2017年2月6日
エンコード方式 base-122
(2016-11-26)by Kevin Albertson
本記事は、原著者の許諾のもとに翻訳・掲載しております。
base-64よりもスペース効率の良い方法。 GitHub レポジトリ
1 概要
バイナリをテキストに変換するエンコード方式としての base-64 は、そのデータ量を33%増大させます。この記事では、UTF-8のテキスト変換方式であり、元のデータから14%増大するbase-122を紹介します。base22はWebを念頭において作られました。 実装 には、Javascriptのデコーダを使い、base-122でエンコードしたリソースをWebページに読み込ませる過程が含まれます。
免責事項
3で示すように、base-122は 大半のWebページが該当します gzip圧縮ページでの使用は推奨しません。ですが、base-122は一般的な文字エンコード方式として役に立つ可能性があります。
1.1 はじめに
画像、フォント、オーディオなどの外部のバイナリリソースは、base-64でエンコードする データURI を使ってHTMLに埋め込むことができます。データURIは通常、小さなイメージを埋め込む際に、HTTPリクエストを避け、ロード時間を減らすために使われます。
このソースでは”example.png”を取得するのに余分なHTTPリクエストを要します。
<img src="example.png" />base-64変換で同じ画像を埋め込む場合。
<img src="data:image/png;base64,iVBORw0KGgoAAAANSUhEUgAAAGYAAABmCAMAAAAOARRQAAAAkFBMVEX////MAADLAAD//Pz+9/f66en+9vb/+vrPAAD88PD21tb439/109P65OT32tr87e3yxMTWRkbSLy/YT0/pnZ3rp6fxv7/QJSXkf3/genrmlZXwurrPHh7eYmLzycnebW3jhYXODg7tsbHaVFTVPT3kjY3PFBTfc3PVPz/WSkrcXl7bZWXSIiLssrLooaHWNTXt35LZAAAGB0lEQVRoge1a55aiShCGIhgIoiIoMkgQMfv+b3erqkG5s3Nm5yzl/to6Z5wGtT8qh1bT/tE/egOZs78AcqubSx167wWxqgKQ9EXyThR/Dzqh4MvSfxuKt0SU+FLpBPTI5Da26+h1YeSIsvNn3vZIOAtXDGUDcfC8GuHeFa+8E+GcpVB2JKSncFZ4pYzZnyNMJYSiTT7ooefT9nINcOBFQMysDSkYzTozjt/B6GP6H8XI1sYUQ0Gx7Qnn5HcwgJwFB7KE9gM3SwTHexDOkY2qxO1PxjbFO033NlwmIjjTOeM4uLRwVTSEux6pN40dQD6SwWEnqWzclBHxL7Tb97YHHRIhU3AWtPsFTTnCBS5X3TvuAuAoFnQ8toOLpdlrwhm7rZhcsoWtFAo/teLHYQHqeYbW7JRXRKnlUFAHMePYmj8mfjB8bpoT4sFZRv8dRQfGmWjOQeUBSgcAOxlrnviuO+VMGV2JjbWpTfJFiwGPu4yRlTt89vExIWPaLhgHV1myPBR6WoUyicDO2UnwZb8yOv0Qjub5SDJRRjPWCoNfKFCuOGkKBmamFe2fVnudgZaIEyoc+/ff/TlZ5JO7yHNXc8bJ0ahCMmfIJWE8YEdBmp05xlCISZi1UAzE1O5oY50acmKiIMMiuYFeCqFE19sKXtIZ5XpXbSRyTqmtHjC+ADjPGyw3YBPOxVB8tmJd723nF3obJieRkMNoWsW2VfQtt0adzKX2b2m0I2bG/erVxhuxMExboKW9oGWgG4nDaBYXNI8XjhEDLMR2v58eu4AKvREnzPQpN/LWDyGUgFMJ7CjDWGQHsGyN2kYpQvDtl39MWaEMWbVInsLhpOZs5JiZLdtWrN3cYrmdLWu72ZOihCqlkFqj/EK1K3xQgzEqurSPdHZ+u8GPaIKF6pEqcS6SPigEuHslRb2Y11JdOrZGBdeTGVcxDcWUjHGKMpPrZ7FL3qtwFXCN1DA/vMyFErM9m03cI3RtXsD8nElODqtqJyKyYJcW18sDLt2NSFWZxIR7fLI2jMz7uLWmJ4wWsZElVLpGzE8zuNAo9dae+h14wPe4dylZP0N7zSl5YUza0NNeF6GqMlb+thDAuVMrGWwvtFX8wjFC6l6OLKuSW+dB6jEr4I7P+owzCvXn/KdMuU77Y5oZJlbjPF+wOJXpvZSZxM8As6qHuI67P6BjjNUFjU4whPX0I+SVQYpNyvVZSthqdiI2WOqInbCXSCzmR643bslVneQrX6lUdhWrxFqaqoz/8nBnyfY2/eY7f0IqkvRcwuEZwFwoh3VkbOETjjsHNdKQoElZRyp43BinfvX30zm7qwBZa0rx45L9ggdX/WmFvxYB0Zy5GvG0w6NbShehcOuq+ad2XoWBnmW15bUwDpWTcFheXwmFmz4RHPO1BRWQG7SkunjpPik+6efPKMuf3S+mRWho71HIOuEzBTPhcDCsdbUTDF7doy4BYuUVs+rZiCsciId4pV/xwOjOFze9G+iZdWsHioccTXwIN0FBIPFOxXcsWbg+pnMFiJuU2nzkx/S0+rD6dp/viaIwFOtnb3JXUqKSooi0nEuaMKgXwSwbYGlTOtiJ3V5VsmUFeMjHrc2YWNJgxzckjJlkvl/NCzbdnPrctk7Nr5/5OWF13zZcn+4v4KrkWHLvBPshKHTkot+/uH8HOCnrvWDrdF7Wg47+RjXo1+jX+zaaWcWp2Ehh7s28YXFmhNEq7Z+OGSMkTDcN6pwrMsRbDz6JMWjUsmkf1fLd/GNRpMvQ58O4czaz0EV1gfF7yfW26zlZGZ6vXbu6iHiQebic9KeOBtGUhiL6Yzl/tL24st5Drc5IoIudQylUebKFgHYFRbJoR79CGTnvmCCAR9VszgdVwpIMx3Ops2XjrgYxcKiSW4ZGPCu5BrTsoCy3gvWYl93DsJw6VuccWdE/Unof0eGskE6+I/Kmtx74K2oQRryL+ZWoHBc9UPiScunzhK/ITGhu9ubffGhegyVI8WZztpPjO46U/kem01BpBvp7fWaqOtr9uwPAluLnx/s9psQW7f0Og3Ym+QuMfzSA/gP09FnS+GSFqAAAAABJRU5ErkJggg==" />データURIの埋め込みを使えば、サーバから”example.png”を取得するための余分なHTTPリクエストを避けられます。場合によってロード時間の改善につながりますが、データURIは慎重に使用するよう勧められています。小さな画像には役立つとはいえ、逆にパフォーマンスを下げる可能性もあるからです。
base-122がbase-64よりも改良されている点を論じる前に、base-64とは何かを簡単に説明しましょう。 Wikipedia でより詳しく紹介されていますが、ここでは主な点を見ていきます。
1.2 エンコード方式 base-64
base-64は バイナリのテキスト変換 に伴う、一般的な問題を解決するひとつの方法です。例えば、1バイト 01101001をテキストファイルに埋め込みたいとします。テキストファイルは文字のみで成り立つので、このバイトを文字で表す必要があります。このバイトをシンプルに変換する方法は、”A”は0ビット、”B”は1ビット、といった要領で、それぞれのビットを文字に当てはめることです。例えば、次のようなエンコード方式が存在し、1バイト 01101001が1つの(非常に小さな)画像を表すとしましょう。それに対応するHTML上のデータURLは次のように見えます。
バイナリのテキスト変換のダミー
<img src="data:image/png;sillyEncoding,ABBABAAB" />容易にデコードできるのは確実ですが、スペースの無駄というコストがかかります。”A”や”B”などそれぞれの文字はHTMLファイル上では1バイトです。つまり、1ビットのバイナリデータを8ビットのテキストデータで変換するので、データは8:1の率で増えます。
base-64方式は上記のエンコーディング例の改良版です。6ビットの塊(0から63の数字で表す)を64文字のいずれか1つに位置づけます。その結果出てくる文字はそれぞれ1バイトなので、増加率は8:6です。
同じバイトをbase-64で変換した場合。追加の==は余白です。
<img src="data:image/png;base64,aQ==" />base-64はバイナリのテキスト変換に有用なのは、標準のASCII文字を生成するからです。しかし、base-64を改良するためには、UTF-8文字にどれだけのデータを詰め込めるかを調べる必要があるでしょう。
1.3 文字コードとUTF-8
大半のWebページはUTF-8でエンコーディングされているので、base-122はUTF-8の文字変換方法のプロパティを利用します。ここで、UTF-8と文字コードに関する用語を明確にしましょう。

