2016年10月25日
バックグラウンドジョブの改善によってRailsのパフォーマンスを高める
本記事は、原著者の許諾のもとに翻訳・掲載しております。
スケーラビリティの実現は簡単だという発想は、珍しいものではありません。 Heroku などのホスティングサービスを利用していれば、ほんの数回クリックするだけで、アプリケーションにRAMやCPUなどのリソースを追加できますよね。確かにインフラストラクチャをアップグレードするのは有効な選択肢ではありますが、現在稼働しているアプリケーションのほとんどは、コードの書き方を工夫するだけでもスケーラビリティを高められると私は考えています。
利用可能なリソースをより効率的に使う方法について、以下にヒントを幾つか紹介しますので、しっかりついて来てください。あなたのプロジェクトの経費を節約できるかもしれません。

出典: https://freecrmstrategies.files.wordpress.com/2010/11/rowing_crew.jpg
バックグラウンドジョブに注目する
これまでにも恐らく、何かのツールを使って、バックグラウンド処理の制御を試みたことはあるでしょう。それ自体は本当に素晴らしいことです。つまり、演算負荷の高いタスクをバックグラウンドで実行するジョブに割り振ることで、アプリケーションの応答時間を短縮できます。
応答時間を短縮すると スループット が上昇します。サーバ内の各インスタンスが処理するリクエストの1秒当たりの数が増えるためです。いいですね、アプリケーションWebサーバが早くもスケールされていますね。でもワーカインスタンスはどうでしょうか。こんなにたくさんの処理をどのくらいタイムリーにこなしているのでしょう。
適切なアプローチを取らないと、この問いへの回答は単純明快に「あまり対応できていない」ということになりがちです。このことを念頭に置きながら、私のチームがどうやってリファクタリングに成功したかを説明します。以前はバックグラウンドジョブのアーキテクチャにスケーラビリティがなく、処理が全面的に停止してしまうようなこともありましたが、リファクタリングの結果、今では信頼性が以前に比べて格段に向上したという実績を挙げていますし、リソースの使用量も最低限で維持しています。
何よりもまず、アプリケーションに何らかの最適化を実行するためには、パフォーマンスをとにかく何度も測定することです。最適化の際に使える武器の中で、最も重要で役に立つものは測定値です。よく覚えておいてください。測定値の取得には、私は New Relic を使うことが多いのですが、選択肢は他にもたくさんあります。
本番環境で発生した事態
リクエストされた機能は、購読ユーザのリスト宛てに、ユーザの興味を引きそうなコンテンツを含むメールを送信するという、恐ろしいほどシンプルそうな処理です。お茶の子さいさいですね。購読ユーザ全員を対象とするクエリを実行し、各ユーザに合わせたコンテンツを収集し、そのメールを直ちに送信しましょう。このような単純なタスクを急いで実行するには、以下のコードを書けば終わりです。
開発環境でこのコードをテストした時には、うまく動作しました。そこで本番環境にこれをデプロイしたところ、ジョブが起動したとたんに問題が発覚しました。ユーザには同じメールが何度も送信され、Herokuは R14エラー(メモリの割り当て量を超過している) を出力して悲鳴を上げ、それ以降はありとあらゆるエラーが出続けました。いったい何が間違っていたのでしょう。
