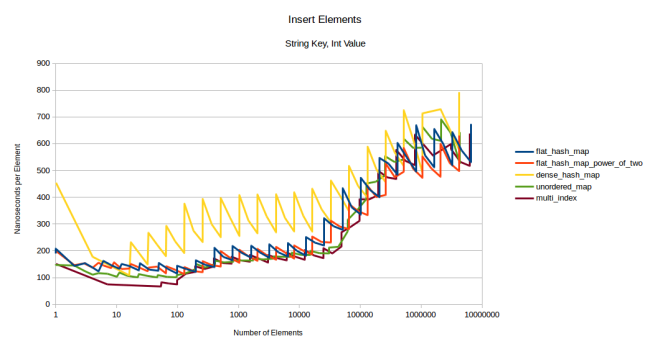
注釈:
挿入要素
文字列キー、整数値
(縦軸)ナノ秒/要素
(横軸)要素の数
このベンチマークでは、dense_hash_mapは驚くほど速度が遅くなっています。これは、私のdense_hash_mapのバージョンが、まだmoveのセマンティクスをサポートしていないからで、不必要な文字列のコピーを行っています。このバージョンをUbuntu 16.04で使用しています。少し古いかもしれませんが、ムーブセマンティクスをサポートしているものを見つけられそうにないので、こちらのバージョンを続けて使用します。
このグラフは主に、私のテーブルとノードベースコンテナとの比較するために使いますが、私のテーブルが敗北を喫しています。やはり再割り当ては高いコストになりました。最初にreserveを呼び出したらどうなるかを見てみましょう。

注釈:
reserveした後に挿入
文字列キー、整数値
(縦軸)ナノ秒/要素
(横軸)要素の数
正直なところ、このグラフからは何も読み取ることができません。文字列のコピーのコストが支配的で、全てのテーブルが同じように見えます。ここから分かることは、コピーのコストが高い型だと、挿入の時間を支配するということです。ルックアップタイムのような他の測定に基づいて、ハッシュテーブルを選ぶべきです。文字列を大きな値の型でキーとして挿入すると、これと似たような結果が出ました。

注釈:
reserveした後に要素を挿入
文字列キー、1024バイト構造体の値
(縦軸)ナノ秒/要素
(横軸)要素の数
ここでもまた、dense_hash_mapは全てのバイトを初期化するので速度が遅くなります。コピーのコストが支配しているので、この他のテーブルも、ほぼ同じ結果です。flat_hash_map_power_of_twoは、16385個の要素の時と同じような変なギザギザになりました。これはclear_page_c_eでの時間の増加によるもので、1024バイト値で整数を挿入したときも同じになります。
ここまでで次のようなことが分かりました。大きな型の場合、全てのテーブルで挿入の速度が等しく遅くなるので、事前にreserveを呼び出しておくべきです。ノードベースのコンテナは、小さい型よりも大きい型の場合に、より優位性があるオプションです。

株式会社リクルート プロダクト統括本部 プロダクト開発統括室 グループマネジャー 株式会社ニジボックス デベロップメント室 室長 Node.js 日本ユーザーグループ代表
- X: @yosuke_furukawa
- Github: yosuke-furukawa
関連記事