注釈:<左から>16進数 2進数(バイナリ) 2進数(バイナリ)
<黒帯部分>Unicodeコードポイント UTF-8エンコーディング レンダリングされる文字
図1:εの3種類の表し方
コードポイント は、(通常)1つの文字を表す1つの数字です。Unicodeは、標準的な複数言語のアルファベットから、コードポイント0x2615のコーヒーカップの絵文字(U+2615と表記されることが多い)など、より曖昧な文字まで記述可能な範囲を広く受け入れられる基準です。 このUnicode表 でコードポイントを参照できます。
一方で、 文字コード にはバイナリでコードポイントをどのように表示するかを決める役割があります(例:ファイル内など)。UTF-8はWebにおいて 圧倒的によく使われている テキストエンコード方式です。可変長のエンコード方式で、1,112,064種類のコードポイントを表現できます。ASCII文字を表すコードポイントは、UTF-8ではたった1バイトで変換できますが、より高いコードポイントでは最大4バイト必要です。以下の表1は、様々なコードポイントの領域におけるUTF-8エンコード方式のフォーマットをまとめたものです。
| コードポイントの範囲 | UTF-8 フォーマット (xはコードポイント) | トータルのビット | コードポイントのビット |
|---|---|---|---|
| 0x00 – 0x7F | 0xxxxxxx | 8 | 7 |
| 0x80 – 0x7FF | 110xxxxx 10xxxxxx | 16 | 11 |
| 0x800 – 0xFFFF | 1110xxxx 10xxxxxx 10xxxxxx | 24 | 16 |
| 0x10000 – 0x10FFFF | 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx | 32 | 21 |
表 1: UTF-8エンコード方式のまとめ。xは、コードポイントデータのためのビットを表す。
増加率は、文字のビット数に対するコードポイントのビット数の比率です。比率が1:1であれば効率的に全く無駄がないということです。バイト数が増えるにつれ、コードポイントのためのビットが減るので、増加率は悪化します。
2 base-64の改良
表1でUTF-8の1バイト文字のエンコーディングを見ると、図2のように、1エンコードバイトで7ビットの入力データを変換できることが分かります。

図2:バイトごとに7ビットを変換する試み
図2のエンコード方式がうまくいけば、base-64の8:6の増加率は、8:7に改善されることになります。しかし、このバイナリのテキスト変換を、HTMLページのコンテキストで使いたいのです。残念ながら、1バイトのUTF-8文字はHTML上でコンフリクトを起こすため、このエンコード方式は役に立ちません。
2.1 不正文字の回避
上記のアプローチの問題はHTMLページのコンテキストでは安全に使えない文字があることです。ここでは、コードをデータURIに似たフォーマットで格納します。
<img src="data:image/png;ourEncoding,(Encoded data)" />この変換データはダブルクォートを含めることができません。またはブラウザが適切にsrc属性を解析しないことがすぐに分かります。さらに、改行文字、復帰文字は行を分割します。バックスラッシュとアンパサンドは不意にエスケープシーケンスを生成することもあります。また、表示不可のnull文字( コードポイント0x00 )も、 エラー文字 (0xFFFD)として解析されるのも問題でしょう。よって、null、バックスラッシュ、アンパサンド、改行文字、復帰文字、そしてダブルクォートは1バイトのUTF-8文字の中では不正と判断されるのです。結局、122の正規の1バイトUTF-8文字を使うしかないというわけです。122文字は7ビットの入力データをほぼ変換できます。7ビットのシーケンスが不正文字の原因になるなら、補強をする必要があります。これが最後のエンコード方式に至った理由です。
2.2 エンコード方式 base-122
エンコード方式 base-122は、一度に7ビットの入力データのチャンクを処理します。チャンクが正規の文字に位置づけられる場合、1バイトのUTF-8文字: 0xxxxxxx で変換されます。チャンクが不正の文字に当たる場合は、代わりに2バイトのUTF-8文字: 110xxxxx 10xxxxxx を使います。正規のコードポイントは6つのみのため、たった3ビットで識別できます。これらのビットを sss として表すと、フォーマット: 110sssxx 10xxxxxx になります。残りの8ビットはより多くの入力データを変換できるように見えます。しかし、0x80以下のコードポイントを表す2バイトのUTF-8文字は無効です。ブラウザは無効のUTF-8文字をエラー文字とみなします。コードポイントが常に0x80より大きくなるよう制御するには、0x80のビット単位OR(これはさらに改良できる可能性があります。4を見てください)と同等のフォーマット 110sss1x 10xxxxxx を使うと簡単です。図3はbase-122のエンコーディングのまとめです。

