2016年9月16日
Go言語の低レイテンシGC実現のための取り組み
(2016-07-06)by Rhys Hiltner
本記事は、原著者の許諾のもとに翻訳・掲載しております。
(訳注:2016/9/28、頂きましたフィードバックを元に記事を修正いたしました。)
私たち Twitch では、通信が大変混み合うシステムの多くで Go を採用しています。ライブ映像を配信したり、何百万人というユーザにチャットサービスを提供したりする場合に直面する問題を考慮すると、Goはそのシンプルさや安全性、パフォーマンス、読みやすさの点で良いツールだと言えます。
しかしこれは、私たちにとってGoがいかに素晴らしいツールかを説明する、よくある記事ではありません。Goで現在実装されているランタイムにより行き詰まったいくつかの局面をどう打開するか、さらに、私たちはそうした限界に達した時にどう対応したらいいのかについて書いたものです。
これからお話しするのは、「Go 1.4からGo 1.6へのGoランタイムの改善が、どのようにしてガベージコレクション(GC)の停止時間を20倍も改善することにつながったのか」、「Go 1.6での停止時間はどのようにしてさらに10倍も改善したのか」、そして「私たちの経験をGoランタイムのチームに共有したことが、Go 1.7においてマニュアルチューニングなしにさらに10倍にスピードアップしたことにどのように貢献したのか」についてです。
GCレイテンシの話
私たちのIRCベースのチャットシステムは、2013年後半に初めてGoで書かれ、それまでのPythonによる実装と置き換わりました。Go 1.2のプレリリース版を使って、特別なチューニングをせずに、物理ホストそれぞれから50万人以上のユーザに対し同時にサービスを提供することができました。各接続にサービスを提供する3つのgoroutine(Goの軽量スレッド)のグループで、プログラムは1プロセスにつき150万のgoroutineを使って順調に処理を行っていました。このように大きな数のgoroutineを使っていたにもかかわらず、このリリース前のGo 1.2でパフォーマンスに関して直面した問題は、GCが実行されると必ず数十秒間アプリケーションがフリーズすることになるGC停止時間だけでした。しかし、この問題は、対話型チャットサービスを提供する側としては見過ごすわけにはいきませんでした。
GC停止の1つ1つに非常に高いコストがかかっただけでなく、GCが1分間に数回実行されているのです。そこで私たちは、GCがそんなに多く実行されないよう、メモリ割り当ての数やサイズを減らそうと懸命に取り組みました。ヒープは2分ごとに約50%だけでも拡大した時点で成功だと言えます。停止の頻度は減ったものの、1つ1つの停止は依然として大変な打撃でした。
Go 1.2のリリース版では、GC停止時間は”たった”数秒に減ってはいました。しかし私たちは、より多くのプロセスにわたってトラフィックを分けることで、停止時間をもっと快適だと思える範囲まで減らしたのです。
割り当てを減らす作業は、Goの実装が進化していくにつれ、私たちのチャットサーバに利益をもたらし続けています。しかし、より多くのプロセスにわたってチャットトラフィックを分けるという変更は、いくつかバージョンのあるGoの中でも特殊な範囲を対象にした回避策です。こうした回避策は時の流れに耐えられないものですが、今日の私たちのユーザに良いサービスを提供するためには重要なものです。しかも回避策の経験をシェアすれば、複数のプログラムに利益をもたらすGoランタイムの持続可能な改善を生み出すのにも役立ちます。
2015年8月時点のGo 1.5以降では、ガベージコレクタは並行して行われ、インクリメンタルになっています。つまり、アプリケーションが大部分の作業を行っている最中に完全な停止を余儀なくされるということは、もはやないのです。比較的短いセットアップや終了フェーズはさておき、私たちのプログラムはガベージコレクションが進行する間もオペレーションを継続することができます。Go 1.5にアップグレードするとすぐに、私たちのチャットシステムでのGC停止時間は10倍も向上しました。負荷の高いテスト用のインスタンスでは、停止時間は2秒から200ミリ秒にまで少なくなりました。
GCの新時代、Go 1.5
Go 1.5で獲得したレイテンシの短縮は称賛に値するものでしたが、この新たなGCが本当に素晴らしかったのは、以降も徐々に改善が進むためのお膳立てをしたことでした。