Herokuの測定値を詳しく検討すると、最大の問題点はどうやらメモリ消費量のようです。R14エラーは深刻な事態を示しています。利用可能なRAMがなくなると、アプリケーションはスワップメモリを使い始めるからです。Heroku上のスワッピングは驚くほど低速で、このために原因不明のエラーがよく発生します。
さあ、この混乱をすっきりさせよう
この問題に適切に取り組むために、できるだけ本番に近い開発環境をセットアップしようとしました。簡単に言えば、productionフラグを使ってサーバを実行し、できる限り同じ環境変数をセットします。また データベースダンプのインポート を忘れないでください。
開発環境で検証を行う場合には、たいてい UNIXの top コマンド を使って有益な情報を得ることができます。このコマンドは、対象となるプロセスの多くの測定値を示しますが、簡単にするため、メモリに注目します。
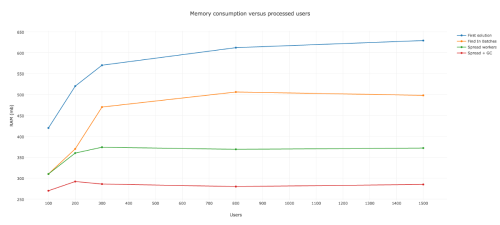
そこでアプリケーションを起動し、モニタリングを開始しました。最初はメモリ消費量が急速に増加し、ユーザプロセスがちょうど200の時点で約520MBのRAMを食いました。ユーザプロセスが1000を超えた後も、非常にゆっくりではありますが、なおも増え続けていました。
注釈:
メモリ消費量とユーザプロセス数
これで、Heroku上で問題が起きた理由は明らかですね。約200のユーザプロセスで利用可能なRAMを全て使い切ってしまったので、スワッピングが始まりました。ワーカが停止し、再起動する前に、800未満のユーザプロセスを管理していたのは間違いありません。この動作により、ユーザは同じメールを何度も繰り返し受け取るはめになりました。
オブジェクトのインスタンス化の制御
そうです。ActiveRecordに注目しています! 全購読ユーザをクエリすることは明らかに名案とはいえません。というのもRailsがクエリのたびに、試行しインスタンス化するからです。しかし簡単な解決策があります。ActiveRecordの find_in_batches メソッドです。また他にも利点があります。 find_in_batches に対する引数としてバッチサイズを設定すると、いろいろなサイズを試すことができるのです。
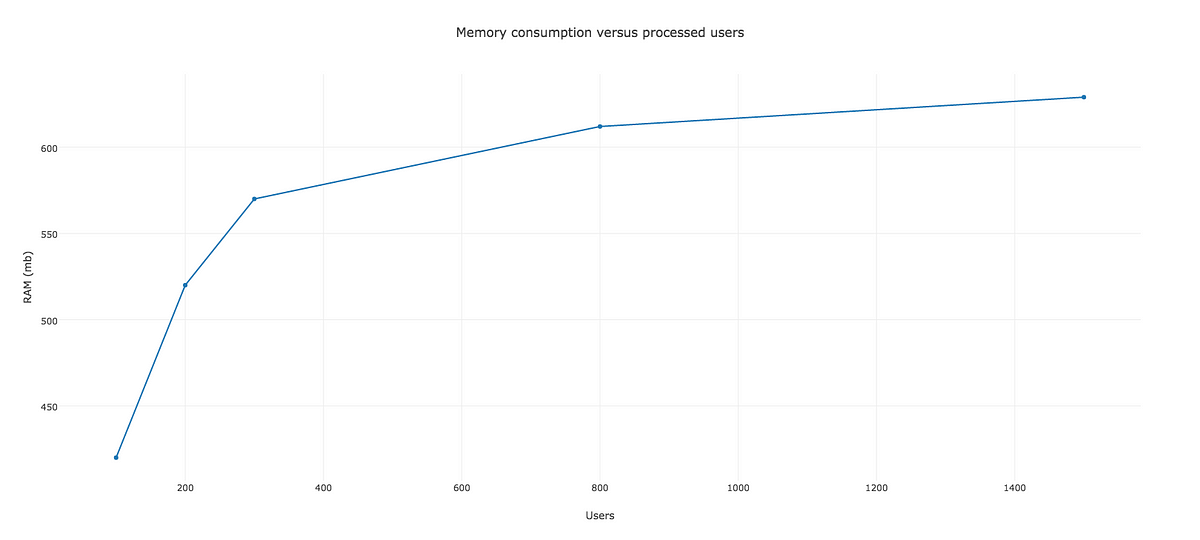
要するに、バッチプロセスによって、一括でレコードを処理することができるのです。この方法によって、インスタンス化するオブジェクトをより少なくし、メモリ消費量をかなり削減します。この便利な方法で、バックグラウンドジョブを書き直し、より良い結果を得ることができました。バッチサイズを100にすると、HerokuのワーカでRAMの使用量を512MB以下に抑えることができます。
新しいコードと測定値は以下のようになります。
注釈:
メモリ消費量とユーザプロセス数
さて、早くも改善しました。恐らく本番環境で正しく実行できるでしょう。メモリ消費量も安定し、512MBを超えることは無いと思われます。しかし、さらに改善できることが分かっています。上限を超えていないことが、十分だとも安全だとも言えません。
バックグラウンドジョブ、正常に動作!
