2015年9月14日
イベントループなしでのハイパフォーマンス – C10K問題へのGoの回答

(2015-08-8)by Dave Cheney
本記事は、原著者の許諾のもとに翻訳・掲載しております。
この投稿は、私が去年OSCONで行ったプレゼンテーションを基に作成しています。プレゼンよりは簡潔に編集し直し、プレゼン後にいただいたいくつかのフィードバックに応える形で記事を書いています。
Go言語に関してよく言われるのは、Go言語はサーバでうまく機能し、静的なバイナリや強力な並行処理、高いパフォーマンスを見せくれるということです。
この投稿では、その後半の2つの項目に関して焦点を当てます。プログラマとってGo言語とそのランタイムは、スケーラブルなネットワークサーバをスレッド管理やブロッキングI/Oを気にせずに書くのにどんなに有効かを説明していきます。
効率的なプログラミング言語に関しての議論
技術的な話に入る前に、Go言語をターゲットにしたマーケットを説明する2つの議論に関してお話したいと思います。
ムーアの法則
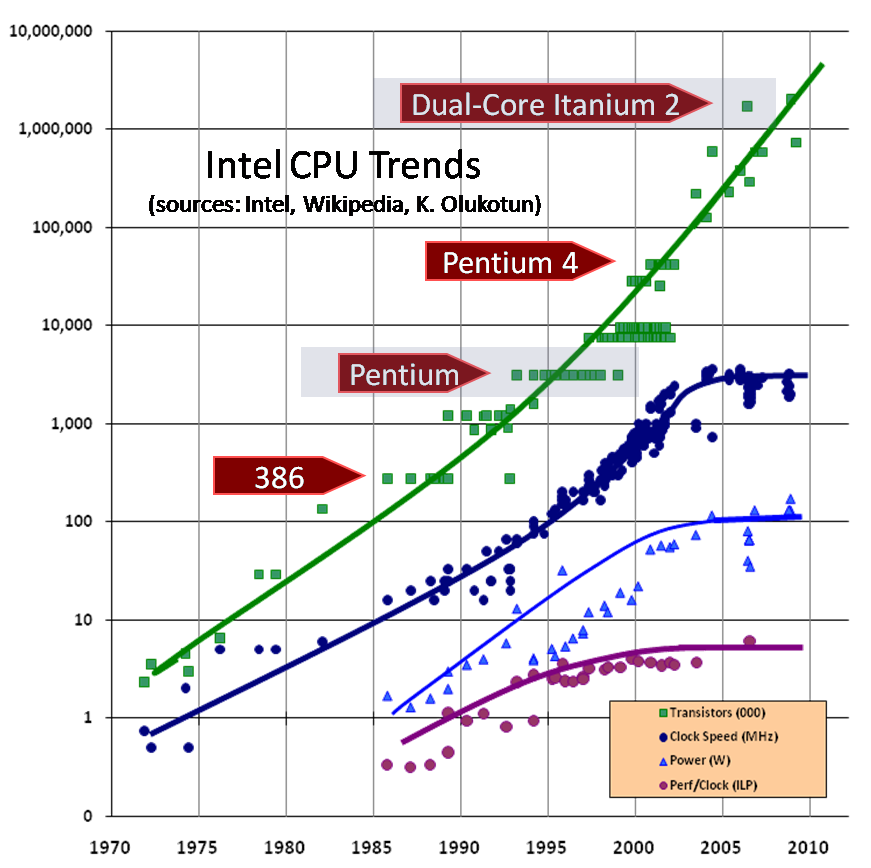
画像は以下より引用; 2005年5月にHerb Sutter氏が書いたDr. Dobb’s journal
ムーアの法則では、1平方インチ毎にトランジスタ数がおおよそ18カ月で倍増すると言われています。
しかし、完全に違うプロパティの機能であるクロックスピードは、10年前にPentium4で頂上を極めた後、徐々に後退してきています。
スペースの制約から、電力の制約に

Sun Enterprise e450- ホテルの冷蔵庫くらいの大きさで、同じ消費電力。画像は以下より引用; eBay
これは、Sun e450です。私が働き始めた頃は、これが業界では重宝されていました。
これはとても巨大な機械です。縦に3つ重ねると19インチラックにピッタリ収まるくらいです。消費電力は1つにつき、たったの500ワットです。
ここ10年でデータセンタはスペース制約から電力制約に移行しました。私が関わった2つのデータセンタのロールアウトでは、サーバラックが3分の1ほど埋まった時に、電力がなくなりました。
コンピュータのサイズが急激に小さくなったので、データセンタのスペースに関してはもはや問題ではありません。しかし、最近のサーバは小さい設置スペースで済むものの、電力消費が著しいため、冷却についても同様に重要となっています。
電力の制約は、マクロとミクロの両方のレベルでの影響があります。マクロには、1RU あたり1200ワットのサーバからなるラックに十分な電力を供給することなどできませんし、ミクロには、何百ワットもの電力がほんの小さなシリコンのダイで浪費されます。
電力消費はどのようにして起こるか

CMOSによるインバータ。画像は以下より引用; Wikipedia
この図は、考え得る一番シンプルな論理ゲートのインバータです。入力Aがハイなら、出力Qはローになります。これが逆の場合も同じです。
現在の家庭用電化製品は全てCMOS論理で作られています。CMOSはComplementary Metal Oxide Semiconductor(相補型MOS)の略です。 相補型 というのが鍵になります。CPUの中のそれぞれの論理の要素は対のトランジスタで実装されます。1つのスイッチがオンになると、もう1つはオフになります。
回路がオンかオフの時には、ソースからドレインに直接電流が流れることはありません。しかし、切り替えている間は直接ショートして、 両方の トランジスタは少しの間伝導しています。
電力制約、つまり熱の散逸は、1秒間でのトランザクションの数と正比例します。これをCPUのクロック周波数 ^(1) と言います。
