2016年4月25日
アジャイルな開発には安全性が不可欠 : 現実世界の安全機構との3つのアナロジー
(2016-03-30)by Yevgeniy (Jim) Brikman
本記事は、原著者の許諾のもとに翻訳・掲載しておりま��す。
(2016/7/15、著者プロフィールを修正いたしました。)
仮に、高速道路の自動車をより速く走らせることがあなたの務めだとします。もしあなたが、ドライバー全員にただ「アクセルを思いきり踏むように」と言ったら、一体どうなるでしょうか?
結果は明らかに、大惨事となるでしょう。それなのに、ソフトウェアの構築を速めようとする時に、多くの開発者がまさにそんな態度を取っているのです。その理由として持ち出されるのは、以下のようなことです。
「本当にアジャイルに進めたいので、デザインやドキュメントには時間をかけられない」
「これは本番環境にすぐ反映しなきゃいけないから、テストを書く時間はない」
「何もかも自動化する時間はなかったので、コードのデプロイは手作業でやる」
自動車が高速道路を高速で走るには、安全性が欠かせません。より速く走るためには、ブレーキやシートベルト、エアバッグといった、いざという時にドライバーを危険から守るための安全機構が不可欠です。
ソフトウェアの場合は、アジャイルな開発には安全性が欠かせません。賢明なトレードオフをすることと、全く用心せずやみくもに突き進むことは違います。コードの変更によって何か問題が起こった時に、その被害を抑えるための安全メカニズムが不可欠なのです。向こう見ずに事を進めると、結局は開発を速めるどころか遅らせてしまうことになります。
-
テストを書かないことで1時間を”節約”できても、本番環境で厄介なバグを突き止めるのに5時間かかる羽目になります。もし”ホットフィックス”によって新たなバグが発生したら、さらに5時間かかってしまうでしょう。
-
ドキュメントを書くという30分の作業を省くと、同僚の一人一人にコードの使い方を教えるのに1時間を費やすことになります。もし同僚がコードを不適切に使ったら、その後始末にさらに1時間かかってしまうでしょう。
-
自動化をセットアップしないことでわずかな時間は節約できたとしても、手作業でコードのデプロイを繰り返すのにはるかに多くの時間を費やす羽目になります。もし誤ってステップを飛ばしたら、バグを突き止めるのにさらに時間がかかってしまうでしょう。
ソフトウェアの世界で鍵となる安全メカニズムは何でしょうか? この記事では、物質界に見られる3つの安全機構と、ソフトウェア界でのそれに類似したメカニズムをお話ししていきたいと思います。
ブレーキ / 継続的インテグレーション
自動車の場合、適切なブレーキとは、問題に遭遇する前に車を停止させてくれるものです。ソフトウェアの場合、継続的インテグレーションとは、バグを含むコードを本番環境へデプロイされる前に阻止してくれるものです。継続的インテグレーションを理解するために、まずはその逆の 遅延インテグレーション について考えてみましょう。
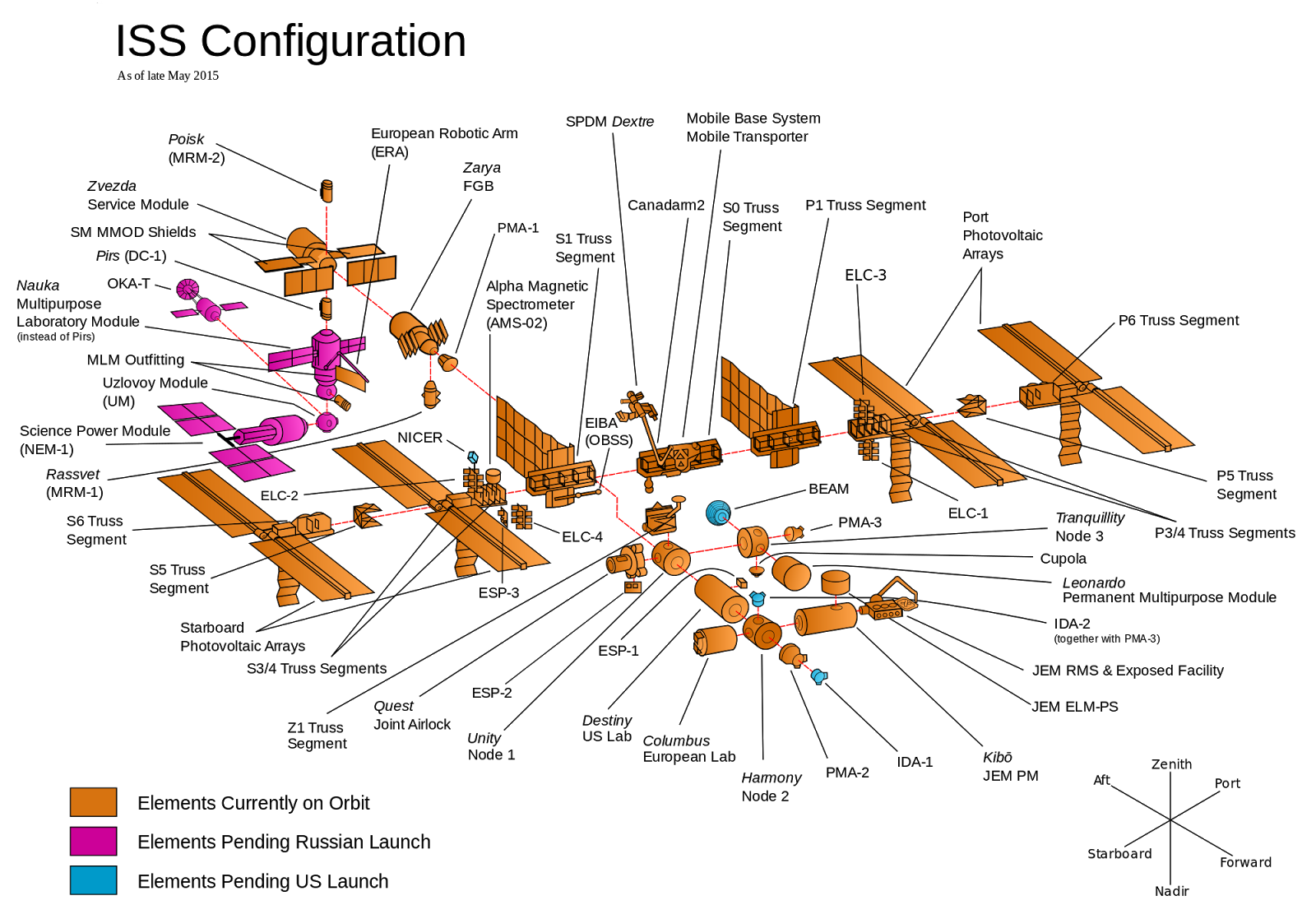
図1:国際宇宙ステーション
