2018年6月28日
iPhone XのFace IDを、Pythonとディープラーニングで再現する方法

本記事は、原著者の許諾のもとに翻訳・掲載しております。
iPhone Xの新しいロック解除メカニズムのリバースエンジニアリング

新しい iPhone X で議論の的になった機能と言えば、新規ロック解除方式で、Touch IDの後継である Face ID でしょう。
ベゼルレスのスマートフォンを実現してきたAppleは、端末を簡単かつ素早くロック解除できる新たな方式を開発する必要がありました。競合他社が指紋認証を採用し続ける中、Appleは別のポジションのメーカーとしてスマートフォンのロック解除方式を刷新し、変革を起こす決断をしました。それは、単に見るだけで認証されるという機能です。進化した(そして驚くほど小さい) 深度センサ付きカメラ が前面に埋め込まれているおかげで、iPhone Xにはユーザの顔面の3Dマップを生成する能力があります。さらに、ユーザの顔写真を 赤外線カメラ でキャプチャするため、環境の光や色彩による変化に左右されにくいのです。 ディープラーニング を用いたスマートフォンは、ユーザの顔を極めて詳細に学習し、オーナーが手に取るたびに本人かどうかを認識することが可能です。驚くのは、この方式は Touch IDよりもはるかに安全 であり、誤って別人を認識してしまうエラー率は100万分の1に過ぎないとAppleが説明していることです。
私はAppleがFace IDの実現に用いた技術に非常に興味をそそられました。とりわけ、この機能のすべてがオンデバイスで稼動し、最初にユーザの顔を少し学習するだけで、スマートフォンを手に取るたびにスムーズに機能するという事実に惹かれたのです。そこで、ディープラーニングでこの処理を機能させる方法と、各ステップを最適化する方法に注目しました。この投稿では、 Kerasを利用してFace IDに似たアルゴリズムを実装する過程 を紹介しましょう。私が選んださまざまなアーキテクチャに加え、最後のKinectを使った実験についても説明します。 Kinect はよく知られたRGB・深度センサ付きカメラで、iPhone Xの前面カメラによく似たアウトプットができます(しかし、モバイルよりもかなり大きなデバイスで)。ゆっくりとコーヒーでも飲みながら、 Appleの画期的機能のリバースエンジニアリング にお付き合いください。
Face IDを理解する
「…ニューラルネットワークが駆動するFace IDは、単に分類を実行しているのではありません」。
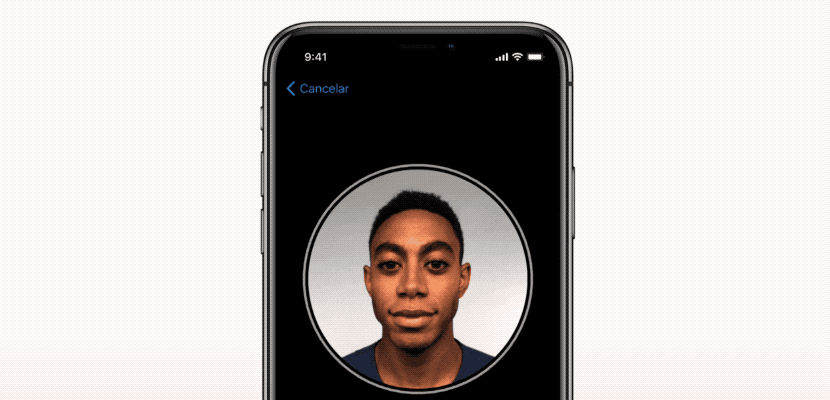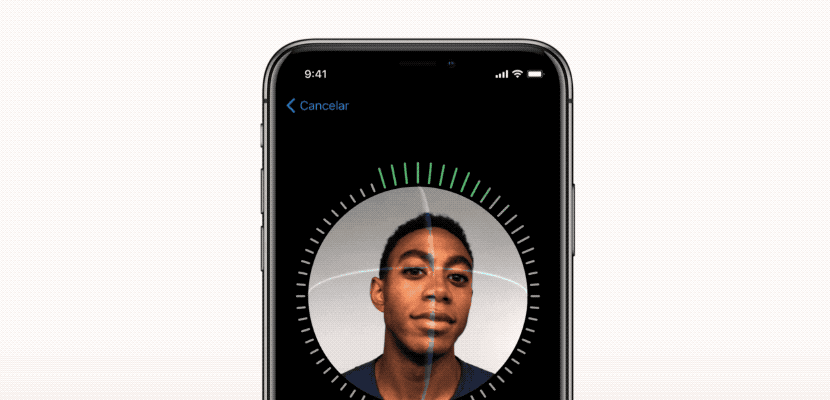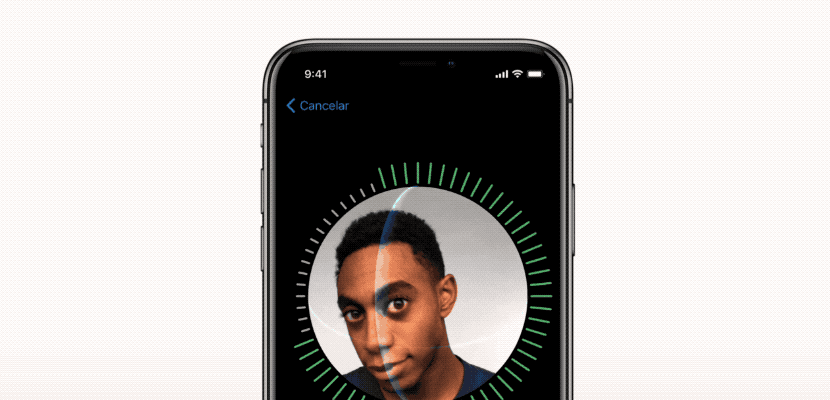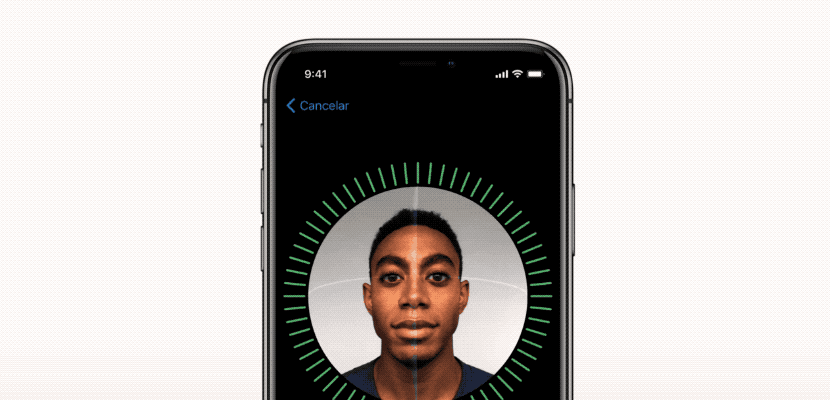
Face IDの設定プロセス。
第一のステップは Face IDがiPhone X上でどのように動作するのか を丁寧に解析することです。Appleが提供する ホワイト・ペーパー がFace IDの基本的なメカニズムを理解するのに役立つでしょう。Touch IDの場合、ユーザは初めにセンサを数回押して、指紋を登録する必要があります。15回から20回のタッチで、スマートフォンは登録を完了し、Touch IDが有効になります。同様に、Face IDの場合、ユーザは顔を登録しなければなりません。プロセスは非常にシンプル、ユーザはいつもやっているように端末を見るだけです。そして頭をゆっくりと円を描くように回し、別のポーズからも顔を登録します。以上でプロセスは完了し、スマートフォンはロック解除できるようになります。この非常に迅速な登録手順を見れば、 根底にある学習アルゴリズムに関して多くのことが分かります。 たとえば、 ニューラルネットワーク が駆動するFace IDは、 単に分類(クラシフィケーション)を実行しているのではありません。 理由を説明しましょう。