図3: base122のエンコーディング。nullコードポイントは000に位置づけられる。
これは14ビットの変換に、1バイト文字変換の7ビットと2バイト文字を使います。よって、1バイトにつき7ビット変換する目標を達成しています。つまり、8:7の増加率です。結果として、base-122で変換した文字列は、base-64で行った場合の86%のサイズです。
2.2.1 最終文字に関する覚書
入力データの最後の7ビットチャンクは、必要な場合はゼロビットで埋め込まれます。そのため、最後の1バイト文字は、6個のパディングゼロビットを持つ可能性があります。デコーディングでは概数になるので、これらの6個のパディングビットはデコーディング中に適宜切り捨てられます。しかし、もし2バイト文字で終える場合は、13ものパディングビットを持つことになります。この解決には、最後の2バイト文字が7ビット以上を変換したかどうか区別するのに 役立ち ます。
2.3 実装
base-122によるエンコーディングとデコーディング機能の実装は GitHubで 入手できます。これには2つの主な機能があります。
- ファイルのbase-64の文字列をNodeJSスクリプトでbase-122に再変換する
- base-122の文字列を、クライアントサイドのJavascript関数で元データにデコードする
2.3.1 base-122に変換する
base-122が変換した文字列にはコピー&ペーストができないように見える文字が含まれています。ユーザのコピー&ペーストを禁止するため、NodeJSスクリプトはHTMLファイル内でbase-64のデータURIを再変換します。図4はその一例です。
<html>
<head><meta charset="utf-8"></head>
<body>
<img src="data:image/jpeg;base64,/9j/4AAQSkZJRgABAQAAAQABAAD/2wBDAAYEBQYFBAYGBQYHBwYIChAKCgkJChQODwwQFxQYGBcUFhYaHSUfGhsjHBYWICwgIyYnKSopGR8tMC0oMCUoKSj/2wBDAQcHBwoIChMKChMoGhYaKCgoKCgoKCgoKCgoKCgoKCgoKCgoKCgoKCgoKCgoKCgoKCgoKCgoKCgoKCgoKCgoKCj/wgARCABAAEADASIAAhEBAxEB/8QAGwAAAwEAAwEAAAAAAAAAAAAAAgQFAwABBwb/xAAUAQEAAAAAAAAAAAAAAAAAAAAA/9oADAMBAAIQAxAAAAH03tUhvpURrqbmVwmEeVUx0H1F2Roebiab6BzCQ6POQ6gzmpWJFN2efDMTTGt09ivuahWOcZ//xAAgEAACAgICAgMAAAAAAAAAAAACAwABBBIREwUhFCIz/9oACAEBAAEFAuZzOZtN5vOam1TebzeWdVLyVwstNT5C53hKe+yU4jhbBLaXNjc1Hc7UNtMBmwLFTrMbd1iqylWUMhKmLW2XhDSlsHqr8R0ZPsoBtV3m8ioHtqZJEsBIqAW0MLIKonPyahPPKbqfYPuZgbFbIJ+jZtEHrGEZUlrKYfkmnBzN7KDfFbXUWVXaLX1NNQ3ju1jyQVf/xAAUEQEAAAAAAAAAAAAAAAAAAABA/9oACAEDAQE/AQf/xAAUEQEAAAAAAAAAAAAAAAAAAABA/9oACAECAQE/AQf/xAAsEAABAwMBBgQHAAAAAAAAAAABAAIREiExIgMQMkFRYRMjcZEwM2JygaGx/9oACAEBAAY/Avh3IXEuML5jfdcbfdaSVTS6vsgCdR5SuDaInH7WpsrWtBYV3hOIAkWEqk88TdAsNzzRL3ymm0fSpo9iqnNv6oUCrrIVUGG80Bl56Knwtp+VFLgSmDZVZWb/AGoPrZULwolCaqVo8v8Aq5PHogTFkzAMY6q7VgkbsbrWKY5oLR1Q2wN22QqvCii/ffjc1xyOq8qpqccg8iFbZmexX//EACAQAQACAgIDAQEBAAAAAAAAAAEAESExQVFhcYGRsdH/2gAIAQEAAT8h9oZbhLTiUlGPdGB6z5nxBLAeYFyZQ3n6l+f0pDh/NK0rwxK1rQpfogwUsKBB4xuIVrwigcS/cKAR6OI+4HNLxC2qtGdwGnnFs1+7bBOEJo8RiNR5qp5k2Fe4XVBzsjTOZOsHvZS0S9OGY/2WK3EAf7N1+1D11K9DTPwmgZj24uz/AGOLEpiR06hoZXlZsO5hd2dZRrKb2x8mS4K8dxLf7Xv6gwyByZl6DHHEQTuWrCMi/UVt6NVKih0ZYZ7DcNqosWwa6wduYXEbQ/kAZhDgxNwN2xFDY5Bx8i4Jv7EGp881VP/aAAwDAQACAAMAAAAQ48AQocYogYQw8wks/8QAFBEBAAAAAAAAAAAAAAAAAAAAQP/aAAgBAwEBPxAH/8QAFBEBAAAAAAAAAAAAAAAAAAAAQP/aAAgBAgEBPxAH/8QAJRABAQACAgICAQQDAAAAAAAAAREAITFBYYFRcZGhscHREOHx/9oACAEBAAE/ELXZc5C3B8rg9jiIrT1gqA+9YM4XPkfp/jCyt7GedtKYiNPuMzaAqAFcBgEWaP3Y82fpv5whWuuBytDmRuXOodKOZTd+cb421wPG/wCckzcw6PnVMAggjWBDYTduP4psU/V4xRdiqKuqcv4zpLF83etTHZmwLtUSPZ3h6mQYg7Nt/wCYYTQmjRuF47wmlq5ke9bywDAyijpL8T8ZydQaKhCiz6wvlGERWU71Mh634Rny6Uxvdh3g54jxOJiS6hxfT9uLhawWowu4NemJ0Q0KV5xM5HoALv8AP7YdFuGrfsFycbgcpu70/wCsKDqCtvxmpUb6gpX43MlhCAz0bV4MvigFhHsN45XDAiKpn0frhHC7geRAqyHPjKoI9gNehx2EggXT1j+pyGfGRQHGr7x0r0msWFcV3P7/ALxYepTu6buzrG4wB2SS66DHNZ46PL9HNyZBMRKNh+MLGqbwJSF57YAIeU3idMCqa5xThyDanSX6zbFXkT8rkPDcLTjx+22H35xRJaj+kRz/2Q==" />
</body>
</html>図4a: 元ファイル
<html><body>
<head><meta charset="utf-8"></head>
<body>
<img data-b122="v¬~ J#(` m@0 @0Ɔ A``@( ƅ!PP q `0ƅBaPtJ¬ʆd1`X, 21R*F#ri@Z(%I#[`8ƄB0P(ҨʅCρ P(ƅA P(ƅA P(ƅA P(ƅA P(ƅA P(ƅA P(ƅG BÈ@D @?| ¶à A`o~À 4à S=UoRQʺMf+B0GJTcP>Q;Py֦Mz LGN!j9TVngOCMk:=E>s(+8g| À@ ΰ) (Ι{ Pf9MS<oj6Tofy3U%r+BeS)yg<O>dSD8-Ai9Xn5sZC6L 1)kmnXU2JY!H%Җ[2x!RK0=*~hd}Jí+^7HT[)I(m
*DsyB<yӵ¬0>s˅6 Ohlm XaTK,Srӎ^e >Zu
.hZ}Ӎ!^m1r U| ¨À~hÀ`|q D ?{ À'p-D Á@@8 DD H
ң8d҃ePl?}PÀãx
pw֥cyF}kFo]4I*4]/YT<R֍Q c{-ӥ5VA0W<DÈX%) <ӴC9sί>)S4>JM1*N6*ƂW,BU yP^=ǏBm-JE`lU2Y_p (¬-JBx(J U%4<_p.'GQY@cU.j`Hnc:kƱfA4:Pm@nmH*^Ɣ/o_Fs.G*y*M' y+63 b_qÀÀ ÀEQ0ְˇ#m ¬H>h2n 4qJ{Q@zgf>%@<`.Ҩ7Oj/gz)yRZ+aDVZh)?ΆƂFDWB ?8( G}`9RxBm*hg8O-M?;6 pB4<#j 5)s0W֗*HiN2:`{lRhKiaL?lXVqv7/m!uj+h4gpML=֮g|ãEDS NPh2^+9Bw3V(ko6-p+c֥_v^(2 IL^AG;K+ 2uǭt5)(Pt2aO0n˕Ϣlʺ`vsb!~ 0CADn ;1ƍG8|E`M~bSsfU'4àPqEas K¬| ¨À~hÀ` | q D ?{ À'qD À Ҕ
Q8d4ΐp|?}PÀxBkY9dp>+AvΕSkP^Xa9yi+=F<viґʟ8f6@*`4?;¬S?N+.ևPsלu%2Mog˸mWq_p rҷ:¬)@FX6 ]ֿEƿ+cƗ1*:SK|3R,/Mo-ҝLlm(H{pzLADfm@ PMʍa<;a-.2 zoà2EI? |3IjE!
