2016年7月13日
ハミング符号 : データの誤り検知/訂正をインタラクティブに学ぶ
(2016-02-01)by Nick Berry
本記事は、原著者の許諾のもとに翻訳・掲載しております。
今週お話しするのは、誤りの検知についてと、さらに誤りの訂正についてです。

我々が住んでいる世界は完璧ではなく、デジタルの信号(on/off)を扱う時でさえ誤りが生じます。電力の異常によりビットが反転することがあるのです。ハードウェアも失敗を起こすことがあり、信号が歪められることもあります。
デジタル信号に生じた誤りを検知する方法については既に過去に書いたことがあります。もっとも一般的なやり方は、ある種のパリティビット(ご存知なくともご心配なく。以下でパリティの意味を説明します)です。ある長さの単語に対し、シンプルなパリティビットをたった1つ加えることで、単語中のビットが1つ反転した場合にそれを検知することができます。「エラーが起こったことがわかる」ということは有益ですが、1個のパリティビットだけではその誤った信号を修復することができません。また、信号中に2個以上の誤りがあった場合、その誤りが打ち消し合って誤りの検知が全くできないこともあります。
数学には、誤り検知/訂正が可能になるよう余分なデータを信号にエンコードする手法を取り扱う分野があり、この記事ではそのうちの1つの手法を取り扱います。その手法とは、1950年にアメリカの数学者Richard Wesley Hammingが発明したものです。彼の解決策は、彼の名前から ハミング符号 と呼ばれています。まず、数学に深入りする前に、いくつかの思考実験をしてみましょう。
ノイズのある信号
以下のような、コード化された「I LOVE LUCY」というメッセージを送信したいと仮定します。

しかし問題なのは、このメッセージを送るのに使おうとしているチャンネルがノイズまみれなので、全ての文字が破損せずに送られる可能性が低い、ということです。もし1文字だけが誤りを起こしており、その文字が最初の1文字目だった場合、その誤りの起こり方に感謝するでしょう。「N LOVE LUCY」という文に意味はないからです。「I LRVE LUCY」のようになった場合も同様に意味のない文になります。しかし、もし「I MOVE LUCY」となってしまった場合、おかしなところのないメッセージとして受け取られかねませんし、「I LOVE LUCK」などでも同様です。これらはみな1文字だけしか誤っていないのです。

もし2文字が変わってしまった場合、例えば「I ZZVE LUCY」となってしまうかもしれません。この場合は誤りだとわかりますが、もし2文字の変化により「I HOPE LUCY」や「I WOVE LACY」、「I LOVE LADY」となってしまった場合、誤りだと気付かれないかもしれません。
もし3文字が変わってしまった場合、例えば「IGNORE LUCY」になってしまったりして(スペースもただの文字の一つです)、これも誤りには見えないでしょう!
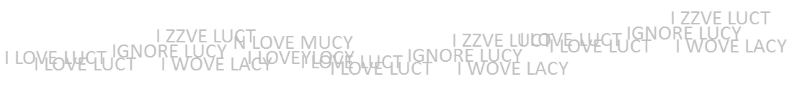
また、送るメッセージが英語のテキストでなくパスワードやデータの文字列で、有効なメッセージか確認するための辞書やスペルがない場合、一体どうなってしまうでしょう?誤りがあった事を知ることさえできないのです!
メッセージが何らかの方法で破損したことを知ることができれば、それは素晴らしいことです。更に、メッセージが自身を訂正できればさらに素晴らしいです。
それでは、受け取ったメッセージが送信者の意図通りのものであったかどうかについて、強く確信を得るための方法にはどんなやり方があるでしょう?
