2018年4月19日
カオステストでHTTP/2の問題を見つけ出す
本記事は、原著者の許諾のもとに翻訳・掲載しております。
(注:2017/04/20、いただいたフィードバックを元に翻訳を修正いたしました。修正内容については、 こちら を参照ください。)

要約
HTTP/2 にはHTTP/1.xに比べて多数の改良点がありますが、 カオステスト を行ったところ、HTTP/2のパフォーマンスがHTTP/1より劣る状況があることが分かりました。
ネットワーク上にパケット損失がある場合、TCP層での輻輳制御によって、少数のTCPコネクションの中に多重化されているHTTP/2ストリームがスロットリングされます。さらに、TCPリトライのロジックにより、リトライが行われている間、1つのTCPコネクションに影響しているパケット損失が、いくつかのHTTP/2ストリームに同時に強い影響を与えます。言い換えれば、ヘッドオブラインブロッキングが事実上、ネットワーク階層の レイヤ7 から レイヤ4 へ移動したということです。
背景とサービスメッシュの空間
サービスメッシュ は、最近一般的になってきた、クラウドネイティブアーキテクチャのためのネットワーキングモデルです。各々が選んだたくさんの技術を使って作業している別々のチームの開発者たちは、高速で信頼性の高い通信をサービス間で行うために必要なロジックを「サイドカー」プロセスに入れることによって、ライブラリも、アプリケーションコードへの変更も必要とせずに、一貫したネットワークトランスポート手段を得ることができます。
このプロセス外アーキテクチャでは、各アプリケーションはメッセージの送信と受信を localhost に対して行い、ネットワークトポロジについては関知しません。サービスメッシュのサイドカーは、アプリケーションからは見えず(透過的)で、サービスディスカバリ、ロードバランス、回路遮断、リトライ、暗号化、転送速度制限などの問題を一貫的に処理できます。
最近、サービスメッシュの空間はとても活発で、Lyftの Envoy 、 linkerd 、 Traefik のような新しいプロジェクトが nginx と HAProxy に加わって、ますます革新的な状況を見せています。
Twilioでは、豊富な機能セットをもつEnvoyに特に注目しました。その機能には、改良された遠隔測定法(これまで私たちが使っていた statsd 、 LightStep と統合されています)、経路全体を把握した(AZ-awareな)先進のルーティング能力、そして、マイクロサービスが互いに通信するための、暗号化されたコネクションを介した一貫した方法などがあります。さらに、GoogleがEnvoyを支援していること、最近 CNCF に加入したこと、コミュニティが急速に成長していることから、このソフトウェアプロキシが将来さらに改良されると確信しました。

HTTP/2への移行
Envoyに組み込まれた機能のうち、特に興味深いものは、HTTP/1のトラフィックがHTTP/2に透過的にアップグレードされることです。
HTTP/2はHTTPプロトコルへの最新の大きな改訂です。HTTP/1からの主要な改良点は、HTTP/2がバイナリ/フレーム形式のプロトコルであり、HTTPリクエストを持続性TCPコネクション内のいくつかの双方向ストリームに多重化することです。また、HTTP/2では、リクエスト/レスポンスのヘッダを圧縮してパフォーマンスを改善できます。
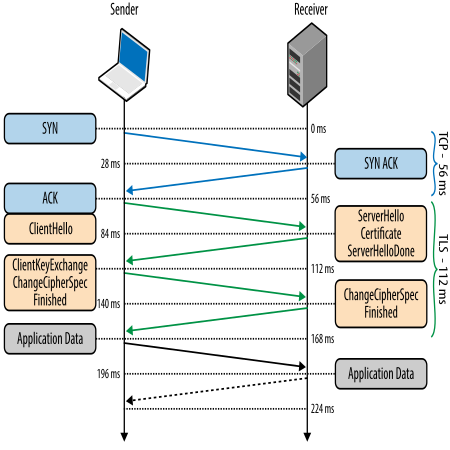
HTTP/2が持続性コネクションに対応していることは、特に私たちの興味を引きました。サービス間のネットワーク遅延を減少させられる可能性があるからです。通常、ホスト間に新しいTLSコネクションを作るには、何回かのやりとりの往復(ラウンドトリップ)が必要です。TCPコネクションそのものを作るための3ウェイハンドシェイクに加えて、暗号化トンネルのネゴシエーションのために、ホスト間でさらに2回のラウンドドリップが必要になります。

私たちには非常に小さな遅延でセキュアな通信を行いたいという要望があります。その要望が、サイドカープロセスを使って言語不問の一貫した暗号化TCPコネクションを作り出す能力によって満たされるのではないかと考えました。おまけに、既存のサービスのコードを変更せずにHTTP/2の他の新しい機能へもアップグレードできるという点も魅力的でした。
