2017年3月9日
ニューラルネットワークの動物園 : ニューラルネットワーク・アーキテクチャのチートシート(後編)
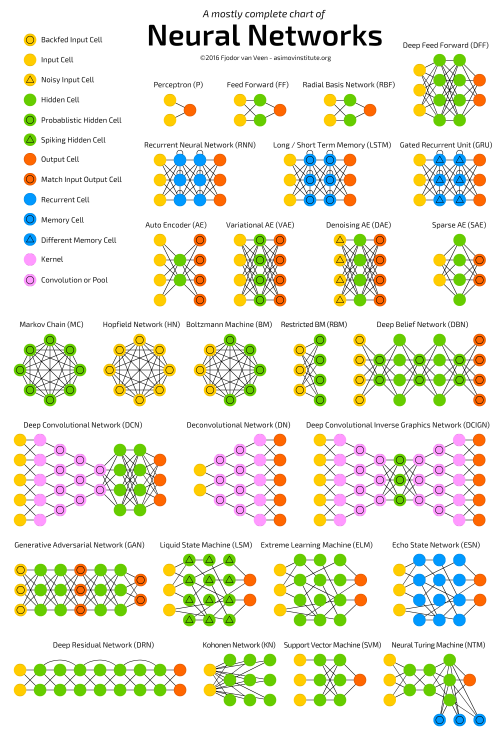
(2016-09-14)by FJODOR VAN VEEN
本記事は、原著者の許諾のもとに翻訳・掲載しております。
前編はこちら: ニューラルネットワークの動物園 : ニューラルネットワーク・アーキテクチャのチートシート(前編)

逆畳み込みネットワーク(DN) は、インバース・グラフィックス・ネットワーク(IGN)とも呼ばれていますが、畳み込みネットワークを逆転させたものになります。例えばネットワークに”猫”という言葉を入力すれば、生成した猫らしき画像と本物の猫の写真を比較しながら猫の画像を作成するよう訓練するようなイメージです。普通のCNNと同様にDNNをFFNNに組み合わせることができますが、新しい略語が見つかる時に線が描かれるところが特色です。深層逆畳み込みニューラルネットワークとでも呼べそうですが、FFNNの前後にDNNをつなげると、新しい名前をつけるにふさわしい別のアーキテクチャのネットワークができると主張できます。実際にはほとんどのアプリケーションにおいて、ネットワークにテキストに似たものが入力されるのではなく、どちらかと言うとバイナリ分類の入力ベクトルが与えられることにご注意ください。\<0,1>が猫で、\<1,0>が犬、\<1,1>が猫と犬だと思ってください。DNにおいては、一般的にCNNのプーリング層は同様の逆演算によって置き換えられます。この逆演算は主に、バイアスのかかった仮定(プーリング層でマックスプーリングが使用されている場合、それを逆にするにはより小さな値を独自に与えればよい)を基にした補間・補外です。
Zeiler, Matthew D., et al. “Deconvolutional networks.” Computer Vision and Pattern Recognition (CVPR), 2010 IEEE Conference on. IEEE, 2010.
原文PDF

深層畳み込みインバース・グラフィックス・ネットワーク(DCIGN) は、名前がミスリーディングを引き起こしています。実はこのネットワークはVAEで、エンコーダとデコーダとしてCNNとDNNがそれぞれ使用されています。エンコードの際に”特徴”を見込みでモデリングしようとします。これをすることで、猫と犬の画像を別々に見たとしても、猫と犬を一緒にした画像を作成することを学習できます。反対に猫と隣人の飼っている迷惑な犬が写った画像を入力し、実際の操作をしなくても犬だけを削除してもらうことができます。デモでは光源や3次元で回転させた物体を変化させるような、画像の複雑な変換もネットワークに学習させることが可能であることが確認されています。このようなネットワークはバックプロパゲーションを使用して訓練する傾向があります。
Kulkarni, Tejas D., et al. “Deep convolutional inverse graphics network.” Advances in Neural Information Processing Systems. 2015.
原文PDF