Go 1.5のガベージコレクタには、依然として同じ2つの主なフェーズがあります。どのメモリ割り当てをまだ使っているかをGCが判断するマークフェーズと、使われていないメモリを再利用のために用意するスイープフェーズです。しかし、これらはそれぞれが2つのサブフェーズに分割されています。最初、その前のスイープフェーズが終了する間に、アプリケーションが停止されます。次に、ユーザコードが実行されている間に、並行してマークフェーズが使用中のメモリを検索します。最後に、マークフェーズが終了するために、もう一度アプリケーションが停止されます。その後、アプリケーションが起動する間に、使われていないメモリが徐々にスイープされます。
ランタイムの gctrace 機能は、各フェーズの時間を含め、各GCサイクルを要約した行を表示してくれます。私たちのチャットサーバでは、残った停止時間のほとんどがマーク終了フェーズで起こっていることが分かったので、その点を中心に分析する必要があります。ランタイムチームは、いまだに長いGC停止が起こるアプリケーションについて説明するバグレポートを要求していましたので、私たちも停止時間が長かったという結果を秘密にするのは怠慢だと思ったのです。
もちろん、そうした停止中に、GCが正確には何をやっていたのかをより詳しく知る必要があります。Goのコアパッケージには優れた ユーザレベルのCPUプロファイラ が含まれていますが、ここでは私たちはLinuxの perf ツールを使おうと思います。 perf ツールを使うと、より高頻度のサンプリングが可能ですし、カーネル内で費やされた時間を可視化してくれます。カーネルで費やされたサイクルを観察することが、時間のかかるシステムコールをデバッグし、仮想メモリ管理を透過的に行うことに役立ちます。
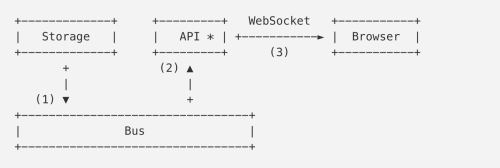
下の画像は、Go 1.5.1で実行されている私たちのチャットサーバのプロファイルの一部です。これは、 Brendan Gregg氏の開発したツール で作成した flame graph で、スタックにおける runtime.gcMark 関数を含むサンプルだけが含まれるように切り取ったものです。Go 1.5のものでは、マーク終了フェーズで費やされた時間の近似値が出されています。
このflame graphは、下から上に伸びるほどスタックが深いことを、各セクションの幅がCPU時間を表しています(色に意味はなく、x軸の順序も重要ではありません。これは単なるアルファベット順です)。グラフの左の方で、 runtime.gcMark がサンプリングされたスタックのほとんど全てで runtime.parfordo を呼び出していることが分かります。上の方に目を向けると、 runtime.markroot が runtime.scang 、 runtime.scanobject 、 runtime.shrinkstack を呼び出すためにほとんどの時間が費やされていることも分かります。
runtime.scang 関数は、マークフェーズの終了を補助するためにメモリを再スキャンするためのものです。マーク終了フェーズで行うことというと、基本的な考え方としては、アプリのメモリのスキャンを終了することです。そのため、これはここで行われることとしては適切な作業だと言えます。パフォーマンスを改善すべき箇所は他の関数について探した方がよいでしょう。
次は、 runtime.scanobject です。この関数が行うことはいくつかありますが、Go 1.5でチャットサーバのマーク終了フェーズの間に実行している理由は、ファイナライザを実装するためです。「なぜプログラムは、GCの停止時間に大きく影響するにもかかわらず、それほど多くのファイナライザを使うのだろう?」と、不思議に思うかもしれません。問題となっているアプリケーションは、チャットサーバで数十万人のユーザを扱うものです。Goのコアパッケージの1つである”net”パッケージには、ファイルディスクリプタのリークを制御するため、全てのTCP接続にファイナライザが付されています。各ユーザがそれぞれのTCP接続を確立するので、小さなマーク終了であっても積み重なって大きく影響するのです。
このことは、Goランタイムチームに報告する意味があると思われました。メールでやり取りをしたところ、Goチームはパフォーマンスの問題を起こしている原因を突き止め、そこから無駄なものを除いて最小限のテストケースにする方法を考え出す際に、大変協力してくれました。Go 1.6では、ランタイムチームは、並行するマークフェーズにファイナライザスキャンを移動し、TCP接続の多いアプリの停止時間がより短くなることにつなげました。その他にも改善されたことの全てが相まって、Go 1.6リリース版では、私たちのチャットサーバの停止時間はGo 1.5の場合の半分になり、テストインスタンスでは約100ミリ秒まで下がっていました。進歩しています!
