2015年8月17日
Goで毎分100万リクエストを処理する

本記事は、原著者の許諾のもとに翻訳・掲載しております。
Malwarebytes は、驚くべき成長を見せています。1年以上前にこのシリコンバレーの会社に入社して以来、私の主な仕事は急成長するセキュリティ企業の力となるシステムの設計と開発です。日々数百万人が利用する製品をサポートするために必要な、全ての基盤をつくります。私は12年以上、アンチウイルスとアンチマルウェアに関わるいくつかの会社で働いてきました。毎日処理する膨大なデータのせいで、これらのシステムがどれだけ複雑なものになるかを理解しています。
面白いことに、ここ9年ほどで私が携わったWebのバックエンド開発のほとんどは、Ruby on Railsが使われていました。誤解されないように言っておきますが、私はRuby on Railsが大好きですし、すばらしい環境だと思っています。しかし、Rubyでシステムを設計し始めると忘れてしまうのは、マルチスレッド化や並列化、高速化、メモリオーバーヘッドの低減に力を入れられれば、ソフトウェアのアーキテクチャが効率的で単純なものになるということです。長年、私はC/C++とDelphi、そしてC#のデベロッパをやっていますが、適切なツールを使えばジョブの複雑さを減らせることに最近気づきました。
私は設計者の代表として、インターネットで常に行われているプログラミング言語・フレームワーク戦争があまり好きではありません。効率性や生産性、そしてコードの保守性は、どれだけシンプルにソリューションを設計できるかにかかっていると信じています。
問題点
匿名のテレメトリと分析システムを使って仕事をしていたときの目標は、多数のエンドポイントからの大量のPOSTリクエストを処理できるようにすることでした。Webハンドラは、多くのペイロードのコレクションを含むJSONドキュメントを受け取ります。これは後々MapReduceをこのデータ上で操作できるように、Amazon S3に書き込む必要があります。
私たちはWorker-Tierのアーキテクチャの作成について調査しており、次のようなものを利用しています。
- Sidekiq
- Resque
- Delayed_job
- Elastic BeanstalkのWorkerTier
- RabbitMQ
- その他
2つの異なるクラスタをセットアップするのですが、1つはwebのフロントエンドのためのクラスタ、もう1つはWorkerのためのクラスタです。これで操作可能なバックグラウンドの仕事を拡張することができます。
しかし当初より、私たちのチームはGoを使用するべきだと思っていました。話し合いの段階で、このシステムのトラフィックは膨大になりそうだったからです。私は2年ほどGoを使っています。仕事でいくつかのシステムを開発しましたが、これだけの量のロードが可能なものは1つもありませんでした。
私たちはいくつかの構造体を作成し、POSTの呼び出しを通して受け取るWebリクエストのペイロードと、S3のバケットにアップロードするためのメソッドを定義することから始めました。
type PayloadCollection struct {
WindowsVersion string `json:"version"`
Token string `json:"token"`
Payloads []Payload `json:"data"`
}
type Payload struct {
// [redacted]
}
func (p *Payload) UploadToS3() error {
// the storageFolder method ensures that there are no name collision in
// case we get same timestamp in the key name
storage_path := fmt.Sprintf("%v/%v", p.storageFolder, time.Now().UnixNano())
bucket := S3Bucket
b := new(bytes.Buffer)
encodeErr := json.NewEncoder(b).Encode(payload)
if encodeErr != nil {
return encodeErr
}
// Everything we post to the S3 bucket should be marked 'private'
var acl = s3.Private
var contentType = "application/octet-stream"
return bucket.PutReader(storage_path, b, int64(b.Len()), contentType, acl, s3.Options{})
}Goルーチンへの素朴なアプローチ
初めに非常に素朴な方法で、POST ハンドラの実装を行いました。ジョブプロセスをシンプルなgoroutineで並行処理します。
func payloadHandler(w http.ResponseWriter, r *http.Request) {
if r.Method != "POST" {
w.WriteHeader(http.StatusMethodNotAllowed)
return
}
// Read the body into a string for json decoding
var content = &PayloadCollection{}