敵対的生成ネットワーク(GAN) は、異なる種類のネットワークで、2つのネットワークが一緒に機能しています。ネットワークの種類に関係なく、GANは2つのネットワークで構成されています(FFとCNNの組み合わせが多く見られます)。片方のネットワークでコンテンツの生成を実行し、もう片方のネットワークでコンテンツを判定します。生成ネットワークから識別ネットワークが訓練データか生成データのどちらかを受信します。識別ネットワークがデータソースを正しく予測できたかどうかが生成ネットワークの誤差の一部として使用されます。実データと生成データの区別をする弁別子と弁別子に予測されないように学習するジェネレータの間で競合関係が発生します。非常に複雑なノイズに似たパターンであっても最終的には予測可能であるため部分的にうまく機能しますが、特徴が類似した生成コンテンツを入力データと区別する学習は難しくなります。2つのネットワークを訓練するだけでなく(どちらかが問題となる可能性はありますが)、2つのネットワークを動的平衡状態にする必要もあるため、GANを訓練するのはかなり難しくなります。予測と生成のどちらかが比較的良くなってしまうと、本質的相違が出てくるためGANは収束しなくなります。
Goodfellow, Ian, et al. “Generative adversarial nets.” Advances in Neural Information Processing Systems. 2014.
原文PDF

回帰結合型ニューラルネットワーク(RNN) はFFNNに時間的ひねりを効かせたネットワークです。ステートレスではなく、パス間に時間を介した接続が存在します。情報は前の層からだけでなく、ニューロン自身の前のパスからも与えられます。つまり、情報の入力とネットワークの訓練の順番は重要になります。先に”牛乳”を入力して次に”クッキー”を入力した場合と、先に”クッキー”を入力して次に”牛乳”を入力した場合では結果は異なります。RNNの最大の問題の一つは、使用されるアクティベーション関数に応じて、非常に深層FFNNが深層情報を失うように、時間の経過とともに情報が急速に失われる、枯渇(または破裂)勾配問題があることです。直感的に言えば、これらは単に重みでありニューロンの状態ではないのであまり問題にはなりませんが、時間による重みは実際に過去の情報が格納されている場所のため、もしも重みが0あるいは1,000,000という値に達した場合、以前の状態は全く役に立たなくなります。使用しているほとんどのデータに時間的要素が(音や動画とは異なり)含まれず、シーケンスとして表されているため、基本的にRNNを多くの分野で使用することが可能です。写真や文字列を1ピクセルずつや1文字ずつ与えることができるため、時間に依存する重みはシーケンスの前の方のものに使用されても、x秒前に発生したことに使用されることはありません。一般的に回帰結合型ネットワークは自動補完のように、先回り情報や情報完成のために用いられます。
Elman, Jeffrey L. “Finding structure in time.” Cognitive science 14.2 (1990): 179-211.
原文PDF

長期・短期記憶(LSTM) ネットワークは、ゲートや明示的な記憶セルを導入することで枯渇(または破裂)勾配問題を解決しようとしています。発想はほとんどが回路に基づき、生物学的なものはほとんどありません。各ニューロンには記憶セルと3つのゲート(入力、出力、忘却)があります。それぞれのゲートは情報の流れを停止したり許可したりすることで情報を守る機能を果たしています。入力ゲートは前の層からどれだけの情報をセルに格納するか決定します。出力ゲートは反対に次の層にセルの状態をどれだけの情報として渡すかを決定します。一見忘却ゲートが存在することが異様に思えますが、忘れることがいいこともあります。例えば新しい本や章を学習する際に、前の章の文字などをネットワークが少し忘れる必要があるかもしれません。LSTMネットワークはシェイクスピアのような文章の作成や簡単な音楽の作曲といった複雑なシーケンスを学ぶことができることが分かっています。それぞれのゲートに前のニューロンのセルの重みを持っているため、実行により多くのリソースを必要とすることにご注意ください。
Hochreiter, Sepp, and Jürgen Schmidhuber. “Long short-term memory.” Neural computation 9.8 (1997): 1735-1780.
原文PDF

