2026年2月27日
Web上の巨大HTMLドキュメントを探る

(2025-12-02)by Matt Zeunert
本記事は、原著者の許諾のもとに翻訳・掲載しております。
ほとんどのHTMLドキュメントは比較的小さく、ページ上の他のリソースを読み込むための起点として機能しています。
しかし、なぜ一部のWebサイトでは数メガバイトものHTMLコードが読み込まれるのでしょうか?通常、ページ上に大量のコンテンツがあるわけではなく、他の種類のリソースがドキュメント内に埋め込まれていることが原因です。
この記事では、Web上に存在する巨大なHTMLドキュメントの実例を取り上げ、コードの中身を覗いて何がそれほど大きくしているのかを探っていきます。
Web上のHTMLは驚きの連続です。この記事を執筆する過程で、DebugBearのHTMLサイズアナライザーのほとんどを作り直しました。スクリプトの中にJSON、その中にHTML、さらにCSSや画像——HTMLにそんな深い入れ子構造があっても、今なら対応しています!
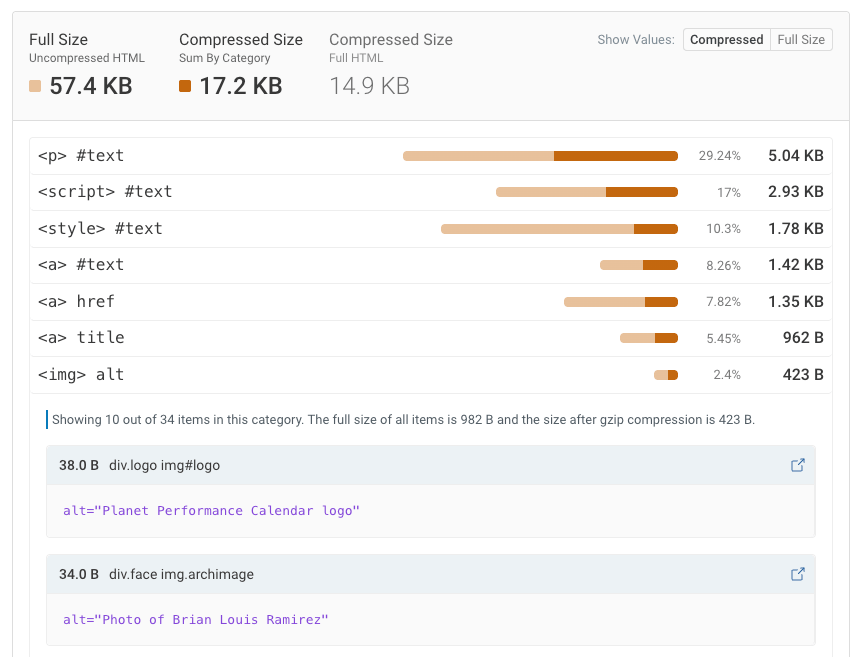
埋め込み画像
Base64エンコーディングは、画像をテキストに変換する方法で、HTMLやCSSなどのテキストファイルに埋め込むことができます。画像を直接HTMLに埋め込むことには大きなメリットがあります。画像を表示するためにブラウザが別途リクエストを行う必要がなくなるのです。
しかし、大きなファイルの場合は問題を引き起こす可能性があります。たとえば、画像を個別にキャッシュできなくなり、また画像がドキュメントコンテンツと同じ優先度で取得されてしまいます——通常、画像は後から読み込まれても問題ないのですが。
以下は、データURLを使用してHTMLに埋め込まれたPNGファイルの例です。