¬,eǥuV~geiқnao OxN (8_'vq8-0-#n^L'sDgt?` }X:pjol
Ic8)]o'|,P+7qM%#>P)/c9I0BO#5<_ƀX#lcJp`ΕҾGua
ևH@UH9xe(vWPql iuGzN!OFπ8j}qi/$k
8W9~@ECj)ntnv:c8`2$]:k t9ADQX?S< R
g[ )^S*5gƸ9 5~Y[Ǟοd ˡ4qq}[0}|qΥT?Rg2" />
</body>
</html>図4b: 再変換したファイル
少しの差分では意味がありません。CSSデータURIではなく、src属性の中のデータURIだけが再変換されます。UTF-8文字セットのメタタグを指定しなければなりません。data-b122属性はデコード中にDOMの簡単なクエリ実行に使われます。デフォルトのMIMEタイプは”image/jpeg”ですが、data-b122m属性は他のMIMEタイプを特定します。
2.3.2 BLOBにデコードする
base-122変換リソースをデコードするには、 atob 関数を使い、base-122文字列を元データにデコードする必要があります。さらに、いくつか設定コード(DOMにクエリを実行し、 createObjectURL でデコードしたBLOB URLを生成する、など)をHTMLページ内のスクリプトを含めるとなると、外部スクリプト(別のHTTTPリクエスト)を追加するか、全関数をページ内に書くことになります。しかしそれでは、base-122のエンコーディングの省スペースを損ねてしまいます。よってデコード関数はパフォーマンスを犠牲にせずに、なるべく小さくしなければなりません。縮小したデコードスクリプトは下記で、現状のサイズは487バイトです。
全ての要素をdata-b122属性でデコードし、BLOB URIを生成する。
!function(){function t(t){function e(t){t<<=1,l|=t>>>d,d+=7,d>=8&&(c[o++]=l,d-=8,l=t<<7-d&255)}for(var n=t.dataset.b122,a=t.dataset.b122m||"image/jpeg",r=[0,10,13,34,38,92],c=new Uint8Array(1.75*n.length|0),o=0,l=0,d=0,g=n.charCodeAt(0),h=1;h<n.length;h++){var i=n.charCodeAt(h);i>127?(e(r[i>>>8&7]),h==n.length-1&&64&g||e(127&i)):e(i)}t.src=URL.createObjectURL(new Blob([new Uint8Array(c,0,o)],{type:a}))}for(var e=document.querySelectorAll("[data-b122]"),n=0;n<e.length;n++)t(e[n])}();図4cはデコーディング、設定コードを含めた最終ファイルです。
<html><body>
<head><meta charset="utf-8"></head>
<body>
<img data-b122="v¬~ J#(` m@0 @0Ɔ A``@( ƅ!PP q `0ƅBaPtJ¬ʆd1`X, 21R*F#ri@Z(%I#[`8ƄB0P(ҨʅCρ P(ƅA P(ƅA P(ƅA P(ƅA P(ƅA P(ƅA P(ƅG BÈ@D @?| ¶à A`o~À 4à S=UoRQʺMf+B0GJTcP>Q;Py֦Mz LGN!j9TVngOCMk:=E>s(+8g| À@ ΰ) (Ι{ Pf9MS<oj6Tofy3U%r+BeS)yg<O>dSD8-Ai9Xn5sZC6L 1)kmnXU2JY!H%Җ[2x!RK0=*~hd}Jí+^7HT[)I(m
*DsyB<yӵ¬0>s˅6 Ohlm XaTK,Srӎ^e >Zu
.hZ}Ӎ!^m1r U| ¨À~hÀ`|q D ?{ À'p-D Á@@8 DD H
ң8d҃ePl?}PÀãx
pw֥cyF}kFo]4I*4]/YT<R֍Q c{-ӥ5VA0W<DÈX%) <ӴC9sί>)S4>JM1*N6*ƂW,BU yP^=ǏBm¬JE`lU2Y_p (¬-JBx(J U%4<_p.'GQY@cU.j`Hnc:kƱfA4:Pm@nmH*^Ɣ/o_Fs.G*y*M' y+63 b_qÀÀ ÀEQ0ְˇ#m ¬H>h2n 4qJ{Q@zgf>%@<`.Ҩ7Oj/gz)yRZ+aDVZh)?ΆƂFDWB?8( G}`9RxBm*hg8O-M?;6 pB4<#j 5)s0W֗*HiN2:`{lRhKiaL?lXVqv7/m!uj+h4gpML=֮g|ãEDS NPh2^+9Bw3V(ko6-p+c֥_v^(2 IL^AG;K+ 2uǭt5)(Pt2aO0n˕Ϣlʺ`vsb!~ 0CADn ;1ƍG8|E`M~bSsfU'4àPqEas K¬| ¨À~hÀ` | q D ?{ À'qD À Ҕ
Q8d4ΐp|?}PÀxBkY9dp>+AvΕSkP^Xa9yi+=F<viґʟ8f6@*`4?;-S?N+.ևPsלu%2Mog˸mWq_p rҷ:¬)@FX6 ]ֿEƿ+cƗ1*:SK|3R,/Mo-ҝLlm(H{pzLADfm@PMʍa<;a-.2 zoà2EI? |3IjE!