iPhone XとFace IDを披露するApple Keynote。
分類の実行は、ニューラルネットワークにおいては、顔がユーザのものであるか否かを予測できるよう学習することを意味します。そのためには、基本的には訓練データを使って 「真」、「偽」のいずれかを予測 しなければならないでしょう。しかし、他の数多のディープラーニングのユースケースと異なり、ここではそのアプローチは 使えません。 まず、ネットワークは、ユーザの顔面から新たに取得したデータを使ってゼロから再訓練しなければなりません。これには 相当の時間とエネルギーがかかる 上、 訓練データとしていくつもの「偽」の顔の例を集める のは非現実的です(既に訓練されたネットワークの転移学習と微調整を行ってもほとんど変わらないでしょう)。何よりも、この方式ではAppleは「オフライン」、すなわち彼らのラボではるかに複雑なネットワークを訓練し、学習済みですぐに使えるiPhoneとして出荷する可能性が見出せないのです。代わりにFace IDは、Appleが「オフライン」で訓練した シャム双生児型(Siamese)の畳み込みニューラルネットワーク で動いているのではないかと私は思います。 対比損失(contrastive loss) を用い、別人の顔の間の距離を最大化するよう成形した 低次元の潜在空間(low-dimensional latent space) に顔をマッピングする仕組みです。何が起こるかと言うと、 ワンショット学習(One shot learning) の能力を持ったアーキテクチャが実現するのです。これについては、わずかながらKeynoteのレクチャーで言及されていました。多くの読者には馴染みのない名称があったと思いますが、読み続けてください。1つずつ私が言わんとしていることを説明しましょう。