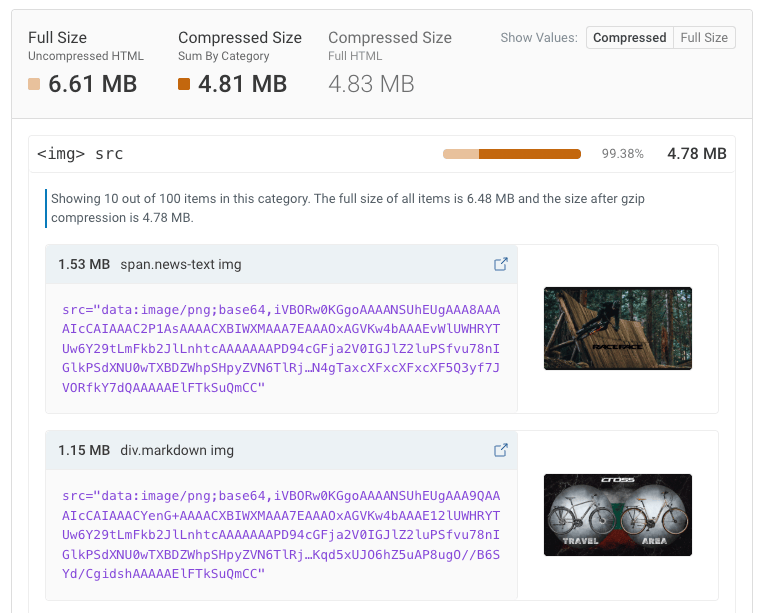
このパターンにはさまざまなバリエーションがあります:
- 誤って含まれた数メガバイトの単一画像である場合もあれば、時間の経過とともに蓄積された数百個の小さなアイコンの場合もある
- レスポンシブイメージとデータURLを組み合わせて使用しているサイトもあった。レスポンシブイメージの目的の1つは必要最小限の解像度の画像だけを読み込むことだが、すべてのバージョンをHTMLに埋め込むと逆効果になる
- 間接的に埋め込まれた画像:
- PNGやJPEGの単なるラッパーにすぎないインラインSVG
- インライン化されたCSSスタイルシートに含まれる背景画像
- JSONデータ内の画像(これについては後述 😬)
以下は、背景画像が埋め込まれた201のルールを含むstyleタグの例です。
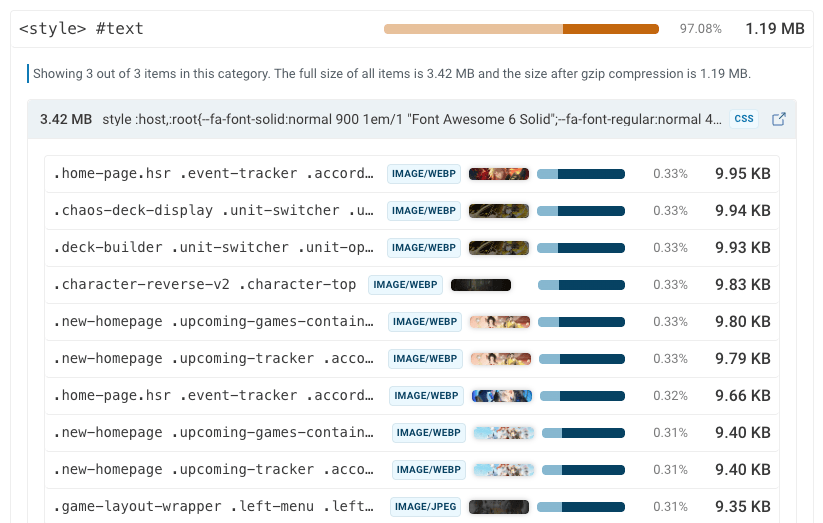
インラインCSS
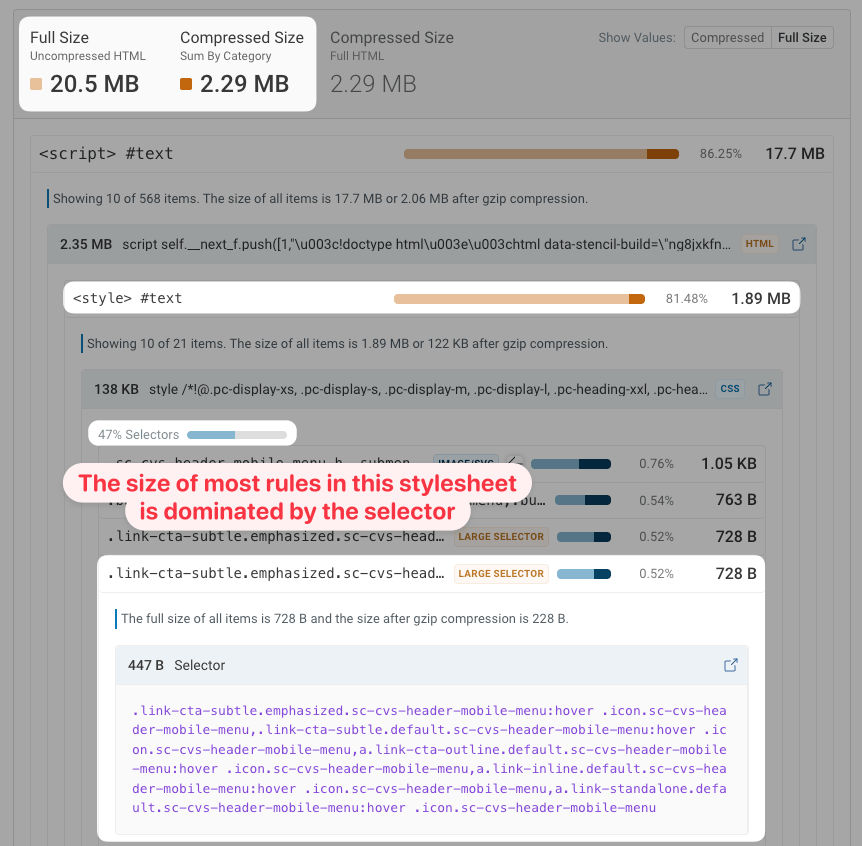
大きなインラインCSSの原因は通常、画像です。ただし、深くネストされたCSSによる長いセレクタも、CSSおよびHTMLのサイズ増大に寄与します。
以下の例では、HTMLに類似した内容の20個のインラインstyleタグが含まれています("header"、"header-mobile"、"header-desktop" などのバリエーション)。ほとんどのセレクタは200文字以上あり、その結果、スタイルシート全体の内容の47%がスタイル宣言ではなくセレクタで占められています。
ただし、セレクタ内の繰り返しによりHTMLの圧縮効率は良好で、GZIP圧縮後は20.5メガバイトからわずか2.3メガバイトにまで縮小されます。