例えば、あなたが国際宇宙ステーション(ISS)の建設を任されているとします。ISSは図1に示されているように何十もの構成要素から成り立っています。各構成要素は異なる国のチームが開発し、それらをどう組み立てるかの決定権はあなたにあります。選択肢は以下の2つです。
-
全ての構成要素の設計を前もって考えてから、各チームには担当する構成要素の開発を全く別々に進めさせる。全チームの開発が完了したら、全ての構成要素を宇宙空間へ打ち上げ、一斉に組み立てる。
-
全ての構成要素の初期設計を考えてから、各チームで開発に取り掛からせる。開発の過程では、各構成要素を他の全ての要素に対して絶えずテストし、問題があれば設計を改良するようにする。構成要素は完成に伴い1つずつ宇宙空間へ打ち上げ、その都度追加する形で組み立てていく。
1つ目の選択肢は、最終段階でISS全体を組み立てるやり方ですが、これでは膨大な数の食い違いや設計上の問題が出てくるでしょう。例えば、ドイツのチームはフランスのチームが配線の担当だと考えていたのに、フランスはイギリスがその担当だと考えていたり、どのチームもメートル法を採用しているのに1つのチームだけが異なる単位系を使っていたり、トイレの設置を優先するチームが1つもなかったりするかもしれません。こうした様々な問題が、全ての開発が済んだあとに宇宙空間で発覚したら、解決は非常に難しくなり、コストも高くついてしまうでしょう。
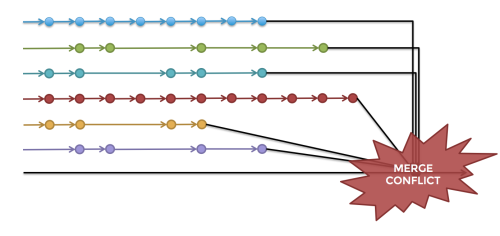
残念なことに、これはまさしく、多くの企業がソフトウェアを構築する際に取っている方法です。開発者たちは一度に何週間や何カ月も全くばらばらに各 フィーチャーブランチ で作業を進め、最後の最後で全ての作業結果を一斉にリリースブランチにマージしようとしているのです。このプロセスは 遅延インテグレーション として知られていますが、結果的に、マージでのコンフリクト(図2参照)を修正し、見つけにくいバグを突き止め、そしてリリースブランチを安定させるのに、数日や数週間かかることもよくあります。
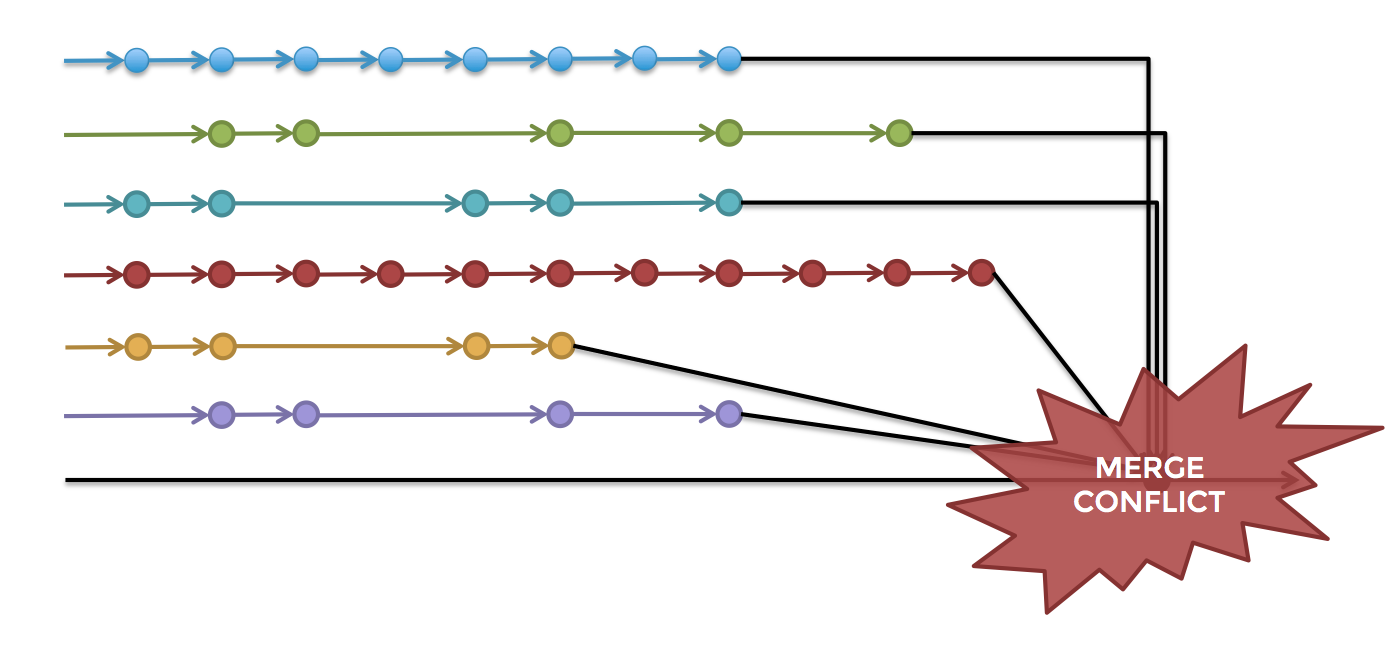
図2:各フィーチャーブランチをリリースブランチにマージした結果、困難なコンフリクトが発生
2つ目の選択肢として前述した、もう1つのアプローチに当たるのが継続的インテグレーションで、全ての開発者が作業結果のマージをきちんと定期的に行うやり方です。その結果、誤った方向に行き過ぎる前に、プロセスの途中で設計上の問題が明らかになるので、設計をその都度改良することができます。継続的インテグレーションを実践する最も一般的な方法は、 トランクベースの開発モデル を使うことです。
トランクベースの開発モデル では、開発者たちは全ての作業を同一のブランチで行います。このブランチは、バージョン管理システム(VCS)に応じて、トランクやマスタと呼ばれています。そこへ皆が定期的にチェックインするというのがこのモデルの考え方で、頻度は1日につき複数回になることもあります。全ての開発者が単一のブランチで作業するという状況を、本当にスケールできるのでしょうか? トランクベースの開発は、 LinkedIn や Facebook 、 Google で何千人もの開発者が実践しています。Googleのトランクの統計は特に驚くべき規模です。彼らは20億行以上のコードを管理し、単一のブランチで 1日につき 45,000回のコミットを行っているのです。