Face IDはTouch IDの跡を継ぐ新たなスタンダードになりそうです。Appleは全デバイスに採用するのでしょうか?
ニューラルネットワークで顔面から数字へ
シャム双生児型(Siamese)ニューラルネットワーク は基本的には全重量を共有する2つの同一のニューラルネットワークで構成されています。このアーキテクチャは、画像など特定の種類のデータ間の 距離の算出 を学習できます。シャム双生児型ネットワークを通して複数のデータを渡すと(あるいは単純にデータを、同じネットワークを通して2つの別々の段階を踏んで渡す)、ネットワークがそれをN次元配列のような 低次元特徴空間(low dimensional feature space) にマッピングします。ネットワークを訓練し、異なるクラスのデータ点は 可能な限り遠く 、同じクラスのデータ点は 可能な限り近く マッピングするという考え方です。長期的には、ネットワークはデータから最も意味のある特徴を抽出することを学習し、配列へ圧縮して意味を持つマッピングを作成できるようになります。この過程を 直感的に理解 するには、小さなベクトルを使って 犬の品種を説明 するにはどうするかを想像してください。似ている犬たちがより近いベクトルを持つようにします。おそらく、数字を用いて犬の毛の色をコード化したり、犬のサイズや毛の長さなどを示したりするのではないでしょうか。そうすると、似ている犬同士は互いに似たベクトルを持つことになります。実にスマートでしょう?そう、シャム双生児型ネットワークは代わりにそれを学習し、 自動エンコーダ と似た動きをしてくれます。
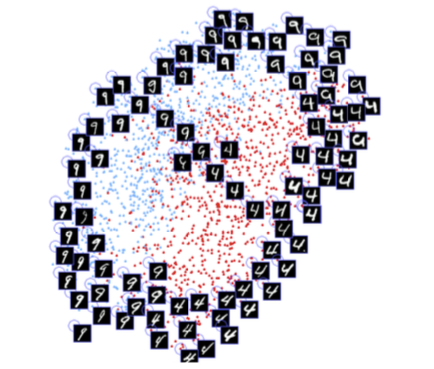
Hadsell, Chopra and LeCun著の論文『不変マッピングの学習による次元削減(Dimensionality Reduction by Learning an Invariant Mapping)』掲載図。アーキテクチャが数字間の類似性を学習し、自動的に2次元にグループ化していることに注目してください。同様の技法が顔面にも適用されています。
この技法であれば、膨大な数の顔を使い、どの顔同士が最も似ているかを認識するようなアーキテクチャを学習させることができます。予算とコンピューティングの力量が望めるなら(Appleのように)、 もっともっと高度な例 を使い、双子や敵対攻撃(マスク)などにも動じないネットワークを作れるでしょう。そしてこのアプローチを使う最終的な利点は何でしょうか?それは、さらなる訓練を施すことなく、さまざまなユーザを認識する モデルについにアクセスできるようになる ことです。初期設定の間に何点か写真を撮ったら、後は単にユーザの顔が潜在マップのどこに位置するかを算出するだけでよいのです(先述の例で言えば、犬種のベクトルを書き、新しい犬用にそれをどこかに保存しておけると考えてみてください)。加えて、Face IDはあなたの容貌の変化にも対応できます。突然の変化(例:メガネ、防止、化粧)でも、緩やかな変化(例:顔の毛)でも問題ありません。基本的にはこのマップ内に新たな見た目に基づいて計算された参照顔面ベクトルを追加することで実現します。