バックグラウンドジョブでかなり多くの処理を行っていたことに気がついたかもしれません。そこでは、全購読ユーザの取り込みと全員のメール送信を処理します。他のクラスと同じで、ワーカが行う処理は非常に特化したものでなければいけません。その点を考慮して、私たちは新しいアーキテクチャを選びました。つまり、巨大なワーカ1つに全てを任せるのではなく、きっちり1つの処理をする何百もの小さなワーカを持つことにしたのです。
この真の意図は、メールを送るユーザごとにワーカを1つ持つということです。この新しい手法には、スケーラビリティに対して幾つかの利点があります。例えば、ひょっとするとアプリケーションが、複数の種類のバックグラウンドジョブを持っており、そのジョブはユーザがアプリケーションと互いにやりとりしながら、ランダムに実行する必要があるかもしれません。長時間実行している巨大なバックグラウンドジョブがあると、リソースにもよりますが、他のジョブを実行する空きスロットが無く、Webサーバ上で原因不明のエラーに陥ります。
また、このアプローチによって、オブジェクトのインスタンス化を改善することもできます。すごいですね! それは、もう1つの素晴らしいActiveRecordのメソッド pluck を使う方法です。これにより、インスタンス化されたユーザの代わりにユーザIDの配列を取得でき、各IDを新しいContentSuggestionWorkerに引数として渡すことができます。ここで、私たちの新しいワーカをキューに加える別のエンティティを書いてみました。
特化されたワーカを使うことの利点を他にも挙げると、ついに retryオプション を使えるようになることです。各ワーカは1ユーザだけを処理するので、このオプションをFalseに設定すれば、ワーカが処理しているユーザだけに影響することになり、私たちとしてはこの仕様で特に問題は無いと考えます。
以前のワーカにおいて、エラーの際にretryしないようにSidekiqを設定することは不都合でした。なぜなら、未処理のユーザは、どんなエラーが起きても何のサジェストも受け取れなくなってしまうからです。それは望ましい状況ではありません。一方で、retryをTrueにしておけば、エラーが起きた際に、処理されたユーザはメールを繰り返し受け取ることになります。
この変更を加えた結果は次のようなものです。
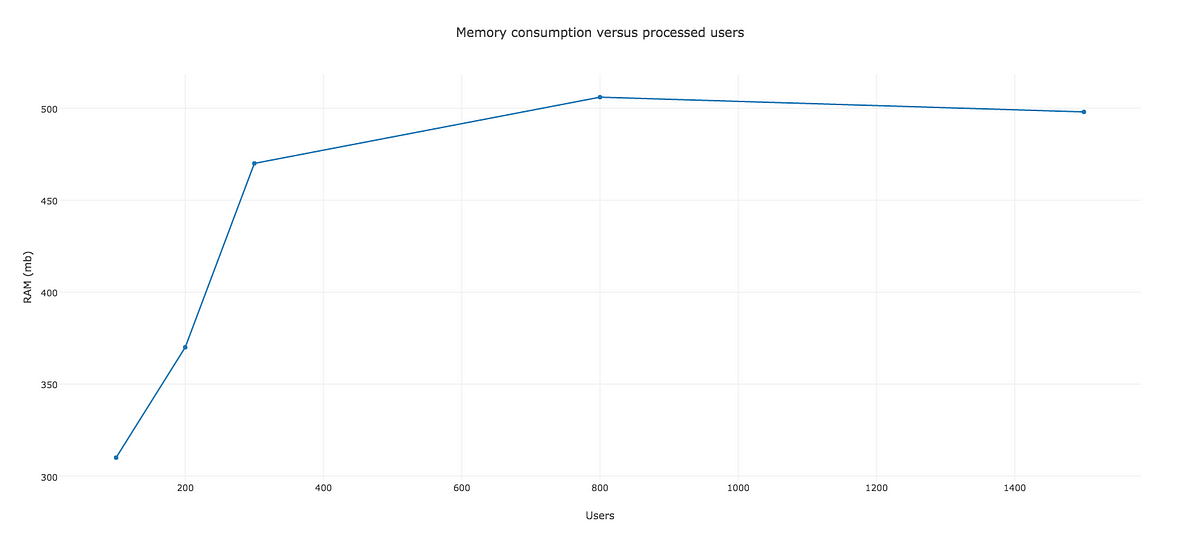
注釈:
メモリ消費量とユーザプロセス数
最大値は372MBあたりで、以前よりも改善されています。もう512MB近くまで上昇することはありません。やりましたね! しかし、まだこれで終わりではありません。こうした結果から、次に目指すべき方向の手掛かりが得られました。
Collect that garbage!