¬,eǥuV~geiқnao OxN (8_'vq8-0-#n^L'sDgt?` }X:pjol
Ic8)]o'|,P+7qM%#>P)/c9I0BO#5<_ƀX#lcJp`ΕҾGua
ևH@UH9xe(vWPql iuGzN!OFπ8j}qi/$k
8W9~@ECj)ntnv:c8`2$]:k t9ADQX?S< R
g[ )^S*5gƸ9 5~Y[Ǟοd ˡ4qq}[0}|qΥT?Rg2" />
<script>
!function(){function t(t){function e(t){t<<=1,l|=t>>>d,d+=7,d>=8&&(c[o++]=l,d-=8,l=t<<7-d&255)}for(var n=t.dataset.b122,a=t.dataset.b122m||"image/jpeg",r=[0,10,13,34,38,92],c=new Uint8Array(1.75*n.length|0),o=0,l=0,d=0,g=n.charCodeAt(0),h=1;h<n.length;h++){var i=n.charCodeAt(h);i>127?(e(r[i>>>8&7]),h==n.length-1&&64&g||e(127&i)):e(i)}t.src=URL.createObjectURL(new Blob([new Uint8Array(c,0,o)],{type:a}))}for(var e=document.querySelectorAll("[data-b122]"),n=0;n<e.length;n++)t(e[n])}();
</script>
</body>
</html>図4c: デコーディング、設定コードを含めた最終ファイル
3. 実験結果
base-122が、base-64のWebにおけるエンコード方式の実用的な代替手段になるかどうか検討するため、実装をテストし、省スペースであることを確かめ、ランタイムの実績をチェックしました。
3.1 省ストレージ
エンコード方式 base-122は、1バイトにつき7ビットの入力データを変換します。base-64は6ビットです。ですから、同等のbase064のデータと比べ、base-122のデータは14%小さくなるはずです。様々なサイズの四角の画像で行なった最初のテストでそれを確認できます。
| Image (JPEG) Dimension | Original (bytes) | Base-64 (bytes) | Base-122 (bytes) | % difference |
|---|---|---|---|---|
| 32×32 | 968 | 1292 | 1108 | -14.24% |
| 64×64 | 1701 | 2268 | 1945 | -14.24% |
| 128×128 | 3027 | 4036 | 3461 | -14.25% |
| 256×256 | 7459 | 9948 | 8526 | -14.3% |
表の項目の見出し(左から):画像(JPEG)サイズ オリジナル(バイト) base-64(バイト) base-122(バイト) %差分
図2: base-64とbase-122の画像サイズを比較
しかし、 以前の記事 で指摘したように、HTMLページを圧縮したgzipはbase-64のエンコーディングのサイズを劇的に減らします。表3はgzipデフレ―ト圧縮を適用した変換結果です。
| Image (JPEG) Dimension | Original (bytes) | Base-64 gzip (bytes) | Base-122 gzip (bytes) | % difference |
|---|---|---|---|---|
| 32×32 | 968 | 819 | 926 | +13.06% |
| 64×64 | 1701 | 1572 | 1719 | +9.35% |
| 128×128 | 3027 | 2914 | 3120 | +7.06% |
| 256×256 | 7459 | 7351 | 7728 | +5.12% |
図3:gzipを適用したbase-64とbase-122の画像サイズを比較
あいにく、base-64のほうがbase-122よりも圧縮の効果が高いようです。おそらく、base-64には冗長なシーケンスのビットが比較的多いために圧縮も簡単なのでしょう。興味深いのは、gzipでbase-64を使うと、元のサイズよりも小さくなることです。
3.2 パフォーマンス