CPUのサイズを縮小させる主な目的は、電力消費を抑えることです。電力消費を減少させるのは単に”エコ”という意味だけではありません。一番の目的は電力消費、つまりは熱の散逸を、CPUにダメージを与えないレベルで維持することです。
クロック周波数が落ち、電力消費の直接コンフリクトしている状態では、パフォーマンスの向上は主にマイクロアーキテクチャの改良や難解なベクタのインストラクションによってしか実現できません。そして、これらの手法は一般的なコンピュータの使用時には使えません。それぞれの マイクロアーキテクチャ (5年サイクル)の変更は世代毎に最大で10%の改善を生み出します。最近ではかろうじて4~6%になるくらいでした。
“無料ランチは終わり”
これで、ハードウェアはこれ以上速くはならないことがお分かりいただけたでしょうか。あなたにとってパフォーマンスとスケールが重要なら、少なくとも従来の意味では、ハードウェアを投入しても問題は解決しないという、私の意見に賛同してくれるはずです。Herb Sutter氏が書いた “無料ランチは終わり” で詳しく説明されています。
効率のいい言語が必要ですよね。だって、設備投資という意味では、非効率な言語は大きな規模ではプロダクションで正当化できません。
コンカレントプログラミング言語に関する議論
2番目の論点は以下です。CPUは速くなりませんが、幅広くなります。これがトランジスタの行く末です。別に驚愕の事実ではありませんね。

画像は; Intelより引用。
複数の処理を並行して進めるマルチスレッド、Intelで ハイパースレッディング と呼んでいる技術は、適度な数のハードウェアを付けて、1つのプロセッサコアに対して並行して複数の命令ストリームを実行するものです。Intelはハイパースレッディングを使って、人工的にプロセッサにマーケットを分割します。Oracleと富士通はハイパースレッディングをもっと積極的に使って、自分たちの製品に8~16個のハードウェアスレッドをコア毎使っています。
デュアルソケットは1990年代後半以来、Pentium Proにより実現し、今では主流のサーバのほとんどがデュアルかクアッドソケットのデザインをサポートしています。トランジスタの数が増えると、CPUを他と一緒に同じチップ上に設置できます。携帯電話のデュアルコアや、デスクトップのクアッドコア、サーバ上での複数のコアも、現在存在しています。予算に見合うならば1つのサーバにいくつでもコアを設置することができます。
なお、複数のコアを有効に使うには、しっかりした言語の並行処理の知識が必要です。
プロセスとスレッドとGoルーチン
Goは、並行処理の基礎となるGoルーチンを備えています。ここで一度立ち止まって、Goルーチンが生まれた歴史をひも解いていこうと思います。
プロセス
まず、コンピュータはバッチ処理のモデルで一度に1つのジョブを実行していました。60年代には、インタラクティブなコンピューティング形態を求める声から、マルチプロセッシングやタイムシェアリング、OSが発達していきました。70年代までには、この考え方が、ネットワークサーバやftp、Telnet、Rlogin、子プロセスをフォークすることでそれぞれのネットワークの接続を扱うTim Burners-Lee氏の CERN httpd などが確立されました。
タイムシェアリングシステムでは、OSが有効なプロセス間でCPUを高速で切り替えることで並行処理を維持します。この時、起動中のプロセス状態を記録し、他のプロセスの状態は復元されます。これをコンテキストスイッチングと言います。
コンテキストスイッチング

画像は Immae (CC BY-SA 3.0)より引用。
以下はコンテキストスイッチングでかかる主なコストです。
- カーネルは、プロセスの全てのCPUレジスタのコンテキストを保存し、他のプロセスの値を復元します。プロセスの実行中ならいつでもプロセススイッチングは発生し得るので、OSは全てのレジスタのコンテキストを保存する必要があります。これはその時にどれが使われているか分からないからです ^(2) 。