そう考えれば、当然、そうした技術的利点を検証したくなります。そこで、私たちのチームは、サービスをHTTP/2を使った通信にアップグレードする利点をテストすることにしました。
カオスエンジニアリングとテスト計画
カオスエンジニアリングとは、数年前にNetflixによって作られた造語です。簡単に言えば、カオスエンジニアリングの中心となる発想は、故障をシステムに先手を打って注入することです。そうして、システムが故障する様子を観察し、実際のディザスタに見舞われたときにサービスが停止しないように改良を施すのです。
Principles of Chaos Engineering(カオスエンジニアリングの原理) というドキュメントでは、カオスエンジニアリングが次のように説明されています。
カオスエンジニアリングとは、システムの、稼働中の混乱状況に耐える能力を信頼できるようにするための、分散システムにおける実験の規律。
クラウドで運用される分散システムでは、ネットワーク遅延とパケット損失は、サービス間の通信でよく見られる問題です。問題に直面したときのTwilioの信頼性と耐性を高めるために役立てるために tc コマンドを使ってカオステストを行い、さまざまな組み合わせのネットワーク遅延とパケット損失をサービスに与えました。例えば、0ms/10ms/25msのネットワーク遅延と、0%/1%/3%のパケット損失を加えました。
テスト構成の設定は次のとおりです。
- AWSの同一アベイラビリティゾーン内に2つのc3.2xlargeインスタンス
- クライアントが、1KBのPOSTペイロードと現実的なリクエストヘッダのセットを使って、ローカルホストのサイドカーを通して1000HTTPリクエスト/秒で[Vegeta](https://github.com/tsenart/vegeta)を実行
- 最初は2分間の繰り返しで実行しましたが、その時のテスト結果は紛らわしく見えたので、15分間の終夜実行に切り換えました(「テスト結果」のセクションで詳しく説明します)。
- サーバが“`return 200“`locationでnginxを実行し、static型の1KBの本体を返す
- いくつかsysctlを調整しましたが、それ以外は私たちのLinux AMIのデフォルトです
- “`net.core.somaxconn“`
- “`net.ipv4.tcp_fin_timeout“`
- “`net.ipv4.ip_local_port_range“`
そして、次のサイドカー構成をテストすることにしました。
- サイドカー無し(つまり、クライアント-サーバ間直接通信)
- HAProxyサイドカー
- HTTP/1を使用したシングルのegress-only Envoy(HAProxy構成に類似)
- HTTP/1を使用したダブルEnvoy
- HTTP/2を使用したダブルEnvoy
- HTTP/2とTLSを使用したダブルEnvoy
HTTPリクエスト遅延テストの結果

Envoyの、HTTP/2への透過的アップグレードのパフォーマンスは、基本的に、HAProxyやサイドカー無しの構成と同様でした。上のグラフでは、遅延とパケット損失はカオスエンジニアリングによって人為的に追加されていません。平均/中央値/p95/p99のリクエスト遅延は、どのシナリオでも互いに類似しています。その他の追加の特徴や利点がHTTP/2から得られるとはいえ、トラフィックをHTTP/2に透過的にアップグレードしても、遅延の違いは1ミリ秒にも満たないものでした。
しかし、カオステストのシナリオで3%のパケット損失を追加すると、結果はずっと興味深いものになりました。
ここには、追加3%のパケット損失でのp99遅延だけを、さまざまなネットワーク遅延のレベルで示します。これを見ると、HTTP/2を使うと、3%のパケット損失があるときには99th%リクエスト遅延のパフォーマンスが一貫して劣ることが分かります(紫と水色のバー)。
この結果は、非常に紛らわしいものでした。HTTP/2はHTTP/1より優れているはずではなかったのか? HTTP/2はバイナリプロトコルで、多重化され、持続性コネクションがあり、ヘッダが圧縮されます。どのテストでもHTTP/2はHTTP/1に勝つはずでは? なぜこんなに成績が悪いのか?