1つに、メッセージを複数回送るという方法があります。もしも誤りの起こり方が公平にランダムな分布となっていれば、誤り同士を互いに打ち消し合うことが可能でしょう。上記のような不自然な例(誤りがランダムに分布して いない )でさえも、メッセージが複数回送信され、最も頻出する答えを各文字ごとにとる(各位置ごとの最頻出文字)ことで、メッセージを修正できる可能性が十分にあります。失敗の余地がないわけではありませんが、これでもおそらく機能はすることでしょう*。 もしもさらに正確さを求めるのであれば、メッセージを更にたくさんの回数送るという方法があります。しかし、この方法は、正しい情報も同様にたくさんの回数を送ることになるので、回数を増やせば増やすほど非効率性は急速に増していきます。
上のように、メッセージを複数回送りました。それぞれの文字について、「何番目の文字としてはどの文字が頻出である」というのを全ての文字位置について取った場合、元のメッセージを再構築することがうまくできるかもしれません。
もしノイズが弱ければ、メッセージを送りなおす回数を少なくしてもノイズの除去ができるでしょう。逆にノイズが強ければ、より多くの回数の送信が必要になります(より詳しい説明はのちほど)。
* お分かりかもしれませんが、数学的に言って、これも100%確実ではありません。普通に考えて起こりえないようなことが(悪い意味で)起こることもありますし、用意した検知機構を欺くような誤りが信号送信の度に起こる、ということもあり得ます。メッセージの検証のためにチェックサムを計算したとしても、そのチェックサムも同様に送信されるので、チェックサム自体もあたかも上手く行っているようにご送信されることさえあり得るのです。
バイナリ
それでは、この思考実験をバイナリ(=現在のコンピューターがほとんどの場合に使っているもの)の場合について考えてみましょう。バイナリは 理論的に 最も効率的なデータ保存方法とは限りません。しかし、バイナリは「信号が存在する」「信号が存在しない」という2つの状態しか(物理的に)とらないため、信号が有無で表現されるデジタルコンピュータにおいてはうまく機能します。
パリティ
1101 という4ビットの単語を送信する必要があるとしましょう。これに対して何ができるかを見ていきます。

まず最初にパリティビットについて話していきましょう。パリティテストは、単一の誤りが起こった場合に検知することができる手法です。4ビットの単語の末尾に1ビットのデータ(パリティビットといいます)を追加し、合計で5ビットの単語にします。パリティには偶数パリティと奇数パリティがあります(一貫してどちらかを使うようにさえすれば、どちらを使っても構いません)。偶数パリティでは、「あらゆる単語において、1になっているビットの個数が常に偶数でなければいけない」ということになります。1101という例についていえば、1になっているビットが奇数個あるので、個数を偶数にするためにパリティビットとして1を追加します(1になっているビットの個数が既に偶数個であれば、パリティビットは0になります)。
メッセージを受け取った後、パリティが正しいかどうかをチェックすることができます。
試してみる
以下に4ビットの単語があり、5ビット目は偶数パリティビットを表すようになっています。
データのビットを クリック して値を変更し、パリティビットへの影響を確認してみましょう。
| 0 | 0 | 0 | 0 | 0 |
| D ₁ | D ₂ | D ₃ | D ₄ | Parity |
ここからわかるように、パリティビットを含めたどのビットが1つ変更されてしまった場合でも、パリティが正しくなくなってしまうので、誤りが起こったことが検知できるのです。
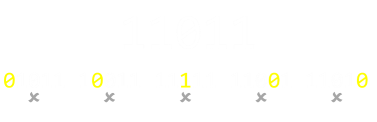
1101 の例を用いて考えるましょう。どのビットであれ、1つのビットを変更すると、パリティ外のビットのうち1となっているビットの個数が変化し、1になっているビットの総数が奇数となってしまいます。これは容易に検知することができます(上の図を参照)。

これは素晴らしく、またとても効率的です。1単語に対して必要なのはたった1ビットです。しかし、ここで小さな問題となるのが、「1単語に対して2個以上の誤りが生じた場合は?」ということです。任意の個別の2ビット(あるいは、2個に限らず、偶数個のビット)に誤りが生じた場合、これらが打ち消しあってしまい、誤りを表すものがなくなってしまいます。