図3:トランクベース開発では、全員が同じブランチにチェックインする
何千人もの開発者が同じブランチに頻繁にチェックインしていてコンフリクトがないという状況は、どうやったら実現できるのでしょうか? 実は、大規模でモノリシックなマージではなく小規模で頻繁なコミットを行うことで、コンフリクトの数はかなり少なくなり、生じるコンフリクトも妥当なものとなることが分かっています。その理由は、どんなインテグレーション戦略を取っていようともコンフリクトには対処する必要があり、(継続的インテグレーションでの)1日や2日の作業に対して生じるコンフリクトの方が、(遅延インテグレーションでの)何カ月もの作業に対して生じるコンフリクトよりも扱いやすいからです。
では、ブランチの安定性についてはどうなのでしょうか? もし全ての開発者が同一のブランチで作業をしている中、コンパイルできないコードや深刻なバグを引き起こすコードを1人の開発者がチェックインしてしまうと、全ての開発が妨げられる可能性もあります。それを防ぐには、自己テスト機能を備えたビルドが必要です。自己テスト機能付きビルドは、十分な自動テストを含む完全に自動化されたビルドプロセス(すなわちコマンド1つで実行可能)なので、テストが全て通れば、そのコードの安定性を信頼することができます。通常のアプローチは、各コミットを受け取るVCSにコミットフックを追加し、JenkinsやTravisなどの継続的インテグレーション(CI)サーバ上のビルドを通じてコミットフックを実行して、ビルドが失敗したらそのコミットを拒否するというものです。CIサーバはゲートキーパであり、トランクへ通す前に全てのチェックインを検証し、不適切なコードが本番環境に反映されるのを防ぐ優れたブレーキの役目を果たすのです。
継続的インテグレーションを実践していない場合、通常はテストかインテグレーションの段階で動作が証明されるまで、ソフトウェアは壊れている。継続的インテグレーションを実践している場合は、新たにどんな変更が加わっても(十分に広範な自動テストを経ているとすれば)ソフトウェアは動くと証明されており、壊れてもすぐに修復できると分かっている。
– Jez Humble、David Farley著『Continuous Delivery』(邦訳書『継続的デリバリー』)
継続的インテグレーションで大規模な変更を行うにはどうしたらよいでしょうか? つまり、何週間もかかる機能の構築に取り組んでいる場合に、1日に複数回、トランクにチェックインする方法とは? 1つの解決策として、フィーチャートグルを使うやり方があります。
安全装置 / フィーチャートグル