はじめは、テストのやり方をどこか間違っているのだと考えました。AWSのクラウドでの断続ネットワーキングの問題か、テストの自動化でのコードエラーかも知れないと。終夜や週末にテストを繰り返し実行して、テストコードにバグがないか調べました。残念ながら、テスト結果は非常に再現性が高いものでした。
この謎の説明を求めて、データを詳しく調べることにしました。Vegetaの -dump モードを使って、テスト中に行われた全てのHTTPリクエストのネットワーク遅延のCSVを生成しました。次にそのCSVを使って、基礎データのリクエスト遅延のパターンを見るために散布図のグラフを作成しました。先ほど見た棒グラフではそれぞれの集計を通してデータがマスキングされていましたが、それに比べて、この図を見ると、各ネットワークリクエストに何が起こっていたのかがよく分かります。
この散布図のグラフから判明した結果は、衝撃的でした。
[TABLE]
HTTP/2テスト結果の解釈
上のグラフから、明らかな疑問がわいてきます:HTTP/2に何があったのか? リクエスト遅延時間が正弦曲線を描くのはなぜか?
次のシナリオを考えてみましょう。
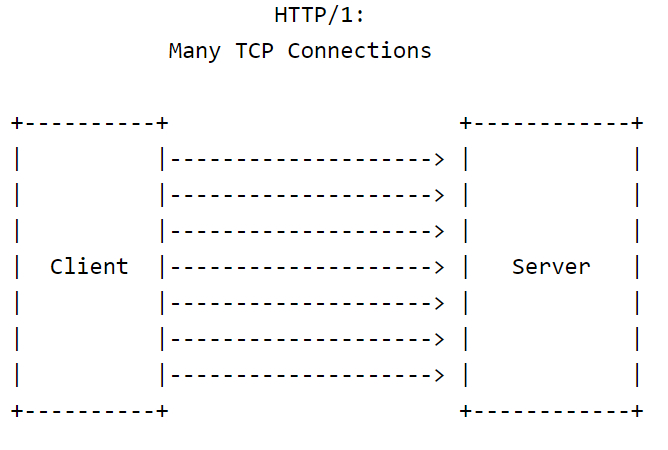
注釈:
HTTP1:多数のTCPコネクション
- HTTP/1の場合:各HTTPリクエストにそれぞれTCPコネクションがあり、各TCPコネクションは別々に、それぞれ最適なTCP輻輳ウィンドウ(CWND)を決定しようとします。
- TCPコネクションのどれか1つがパケット損失に遭遇しても、他のコネクションには影響しません。
- TCPコネクションのいくつかがパケット損失に遭遇したとき、全体的なスループットは比較的大きな数であるTCPコネクションの数の関数になります。
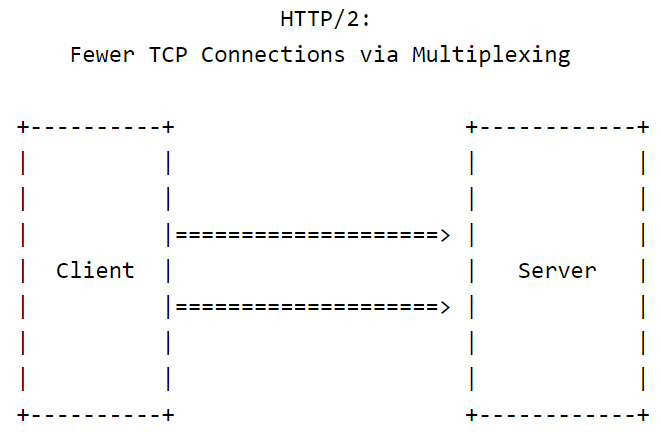
注釈:
HTTP2:多重化によりTCPコネクションが少なくなる
- HTTP/2の場合:TCPコネクションの数は比較的少なく、持続性です。各TCPコネクションの中にはいくつかのHTTP/2ストリームが多重化されています。
- パケット損失が起こると、そのTCPコネクション内の全てのストリームが2つの不利益を被ります。
- 不利益その1:失われたパケットの再送を待つ間、そのTCPコネクション内の全てのHTTPストリームが同時に停止します。すなわち、HTTPリクエストのヘッドオブラインブロッキングがレイヤ7からレイヤ4に移動したのです。
- 不利益その2:TCPウィンドウのサイズが劇的に小さくなり、全てのストリームが同時にスロットルダウンされます。
- パケット損失が起こると、そのTCPコネクション内の全てのストリームが2つの不利益を被ります。
- HTTP/1のシナリオよりもTCPコネクションが少ないので、全体的なスループットは必然的にHTTP/1の場合よりも低下します(すなわち、N > Mなら、N個の不良コネクション > M個の不良コネクション)。言い換えれば、HTTP/2の強みの1つは大きな弱点の1つでもあるのです。