上記の例では、それぞれの5ビットのうち4ビットがデータに使われています。これを、 H(5,4) と表現することにします。
データ単語内のビット数はトレードオフとして調整することができます。データ単語内のビット数を少なくすれば、複数個の誤りが生じる確率は減りますが、送信の効率性も低下します。 H(4,3) では、3つしかデータのビットがないため2つの誤りが起こる確率は低いですが、メッセージの4ビットのうち1ビットがパリティとなるため、帯域の25%をこのメリットのために失うことになります。
H(16,15) にすればデータの効率性という点では断然よくなりますが、前述の2重の誤りが発生する可能性はずっと高くなります。

2番目の数を1番目の数で割ったものを「コード率」と呼びます。コード率が高ければ高いほど、送信の効率性は高くなります。
頭の上にはりんごが2つ
上記で見てきたように、誤りを検知する方法の別の選択肢として、メッセージを複数回送るというものがありました。 1101 を送信する代わりに、各ビットを2回ずつ送ってみる、つまり 11 11 00 11 を送ってみるのはどうでしょう?(空白は見やすさを考慮して付け加えています)これはよく 反復符号 と呼ばれます。
この方法が効率性にどういう意味合いを持つかは無視するとして、このシステムでは何を検知することができるでしょうか?各ビットが複数送信されているので、隣り合った各ペアは一致する必要があります。もしもどれかのビットに誤りが生じたら、それとペアをなすビットと一致しなくなるため、そのペアに誤りが生じたということがわかります。しかしここで問題となるのは、 10 または 01 を信号内に見つけたとして、その元のメッセージが 00 だったか 11 だったかかはわからない、ということです。(更にややこしいケースとして、ペアの 両方 のビットが反転してしまった場合があります。この場合、誤りであることを示すものが何もありません。)
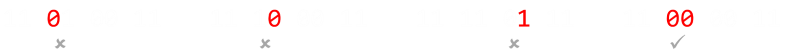
2重に送信することで1つの誤りを検知できるようになりますが、誤りの訂正を行うことはできません(少し考えてみるとわかりますが、ある信号を2重にするということは、全てのビットに対して専用のパリティビットを付与するのと同じです)。つまり、これは H(2,1) と言えます。
頭の上にはりんごが3つ
さらにこれを深化させて、各ビットを3重に送信してみるのはどうでしょう?つまり、 111 111 000 111 ということです。
これは少しだけ助けになります。3つ組のうち1つに誤りが生じた場合、その誤りを検知する(3つ組全てが一致するか否か)だけではなく、それを訂正する(多数決:3つのうち2つが正しいビット、残り一つが誤ったビットと考える)こともできます。
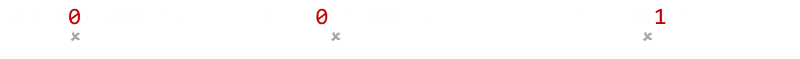
もし同じデータのビットのうち2つに誤りが生じた場合、誤りの痕跡自体は発見できますが、もし訂正もしようとする場合には誤った値に訂正されてしまいます(多数決による)。しかし、少なくとも誤りが生じたことは知ることができます。
同一のデータを表すビット全てに誤りが生じた場合は、偽の(反転した)答えを得ることになってしまいます。
このデータの三重化は H(3,1) と呼べます。
頭の上にはりんごが4つ
さらに反復するビット数を増やして4ビットにしたとして、どのビットについても単一ビットの誤りであれば検知と訂正が可能です。もし2ビットに誤りが生じた場合、検知はできますが訂正はできません(反復したビットが偶数個なので多数決で決まりません)。4ビット中3ビットに誤りがあれば、検出は出来ますが、訂正は誤った方になされます。
さらに増やして5ビットにした場合、2ビットまでの誤りが検知:訂正でき、3,4ビットの誤りが検知できます(正しく訂正はできません)……
こうやっていくと、急速に非効率な方法になっていきます。
ハミング距離
更なる誤り訂正ビットを「違うビットに誤りが生じた場合、違った結果が生じ、誤りが生じたのがどのビットかわかる」という方式で付け加えると、より効率的にできます。これがHammingの発見した方法です。
ここで、 ハミング距離 という概念を導入します。これは、「あるソースがある違うものに変化させられるために、いくつの変更が必要か」というものです。
編集距離の概念と変更は、コンピュータプログラミングにおいて強力な概念であり、スペルチェックや誤字訂正、ファイルのマージといった他の多くの分野で用いられています。