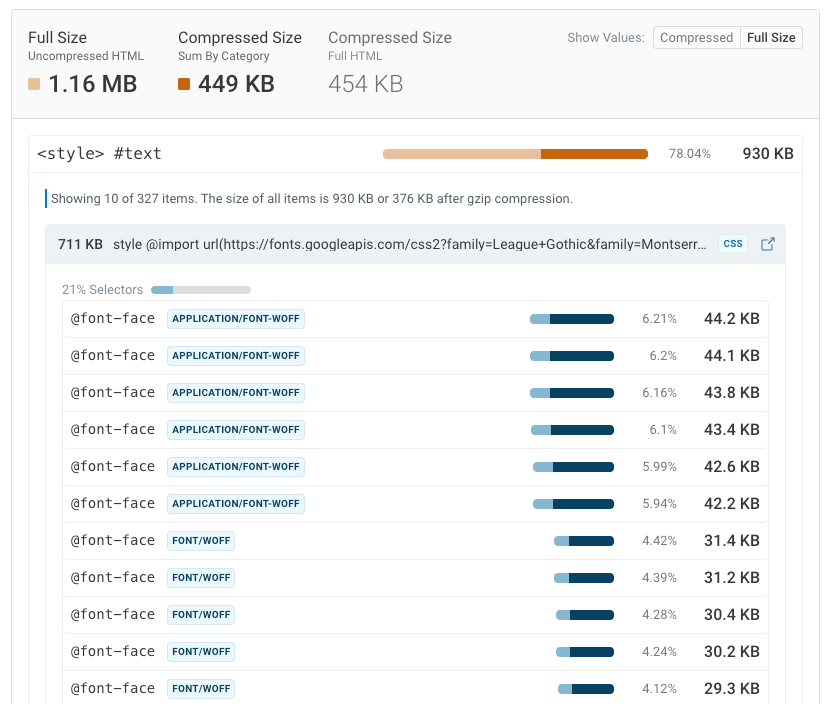
埋め込みフォント
画像と同様に、フォントもBase64でエンコードされることがあります。1つか2つの小さなフォントであれば、テキストを適切なフォントですぐにレンダリングできるため、実際にうまく機能します。
しかし、多くのフォントが埋め込まれている場合、これらのフォントのダウンロードが完了するまでページコンテンツのレンダリングを待たなければならないことを意味します。
クライアントサイドのアプリケーション状態
現代の多くのWebサイトは、JavaScriptアプリケーションとして構築されています。すべてのJavaScriptと必要なデータの読み込みが完了してからコンテンツを表示するのでは遅いため、初回のページ読み込み時にはHTMLもサーバーサイドでレンダリングされます。
クライアントサイドのアプリケーションコードが読み込まれると、静的なHTMLは「ハイドレーション」されます。ページコンテンツがJavaScriptでインタラクティブになり、クライアントサイドのコードがそれ以降のコンテンツ更新を制御するようになります。
通常、クライアントサイドのコードはバックエンドのAPIエンドポイントにfetchリクエストを送信して必要なデータを取得します。しかし、初回のクライアントサイドレンダリングにはサーバーサイドレンダリングと同じデータが必要なため、サーバーはハイドレーション用の状態を最終的なHTMLに埋め込みます。これにより、クライアントサイドのハイドレーションは追加のAPIリクエストを行うことなく、すべてのJavaScriptの読み込み完了直後に実行できます。
ご想像のとおり、このハイドレーション用の状態は巨大になり得ます! 以下のようなフレームワーク固有のキーワードを参照するscriptタグから識別できます:
