2015年6月4日
プロファイラは本当に必須か?―パフォーマンスについて考える

(2015-04-28)by Chad Austin
本記事は、原著者の許諾のもとに翻訳・掲載しております。
最近、2つの出来事があり、私が行っているパフォーマンスへのアプローチ方法は、あまり広く知られていないようだと感じさせられました。
1つ目の出来事は、 redditでBufferBuilderを発表 した際に、初期のコメントで次のような質問をもらったことです。「Haskellを実行する時に、プロファイラを利用してコードのどの部分で処理が遅くなっているのか確認しましたか?」というものでした。もっともな質問ですが、私の答えは”ノー”でした。プロファイラは利用していません。なぜなら、Haskellのプロファイラで確認できる段階では既に遅すぎるからです。私はバッファを構築する効率的な方法を既に知っていました。境界チェックをしてから、保存(シングルバイトの場合)または複製(バイト列の場合)をするやり方です。これ以上の命令は意味がありません。ですから、BufferBuilderの開発にあたって最初にやったことは、ベンチマークやプロファイラの実行ではなく、生成されたアセンブリを読み込み、どのようにHaskellを命令に変換するかというメンタルモデルを構築することでした(ベンチマークは後ほど登場します)。”典型的”なCPUバウンドのHaskellプログラムは、どんなものであっても結局は stg_upd_frame_infoとstg_ap_*_info に大半の時間を費やすこととなります。
2つ目は、ローカルなプログラミングのIRCチャンネルで、divをshiftに置き換えるという Twitterで見た 小技を披露した時のことでした。[0, 2]内の変数 i について、 (i+1)%3 == (1<<i)&3 が成り立つというものです。ある人がこの技を使うことに猛反対を唱えました。どんな議論だったかをまとめると、「コードの意味は不明確なので、このような小技はコンパイラに任せるべきだ。しかし、全ての変数iの値に有効なわけではなく、実際にコンパイラが右式を左式に置き換えることは決してない。余計なことはするな」といった具合です。この議論の”真意”が「この問題の大きさを理解できないうちは、この技を使ってはいけない」ということだと分かってから、私たちは何度か連絡を取り合いました。そして、「この問題を知るためにプロファイラを実行しなければいけない」という答えにたどりついたのです。特別なツールを使わなくても、目と頭脳を使えばインナーループ内のクリティカルパスにdivがあることは分かる、と私は主張しました。オペレーションコストとアウトオブオーダー実行でのCPUの働きをざっくりと理解しているだけでいいのです。
私は何年もかけて、パフォーマンスについて考えるためのメンタルフレームワークを構築してきました。それは「まずは動くプログラムを作り、ホットスポットをプロファイルし最適化する」という一般的に推奨される方法にはとらわれないものです。私のメンタルフレームは以下の3つの考え方が基本となっています。
- Rico Mariani はパフォーマンスを向上させるデザイン方法について多くの記事を書いています。プロジェクトの終わりの方でハマってしまい、パフォーマンスの目標を達成できないということがないよう導いてくれます。マシンや問題の制約を理解して解決のための筋書きを紙に記し、それが適切な方法かどうかを確認します。必要でしたらプロトタイプを利用しましょう。
- 私は常に、物理的なシリコンの上で、どのようにプログラムが実行されているのかということに興味を抱いてきました。『 The Pentium Chronicles: The People, Passion, and Politics Behind Intel’s Landmark Chips 』はアウトオブオーダー実行機能が備わったIntel P6系列のデザインが進化する過程を書いた名著です。
- 私は「まずは動くプログラムを作って、あとからプロファイルと最適化を行う」という指針のプロジェクトに関わり過ぎました。この戦略は失敗が非常に多く、結果として一様に遅く、修正するにも非経済的なプログラムになってしまいます。
パフォーマンスはエンジニアリング
目標のパフォーマンスを達成するための第一歩は、目標を決めることです。何を達成したいのかよく考えて下さい。目標とするパフォーマンスの例をいくつか挙げてみます。
- 携帯電話での対話型VRを実現する。
- マウスをメニュー上でクリックしてからアクションが起こるまでの時間を100ミリ秒未満とする。
- 完全な3Dチャットルームを5秒以内にロードする。
- 「ハワイの山」を検索した際、検索結果の最初のページが0.5秒以下で開かれる。
- 最新の実験的解析を半日で完了させる。
また、なぜこれらの目標を達成したいのかということも明らかにしておきましょう。Todd Hoffが書いた『 Latency is Everywhere and it Costs You Sales 』ではいくつかリンクが貼られていて、そのリンク先からパフォーマンスがいかにビジネスメトリクスや顧客の満足度に影響を与えるかを知ることができます。
BufferBuilderの目標は、HaskellでのパフォーマンスをネイティブC++のバッファ構築ライブラリに匹敵させることです。
目標が定まって解決すべき問題を理解したところで、最後にもうひとつ知っておくべき事があります。それは、「人間とコンピュータの相互作用による基本定数」と呼ばれ、人間の動きとコンピュータの動作でそれぞれ半分に分けられます。
概略は下記の通りです。
- 〜16ミリ秒:対話型アニメーションのフレーム動作
- 100ミリ秒:ユーザが瞬間的だと感じる速さ