err := json.NewDecoder(io.LimitReader(r.Body, MaxLength)).Decode(&content)
if err != nil {
w.Header().Set("Content-Type", "application/json; charset=UTF-8")
w.WriteHeader(http.StatusBadRequest)
return
}
// Go through each payload and queue items individually to be posted to S3
for _, payload := range content.Payloads {
go payload.UploadToS3() // <----- DON'T DO THIS
}
w.WriteHeader(http.StatusOK)
}中程度のロードであれば、ほとんどの人にとっては問題ないはずですが、大きなスケールになると、うまくいかないことは即座に明らかになりました。最初のバージョンをデプロイした際、多くのリクエストが来るとは思っていましたが、それが桁違いの量になるとは想定していませんでした。トラフィック量の見積もりを完全に誤ったのです。
上記のアプローチには、いくつか問題点が挙げられます。Goルーチンをどのくらい生成するかコントロールできないのがひとつ、また、毎分100万のPOSTリクエストを取得すると、このコードはすぐにクラッシュし、炎上してしまいました。
もう一度チャレンジ
というわけで、別の方法が必要です。私たちはリクエストハンドラの寿命をごく短くすることと、同時にバックグラウンドでプロセスを生成することの重要性を議論し始めました。もちろん、これはRuby on Rails界においては当然なされるべきことですが、さもなければpuma、unicornあるいはpassengerを用いて、全てのWorker webプロセッサをブロックしているでしょう(JRubyの議論はここでは忘れてください)。そこで、Resque、Sidekiq、SQSといったありふれた解決法にレバレッジを効かせれば良かったのでは、という話になりました。そのやり方であればいくらでも案が出てきます。
2番目のイテレーションは、複数のジョブを待機させ、S3にアップロードさせるバッファチャネルを作ることでした。私たちはジョブの待機列のアイテム最大数をコントロールできた上、全てのジョブをメモリに並べられるだけの十分なRAMを保持していたので、ただジョブをチャネル列にバッファすれば良いだろうと考えました。
var Queue chan Payload
func init() {
Queue = make(chan Payload, MAX_QUEUE)
}
func payloadHandler(w http.ResponseWriter, r *http.Request) {
...
// Go through each payload and queue items individually to be posted to S3
for _, payload := range content.Payloads {
Queue <- payload
}
...
}そして、ジョブをデキューしプロセスするのに、下記のような方法を使いました。
func StartProcessor() {
for {
select {
case job := <-Queue:
job.payload.UploadToS3() // <-- STILL NOT GOOD
}
}
}正直なところ、何も考えていなかったということです。きっと何本ものレッドブルを共にした深夜だったのでしょう。このアプローチには何も利点がありませんでした。欠陥だらけの同時実行と引き換えに、問題を先延ばしするだけのバッファされたキューを得ました。私たちの同期プロセッサは一度に1ペイロードだけをS3にアップロードするという代物であり、受信リクエストのレートは1プロセッサがS3にアップロードする能力を大幅に超えていたので、バッファチャネルはすぐに限界に達し、リクエストハンドラが次のアイテムを並べようとする動作をブロックしてしまいました。
単純に問題を避けようとしたところ、かえってシステム滅亡のカウントダウンを始めてしまいました。この欠陥バージョンをデプロイして以来、レイテンシレートはコンスタントに上がり続けてしまっていました。
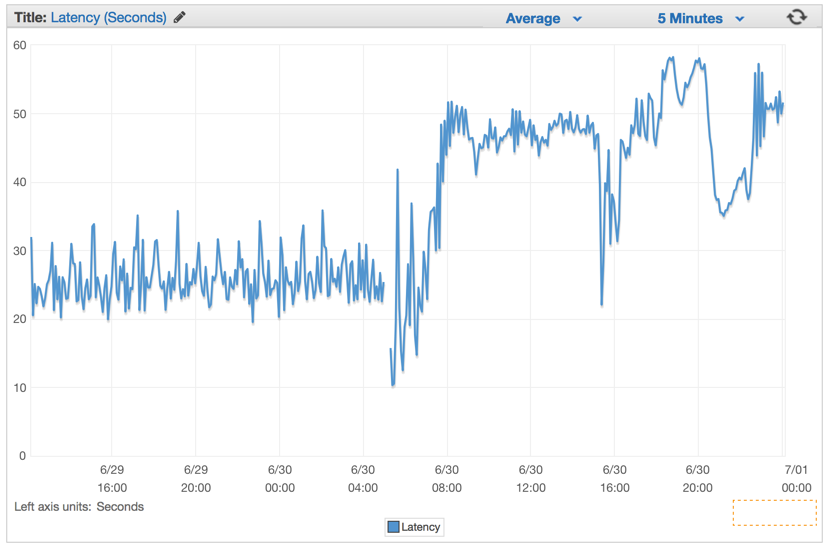
より良い解決法
私たちは、Goチャネルを使う際、ある一般的なパターンを活用することに決めました。ジョブを待機させ、JobQueueにおいて同時に動作するWorkerの数をコントロールする2-Tierのチャネルシステムを作るためです。
このアイデアは、マシンを故障させず、S3から接続エラーを引き起こさない、ある程度の持続可能なレートまでS3のアップロードを並列化処理することでした。そこでジョブWorkerパターンを作ることを選択しました。JavaやC#などをよく知っている人たちは、Worker threadのスレッドプールをチャネルで代用して実装するというGoでのやり方だと考えてください。
var (
MaxWorker = os.Getenv("MAX_WORKERS")
MaxQueue = os.Getenv("MAX_QUEUE")
)
// Job represents the job to be run
type Job struct {
Payload Payload
}
// A buffered channel that we can send work requests on.