ゲート付き回帰ユニット(GRU) は、LSTMの変化形のネットワークになります。LSTMよりもゲートが1つ少なく、配線が少し異なります。入力ゲート、出力ゲート、忘却ゲートの代わりに更新ゲートがあります。更新ゲートは最後の状態からどれだけの情報を保持し、前の層からどれだけの情報を取り込むかを決定します。リセットゲートはLSTMの忘却ゲートのように機能しますが、位置付けが異なります。リセットゲートは常に完全な状態を発信しますが、出力ゲートはありません。多くの場合、LSTMのようにGRUは機能しますが、最大の違いはGRUの方が高速で簡単に実行できるところです(しかし、表現力は豊かではありません)。実際に使用してみると、例えば表現力を豊かにするために大規模なネットワークが必要になるため、パフォーマンスを犠牲にするといったように、長所によって短所は相殺される傾向にあります。表現力を必要としない場合においては、LSTMよりGRUの方がパフォーマンスが優れています。
Chung, Junyoung, et al. “Empirical evaluation of gated recurrent neural networks on sequence modeling.” arXiv preprint arXiv:1412.3555 (2014).
原文PDF

ニューラル・チューリング・マシン(NTM) は、抽象化したLSTMとブラックボックスの解明を試みるニューラルネットワークと思えば分かりやすいでしょう(そして、ブラックボックスの実態を少し見ることができるかもしれません)。記憶セルを直接ニューロンに符号化する代わりにメモリを分けます。これは通常のデジタルストレージの効率と永続性をニューラルネットワークの効率と表現力に組み合わせる試みです。目的は、連想メモリバンクとそこから読み込みや書き込みができるニューラルネットワークを持つことです。ニューラル・チューリング・マシンの”チューリング”はチューリング完全であることに由来しています。つまり、読み込み能力や書き込み能力、読み込みに基づく状態遷移は、ユニバーサルチューリングマシンによって表現できるものを表すことができるということです。
Graves, Alex, Greg Wayne, and Ivo Danihelka. “Neural turing machines.” arXiv preprint arXiv:1410.5401 (2014).
原文PDF
双方向回帰結合型ニューラルネットワーク、双方向の長期/短期記憶ネットワークおよび双方向ゲーテッド回帰ユニット(それぞれBiRNN、BiLSTM、BiGRU) は、一方向のものに形状がそっくりなため、記事の最初に載せた図には入れていません。これらのネットワークが違う理由は、過去につながっているだけでなく、未来にもつながっていることです。例えば、一方向のLSTMに文字を1つ1つ与えながら”魚”を予測させる訓練をさせた場合、時間が経っても回帰接続が覚えているのは最後の値になります。BiLSTMもシーケンスの次の値をバックワードパスによって与えられ、未来の情報へのアクセスが可能になります。このような訓練はネットワークに先回り情報を得る代わりにギャップを埋めるように学ばせるため、画像の隅を拡大するのではなく、画像の中心の空洞を埋めることができるようになります。
Schuster, Mike, and Kuldip K. Paliwal. “Bidirectional recurrent neural networks.” IEEE Transactions on Signal Processing 45.11 (1997): 2673-2681.
原文PDF

ディープ・レジデュアル・ネットワーク(DRN) は、とても深いFFNNで、入力を層から先の層(大抵2から5層先)や次の層へとパスできる接続を追加で持っています。いくつかの入力を5つのレイヤーに渡っていくつかの出力にマッピングする方法を探す代わりに、ネットワークはいくつかの入力をいくつかの出力といくつかの入力にマッピングすることを学ぶように強制されます。基本的には、解決策にアイデンティティを追加し、古い入力を持ち越して後のレイヤーに新たに与えます。このようなネットワークは、最大150層までのパターンを非常に効果的に学習することができ、通常の2から5層を学習するものよりもはるかに優れていることが示されています。しかし、これらのネットワークは本質的に明示的な時間ベースの構築されていないRNNであることが実証されており、しばしばゲートのないLSTMと比較されます。
He, Kaiming, et al. “Deep residual learning for image recognition.” arXiv preprint arXiv:1512.03385 (2015).
原文PDF

エコー・ステート・ネットワーク(ESN) は、さらに異なるタイプの(回帰結合型)ネットワークになります。このタイプのネットワークはニューロン間にランダム接続を持ち(つまり、きちんとした層群に編成されていません)、異なる方法で訓練されています。入力してバックプロパゲーションでエラーをみつけるのではなく、入力した情報を転送しニューロンを少しの間更新し、時間の経過とともに出力を観察します。入力層はネットワークを下塗りするために使用され、出力層は時間をかけて展開するアクティベーションパターンを観察するオブザーバ役を務めます。このように、入力層と出力層は少し型破りな役割を担っています。訓練の際、オブザーバと隠れユニット(の集合体)間の接続のみが変更されます。
Jaeger, Herbert, and Harald Haas. “Harnessing nonlinearity: Predicting chaotic systems and saving energy in wireless communication.” science 304.5667 (2004): 78-80.
原文PDF