スタックの縮小
Goは並行処理に対応しているので、多数のgoroutineを扱うことのコストは非常に低くなっています。1つのプログラムで10,000個のOSスレッドを使うとパフォーマンスが悪くなるかもしれませんが、同じ個数のgoroutineを使うのは少しも珍しいものではありません。1つ違うのは、goroutineは、わずか2kBという非常に少ないスタックで始まり、必要に応じて増えていきます。これは、よくあるどこかの大きな固定サイズのスタックとは対照的です。Go関数の呼び出しのプリアンブルは、次の呼び出しのためのスタックスペースが十分にあるかどうかを確認するのですが、もし十分にない場合は、呼び出しを継続する前に、必要に応じてポインタを書き換えてgoroutineのスタックをよりメモリの大きな領域へと 移動させます 。
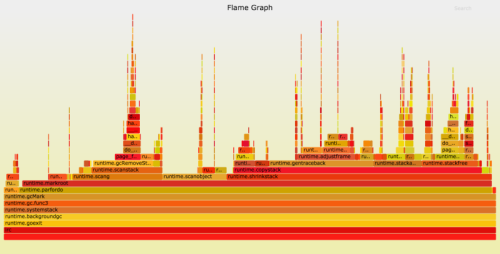
こうしてプログラムが実行されると、そのgoroutineのスタックは生成される最も深い呼び出しをサポートするために大きくなります。ガベージコレクタの役割の1つは、もはや要求されなくなったスタックメモリを再要求することです。goroutineスタックをより適切なサイズのメモリ範囲に移動するというタスクは、 runtime.shrinkstack により行われます。Go 1.5と1.6では、アプリケーションが停止している間ではありますが、マーク終了の間に行われます。
上のflame graph は、2015年10月時点のGo 1.6のプレリリース版で記録されたものです。このサンプルで4分の3ほどの幅を占めているのが runtime.shrinkstack です。これによる作業がアプリケーションの実行中に行われれば、私たちのチャットサーバや他にもある似たようなプログラムで効果的なスピードアップが見込めます。
Goのランタイムパッケージのドキュメントには、スタックの縮小を無効にする方法も記載されています。私たちのチャットサーバの場合は、メモリをいくらか無駄にすることで、コストをかけずにGC停止時間を減らすことができます。私たちは、Go 1.6を実行する際にはそのようにしようと決定しました。スタックの縮小を無効にすると、チャットサーバの停止時間は、その時の状況に応じて、また半分となる30~70ミリ秒ほどになります。
チャットサービスの構成とオペレーションを相対的に一定に保ちながら、Go 1.2からGo 1.4まででは数秒のGC停止時間を我慢していました。それが、Go 1.5では約200ミリ秒、Go 1.6ではさらに約100ミリ秒にまで削減されました。今では、通常、停止時間は70ミリ秒に満たないほどであり、30倍以上も改善されたと言うことができます。
とはいえ、おそらく改善の余地はまだあります。次は、別のプロファイルをやってみましょう!
ページフォールト!?