19世紀の初めごろ、多くの人がエレベーターを使用することを避けていました。乗車中にロープが切れて、エレベーターが落下して死んでしまわないかと心配だったからです。この問題を解決しようと、Elisha Otisは”安全なエレベーター”を発明し、大胆なデモンストレーションでその有効性を実証しました。Otisは内部が分かる巨大なエレベーターシャフトを用意し、囲いのないエレベーターのかご部分を数階分つり上げました。そして図4のように、集まった人たちの前で実際にロープを切断させたのです。エレベーターは少し落下しただけで、すぐに止まりました。

図4:”安全なエレベーター”を実証するElisha Otis
一体どのような仕組みだったのでしょうか? 安全なエレベーターの鍵となったのは、図5のような 安全装置 です。初期状態では、この落下防止装置は完全に伸びきって、エレベーターシャフトのラッチに掛かり、エレベーターが落ちないようにします。落下防止装置が収縮する唯一のケースは、エレベーターのロープが張り詰めて落下防止装置を引き入れている状態です。つまり、ロープが損傷などしない限り、この装置が作動することはありません。
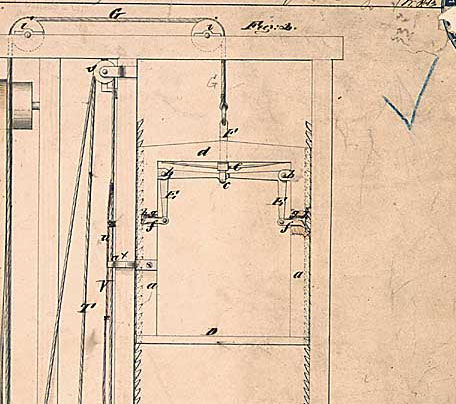
図5:安全装置付きエレベーターの特許から引用。真ん中にエレベーターシャフト(D)、側面に安全装置(f)。上部にロープ(G)。
この素晴らしい設計により、安全装置は常に安全性を提供してくれます。ソフトウェア開発の場合は、フィーチャートグルがデフォルトで安全性を提供してくれます。フィーチャートグルを使用するには、設定ファイルやデータベースから指定されたフィーチャートグル(以下の例ではshowFeatureXYZ)を検索するifステートメントを使って、新しいコードを全てラップします。
if (featureToggleEnabled(“showFeatureXYZ”)) {
showFeatureXYZ()
}鍵となるアイデアは、デフォルトで全てのフィーチャートグルをオフにするというものです。そうすれば、デフォルトの状態では安全です。つまり、フィーチャートグルにラップされている限りは、まだ完成していないコードやバグを含んだコードでもチェックインし、デプロイも可能になります。Ifステートメントになっているので、コードが実行されることや、大きな影響が出ることがないからです。
機能が完成したら、そのフィーチャートグルをオンにします。一番簡単な方法は、指定されたフィーチャートグルと、その値を設定ファイル内に格納することです。そうすれば、開発環境設定のフィーチャーを有効にしても、本番環境設定では機能の準備が整うまで無効にすることができます。
# config.yml
dev:
showFeatureXYZ: true
prod:
showFeatureXYZ: falseさらに強力なオプションは、ユーザごとにフィーチャートグルの値を決められる動的システムと、開発側がフィーチャートグルの値を動的に変更し、特定のユーザに対して機能を有効、または無効にすることができるWeb UIを使用することです。これは図6のようなものです。
例えば開発中は、まずは社員だけを対象にフィーチャートグルを有効にします。機能が完成したら、全ユーザの1%で有効にします。それでうまくいきそうなら、有効にする対象ユーザの割合を10%、次は50%…というふうに増やしていきます。どこかの時点で問題が発生すれば、Web UIを使って機能を無効にすればいいのです。 A/Bテスト、バケットテスト の場合にも、フィーチャートグルを利用できます。