- カーネルは、CPUの仮想アドレスから物理アドレスマッピングに変換する必要があります(TLBキャッシュ) ^(3) 。
- OSのコンテキストスイッチングによりオーバーヘッドや、スケジューラ(CPUを占領する次のプロセスを選択するという働きをします)のオーバーヘッド。
これらのコストはハードウェアでだいたい抑えられますし、コンテキストスイッチングで行われる大量の処理によってコストを償却します。高速のコンテキストスイッチングはコンテキストスイッチングで行われた大量の処理を抱え込みすぎる傾向があります。
スレッド
これが、スレッドを発達させました。概念的にはプロセスと同じですが、同じメモリ空間を共有します。スレッドがアドレス空間をシェアするので、スレッドはプロセスより軽くスケジュールできます。ですから、より素早く生成でき、より速く切り替えができます。
スレッドのコンテキストスイッチングはいまだに高価ですし、多くの状態が制限されなければなりません。Goルーチンはこのスレッドの概念を発展させたものになります。
Goルーチン
タイムシェアリングをカーネルに頼るよりも、Goルーチンは協調的にスケジュールされます。Goルーチン間の切り替えは特定のタイミイングのみで発生します。明瞭な呼び出しがGoのランタイムのスケジューラを作り出す時です。以下が、Goルーチンがスケジューラを生成する主なポイントです。
- 処理がブロックされた時、チャネルが処理を送受信します。
- Goの命令文によります。ただし、新しいGoルーチンがすぐにスケジュールされるという保証はありません。
- ファイルやネットワーク処理のように、ブロッキングなsyscallによります。
- ガベージコレクションのサイクルで止められた後に生成されます。
別の言い方をすれば、これはGoルーチンがもっとデータを取得するか、データを格納するためのスペースを確保できるまではこれ以上継続できないポイントということです。
Goのランタイムによって、多くのGoルーチンがOSの1スレッド上に多重化されます。このことにより、Goルーチンは生成するのも切り替えるのも安価です。1つのプロセスに何万ものGoルーチンがあるのは標準で、何十万とあっても予測の範囲内です。
言語的な観点から言えば、スケジューリングは関数呼び出しに似ていて、同様のセマンティクスを持っています。コンパイラは使用されているレジスタを把握し、自動的に保存します。スレッドは、特定のGoルーチンのスタックを保持しているスケジューラに対して呼び出しをかけますが、返す時は別のGoルーチンのスタックかもしれません。これに比べると、スレッド化されたアプリケーションではスレッドがいつでも、どの命令においてもプリエンプション可能です。
これによってGoのプロセス毎のOSのスレッドは比較的数少なくなっており、Goのランタイムは使われていないOSスレッドに実行可能なGoルーチンをアサインする役目を果たします。
スタックマネジメント
前の項では、Goルーチンがどのようにして多量の、時には何十万もの並列の実行スレッドを管理しつつオーバーヘッドを減らすか、ということについて説明しました。Goルーチンには他の役割もあります。それはスタック管理です。
アドレス空間のプロセス
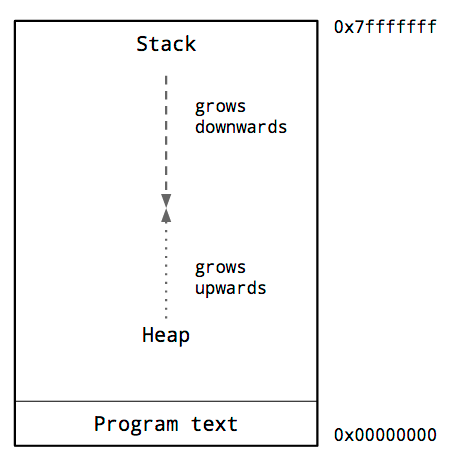
これはプロセスの典型的なメモリレイアウトの図です。ここで気になる重要な点はヒープとスタックの位置です。
プロセスのアドレス空間内部では、従来からヒープはメモリの下層、プログラムコードのすぐ上にあり、上に向かって成長します。
スタックは仮想アドレス空間の一番上にあり、徐々に下に成長していきます。
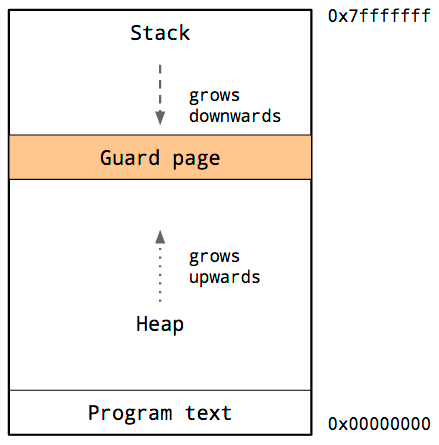
