2016年7月19日
Stack Overflowのデータサイエンティストとしての1年間

(2016-06-20)by David Robinson
本記事は、原著者の許諾のもとに翻訳・掲載しております。
2013年1月のある日、気が付くと私はインターネットで時間を無駄遣いしていました。
これは、残念な発見でした。博士課程の2年半は、みんな忙しくなります。私もそうでした。酵母遺伝学の研究発表が控えていましたし、ニューヨーク大学との共同研究の論文は数カ月遅れていました。しかも学部での研究が残っていて、それはさらに滞っていました。また、プライベートも忙しく、イスラエル旅行から帰国してブラジルの柔術とジョギングを再開したばかりでした。
しかし、そんな日々の中で、 知らない人からのベータ分布に関する質問 に答えて時間を無駄にしていたのです。質問はCross Validatedというサイトに寄せられたものでした。これは開発者向けのQ&Aサイト「Stack Overflow」の統計学版姉妹サイトです。その時までの約1年間、私はStack Overflowでは積極的に回答していましたが、Cross Validatedでの回答はそこまで頻繁ではありませんでした。しかし確かに、私はそうやって過ごして、時間を無駄にするのが 好きだった ようです。
当時の私は、野球の各種記録からベータ分布を説明する、素晴らしいアイディアを持っていました。この回答については、 こちらの投稿 と、 こちらのシリーズ で紹介しています。

私は博士課程において、誇れる研究を数多く行いました。記憶に残らないようなことや、重要ではないことは、さらにたくさん行っています。キャリアへの影響という観点で考えると、サイトで回答することが私にとって一番楽しい作業でした。
Stack Overflowでの1年間
この前の木曜日(6月16日)は、私がデータサイエンティストとしてStack Overflowで働くようになって、ちょうど1周年となる日でした。
私は働き始める1カ月前に博士課程を終えました。そこから技術系の会社に勤めるという変化は私にとって大きな挑戦でした。ほんの数カ月前まで、計算生物学という分野の学術的な研究を続けようと考えていたのです。博士号取得後のフェローシップの申請を始めていて、”企業”の求人に応募することなんて考えてもいませんでした。
何が私の気持ちを変えたのでしょうか。始まりは2015年の1月です。Jason Punyonがベータ分布に関する(2年前の)私の投稿を見つけました。
Why I love working at @StackExchange reason #14785: We get awesome answers to questions like this one: http://t.co/NkgvYHMEAy Thanks @drob
— JSONP (@JasonPunyon) 2015年1月7日
私が @StackExchange で働くのが好きな理由#14785:質問に対するすごい答えを得られるから。例えばこれ。 stats.stackexchange.com/a/47782/60 。 @drob に感謝。
@drob P.S. I know we aren't as exciting as finishing your PhD but if you want an interview here at Stack you can have one :)
— JSONP (@JasonPunyon) 2015年1月7日
追伸:博士課程をやり遂げるほどの魅力はないかもしれないけど、もし君がStackの仕事に興味があれば面接に来てください。
この時点で、私は研究者としての道を歩み始めていることをかなり確信していました。しかし、Stack Exchangeのオフィスをこの目で確かめ、その製品を作り出す人々と出会う機会を逃したくはありませんでした。私が自分の考えを変えるためには基本的にオフィスを一度、訪問するだけで十分でした。そして面接の2、3週間後に採用の話をもらい、それを受けました。
私が取り組んでいる幾つかのこと
人々はWeb開発者が何をするのかを知っています。しかし、データサイエンティストは何をするのでしょうか? ( 私だけがこう質問されているわけではありません )。
私が取り組んでいるプロジェクトは、以下に示すものだけではありませんが、これらのプロジェクトで私が担当していることがどんなものかを感じていただけるでしょう。
機械学習の機能を設計し、開発し、テストする
私たちの製品のどこで機械学習が使われているかという最たる例は、 Providenceです。これは、ユーザとユーザが興味を持ちそうな仕事をマッチングさせるシステムです 。(例えばStack Overflowのサイトに、主にPythonやJavaScriptについての質問を参照しに訪れていれば、最終的には広告欄にPython のWeb開発の仕事が表示されることになります)。これらの機械学習アルゴリズムを設計し、改善し、実装するために、私はデータチームでエンジニアたち( Kevin Montrose と Jason Punyon と Nick Larsen )と一緒に働いています。( 私が参加する前に構築されたシステムのアーキテクチャがもういくつかあります )。例えば、地理的にユーザと近い場所での仕事と、技術的な観点からふさわしいと思われる仕事との間で最適なバランスをとるように作業を進めていきました。また、同じ広告を繰り返し見せるよりも、いろいろなものが表示されることを保証するようにしました。
このプロセスの多くは、A/Bテストの設計と分析、特にクリック率(CTR)を改善するためにターゲティングアルゴリズムや広告のデザイン、その他の要因を変えることに対する分析を伴うものです。私が思っていたよりも、このプロセスは統計的により興味深いものです。ある時には、私が生体実験を解析するために用いていた手法の新しい使い方を示してくれました。また別のある時には、新しい統計的手法を学ぶきっかけを与えてくれました。事実、 ベイズ法を野球の打撃統計に適用するという私のシリーズ の多くは、実は、私が広告キャンペーン全体でCTRを分析するために使った手法の、すぐそれと分かるバージョンなのです。
良いものを学ぶ
私はもう研究機関の科学者ではありません。しかし、それは私がデータから結論を導き出すことに興味を持っていないということではありません。何百万もの質問とユーザ、日々の訪問者が共存するソフトウェア開発のエコシステムを概観する視点をStack Overflowは持っています。その全てのデータから何を学べるのでしょう?
第一に、タグが一緒に使用される方法を見ることにより、自然な技術的クラスタを見つけることができます ^(1) 。