Face IDはあなたの容貌の変化に適応します。
では最後に Kerasを用ってPythonで実装する方法 を説明しましょう。
KerasでFace IDを実装する
あらゆる機械学習プロジェクトにまず必要なのはデータです。独自のデータセットの作成は時間と大勢の人員協力を要し、とても容易ではありません。そこで私はWeb上でRGB-D顔面データセットを探し、 ぴったりのものを見つけました 。これはiPhone Xのユースケースで生成されるような、さまざまな人々の顔のさまざまな角度、表情をとらえたRGB-D画像のシリーズでできています。
最終的な実装は私の Githubリポジトリ にあるJupyter Notebookで見ていただけます。さらに、 Colab Notebook でも実験しましたので、こちらも試してみてください。
畳み込みネットワークは SqueezeNet アーキテクチャを基盤に作りました。このネットワークは2つの顔面のRGBD画像、4チャネルの画像を入力すると、2つの埋め込みの間の距離を算出します。ネットワークは 対比損失(contrastive loss) で訓練されており、同一人物の画像間の距離を最小化し、別人の画像間の距離を最大化します。
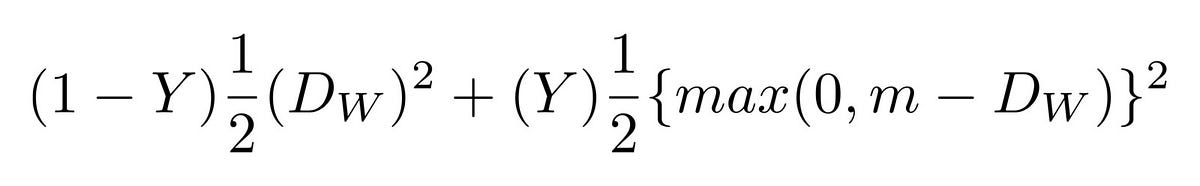
対比損失(contrastive loss)。
訓練後、ネットワークは顔を128次元配列にマッピングできるようになります。同一人物の画像は一緒のグループに入れ、別人の画像からは隔離します。つまり、 デバイスのロックを解除する には、ネットワークは解除の際に撮られた画像と、登録フェーズで保存した画像との間の距離を測るだけでよいのです。その距離が一定の基準値(小さければ小さいほど安全)を下回ると、デバイスのロックは解除されます。
ここでは t-SNEアルゴリズム を使って、128次元の埋め込み空間を2次元で視覚化しました。各色はそれぞれ別の人物に相当します。見てのとおり、ネットワークはこれらの画像を非常に厳密にグループ化できるように学習してきています(t-SNEアルゴリズム使用時はクラスタ間の距離に意味はありません)。興味深いプロットは、 PCA次元削減アルゴリズム を使用した際にも現れます。
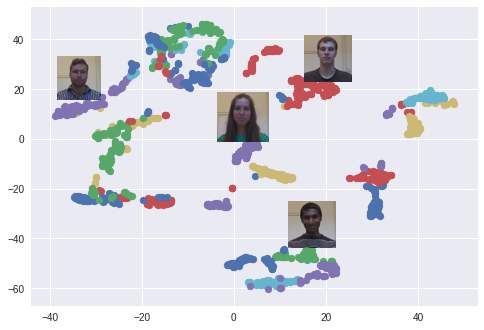
t-SNEを使って作成した埋め込み空間における顔のクラスタ。それぞれの色は別の人に相当します(但、色は再利用します)。
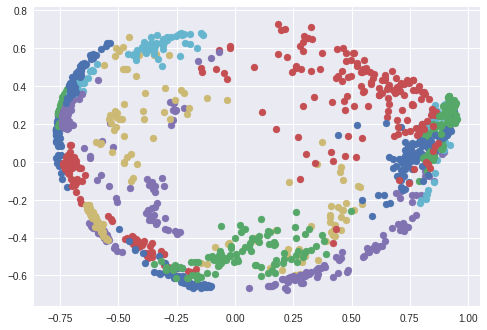
PCAを使って作成した埋め込み空間における顔のクラスタ。それぞれの色は別の人に相当します(但、色は再利用します)。
実験!
モデルの動作を試せるところまで来ました。通常のFace IDサイクルでシミュレーションしてみましょう。まずはユーザの顔の登録です。次にロック解除のフェーズで、ユーザ(成功するべき)と、デバイスをロック解除できてはいけない他のユーザの両方で試します。先に説明したとおり、差異は、ネットワークが算出するロック解除可能な顔と登録した顔との間の距離、そしてそれが基準値を下回るか否かにあります。
登録から始めましょう。データセットから同一人物の画像シリーズを取得し、登録フェーズのシミュレーションをしました。これでデバイスは各ポーズにつき埋め込みを算出し、ローカルに保存しています。

Face IDのプロセスから発想を得た新規ユーザの登録フェーズ。

深度センサ付きカメラで見る登録フェーズ。
では、同一ユーザがデバイスのロック解除を試みた場合に何が起こるかを見てみましょう。同一ユーザのさまざまなポーズ、表情は、平均0.30という低距離を示しています。

埋め込み空間における同一ユーザの顔の距離。
一方で、別の人物のRGBD画像は平均1.1の距離を取得しています。

埋め込み空間における別人の顔の距離。
以上の結果から、約0.4の基準値を設定すれば、別人があなたのデバイスのロックを解除してしまうのを防げそうです。
まとめ
この投稿では、顔の埋め込みとシャム双生児型の畳み込みネットワークを基に、Face IDのロック解除メカニズムの概念実証を行う方法を紹介しました。役に立ったなら幸いです。また質問があればご連絡ください。 関連するPythonコードはすべてこちらで閲覧できます。

株式会社リクルート プロダクト統括本部 プロダクト開発統括室 グループマネジャー 株式会社ニジボックス デベロップメント室 室長 Node.js 日本ユーザーグループ代表
- X: @yosuke_furukawa
- Github: yosuke-furukawa
関連記事