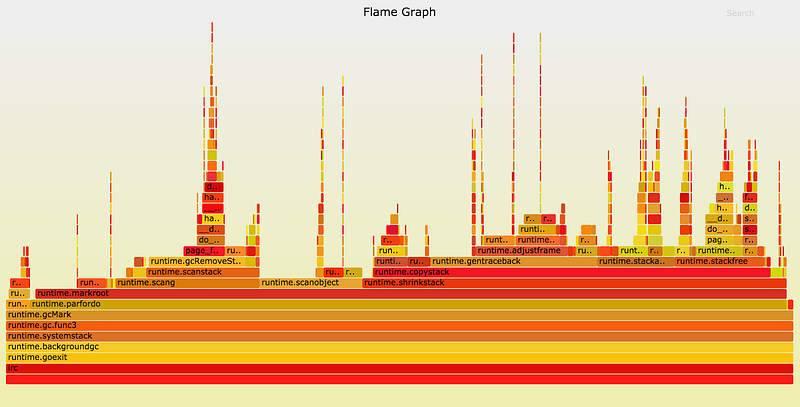
GCの停止時間はこの時点までかなり安定していましたが、今では gctrace の他の出力とは関係なく広い範囲(30~70ミリ秒)に分散しています。以下は、比較的長いマーク終了停止の間に費やされたサイクルのflame graphです。
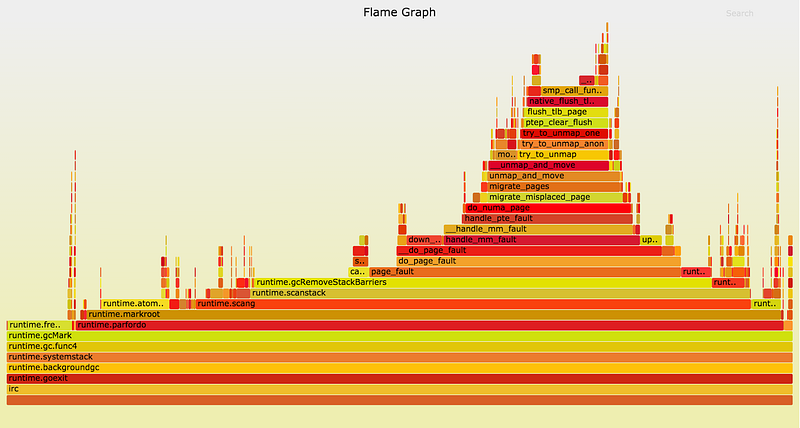
GoのGCが runtime.gcRemoveStackBarriers を呼び出す時、システムはページフォールトを発生させます。そしてカーネルの page_fault 関数が呼び出されるので、グラフの中央右側にある幅の広い高い山ができています。ページフォールトは、カーネルが仮想メモリ(多くは4kB)のページを物理RAMの一部にマップする方法です。プロセスはしばしば、巨大なサイズの仮想メモリを割り当てることを許されており、その仮想メモリはプログラムからアクセスされた時だけページフォールトを介して常駐メモリに変換されることになります。
runtime.gcRemoveStackBarriers 関数はスタックメモリを変更しますが、これはプログラムから直前にアクセスされているはずです。実際、この関数の目的は、ほんの何秒か前にそのGCサイクルの冒頭で追加されたスタックバリアを取り除くことなのです。システムは、物理RAMをよりアクティブな他のプロセスに割り当てなかったので、利用できるメモリをたくさん保持しています。それではなぜ、このメモリが使えるのにページフォールトが発生するのでしょうか?