var JobQueue chan Job
// Worker represents the worker that executes the job
type Worker struct {
WorkerPool chan chan Job
JobChannel chan Job
quit chan bool
}
func NewWorker(workerPool chan chan Job) Worker {
return Worker{
WorkerPool: workerPool,
JobChannel: make(chan Job),
quit: make(chan bool)}
}
// Start method starts the run loop for the worker, listening for a quit channel in
// case we need to stop it
func (w Worker) Start() {
go func() {
for {
// register the current worker into the worker queue.
w.WorkerPool <- w.JobChannel
select {
case job := <-w.JobChannel:
// we have received a work request.
if err := job.Payload.UploadToS3(); err != nil {
log.Errorf("Error uploading to S3: %s", err.Error())
}
case <-w.quit:
// we have received a signal to stop
return
}
}
}()
}
// Stop signals the worker to stop listening for work requests.
func (w Worker) Stop() {
go func() {
w.quit <- true
}()
}Webリクエストハンドラをモディファイし、ペイロードでJob structのインスタンスを作って、WorkerがピックアップできるようJobQueueチャネルに送ります。
func payloadHandler(w http.ResponseWriter, r *http.Request) {
if r.Method != "POST" {
w.WriteHeader(http.StatusMethodNotAllowed)
return
}
// Read the body into a string for json decoding
var content = &PayloadCollection{}
err := json.NewDecoder(io.LimitReader(r.Body, MaxLength)).Decode(&content)
if err != nil {
w.Header().Set("Content-Type", "application/json; charset=UTF-8")
w.WriteHeader(http.StatusBadRequest)
return
}
// Go through each payload and queue items individually to be posted to S3
for _, payload := range content.Payloads {
// let's create a job with the payload
work := Job{Payload: payload}
// Push the work onto the queue.
JobQueue <- work
}
w.WriteHeader(http.StatusOK)
}Webサーバを初期化する間にDispatcherを作り、Workerのプールの作成とJobQueueに現れるジョブをリスニングし始めるため、Run()を呼び出します。
dispatcher := NewDispatcher(MaxWorker)
dispatcher.Run()以下はディスパッチャを実行するためのコードです。
type Dispatcher struct {
// A pool of workers channels that are registered with the dispatcher
WorkerPool chan chan Job
}
func NewDispatcher(maxWorkers int) *Dispatcher {
pool := make(chan chan Job, maxWorkers)
return &Dispatcher{WorkerPool: pool}
}
func (d *Dispatcher) Run() {
// starting n number of workers
for i := 0; i < d.maxWorkers; i++ {
worker := NewWorker(d.pool)
worker.Start()
}
go d.dispatch()
}
func (d *Dispatcher) dispatch() {
for {
select {
case job := <-JobQueue:
// a job request has been received
go func(job Job) {
// try to obtain a worker job channel that is available.