- 200ミリ秒:典型的な人間の反応速度
- 500ミリ秒〜:認知できるくらいの遅さ
- 3秒〜:反応が鈍いと感じる遅さ
- 10秒〜:待っていられない遅さ
コンピュータ上の数値
- 1サイクル:単純なビット単位のオペレーションレイテンシ
- 2〜3サイクル:サイクルごとに呼び出される独立系命令の最大数
- 3〜4サイクル:L1キャッシュのレイテンシ
- 〜12サイクル:L2キャッシュのレイテンシ
- 〜36サイクル:x86アーキテクチャの整数除算
- 200〜300サイクル:メインメモリへのラウンドトリップ
- 50〜250マイクロ秒:SSDへのラウンドトリップ
- 250〜1000マイクロ秒:イーサネットやTCPなどの通信のラウンドトリップ
- 10ミリ秒:回転ディスクのシーク時間
- 150ミリ秒:オーストラリアとアメリカ間でのIP層のレイテンシ
スループットの数値
- 8.5GB/秒:iPhone5のメモリ帯域幅
- 〜100MB/秒:最大限に使われているギガビットイーサネット接続
- 50〜100MB/秒:回転ディスクの転送速度
- 4.5MB/秒:世界で平均的な接続速度
- 3.2MB/秒:アメリカの平均的なモバイルの帯域幅
上記の数値はよりハイレベルな数値に置き換えられます。例えば次のようになります。
今後JSONの構文解析が明らかに早くなる見込みはありません。構文解析はコンピュータの もどかしいレイテンシの問題 を招くためです。「1バイト読み込んでは分岐命令。次の1バイトを読み込んでは、また分岐命令」という動きです。
今後スループットの数値は増えていきますが、一方のレイテンシは少ししか減少していかないので、典型的なプログラムの大半はスループットの限界より先にレイテンシの限界に達してしまうでしょう。
上記で記載した数値の参考サイトです。
- Akamai State of the Internet Report
- iPhone 5 Memory Speed @ Anandtech
- Verizon IP Latency Statistics
- Latency numbers every programmer should know
- Latency: The Heartbeat of a Solid State Disk
- Gigabit Ethernet Latency with Intel’s 1000/Pro Adapters
- Agner Fog Instruction Tables
- Powers of 10: Time Scales in User Experience – Jakob Nielsen
- Latency: The New Web Performance Bottleneck
パフォーマンスのための設計
パフォーマンスの目標を決めたら、その数値に適合させる必要があります。目標が対話型アニメーションであれば、1フレームの描写ごとに、固まった画面のまま応答が返ってくるまで待つ余裕は、まずないでしょう。(やっていけません) また、目標が世界中のどこから操作しても反応が即時に感じられるAJAXアプリケーションであれば、必要なIPのラウンドトリップの回数を注視しなくてはなりません。Modulo TCPのウィンドウ処理の帯域幅は、通常であれば利用可能です。しかし、蓄積された一連のラウンドトリップによって、経験上の期待値はすぐに吹き飛ばされるでしょう。 世界の代表的なインターネット接続を使い、WebGLに5秒で読み込みをさせたいなら、最初のラウンドトリップの時間を引いた数値である2.8MB(5秒×4.5MB/秒)にデータを適合させなければいけません。
BufferBuilderを行う際の目標はC++のパファーマンスとHaskellを匹敵させること(少なくともそれに近づけるくらいに)なので、プロファイラは必要ありませんでした。バッファにシングルバイトを追加することによって、少なくとも次のような必要性を生むことを知っていたからです。現在の出力ポインタの読み込み、(予想される)配列境界のチェック、そして新しい出力ポインタの書き込みです。つまりバッファへの追加は、(予想される)境界のチェック、メモリブロックのコピー、そして出力ポインタのアップデートを意味します。
期待するパフォーマンスの指標を達成するために、プロファイラは必要ありません。本当に必要なのは、問題と制約を理解し生成されるコードに注意を払うことです。
この手法は、ほとんど全ての規模のシステムに対して適用可能です。高解像度のイメージ、グラデーション、トランジションやエフェクトを備えていながらRAMのサイズが100MBとなるリッチなwebサイトを構築してみたいですか? プロトタイプをつくり、各コンポーネントのコストを試算してみましょう。数量に関する理解を深め、数値を適合させましょう(もちろん、忘れていて後で驚かないように、出来上がったページで実際のメモリ消費を計測するのを忘れないでくださいね)。
タップしてからネットワークデータが表示されるまで200ミリ秒のモバイルアプリケーションを設計するのはどうでしょうか。これはなかなか大変そうですね。Androidデバイスの タッチスクリーンのレイテンシは100ミリ秒以上 ですから。 (注記: mdwrigh2氏ががHacker Newsで指摘してくれた ように、いまのAndroidデバイスではこの数値は正しくないようです。)電波が受信できる状態になるまでに 1秒以上 かかることもあるようです。
要するに、システムの様々な階層におけるレイテンシについての大まかな理解と、コード上でのクリティカルパスに関する知識があれば、単に数値を合算していくことにより総レイテンシの近似値を得られるはずです。もちろん、実計測についてきちんと理解できているか定期的に確かめてください。
FAQ
プロファイラは役に立ちませんか?