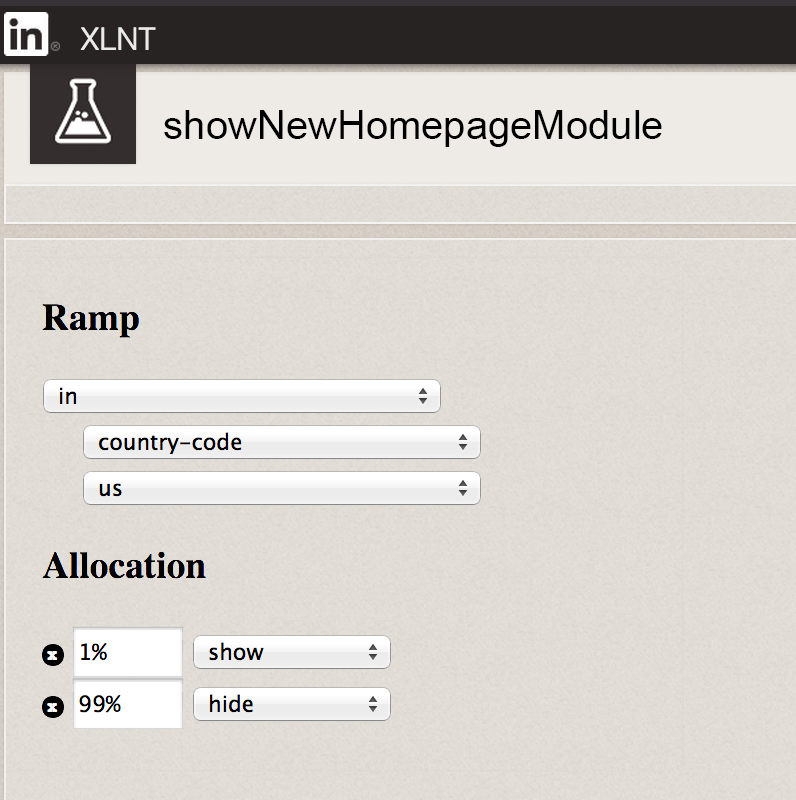
図6:LinkedInのフィーチャートグルのツールXLNTを使用し、アメリカユーザの1%で有効にする。
遮断壁 / コードベースの分割
船の場合、区分けされた水漏れしないコンパートメントを作る際、遮断壁を用います。これによって、船体に亀裂が入った場合でも、1つのコンパートメントの浸水に留めることができます。
同様に、ソフトウェアの場合も、コードベースを区分けしたコンポーネントに分割することで、問題が起きた場合に、被害を1つのコンポーネントに抑えられます。
コードベースの分割は重要です。なぜなら、コードベースに起こりうる最悪のケースである サイズの超過 という問題があるからです。コードが多くなればなるほど、作業は遅くなります。例として、 『コードコンプリート』(邦訳書『コードコンプリート』) から抜粋した以下の表について考えてみてください。この表は、プロジェクトサイズ(コードの行数)に対するバグの数(1,000行のコードごとのバグの数)を表したものです。
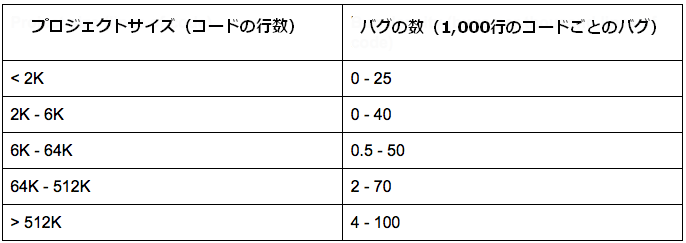
プロジェクトサイズに対するバグの数
つまりこの表は、コードベースが大きくなるに従って、バグの数が急速に増えていることを表しています。例えば、コードベースが2倍になると、そこに含まれるバグの数は、4倍または8倍に膨れ上がることもあります。コードが50万以上の行数になるころには、10行ごとに1つのバグが含まれるという非常に高いバグ率になってしまうのです!
その理由を、 『Practices of an Agile Developer』 から引用して答えるならば、「ソフトウェア開発は、チャートやIDE、デザインツールの中で行っているのではない、開発者の頭の中で行っているのだ」、ということでしょう。何十万といった行数のコードで形成されるコードベースを記憶するには無理があります。これだけのコードの中にある、全ての相互関係やコーナーケースを考慮することはできません。 ですから、コードを分割するという戦略が必要になるのです。そうすることで、1箇所ずつに集中することができ、他の箇所に関心を寄せなくても問題にならないのです。
コードベースを分割する際の主な戦略は、2つあります。1つはアーティファクト依存への移行、もう1つは、マイクロサービスアーキテクチャへの移行です。
アーティファクト依存の意図は、モジュールを変更することにあります。他のモジュールのソースコードに依存(ソース依存)する代わりに、他のモジュールによって発行されたバージョン管理されたアーティファクトに依存させるのです(アーティファクト依存)。恐らく、オープンソースライブラリでこのことはすでに行っているでしょう。JavaScriptコードでjQueryを使ったり、JavaコードでApache Kafkaを使ったりする場合は、これらのオープンソースライブラリのソースコードに依存はしませんが、バージョン管理されたアーティファクトでは、jquery-1.11-min.jsやkafka-clients-0.8.1.jarなどを提供してくれます。各モジュールの固定されたバージョンを使う場合、アップグレードすることを明白に選択しない限り、開発者が行う、これらのモジュールに対する変更は、効果がありません。遮断壁と同様に、他のコンポーネントにある問題から隔離してくれます。