複数のワーカに負荷を分散することで、ガベージコレクタがより良い仕事ができるようになります。その仕事とは、メモリヒープに割り当てられて使用されていない領域を開放することです。というのも、ワーカに関連するオブジェクトは、実行を終えるとすぐにスイープされるという理由が背景にあるからです。先ほどの解決法で、メモリ消費量を削減したことに似ています。
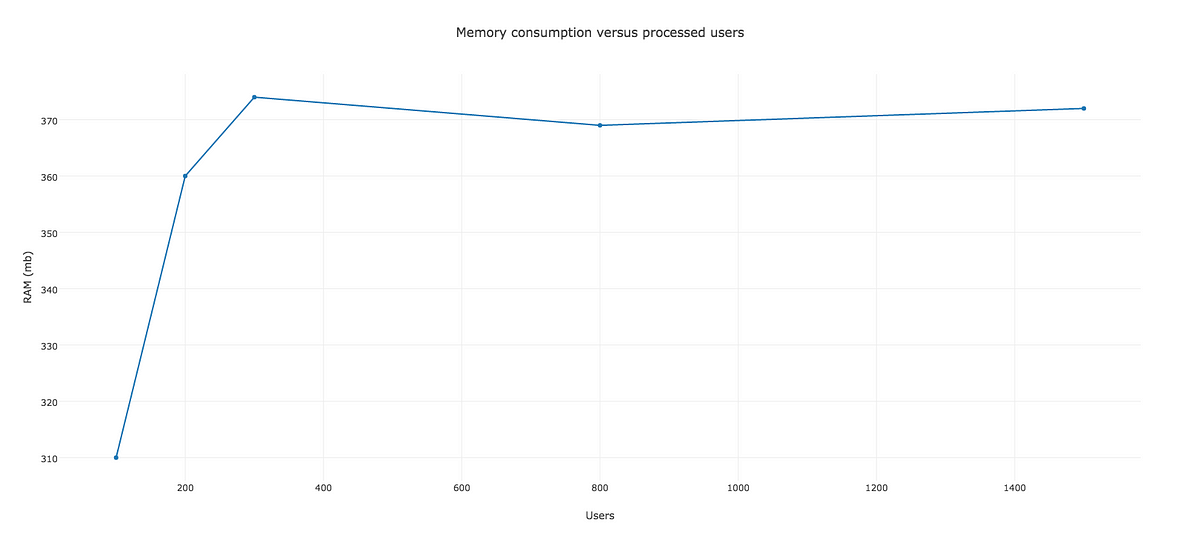
こうした観点から、このガベージコレクションをその限界まで使って、何ができるかを見てみることに決めました。簡単に言えば、各ワーカの終了時に、メジャーGCに強制的にスイープさせたのです。どうなるのか見てみましょう。
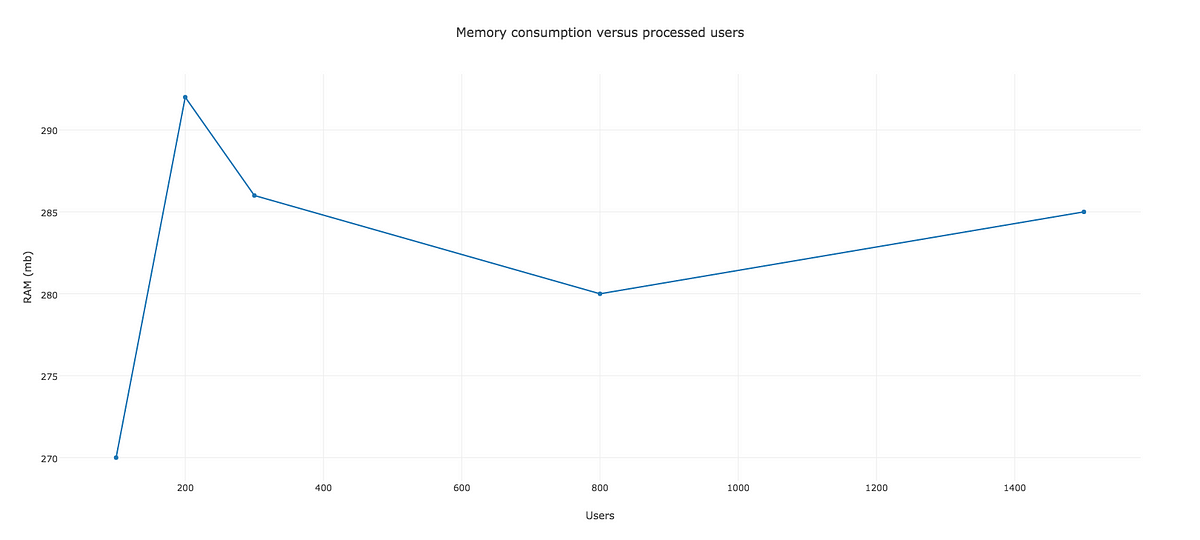
注釈:
メモリ消費量とユーザプロセス数
まさに、これぞ改善と言うものですね。これなら、私たちのジョブは、処理すべき他のルーチン用に十分なスペースを残しつつ、メモリ消費量を300MB以下に何とか抑えたと言えます。
メジャーGCにそんなに多くのスイープを強制するなんて、あまりいい考えではない 、と言う人がいるかもしれません。この意見には心から同意しますが、これはあくまで、私たちの解決策の影にあるコンセプトを示す単なる一例に過ぎません。GCにあまりスイープさせないようにするとどうなるのか、自由に試して確かめてみてください。とにかく、測定を忘れないようにしてくださいね。
おまけの情報
Ruby 2.1+では、ガベージコレクションのチューニングに役立つ環境変数が数多く提供されているので、更にいろいろと実験できます。 Thorsten Ballの投稿 や、 Sam Saffronの投稿 といった、このテーマに関する素晴らしいリソースがあります。また、あなたのアプリケーションのニーズに最適なGCを決める手助けとなる、 TuneMyGC と呼ばれる素晴らしいgemもあります。試してみてください。