そんなことはありません。プロファイラは優秀です。私は 長期間にわたって Pythonのプロファイラを使ってきました。特に以前のAMD CodeAnalystというツールはいいですね(新しいCodeXLではなく)。一般的にプロファイラのサンプリングはとても有用です。私は様々な目的で教育用にもプロファイラを多く作成しました。
しかし、プロファイラは常に新しいことを模索し学習し続けるためのもの、ということを忘れないようにしてください。アプリケーションをビルドした頃には”あなたにとってベストケースのプロファイル”ができなくなってしまっているかもしれません。
どのような状況でもこのアドバイスを一律に適用するべきですか?
もちろんそんなことはありません。モダンCPU上であれば、多くのプログラムはパフォーマンスの期待値内に問題なく収まります。そのような状況下なら、O(n)ループや連結リストを書いたり、各関数内でmalloc()をコールしたり、Pythonを使っても大丈夫です。その場合は人間の開発スピードがボトルネックですから、ご心配なく。
そして様々な事柄のコストに関して、常に学び続けましょう。ビジュアルエフェクトを変更するため、ある時誰かがページ上の大量の <img> タグを <canvas> で置き換えたことがありました。結果、そのページはドカンと恐ろしいほどに遅くなり、膨大な量のメモリを消費したのです。多くのイメージを処理するため、ブラウザというのは一連の作業を最小化することに関しては長けています(実際にアイテムが表示されるまではデコードしたJPEGをメモリからフラッシュするなどのテクニックがあります)。しかし <canvas> はフリーフォームなので、ページファイルにバックアップされたメモリが最低でも width*height*4 の分、消費されてしまうのです。
アルゴリズムの複雑性についてはどうですか?
アルゴリズムの複雑性には改善の大きな可能性があります。特に Accidentally Quadratic に書かれているケースに当てはまる場合、まずこれらの成功例を目指してください。でも、もしO(n)対O(lg n)の問題にぶつかった場合、ほぼ間違いなく定数係数によって制限されるでしょう。
どのような状況においても、まずは最大の成功を目指すべきです。例えば、データベースと通信して100人の顧客のデータを得るようなwebサービスを作るとしましょう。これを最大限に最適化するには、100人の顧客のフェッチを1回のクエリで処理します(1度のラウンドトリップで1~10ミリ秒)。1人ずつ100回クエリを走らせてはいけません。誰かが「私の新しいwebサービスは1.5秒もかかる」と言う場合、まず間違いなくこのケースに陥っていると言えると思います。どちらの手法も技術的にはO(n)ですが、クエリの問題によるオーバーヘッドは非常に大きな定数係数となります。
私が面接で時々応募者にする質問に、2つのアルゴリズムが同じ複雑性を持つ場合、パフォーマンスはどう違うのか、というのがあります。正解は1つではありませんが、「実行時間は同じ」と答えたとしたらそれは間違いです。定数係数は非常に大きくなり得るので、最適化により桁違いに改善することもあるのです。
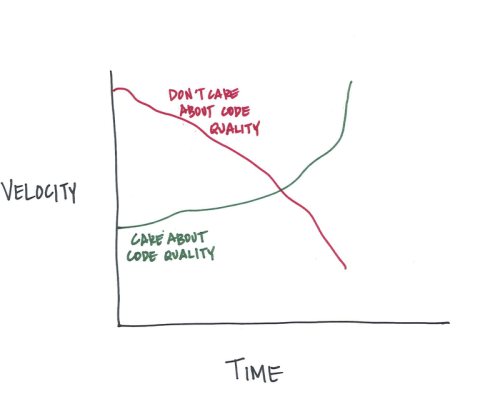
でもKnuthはこう言ったはず…
実際の彼の発言 をまず読んでみてください。あれ以来、私たちは 成熟した最適化 を適用すべき時期について考察を深めてきました。 std::string の代わりに const std::string& を渡すのが未熟な最適化ということではありません。これは普段からちゃんとしておくべき身だしなみのようなものです。

株式会社リクルート プロダクト統括本部 プロダクト開発統括室 グループマネジャー 株式会社ニジボックス デベロップメント室 室長 Node.js 日本ユーザーグループ代表
- X: @yosuke_furukawa
- Github: yosuke-furukawa
関連記事