(ハミング距離は、各単語の長さが不変であることを仮定しています。もしビット/文字の追加・削除が許容される場合、これは レーベンシュタイン距離 と呼ばれます。例えば、”kitten”という文字を”sitting”に変えたいとすると、最初の”k”を”s”に変えて”sitten”にしたのち、”e”を”i”に変えて”sittin”、そして最後に”g”を追加する、ということになります。)
有向グラフによって、ハミング距離を容易に可視化することができます。
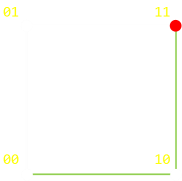
上のグラフは、2重に反復した場合のものです。一般化による損失がないよう、まずは 00 の信号で考え始めていきます。この信号を 11 に変化させるのに必要な 最小 のステップ(誤り)数はいくつでしょう?これがハミング距離です。この場合ではハミング距離は2となります。
ありうる(最短の)経路のうち一つを、上の図の緑の線で示しています。(もちろん、進めたいように前方/後方に進めてもよいのですが、そうするとより多くのステップ数が必要になります!しかし、 00 から 11 へ2ステップ未満で移行する方法はありません。)
誤りを検知できないような信号を生成するには、最低でも2つの誤りが起こる必要があります。
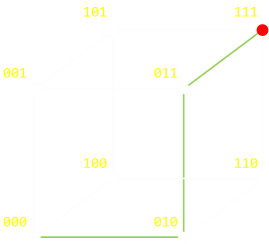
3重に反復した場合、これは立方体として図示することができます。 000 から 111 に変化させるには、少なくとも3ステップが必要になります。
繰り返しますが、ここでは「どのような順序(経路)を取るのか」「『進む』と同様に『戻る』も使うのか」というのは問題になりません。しかし、最小のステップ数は3となります。
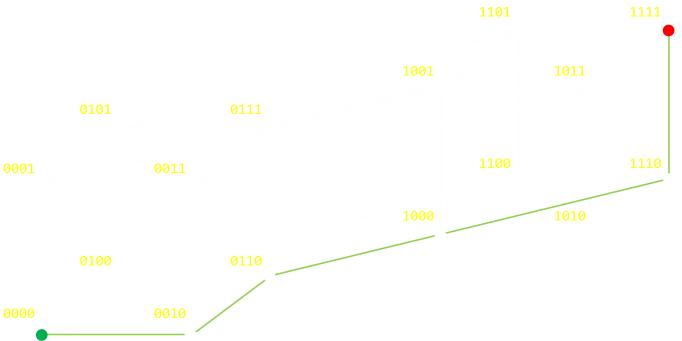
4重の反復で考えると、これの可視化は4次元超立方体(4次元における「立方体」)によって行えます。
ハミング距離(よりギークに)
上述の例では、グラフのある頂点から逆の頂点(全てのビットの反転)へ移るという極端なケースを示しました。ハミング距離は、グラフ上の あらゆる 2つのノードについて有効で、(最小の)ステップ数を説明してくれるものです。ここでのステップ数とは、あるノードから別のノードへの移動に必要なビット反転の最小回数です。以下に2つのランダムな例があります。
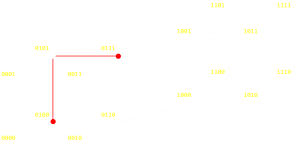 |
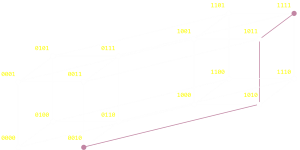 |
もしブーリアン論理に詳しければわかるかと思いますが、ハミング距離を取得する簡単な方法として、2つの値のXORを取ったのちに1となっているビットの数を数えるというやり方があります。(最後のステップはbit population count や sideways sum 、 ハミング重み などと呼ばれることもあります。マイクロプロセッサの中にはこれを基本命令として持つものもあります。)
| 0100 XOR 0111 =
0011 | 0010 XOR 1111 =
1101 |
| (2ステップ) | (3ステップ) |
もし幾何学を勉強したことがあれば、ハミング距離は2つの頂点の マンハッタン (タクシーキャブ)距離と同じです。
誤り訂正に戻ってみる
ここまでで、様々な誤りの検知と訂正アルゴリズムを説明するのに必要な全てのピースが揃いました。それらを「誤りを検知できるハミング距離」「訂正できるハミング距離」と説明することができます。ただのパリティ(シンプルな反復)ではハミング距離が2となり、2ビットが変更されると「誤りが起こったことを検知不可能」という状態になりえます(起こった誤りを検知できないようになるのは、2つの独立した誤りが生じた場合です)。3重にビットを反復した場合、この距離は3となります(そして、信号の送信におけるビット数の効率性はたったの1/3になってしまいます)。
ハミングの研究は、ハミング距離をできるだけ大きくすることに注力されていましたが、同時に送信の効率性を高める(エラー検知用のビット数に対するデータのビット数の比率をできるだけ高める)ことにも注力されていました。
ハミング符号のアルゴリズム
ハミングのアルゴリズムの鍵となるのは、どの単一ビットに誤りが生じたかを独立に検知できるようなパリティビットのセットをどのように生成するか、ということです。