Sidekiqの同時並行性は、メモリにおいても大きな役割を果たします。同時並行性の設定が高ければ、アプリケーションは食欲旺盛になります。なぜなら、より多くの処理やインスタンス化が生じるためで、これには注意したほうがよいでしょう。同時並行性の設定を低くするだけで、十分にリソースを節約することになる場合もあります。
結局、ContentMailerにユーザIDだけを渡して、ユーザのインスタンス化を処理させるということは良い考えかもしれません。このように、私たちは複雑な引数を渡さないようにしますが、これは通常 グッドプラクティス であり、とりわけ、Sidekiqワーカの中ではそう言えます。
まとめ
ご紹介した例は作り話のように思えるかもしれませんが、どうか誤解しないでください。簡単なコードの変更をするだけで、パフォーマンスを向上させ、メモリ消費量を抑えることができたのです。私たちの様々な解決策を比較したグラフを見てください。
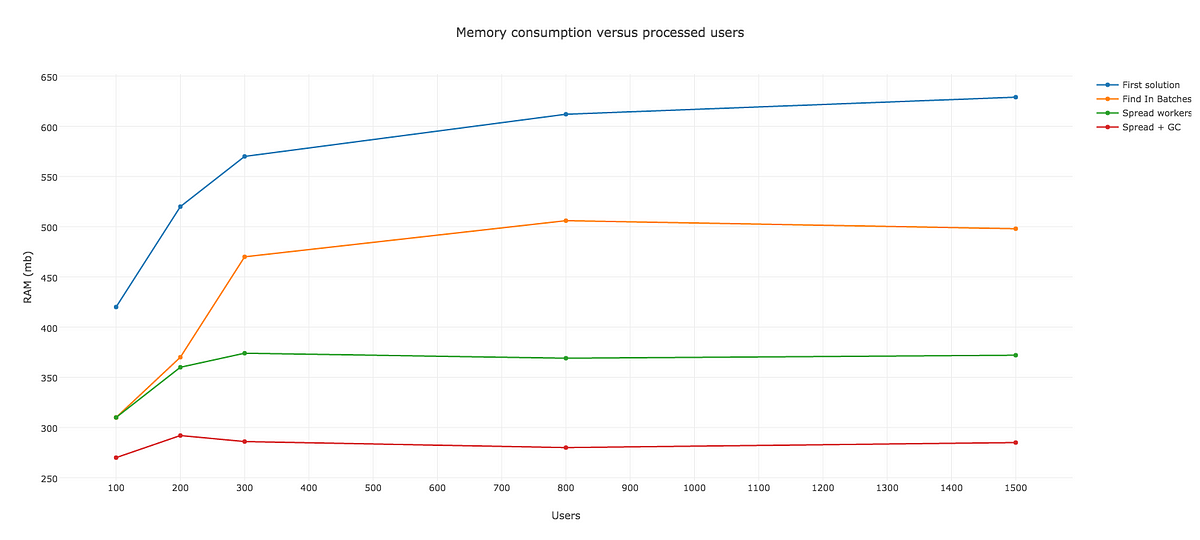
注釈:
メモリ消費量とユーザプロセス数
注釈:
最初の解決策
バッチによる解決策
ワーカの分散
分散+GC
スケーラビリティの向上を模索する旅はまだ終わっていません。私たちはまだいくつかの策を隠し持っています。しかし、それは私たちのアプリケーションの他の領域の改善にも関係することなので、また別の投稿で紹介することにします。それでは、次回にご期待ください。

株式会社リクルート プロダクト統括本部 プロダクト開発統括室 グループマネジャー 株式会社ニジボックス デベロップメント室 室長 Node.js 日本ユーザーグループ代表
- X: @yosuke_furukawa
- Github: yosuke-furukawa
関連記事









{kind=link}