当社のコンピューティングハードウェアの環境が参考になるかもしれません。私たちがチャットシステムの実行に使っているサーバは、最新式のデュアルソケットマシンです。各CPUソケットには、直接接続されたメモリバンクがいくつかあります。この構成によって、メモリへのアクセスはNon-Uniform Memory Access( NUMA )となっています。あるスレッドがソケット0のコアで動作する時、そのソケットに接続されている物理メモリへのアクセスは高速となり、他のメモリへのアクセスはやや遅くなるのです。Linuxカーネルは、スレッドが使うメモリの近くでスレッドを実行することで、また関連スレッドが動作している場所の近くに物理メモリページを移すことで、そのレイテンシを低減させようとします。
以上のことを考慮すると、カーネルの page_fault 関数の振る舞いがより詳しく見えてきます。コールスタックをさらに細かく見てみると(flame graphの上方を見てみると)、カーネルが do_numa_page と migrate_misplaced_page を呼び出していることが分かります。これは、カーネルがプログラムのメモリを物理メモリバンク間で移していることを示しています。
Linuxカーネルは、GCのマーク終了フェーズのほぼ無意味なメモリアクセスパターンを検知し、それにマッチさせるために、多大なコストをかけてメモリページを移動しているのです。この振る舞いは、Go 1.5.1のflame graphではごくわずかに表れているだけですが、今は runtime.gcRemoveStackBarriers に注目しているので、ずっと明白になっています。
perf を使ったプロファイリングの利点は、この場面で特にはっきり分かります。 perf ツールはカーネルのスタックを表示することができますが、Goのユーザレベルのプロファイラであれば、このGo関数を不可解に遅いものとして表示したでしょう。 perf を使う方がやや煩雑で、カーネルスタックを参照するためルート権限が必要となり、Go 1.5や1.6ではGoツールチェーンの非標準ビルドが必要となります( GOEXPERIMENT=framepointer ./make.bash を介して。Go 1.7で標準となる予定)。ですが、このような問題に対しては、間違いなくその労力に値するツールです。
移動を制御する
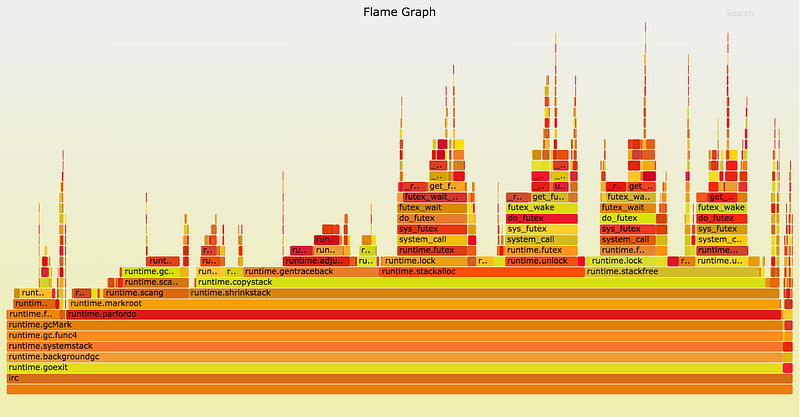
2つのCPUソケットと2つのメモリバンクを使うというのが複雑すぎる場合は、1つだけ使ってみましょう。このことに利用できる最も単純なツールが taskset で、これはプログラムが単一ソケットのコアでのみ動作するよう制限できるコマンドです。制限されたプログラムのスレッドは1つのソケットのメモリにだけアクセスするので、カーネルはそのメモリを移し、当該ソケットのメモリバンクに常駐するようにします。
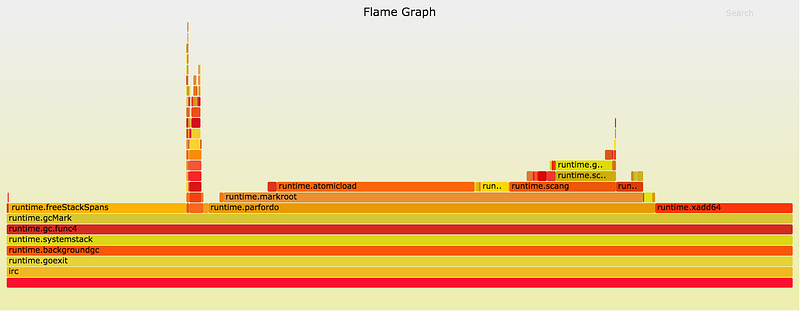
プログラムを単一のNUMAノードに制限した結果、アプリのマーク終了時間は10~15ミリ秒に減少しました。Go 1.5での200ミリ秒やGo 1.4での2秒の停止に比べて、大幅に改善しています( set_mempolicy(2) または mbind(2) を介してプロセスのメモリポリシーを MPOL_BIND に設定すると、サーバの半分を犠牲にせずに同じメリットが得られます)。上記のプロファイルは、2015年10月にGo 1.6以前のバージョンで取得したものです。見てみると、左側で runtime.freeStackSpans がかなりの時間を取っていることが分かります。これはその後、並行GCフェーズに移されているので、もはや停止時間の一因にはなっていません。マーク終了フェーズで取り除くべき要素は残り少なくなりました。
Go 1.7
