2018年12月13日
大規模な決済システムを構築する際に学んだ分散型アーキテクチャの考え方 – 前編
(2018-4-16)by Gergely Orosz
本記事は、原著者の許諾のもとに翻訳・掲載しております。
バックエンドに関する経験があった私は、2年前にモバイルソフトウェアエンジニアとしてUberに入社しました。担当することになった仕事は、決済機能の構築を含む アプリの刷新 です。その後、 技術管理の側に回る ことになり、チームそのものを率いることになります。配下のチームは、決済を行うバックエンドシステムの多くを担当していたため、責任者となった私もバックエンドに触れる機会が以前にも増して多くなりました。
Uberで働く前は、分散型システムの経験はなきに等しかったと言っていいと思います。 それまでの私は、一般的なコンピュータサイエンスの学位を取得後、フルスタックのソフトウェア開発に10年間、関わっていました。分散型システムについては、一応、大まかな仕組みやトレードオフなどは知っていましたが、一貫性や可用性、冪等性などの概念に精通していたとはお世辞にも言えません。
この記事では、大規模で可用性が高い分散型システム(=Uberの決済システム)を構築する際に、私が不可欠だと思った概念のいくつかをまとめていこうと思っています。大規模で可用性が高いとは、1秒間に何千ものリクエストが読み込まれ、たとえその一部がシャットダウンしようとも、核となる決済機能は正しく動作する必要があるようなシステムのことです。なお、今回リストアップするものが分散型システムの概念の全てというわけではもちろんありません。しかし、もっと早くに知っていれば、私の作業はずっと楽だったに違いないといったようなものばかりです。それでは早速、SLAや一貫性、データの持続性、メッセージの永続性、冪等性など、仕事をする上で私が学ぶ必要があったことを見ていきましょう。
SLA
1日に何百万ものイベントを処理するような大規模なシステムでは、不具合が起こることもあります。システムを計画する前に重要なことは、システムにとって”健全”とはどんな状態を意味するのかを決めておくことです。この”健全”さは、 実際に 測定可能なものでなければなりません。そして、それを測定する一般的な方法がサービス水準合意とも言われる SLA です。実際に目にした中で、一般的と思われるSLAの一部を以下に記載します。
- 可用性: サービスが稼動している時間の割合のことです。原則的には100%の可用性を持つシステムを目指すものですが、これを実現するのは難しい上に、コストも高くなります。VISAカードのネットワークやGmail、インターネットプロバイダなど、大規模で多くの人に影響するようなシステムでも可用性は100%ではなく、数年にうちに数秒、数十秒、あるいは数時間程度はダウンしています。多くのシステムにとって高可用性と考えられるのは、99.99%、つまり年間の ダウンタイムが50分程度 といったところでしょう。しかし、このレベルに達するだけでも、通常はかなりの労力が必要とされます。
- 正確性: システム内の一部のデータが不正確であったり消失したりしても問題はないでしょうか? 問題がないとすれば、その割合はどの程度まで許容されるのでしょうか? 私が取り組んでいた決済システムに関して言うと、必要とされる正確性は100%、つまりデータの消失は許されませんでした。
- 許容量: システムはどの程度の負荷をサポートすることが想定されていますか? この指標は、通常1秒あたりのリクエスト数で表されます。
- 応答時間: システムはどの程度の時間で応答すべきでしょうか? リクエストの95%を処理すべき時間、リクエストの99%を処理すべき時間はどのくらいでしょうか? 一般的にシステムにはノイズの多いリクエストが多いため、 95%と99%のパーセンタイル値 が応答時間の指標として現実的で、よく使用されます。
なぜ大規模決済システムを構築する際にSLAが重要だったのでしょうか? Uberにおける私たちの仕事は、新たなシステムを作って既存のシステムを置き換えることです。この新しいシステムが正しいもので、以前のものより”優れた”ものであることを確実にするため、私たちはSLAを使って目標値を定めました。中でも最も重要だった要件は可用性です。いったん目標値を定めたら、達成に向けてアーキテクチャ側にどんなトレードオフが必要なのかを検討しました。
水平スケーリングと垂直スケーリング
新たに構築したシステムを使っている事業が成長した場合、システムにかかる負荷はどんどん増えていくことになります。そしてある時期からは、既存のシステム基盤ではその負荷をサポートできなくなり、許容量を拡張する必要性が生じることになるはずです。その際、最も一般的な拡張戦略として考えられるのが、水平スケーリングと垂直スケーリングです。
水平スケーリングとは、システムにマシン(またはノード)を追加して容量を増やすことを言います。特に水平スケーリングは、多くの場合、ボタンのクリックひとつでクラスタに(仮想)マシンを簡単に追加できるため、分散型システムの拡張には最も一般的とされています。