マイクロサービス の意図は、単一のモノリシックアプリケーションから、分離された個々へのサービスへの移行することです。モノリシックアプリケーションでは、全てのモジュールが同じプロセスで走っており、ファンクションコールを介して通信しますが、個々のマイクロサービスでは、各モジュールが個別のプロセスで、通常は個別のサーバ上で走っており、メッセージを介して相互に通信を行っています。サービスの境界はコードオーナーシップの境界に適しているので、マイクロサービスでは、チーム内のメンバーが個別に仕事をすることを可能にする素晴らしい方法と言えます。また、マイクロサービスは、製品を作るための、様々な技術を使うことができ(例えば、マイクロサービスごとにPythonやJava、Rubyなどを使い分ける)、個別にサービスをスケールすることができます。
アーティファクト依存 やマイクロサービスには多くの利点がありますが、同時に多くの重要な欠点もあります。どちらも、先ほど挙げた継続的インテグレーションの考えに対して否定的であるという点が、その1つです。トレードオフに関する本格的な議論は、 マイクロサービスやアーティファクトへのコードベースの分割 をご覧ください。
3つの質問
安全メカニズムによって迅速性を手に入れることはできますが、これは無料ではありません。緩慢であると思われる時期に、事前に投資をする必要があります。では、実際の製品に対してどの程度の時間を安全メカニズムに投じるべきか、どのように決めたらいいのでしょう? それを見極めるには、3つの質問を投げかけてみてください。
この記事のまとめとして、自動テストをするかしないかというよくある決断に対して、これら3つの質問を投げかけてみましょう。
テストを頑固に支持する人たちの中には、全てのコードに対してテストを書くべきで、100%のコードカバレッジを目指すべきだという主張もありますが、実際にそこまでテストを行っていることは非常に稀です。私が 『Hello, Startup』 を執筆している頃、GoogleやFacebook、LinkedIn、Twitter、Instagram、Stripe、GitHubといった、ここ10年で最も成功したスタートアップ企業の開発者にインタビューをしました。そこで私が発見したのは、特に会社設立初期の頃は、どの企業の開発者も、何をテストして、何をテストしないかについて熟考した上で、トレードオフを行っていたということです。
では早速、3つの質問を見ていきます。
自動テストを書いたり、管理したりするのにかかるコストはどのくらいか?