ヒープとスタックがお互いに上書きし合うと大変なことになるので、オペレーティングシステムはスタックとヒープ間にアクセスできないメモリ空間を用意します。
ガードページと呼ばれ、効果的にプロセスのスタックサイズを制限します。通常、数メガバイトのサイズです。
スレッドのスタック
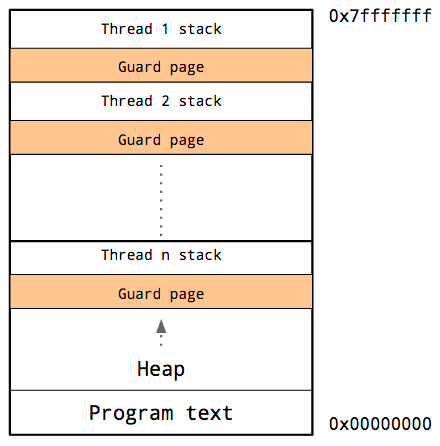
スレッドはアドレス空間を共有しているので、各スレッドそれぞれに独自のスタックとガードページを持つ必要があります。
スタックが要求する特定のスレッドを予測するのは難しいので、各スレッドのスタックには大容量のメモリを必要分以上確保して、ガードページにアクセスしないようにする必要があります。
難点としては、プログラム内でのスレッドが増加すると使用可能なアドレス空間が減ってしまうということです。
Goルーチンのスタック管理
初期プロセスのモデルでは、プログラマがヒープを閲覧でき、心配が要らない程度にスタックサイズを大きくできるようになりました。マイナス面は、サブプロセスのモデルが複雑で費用がかかることでした。
スレッドによって状況は少し改善したものの、プログラマは最も適切なスタックサイズを想定しなくてはならなくなります。小さすぎればプログラムが停止してしまい、大きすぎれば仮想アドレス空間が無くなってしまいます。
Goのランタイムは大量のGoルーチンを少量のスレッドにスケジュールするということは既に述べましたが、これらのGoルーチンのスタックの必要条件はどうでしょうか。
Goルーチンスタックの成長
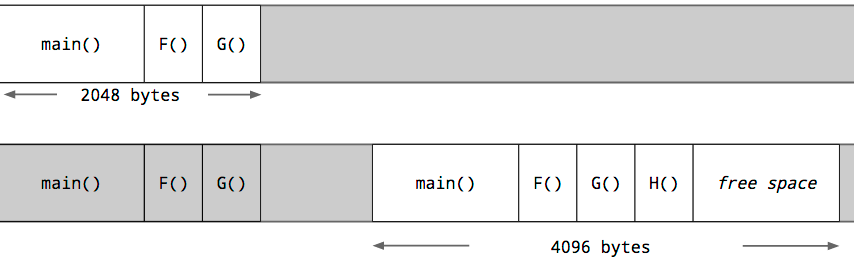
各Goルーチンはヒープが割り当てた小さなスタックから始めます。そのサイズは変動してきていますが、Go1.5では各Goルーチンは2kの割り当てからスタートします。
Goのコンパイラは、ガードページを使う代わりに、各関数呼び出しのテストの一環として、実行させる関数にとって十分なスタックがあるかどうかのチェックを挿入します。十分なスタック空間があれば、関数は異常なく実行されます。
十分な空間がない場合、ランタイムはヒープに対して大きなスタックセグメントを割り当て、現在のスタックの内容を新しいセグメントにコピーし、古いセグメントを解放し、それから関数呼び出しを再開します。
このチェックによりGoルーチンの最初のスタックはかなり小さくすることができるため、GoのプログラマはGoルーチンを安価なリソースとして扱うことができます。Goルーチンのスタックは、十分なサイズが未使用なら縮小することも可能です。これはガベージコレクションの間に処理されます。
統合されたネットワークのポーリング機能
2002年に、Dan Kegelはいわゆる C10K問題 について発表しました。当時のコモディティハードウェア上で、最低1万のTCPセッションを処理できるサーバソフトウェアを開発する方法をシンプルに記述しています。この白書が書かれてから、サーバのパフォーマンスを向上させるにはネイティブのスレッド、また最近ではイベントループを必要とするという概念が通例となりました。
スケジュールのコストとメモリのフットプリントの観点で、スレッドは高いオーバーヘッドを抱えています。イベントループによりこのコストは軽減されますが、今度はコールバック主導の複雑な手法が必要となります。
Goはこの2つの問題への最善の解決をプログラマに供給します。
C10K問題へのGoの回答
Goにおいては通常、syscallはブロッキングなオペレーションで、ファイル記述子の読み込みと書き込みを含んでいます。Goのスケジューラは元のスレッドがブロックされても、未使用のスレッドを探したり生成したりすることによりGoルーチンを提供し続けます。ブロックされたスレッドが少ないとすぐにローカルI/O のバンド幅を使い果たしてしまうため、実際、ファイルI/Oにとっては問題なく機能します。