垂直スケーリングは、基本的には”より強力な大型のマシン(より多くのコア、より多くのプロセッサ、より多くのメモリを備えた(仮想)マシン)を購入する”というものです。分散型システムの場合、水平スケーリングに比べると垂直スケーリングはコストがかかるため、通常はあまり行われません。しかし、Stack Overflowなどのメジャーないくつかのサイトでは、 垂直方向のスケーリングがうまく適用 されています。
なぜ大規模決済システムを構築する際にスケーリング戦略が重要だったのでしょうか? 私たちは早い段階で水平にスケールするシステムの構築を決めました。ケースによっては垂直スケーリングも考えられますが、私たちの決済システムには今、既に想定どおりの負荷がかかっており、超高価な単体のメインフレームを採用しても将来どころか、現時点でも処理できるか疑問でした。さらにチームには大規模の決済プロバイダで働いた経験のあるエンジニアたちがおり、彼らは当時の予算で買える限りの巨大なマシンで垂直スケーリングに挑み、失敗していたという事情もありました。
一貫性
どのようなシステムでも可用性は重要です。分散型システムが可用性の低いマシン上に構築されることはよくあります。私たちの目標は99.999%の可用性を備えたシステムの構築であるとしましょう(ダウンタイム約5分間/年)。現状では、可用性99.9%のマシン、またはノードを使っています(ダウンタイム約8時間/年)。可用性の数字を上げる簡単な方法は、これらのマシン、ノード群をクラスタに追加することです。ノードのいくつかがダウンしても他は稼働しているので、結果としてシステム全体の可用性は個々のコンポーネントの可用性よりも高くなります。
一貫性は、可用性の高いシステムにおける大きな懸念点です。全てのノードが同じデータを同時に参照して返しているなら、そのシステムには一貫性があります。かつてのモデルはより高い可用性に達するべくたくさんのノードを追加していましたが、システムの一貫性を保証することはそれほど簡単ではありません。各ノードに確実に同じ情報を持たせるには、互いに通信し合って同期し続けなければなりません。しかし、相互間の通信に失敗したり、メッセージを消失したりしてノードの一部が使用不可になる可能性があります。
一貫性の概念を学び、十分理解するまでに私はかなりの時間をかけました。 一貫性のモデルにはいくつかあり 、分散型システムで使われる中でも一般的なのは、 強い整合性(strong consistency)、弱い整合性(weak consistency) 、そして 結果整合性(eventual consistency) です。Hackernoonに掲載された 結果整合性対強い整合性 の比較記事を読むと、これらのモデル間のトレードオフを実際的に概観できます。基本的には、求められる一貫性が弱いほど、システムは速くなりますが、直近のデータセットを返す確率が下がります。
なぜ大規模決済システムを構築する際に一貫性が重要だったのでしょうか? システム内のデータには一貫性がなくてはなりません。しかし、どの程度一貫していればよいのでしょう。システムのある部分には、強い整合性を備えたデータ以外の選択肢はありません。例えば、決済が開始されたかどうかの認識は、強い整合性を備えた方法で保存するべきものでしょう。別の部分はそこまで基幹に関わらず、結果整合性も合理的なトレードオフとして検討できるかもしれません。良い例は「最近の決済履歴」リストです。これは結果整合性で実装してもよいでしょう(つまり、直近の決済履歴はしばらく経ってから表示されることになります。代わりに、より低いレイテンシ、またはリソースを集約させて演算できます)。
データの持続性
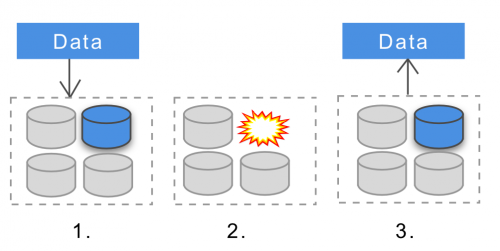
持続性 とは、一度正しく保存されたデータは、以後ずっと利用できるということです。たとえ、システム内のノードがオフラインになったり、クラッシュしたり、そのデータが壊れたりしても変わりません。
分散型データベースによって、持続性のレベルは異なります。マシンまたはノードレベル、クラスタレベルの持続性をサポートするものもあれば、設定が必要なものもあります。通常、持続性を高めるためにある種の反復が用いられます。データが複数のノードに保存された場合、1つか2つのノードがダウンした場合でもデータは利用可能です。分散型システムにおいて持続性を獲得するのが難しい理由に関しては、 ここに良い記事があります 。

なぜ大規模決済システムを構築する際に持続性が重要だったのでしょうか? 決済のような重大なシステムでは、多くの部分で、データの消失は許されません。私たちが構築した分散型データストアは、クラスタレベルのデータ持続性をサポートするために必要でした。たとえ、インスタンスがクラッシュしても、完了した取引は維持しなければならないからです。最近では、Cassandra、MongoDB、HDFS、あるいはDynamodbといった代表的な分散型データストレージサービスは全て様々なレベルにおける持続性をサポートしており、クラスタレベルの持続性を持たせる設定も可能です。

株式会社リクルート プロダクト統括本部 プロダクト開発統括室 グループマネジャー 株式会社ニジボックス デベロップメント室 室長 Node.js 日本ユーザーグループ代表
- X: @yosuke_furukawa
- Github: yosuke-furukawa