重要なのは、ここで明らかになった問題はEnvoyに限ったことではないということです。それでもTwilioでは、サービスメッシュのサイドカーとしてEnvoyを採用する方向に進んでいます。HTTP/1とHTTP/2のどちらを介しても、私たちのマイクロサービス間に透過的で一貫したサービスメッシュを提供するというビジネスニーズを満たすからです。
さらに、このテストの遅延とパケット損失は tc を使って人工的に導入したものだということを忘れてはなりません。現実の世界では、正確に3.00%で数時間にわたって持続するパケット損失など起こるとは思えません。Twilioにはネットワーク条件をモニターするための洗練されたツールセットがあり、今ではHTTP/2の弱点に適応できているので、HTTP/2を使用する事例でネットワーク条件がプラットフォームに悪影響を及ぼすおそれがあっても、それに備えることができます。さらに、Envoyには非常に多くのメトリクスがあり、statsdとLightstepの統合により視覚化されているので、それらも私たちのツールボックスに加わります。
この話題に関してさらに詳しく知りたい方には、 QUIC, a UDP-based Transport for HTTP/2 のRFCを一読されるようお勧めします。 section 5.4 では、Googleの著者がTCPの上のHTTP/2の問題を特に指摘しており、さらに柔軟な輻輳制御をアプリケーション層に移動させる次世代のプロトコルの提案の詳細が記載されています。
最後に
クラウドサービスには、幅広いさまざまな技術要件があります。例えば、マーケティングSaaSと、メッセージングアプリと、ストリーミングビデオサービスを比べてみましょう。
Twilioは、グローバル通信ネットワークとして運用され、24時間休みなく稼働する必要があるので、私たちのサービスが、大きな規模で、さまざまな状況でどのように振る舞うかを理解することは重要です。ネットワークにパケット損失があるときにHTTP/1よりもパフォーマンスを下げてしまうという、HTTP/2のアーキテクチャ上のトレードオフを、カオステストを通して洗い出すことができました。
それでも、事例によってはHTTP/2は正しい選択かもしれません。その判断は完全な技術評価に基づくべきであり、その評価には健全な量のカオスエンジニアリングを含めるべきです。そうすれば、並外れた信頼性と弾力性をもった、サービスの大規模な動作を確保できます。

株式会社リクルート プロダクト統括本部 プロダクト開発統括室 グループマネジャー 株式会社ニジボックス デベロップメント室 室長 Node.js 日本ユーザーグループ代表
- X: @yosuke_furukawa
- Github: yosuke-furukawa
関連記事