各パリティビットは、マスクのように、アドレス空間を二つの領域に分割することができます(もしビットがセットされていれば、誤りはある半分に、そうでなければもう半分に)。これらのマスクは、2の累乗によって定義できます。(この理論を用いたとても面白くギークなパズルに、コインとチェス盤を用いた The impossible Escape というものがあります。)最初のパリティビットは奇数/偶数番目ビットのパリティに関するデータを集めます。2番目のパリティは2個ずつのグループごとのビットについてデータを集めます(2個について数え、2個スキップし、また2個について数え……)。そして、次のパリティは4個ずつのグループのビットについて……
まずアルゴリズムを説明したのち、それを実験してみましょう。
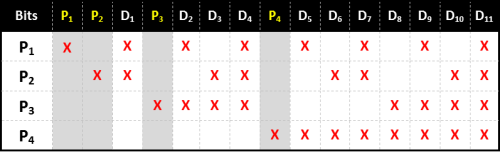
パリティビットはデータのビットの間に挿入され、2の各累乗番目のビットがパリティビットになります。従って、パリティビットの個数は、単語全体をなすデータビットの個数で決定されます。
-
最初のパリティビットは、2進数で表した時の最下位ビットが1となっている(2 ⁰ )全てのデータビット、 つまり 3,5,7,9,11……番目のビットのパリティを表します。(1番目のビットはこのパリティビット自身です)
-
2番目のパリティビットは、最下位から2番目の位のビットが1となっている全てのデータビット(2 ¹ )、 つまり 3,6,7,10,11……番目のビットのパリティを表します。
-
2番目のパリティビットは、最下位から3番目の位のビットが1となっている全てのデータビット(2 ² )、 つまり 5,6,7,12,13,14,15……番目のビットのパリティを表します。
これは以下の表でご覧いただけます。この表では、15ビット(11個のデータビットと4個のパリティビット)までのビット長の単語でのパターンを示しています。このシステムは、どれだけのビット数をエンコードする必要があるかに応じて拡張することが可能です。
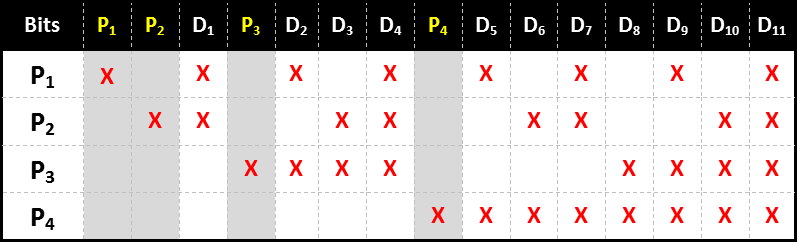
各ビットは独自の(2進数の)パリティビットの組合せを持っています。
誤りをチェックするには、単に各パリティビットをチェックすればよいのです。誤りのパターン(error syndromeと呼ばれます)は、誤りのあったビットを特定します。もし全てのパリティビットが正しければ、どこにも誤りはありません。もしもそうでなかった場合は、誤りのあるパリティビットの位置の和によって、誤りのあったビットを特定することができます。例えば、もし1,2,8番目の位置にあるパリティビット(P ₁ , P ₂ , P ₄ )が「誤りである」と判定した場合、1+2+8=11番目のビット(D ₇ )が誤っている、ということになります。
(もちろん、1つのパリティビットのみが誤りを判定した場合、そのパリティビット自身が誤っているということになります。)
試してみる
4つのデータビットと、それに必要な3つのパリティビットからなる、7ビットの短い単語を以下に示します。データビットをクリックすると、それに合わせてパリティビットが計算されます。これは H(7,4) で、コード率は4/7 ≈ 0.571となります。
| 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| P ₁ | P ₂ | D ₁ | P ₃ | D ₂ | D ₃ | D ₄ |
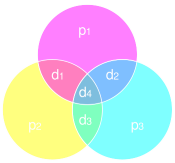
もし集合とベン図に馴染みがあれば、これらのパリティビットとその関係は上の図のようになります。
パリティは、それぞれの円について訂正される必要があり、別個のマッチしないパリティビットの組合せによって桁が特定されます。
11つのデータビットと、それに必要な4つのパリティビットからなる、より長い15ビットの単語を以下に示します。これもインタラクティブになっています。青いパリティビットの四角は他のデータビットから決定されるためクリックすることができません。これは H(15,11) で、コード率は11/15 ≈ 0.733となります。
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| P ₁ | P ₂ | D ₁ | P ₃ | D ₂ | D ₃ | D ₄ | P ₄ | D ₅ | D ₆ | D ₇ | D ₈ | D ₉ | D ₁₀ | D ₁₁ |