// this will block until a worker is idle
jobChannel := <-d.WorkerPool
// dispatch the job to the worker job channel
jobChannel <- job
}(job)
}
}
}インスタンスが生成され、Workerのプールに付け加えられる最大のWorkerの数を与えることに注意してください。このプロジェクトのために、Docker化されたGo環境を用いてAmazon Elasticbeanstalkを利用してきたので、常に成果物の中でシステムのコンフィギュレーションを行うために 12-factor の方法論に従うようにしてきました。そして環境変数からこれらの値を読み込みます。Workerの数とジョブキューの最大数をコントロールすることができたので、これらの値に手を加えるのにクラスタの再デプロイする必要がありません。
var (
MaxWorker = os.Getenv("MAX_WORKERS")
MaxQueue = os.Getenv("MAX_QUEUE")
)即席の結果
デプロイをした直後に、レイテンシレートがわずかな数値にまで下がり、ハンドラリクエストをコントロールする能力が激しく高まっているのが見られました。
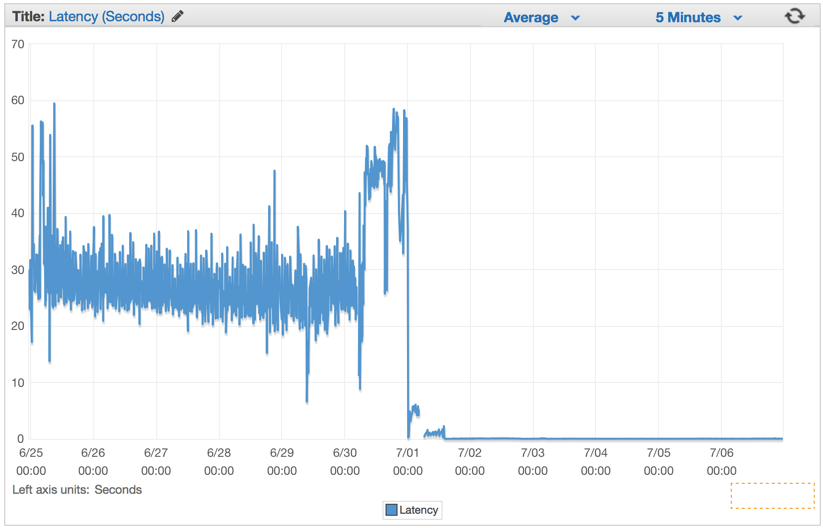
Elastic Load Balancersの準備ができた後に、ElasticBeanstalk アプリケーションサーバが毎分100万リクエストにまで近づいていることが分かりました。毎分100万よりもトラフィックが急上昇する深夜帯の時間があります。
新しいコードをデプロイすると、たちまちサーバの数は100から約20まで著しく下降しました。
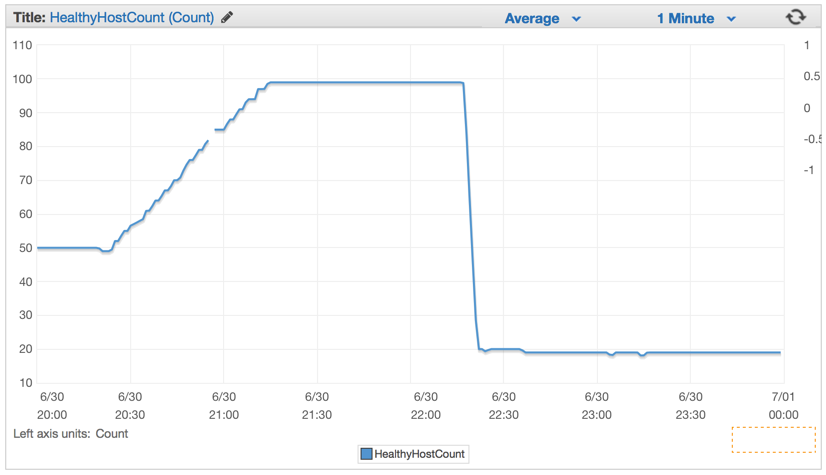
クラスタとauto-scalingセッティングに適切なコンフィギュレーションを行った後は、4つのEC2 c4.Largeにまで下げることができるようになりました。CPUが5分間絶えずに90%を上回った際には新しいインスタンスを生成するようElastic Auto-Scalingを設定しました。
結論
私は、シンプルさこそが常に正解だと考えています。多くのキュー、バックグラウンドのWorker、複雑なデプロイを用いて複雑なシステムを構築することができますが、代わりにElasticbeanstalk auto-scalingの力と、Golangがもたらす即使用可能な並行処理に対する効率かつシンプルなアプローチを利用することに決めました。
私が現在使っているMacBook Proよりもよほど貧弱なマシンたった4台が、毎分100万回Amazon S3バケットに書き込んでいるPOSTリクエストを処理するなんて、そうそうあることではありません。
ジョブのための正しいツールは常に存在します。時折Ruby on Railシステムがとても強力なWebハンドラを必要とする時は、単純だけれど強力な代替可能なソリューションのためにrubyのエコシステムから少し離れて考えてみてください。

株式会社リクルート プロダクト統括本部 プロダクト開発統括室 グループマネジャー 株式会社ニジボックス デベロップメント室 室長 Node.js 日本ユーザーグループ代表
- X: @yosuke_furukawa
- Github: yosuke-furukawa
関連記事