base-122デコーダを実際に使うにあたっての懸念はパフォーマンスです。ブラウザでbase-122をデコードするとパフォーマンスが大きく落ちてしまうと、ダウンロードサイズの小ささでロード時間を減らせる利点をしのいでしまいます。 このJSPerfテスト を使って、同等に変換したランダムな10,000バイトのバイナリの文字列で、base-122のデコーディング関数をbase-64のデコーディング関数である atob と比較しました。
| Browser/OS | Base-64 Ops/Sec | Base-122 Ops/Sec |
|---|---|---|
| Chrome 54/Win. 10 | 9,141 | 3,529 |
| Firefox 50/Win. 10 | 2,342 | 5,338 |
図4: デコーディングのランタイム実績を比較
Chromeでは、約3倍パフォーマンスが落ちます。驚くべきことにFirefoxでは1.5倍から2倍向上しています。
3.3 ケーススタディ
実用テストとして、様々なサイズの小さな画像が載ったHTMLページのロード時間とサイズを比較しました。 unsplash.it から取った64×64ピクセルの画像を使い、10点、100点、1,000点の画像を載せたページで比較しました。
図5: ケーススタディ用のページ
まず、各ページのダウンロードサイズが予測どおりであることを確認しました。
![]()
注釈:転送サイズ率 転送サイズ率(Gzipを有効にした場合)
図6: 転送サイズと元サイズの比率
次にロード時間を5回試し、ChromeとFirefoxの中央値を記録しました。
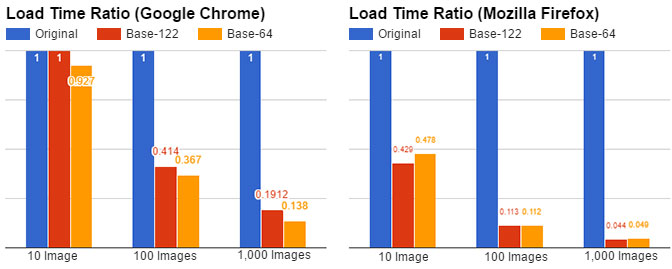
注釈:ロード時間率(Google Chrome) ロード時間率(Mozilla Firefox)
図7: 元のロード時間(zipなし)との比率
Chromeでは、約3倍パフォーマンスが落ちます。驚いたことにFirefoxでは1.5倍から2倍向上しています。
Firefoxでは大きな改善が見られますが、残念ながらChromeでは後退しています。様々な理由があると思われますが、base-64の文字列は、解析され次第即座にデコードされるのに対し、base-122ではデコーダスクリプトの解析からロードされるまでの遅延が大きな原因でしょう。また、gzipを有効にした場合、ダウンロードサイズのさらなる向上は望めません。これらのテストが示すのは、base-122はWebのコンテキストでは、少なくともブラウザのサポートなしでは、大して使い物にならないということです。
base-64、base-122の両方でロード時間が改善されているものの価値はありません。外部からロードされる画像にはなおプログレッシブローディングという利点があり、画像データを埋め込まないことによって、HTMLページのパーツは画像データのダウンロード前からロードできるからです。
3.4 結果の再現
下記を参照すれば、これまでの結果を再現したり、様々な環境でテストしたりすることができます。
- このNodeJSスクリプト で、3.1のサイズの差分を計算。
- JSPerfテスト は、あらゆるブラウザがサポートする。 TextDecoder で実行可能。
- これらのNodeJSスクリプト で unsplash.it の素材を取り、64×64ピクセルの可変の画像を生成できる。
4 結論と今後の展望
Webのパフォーマンスの向上がbase-122の目的でしたが、それはWebに留まりません。UTF-8が使われている部分、バイナリのテキスト埋め込みのあらゆるコンテキストでbase-122を使える可能性があります。そこには例えば次のような改善の余地がありますが、他にもまだ挙げられるでしょう。
- コードポイントを強制的に0x80より高くする不正のインデックスを使い、2バイトのUTF-8文字の中でさらに多くのビットを変換する。
- ブラウザのデコーディングパフォーマンスを上げる。または、web-worker経由でブロックを解除する。
- デコーディングスクリプトのサイズを縮小する。
助言、率直なフィードバック、どちらも歓迎します。 GitHub ページをチェックしてください。

株式会社リクルート プロダクト統括本部 プロダクト開発統括室 グループマネジャー 株式会社ニジボックス デベロップメント室 室長 Node.js 日本ユーザーグループ代表
- X: @yosuke_furukawa
- Github: yosuke-furukawa
関連記事