しかしネットワークソケットでは、常にGoルーチンのほぼ全てがネットワークI/Oを待って意図的にブロックされてしまいます。ネイティブな実装では、ネットワークトラフィックを待ちブロックされてしまうため、Goルーチンと同じ数だけのスレッドを必要とします。Goの統合されたネットワークポーリング機能は、ランタイムとネットワークパッケージとの協力により、これを効果的に処理します。
Goの古いバージョンでは、1つのGoルーチンがkqueuやepollを使って準備完了通知をチェックしポーリングを行っていました。このポーリング用Goルーチンはチャネルを通じて、待機中のGoルーチンへと通知していました。これにより、syscall毎のスレッドというオーバーヘッドを避けることができ、チャネルが送信する汎用のウェイクアップの仕組みを使っていました。スケジューラはウェイクアップのソースや重要性については全く認識していなかったということです。
最新のGoでは、ネットワークポーリング機能はランタイムに統合されています。どのGoルーチンがソケットの準備完了を待っているかをランタイムが把握しているため、パケットが到着し次第すぐに同じCPUへとGoルーチンを配置することができ、遅延を減らし、スループットが向上します。
Goルーチン、スタック管理と、統合されたネットワーク調査
結論として、Goルーチンが提供する強力な抽象化により、プログラマはスレッドプールやイベントループについての心配から解放されます。
Goルーチンのスタックは、スレッドスタックやスレッドプールのサイズを気にすることなく、必要なだけ大きくすることができます。
統合されたネットワーク調査により、Goのプログラマは、複雑なコールバック方式を避け、OSが提供する最も効率的なI/O完了のロジックを利用できるのです。
ランタイムにより、Goルーチンを全て供給するのに十分なスレッドと、コアを使用可能にしておくことが保証されます。
そして、Goのプログラマはそういった全ての機能を意識しなくていいのです。
脚注:
-
CMOSの電力消費は回路が切り替わる時の短絡回路電流によってのみ起こるわけではありません。ゲートの出力容量と、トランジスタのサイズが減少するのに伴いMOSFETのゲートを通じて増加するリーク電流をチャージすることにより、追加の電力消費がおこります。詳細は、講義形式の資料、 CMUのECE322コース を読んでみてください。また、Bill Herdは CMOSがどう機能するかについての一連の記事 を投稿しています。 ↩
-
これは単純化しすぎかもしれません。OSがあまり使用頻度の高くないアーキテクチャ上のレジスタを保存したり復元したりするのを避けられるケースもあります。これは、浮動小数点またはMMX/SSEレジスタにアクセスするとプログラムがエラーになるモードでプロセスをスタートさせることにより、プロセスがこれらのレジスタを使用するので、それ以降に保存し復元するようカーネルに通知します。 ↩
-
CPUによっては、 タグ付けされたTLB と言うものを備えています。タグ付けされたTLBがサポートされるケースでは、OSはプロセッサに対し、特定のTLBキャッシュエントリと識別子を関連付けるように命令します。この場合の識別子はプロセスIDから派生したもので各キャッシュエントリをグローバルに扱うものではありません。これにより、プロセスが同一のCPU上にすぐに戻ってきた場合に、各プロセススイッチのエントリが一掃されてしまうのを避けることができます。 ↩

株式会社リクルート プロダクト統括本部 プロダクト開発統括室 グループマネジャー 株式会社ニジボックス デベロップメント室 室長 Node.js 日本ユーザーグループ代表
- X: @yosuke_furukawa
- Github: yosuke-furukawa
関連記事







{kind=link}