- Next.js:
self.__next_f.pushまたは__NEXT_DATA__ - Nuxt:
__NUXT_DATA__ - Redux:
__PRELOADED_STATE__ - Apollo:
__APOLLO_STATE__ - Angular:
ng-stateなど - 多くの独自構成:
__INITIAL_STATE__または__INITIAL_DATA__
ローカルの開発環境ではデータが少ないため、ハイドレーション用の状態のサイズは気にならないかもしれません。しかし、本番のデータベースにデータが追加されるにつれて、ハイドレーション用の状態も増大します。たとえば、あるホテル一覧では3,561枚もの異なる画像が参照されています(さいわい、Base64で埋め込まれてはいませんが 😅)。
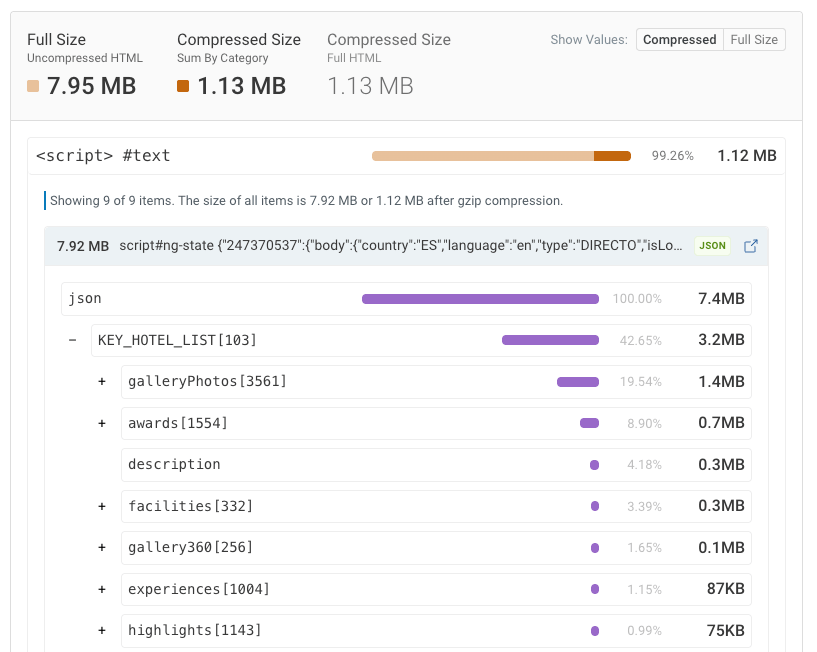
Base64画像をフロントエンドコンポーネントに渡すと、それらはハイドレーション用の状態にも含まれることになります。
あるWebサイトでは、HTMLドキュメント内のJSONデータの中に42枚の画像が埋め込まれていました。最大の画像サイズは2.5メガバイトでした。
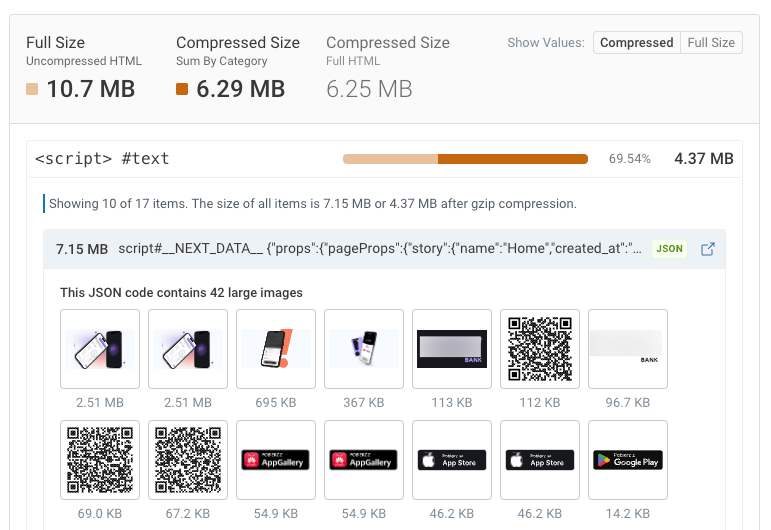
驚くほど深いネストが発生しています。先ほどの例では、HTML内のscript内のJSON内に画像がありました。
しかし、さらに深く潜ることができます! 次の例を見てみましょう:

ハイドレーション用の状態を掘り下げると、judgmeWidget プロパティを持つ52個の商品が見つかります。このプロパティの値自体がHTMLフラグメントなのです!