Go 1.6以前では、コストの高いスタック縮小への対処として、当社のプログラムではその機能を無効にしていました。そのことがチャットサーバのメモリ使用量に及ぼした影響は最小限だったものの、はるかに高いコストとして、複雑な運用が必要になりました。スタックの縮小は、プログラムによっては非常に重要な機能であるため、この変更は全体に適用するのではなく、少数のアプリケーションにだけ実装しました。Go 1.7は今や、アプリケーションが動作している間に並行してスタックを縮小します。私たちは両手に花の状態、つまり特別なチューニングなしにメモリ使用量を抑えられるようになったのです。
並行GCがGo 1.5で導入されて以来、ランタイムは、goroutineのスタックが最後にスキャンされた以降にそのgoroutineが動作したかを追跡するようになっています。マーク終了フェーズは、各goroutineを調べて最近動作したかを確認し、該当するいくつかを再スキャンするものでした。Go 1.7では、ランタイムはそのようなgoroutineの短いリストを別個に保持します。その結果、ユーザコードの停止中にgoroutineのリスト全体を調べる必要がなくなり、カーネルのNUMA関連のメモリ移動コードをトリガし得るメモリアクセスの数が、大幅に減少しています。
最後に、amd64アーキテクチャ向けのコンパイラはデフォルトでフレームポインタを保持するので、 perf のような標準のデバッグ・パフォーマンスツールは目下の関数コールスタックを特定することができます。Goのバイナリディストリビューションを使ってプログラムをビルドしているユーザも、いちいちGoツールチェーンを再ビルドしてプログラムを再ビルド/再デプロイする手間をかけずに、必要に応じてより高度なツールを使えるようになります。これによって、皆さんや私のようなエンジニアは質の高いバグレポートに必要な情報を集められるようになるので、Goのコアパッケージとランタイムのパフォーマンスは今後向上していきそうに思われます。
2016年6月時点のGo 1.7のプレリリース版では、GCの停止時間は、手動チューニングなしの状態でかつてないほど改善されています。当社チャットサーバにおける典型的な停止時間は、初期状態で1ミリ秒に近い数値です。チューニングしたGo 1.6での構成に比べて10倍も良くなっているのです。
当社の経験を共有したことで、Goチームは私たちが遭遇した問題の根本的な解決策を見つけることができました。当社のアプリケーションは、Go 1.5と1.6での停止時間がプロファイリングとチューニングで10倍改善されましたが、ランタイムチームはGo 1.5とGo 1.7の間で、当社で使っているようなアプリの停止時間を100倍改善することができました。Goのランタイムパフォーマンスに対する精力的な取り組みに敬意を表します。
今後について
今回の様々な分析では、当社チャットサーバの悩みの種、ストップザワールド方式の停止時間に注目してきましたが、これはGCパフォーマンスの一側面にすぎません。GCによる厄介な停止はついに制御されるようになり、ランタイムチームはスループットの改善に取り組もうとしています。
チームが最近提案した Transaction Oriented Collector では、goroutineの間で共有されていない、コストの高くないメモリ割り当て・収集を透過的に提供するというアプローチが説明されています。これによって、フルGCを実行する差し迫った必要性はなくなり、ガベージコレクションにプログラムが費やすCPUサイクルの合計数を減らすことができるというものです。
そしてもちろん、Twitchでは人材を募集中です! このような仕事に興味のある方は、 どうぞご連絡ください 。
謝辞
Goの新バージョンをチャットシステムで安全にテストできるよう協力してくれたChris CarrollとJohn Rizzo、そしてこの記事を校正してくれたSpencer NelsonとMike Ossarehに感謝します。また、Goのガベージコレクタを絶えず改善し、有用なバグレポートの提出に協力してくれたGoのランタイムチームに感謝します。

株式会社リクルート プロダクト統括本部 プロダクト開発統括室 グループマネジャー 株式会社ニジボックス デベロップメント室 室長 Node.js 日本ユーザーグループ代表
- X: @yosuke_furukawa
- Github: yosuke-furukawa
関連記事