誤り訂正
エンコードがどのように機能するのか分かったところで、この知識をデコードと訂正にどう用いるのかを見ていきましょう。もしも単語が無傷のまま送信されれば、全てのパリティが正しいはずです。しかし、もしメッセージが変わってしまうと、パリティがおかしくなってしまいます。各データビットがパリティビットの組合せによって一意に分かることを知っていますので、これを用いることで反転したビットを見つけることができるのです。
以下に示すのは、 H(7,4) でのシミュレーションです。一番上の行は、送信しようとしている純粋なデータを表します(‘Randomize’ボタンで、別のランダムな単語を生成できます)。この行は、ランダムな4ビットの数字を生成し、その数字に対してパリティを正しく計算したものです。
その次の行(赤)は、ノイズのある通信のもう片方で受信された信号を表します。最初はこれは正しくなっていますが、各/全ビットをクリックして状態を変更することで、送信中の誤りを表現することができます。
その下には、検知されたパリティの誤りが示されています。これにより、誤りのあったビットを特定します。
| P ₁ | P ₂ | D ₁ | P ₃ | D ₂ | D ₃ | D ₄ |
| 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| P ₁ = OK | P ₂ = OK | P ₃ = OK |
| 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| P ₁ | P ₂ | D ₁ | P ₃ | D ₂ | D ₃ | D ₄ |
Randomize
一番下の行に、再生成された信号を示しています。訂正されたビットは緑で表示されています。
見て分かるように、もしも受信されたビット列のうち1つにのみ誤りがあった場合、元の信号は問題なく復元されます。これはとても、とてもクールですね。誤りの発生を検知しただけ(これは最小の1つのパリティの時の問題でした)でなく、それを修復することもできました。
赤の行の数字を2つ以上変更することで、2つ以上の誤りが生じたケースを実験することができます。 H(7,4) では単一ビットでも2つのビットでもビットの誤りを検知することができますが、訂正できるのは1つのビットまでです(そして、もし2つ以上の誤りがあるのを訂正しようとすると、信号を誤って訂正してしまいます)。
H(7,4) では、2ビットの誤りを1ビットの誤りと区別することができません。
しかし、これを解決するために適用できるもう一つの綺麗なトリックがあります……
1つの追加パリティビットで……
H(7,4) の単語全体に対して適用される追加の(全体)パリティビットを含める、というものです。これにより H(8,4) となります。
これにより、ハミング距離は3から4に増加し、アルゴリズムが2つのビットの誤りを正しく検知できるようになります。
H(8,4) はよくSECDEDと呼ばれます。これは Single Error Correction, Double Error Detection (単一のエラー訂正、2つのエラー検知)の略です。これは、シームレスにどの単一ビットについても誤りと訂正でき、 また 2つのビットに誤りが生じたことを検知することができます(ただし訂正は出来ません)。 H(7,4) ではこれらのうち片方しかできなかったことを考えると、大きな進歩です。
コンピュータサーバや他のミッションクリティカルなコンピュータのメモリボードには、典型的にはSECDEDに沿ったメモリボードが用いられおり、用いられるSECDEDの仕様の多くが H(72,64) 形式になっています。サーバ向けのDIMMを見てみると、1面に乗っているメモリーチップの個数はおそらく 奇数 個になっていますが、それはここに起因しています。
これらのメモリボードはECC(Error Correcting,誤り訂正)と呼ばれ、奇妙なグリッチに遭遇したとしてもサーバがデータを失わずに済むようになりますし、サーバのメンテナンスをする人のために問題として知らせることもできます。


株式会社リクルート プロダクト統括本部 プロダクト開発統括室 グループマネジャー 株式会社ニジボックス デベロップメント室 室長 Node.js 日本ユーザーグループ代表
- X: @yosuke_furukawa
- Github: yosuke-furukawa
関連記事