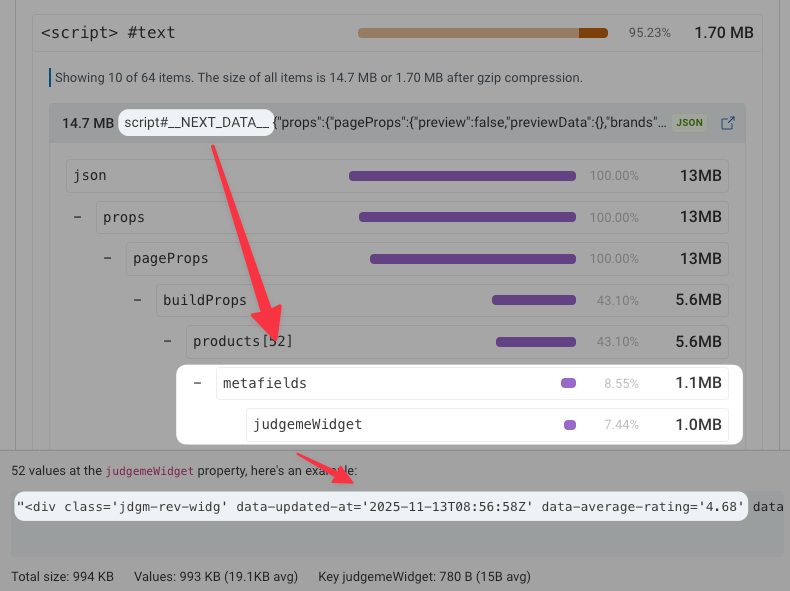
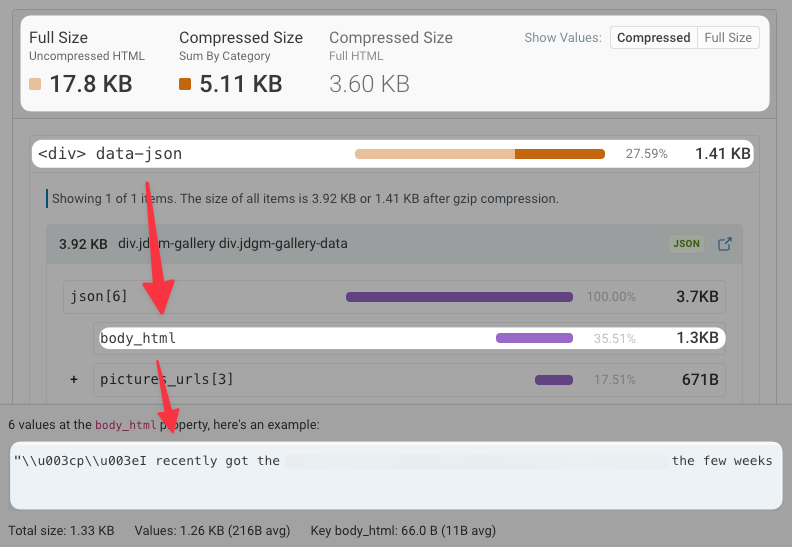
その値の1つをHTMLサイズアナライザーに入れてみましょう。ここでも、HTMLの大部分は実際には埋め込まれたJSONコードであり、今回はdivのdata-json属性の形式になっています!