エクストリーム・ラーニング・マシン(ELM) は、基本的にはFFNNですが、ランダム接続になります。LSMやESNに非常によく似ていますが、回帰も活動電位もありません。バックプロパゲーションも使用しません。その代わり、ランダムな重みから始め、(関数の中でも最も誤差が小さい)最小二乗法に従って重みを1段階ずつ訓練していきます。結果としては表現力のあまりないネットワークができますが、バックプロパゲーションより断然高速です。
Cambria, Erik, et al. “Extreme learning machines [trends & controversies].” IEEE Intelligent Systems 28.6 (2013): 30-59.
原文PDF

リキッド・ステート・マシン(LSM) も同じようなもので、ESNに良く似ています。違いは、LSMが急増型のニューラルネットワークであることです。シグモイド関数は閾値関数に置き換えられ、各ニューロンも蓄積記憶セルです。そのため、ニューロンが更新されると、隣接するニューロンとの合計数にはならず、独自に蓄積された数になります。閾値に達するまで何も起きませんが、閾値に達すると他のニューロンへ放出されるため、急上昇したかのようなパターンを描くのです。
Maass, Wolfgang, Thomas Natschläger, and Henry Markram. “Real-time computing without stable states: A new framework for neural computation based on perturbations.” Neural computation 14.11 (2002): 2531-2560.
原文PDF

サポート・ベクター・マシン(SVM) は、分類問題の最適な解決策を探します。古くからネットワークは線形分離可能なデータしか分類できませんでした。例えば、ガーフィールドの画像とスヌーピーの画像は探せるけど、その他の画像は探せないといったように。訓練の時、SVMは全てのデータ(ガーフィールドとスヌーピー)を2Dのチャートに記入し、各データポイント間にどのように線を引けばいいか考えます。引かれた線によってデータは分けられることになります。つまり、スヌーピーは線の片側に、その反対側にガーフィールドが集められます。この線は、データ点と線の間の余白が両側で最大になるように最適な線に移動します。新たなデータを分類するにはこのグラフに点を記入し線のどちら側(スヌーピー側かガーフィールド側)にあるかを見ればいいのです。カーネル法を使用すれば、n次元でのデータ分類を教えることができます。これにより3D描画での表示ができるようになり、スヌーピーとガーフィールド、そしてSimon’s Catも区別できるようになります。さらには、より高い次元でより多くの漫画のキャラクタを区別することができるようになります。SVMはニューラルネットワークと考えられていない場合もあります。
Cortes, Corinna, and Vladimir Vapnik. “Support-vector networks.” Machine learning 20.3 (1995): 273-297. 原文PDF

そして最後の コホネンネットワーク(KN、さらに自己組織(機能)マップであるSOM、SOFM) で動物園は完成です。KNは競合学習を使用して教師なしにデータを分類することを学ぶことができます。入力によって提供される情報をネットワークは後でどのニューロンが入力に一致するのか評価します。ニューロンはさらに入力データに一致するよう調整されますが、その過程で隣接するニューロンも巻き込まれてしまいます。隣接のニューロンがどれだけ移動することになるかについては、一致するニューロンの位置によって異なります。KNもニューラルネットワークと考えられていない場合があります。
Kohonen, Teuvo著、「位相幾何学的に正しい機能マップの自己組織の形成」、Biological cybernetics 43.1 (1982年): 59-69.
原文PDF
ご意見や批評などお聞かせください。Asimov Instituteは深層学習の研究や開発を行っています。ぜひ Twitter でフォローして今後の更新や投稿をご確認ください。お読みいただきありがとうございました。

株式会社リクルート プロダクト統括本部 プロダクト開発統括室 グループマネジャー 株式会社ニジボックス デベロップメント室 室長 Node.js 日本ユーザーグループ代表
- X: @yosuke_furukawa
- Github: yosuke-furukawa
関連記事






{kind=link}