近年、ユニットテストのセットアップは安く行えます。ほとんど全てのプログラミング言語において、高品質のユニットテストのフレームワークが存在し、ほとんどのビルドシステムには、ユニットテスト向けのビルトインサポートが備わっています。また、通常、実行はとても速いです。対してインテグレーションテスト(特にUIテスト)の実行においては、システムの大部分を使用します。これはつまり、セットアップにはより多くのコストがかかるのに、実行は遅く、管理が困難ということになります。
もちろん、インテグレーションテストは、ユニットテストでは見つけることのできない、多くのバグを見つけてくれます。しかし、セットアップや実行により多くのコストがかかるので、ほとんどのスタートアップ企業は、多くのユニットテストにコストを投じており、インテグレーションテストには、利用価値が高く、欠かせないものに絞って導入しています。
自動テストがなかった場合に見逃してしまうバグにかかるコストはどのくらいか?
1週間で破棄してしまう可能性のあるプロトタイプを構築していた場合のバグのコストは、大したことはありません。ですからテストにコストを投じることはないでしょう。対して、支払い処理システムを構築していた場合、バグのコストは膨大です。お客様のクレジットカードに2度決済を行ったり、誤った金額を請求したりしたくはありません。
私がインタビューを行ったスタートアップ企業が実施したテストは様々でしたが、どの企業もコードにわずかなバグを発見しています。主に、支払いやセキュリティ、データストレージです。これらのコードのバグは決して見過ごすことはできないので、最初から重点的にテストを行っています。
自動テストをしない場合、どのくらいの頻度でバグが起こるのか?
先ほどお話ししたように、コードベースが大きくなると、バグの数はより急速に増えます。チームのサイズが大きくなったり、構築しているものがより複雑になったりすれば、同様のことが起きます。
2人の開発者で10,000行のコードを書くチームであれば、彼らの時間の1割ほどを使えばテストは書けるでしょう。20人の開発者で100,000行を書くチームであれば、彼らの時間の2割、200人の開発者で100万行を書くチームであれば、テストを書くのに、彼らの時間の5割が必要になるでしょう。
コードの行数や開発者の人数が増えれば、比例的にテストにかける時間が多く必要になってきます。
参考資料
もちろん、他にも数多くの役立つ安全メカニズムがあります。さらに深く詳細を知りたい方は、以下のリンクをご覧になってみてください。
- 継続的デリバリー サイト管理者:Jez Humble
- フィーチャートグル 著者:Martin Fowler
- LinkedInの構築、スケーリングからの学び 発表者:Jay Kreps
- 『Growing Object-Oriented Software, Guided by Tests』(邦題訳『実践テスト駆動開発 テストに導かれてオブジェクト指向ソフトウェアを育てる』 著者:Steve Freeman並びにNat Pryce

株式会社リクルート プロダクト統括本部 プロダクト開発統括室 グループマネジャー 株式会社ニジボックス デベロップメント室 室長 Node.js 日本ユーザーグループ代表
- X: @yosuke_furukawa
- Github: yosuke-furukawa
関連記事