そして、そのJSON内で最も大きなプロパティの名前は? body_html です 😂😂😂
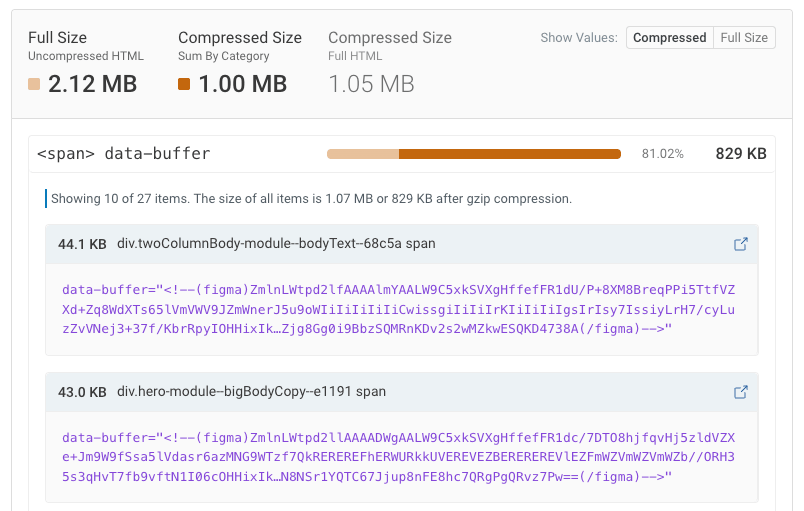
その他の巨大HTMLの原因
調査中に見つけたその他の例をいくつか紹介します:
- 4メガバイトのインラインスクリプト
- Figmaからの予期しないメタデータ
- 7,000以上の項目と1,300のインラインSVGを含むメガメニュー
- 180種類のサイズに対応したレスポンシブイメージ
GZIPやBrotli圧縮をHTMLに適用していない大規模なWebサイトもまだ存在します。そのため、コード量自体はそれほど多くなくても、転送サイズが大きくなってしまいます。
53キロバイトの NREUM スクリプトを見かけると、いつも残念に思います。多くのWebサイトが New Relic のエンドユーザー監視スクリプトをドキュメントの <head> に直接埋め込んでいます。ユーザー体験を計測するのであれば、そのパフォーマンスへの影響は避けたいところです!
HTMLサイズはページ速度にどう影響するか?
HTMLコードは、ページ読み込み処理の一部としてダウンロードおよびパースされる必要があります。これに時間がかかるほど、訪問者がコンテンツの表示を待つ時間が長くなります。
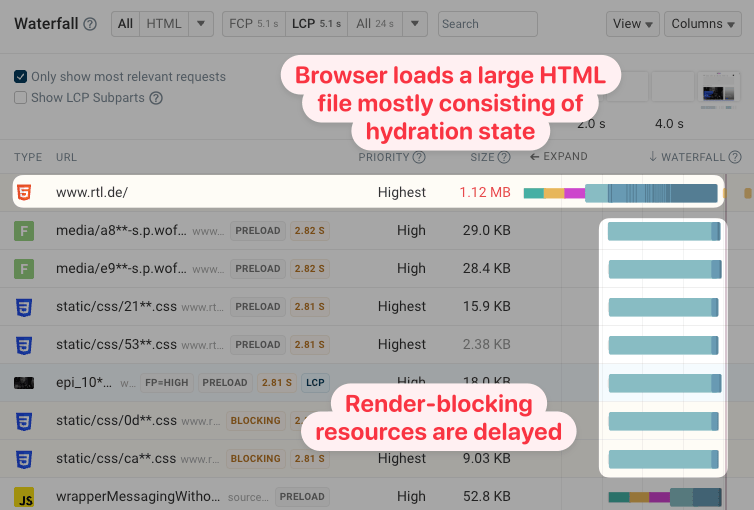
ブラウザはHTMLコンテンツに高い優先度を割り当て、そのすべてが重要なページコンテンツであると想定します。これにより、重要でないハイドレーション用の状態が、レンダリングをブロックするスタイルシートやJavaScriptファイルよりも先にダウンロードされてしまうことがあります。
DebugBearのWebサイト速度テストによるリクエストウォーターフォールの例を見るとわかります。ブラウザは他のファイルの存在を早い段階で把握しているにもかかわらず、すべての帯域幅がドキュメントに消費されています。
画像やフォントをHTMLに埋め込むことは、それらのファイルをキャッシュしてページ間で再利用できなくなることも意味します。代わりに、Webサイト上のすべてのページ読み込みで再ダウンロードする必要があります。
HTMLのパースにかかる時間も懸念されるのでしょうか? 私のMacBookでは、1メガバイトのHTMLコードをパースするのに約6ミリ秒かかります。一方、テストに使用しているローエンドのスマートフォンでは、1メガバイトあたり約80ミリ秒かかります。したがって、非常に大きなドキュメントの場合、CPU処理も考慮すべき要因になり始めます。
巨大なHTMLでもWebサイトは高速であり得る
おわかりのとおり、私はHTMLサイズに少しこだわりすぎているかもしれません。実際のところ、多くの実際の訪問者にとって、本当に問題なのでしょうか?
巨大なHTMLファイルを実際以上に大きな問題であるかのように見せたくはありません。今日あなたのWebサイトを訪れるほとんどの訪問者は、おそらく十分に高速な回線とデバイスを持っています。他のWebパフォーマンスの問題のほうが、通常はより差し迫った課題です。(たとえば、ハイドレーション用の状態を使用するJavaScriptアプリケーションコードの実行など)
また、ページはHTMLドキュメント全体のダウンロードが完了する前にレンダリングを開始できます。ここでは、ドキュメントと重要なスタイルシートが並行して読み込まれていることがわかります。その結果、メインコンテンツはドキュメントの読み込みが完了する前にレンダリングされます。
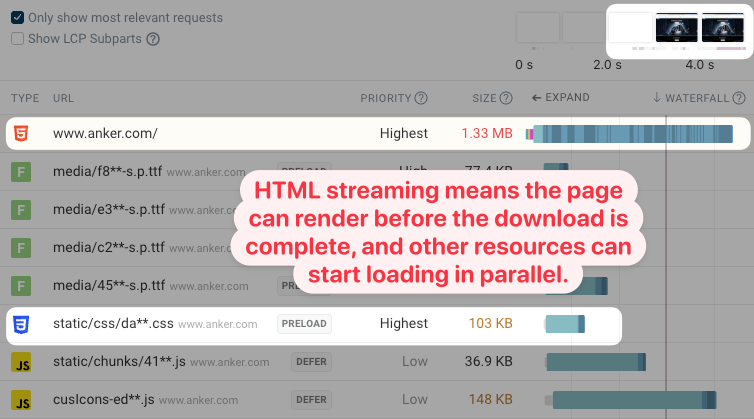
GoogleのChrome User Experience Report(CrUX)の実ユーザーデータによると、このWebサイトでは通常2秒以内にレンダリングされています。しかもモバイルデバイスでの結果です!

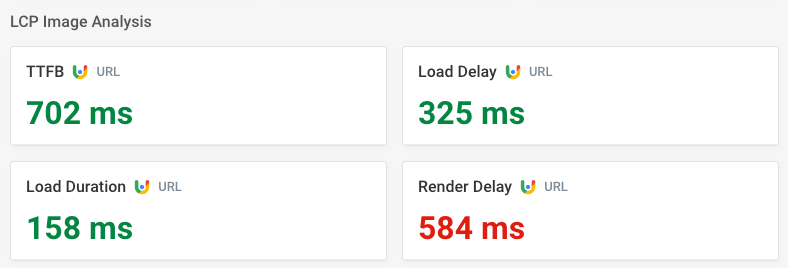
とはいえ、巨大なドキュメントは確実にページを遅くしています。その指標の1つは、Largest Contentful Paint(LCP)の画像が読み込み直後に表示されないことです。CrUXでは584ミリ秒のレンダリング遅延が報告されています。
これは、メインのWebサイトサーバー上のレンダリングブロッキングスタイルシートが大きなHTMLドキュメントと帯域幅を奪い合っていることを示しています。その結果、別のサーバーから配信される画像よりも読み込みが遅くなっているのです。
自分のWebサイトのHTMLをざっと確認し、実際に何が含まれているかをチェックすることは価値があります。多くの場合、すぐにできるインパクトの大きな修正が見つかります。
画像がHTMLやCSSコードにインライン化されている場合、それはパフォーマンス最適化を意図していることが多いです。しかし、良い仕組みがあると、後から画像を追加するのが容易になりすぎて、埋め込まれるファイルの中身を確認しないまま増え続けてしまうことがあります。CIビルドにガードレールを設けて、意図しないファイルサイズの急増を検知することを検討してください。

株式会社リクルート プロダクト統括本部 プロダクト開発統括室 グループマネジャー 株式会社ニジボックス デベロップメント室 室長 Node.js 日本ユーザーグループ代表
- X: @yosuke_furukawa
- Github: yosuke-furukawa
関連記事