この手法では、全て手動で注記をつけることなく、自動的にフレームワークとパッケージを高水準言語とこれらが属しているクラスタに分類できます。
しかし実際に表しているのは、特定のプログラミングの質問に関してタグがどういった組み合わせで付けられているか、だけであって、同じプロジェクトに対して、どのようにタグが使われているかではありません(例えばC#とSQLサーバというタグは同じ質問に常に付けられているわけではありませんが、同じテクノロジスタックのパートとして、よく一緒に付けられています)。そのために、もう1つのデータソースとStack Overflowのキャリアプロフィールを見ることになり、同じ開発者によってどのテクノロジが用いられる傾向があるかを確認することになります。

私は”テクノロジ・エコシステム”ではなく、厳密なカテゴリよる、このタグ分けの仕方を気に入っています。この種の理解はプログラミング技術に限られたことではありません。Stack Exchangeネットワークは広大な範囲のQ&Aを含んでいます。このコミュニティが同じアクティブメンバーを持つ傾向があるかを見ることによって、それぞれのサイトがどのように相互に関係付けられるかのネットワークを同じように作り上げることができます。
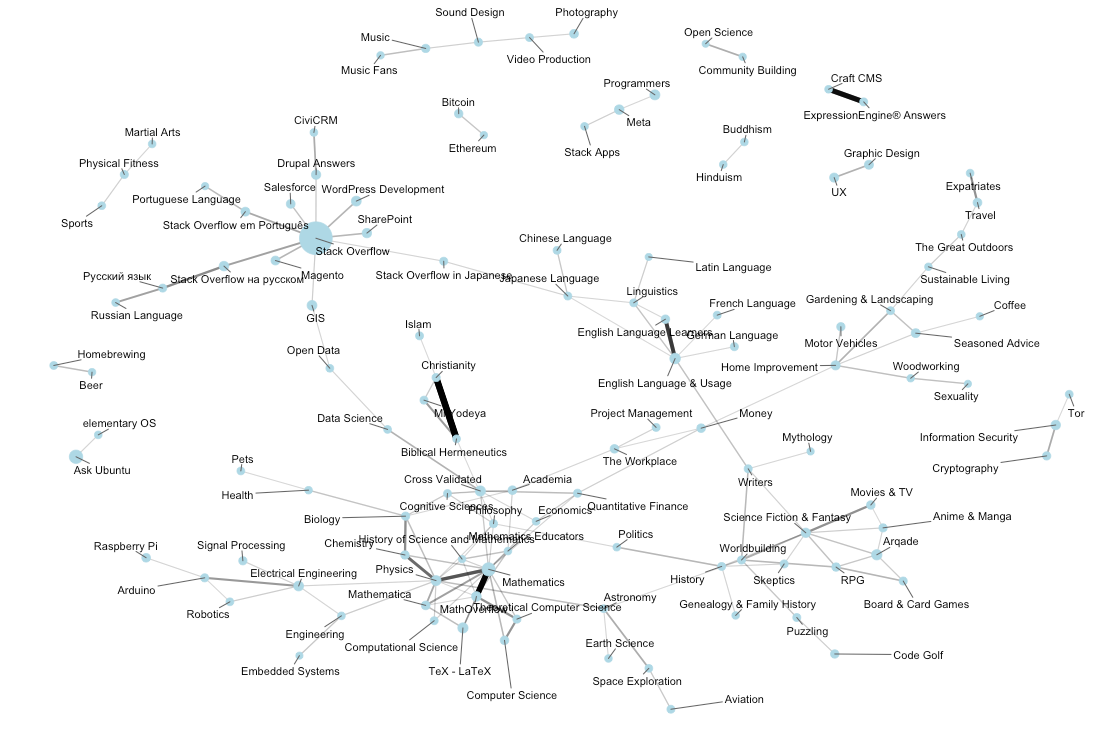
(私が行ったのはネットワークだけではありません。一見して面白いようなものの一例として挙げています)。
なぜ、このような分析に時間を割くのでしょう? それは時に機能の拡張に直接役立つからです。例えば定量的にテクノロジのクラスタを理解することで、Providenceのターゲティングを運用する 開発者の型モデル を改良することができるのです。他の視点では、ビジネス面で価値があります。私は以前、営業、マーケティング、コミュニティチームと一緒に働き、彼らのデータを読み解き、決定を下す支援をしたことがあります。
そしてまた本質的に私はこの手の情報を学び、視覚化することにとても興味をそそられます。仕事を楽しくしてくれるものの1つです。ここでの2年目のプランの1つとして、公にされているより多くの分析結果を共有したいと考えています。以前の記事で、 どのテクノロジについて意見が割れやすいかということについて触れました が、またすぐに同一の項目について多くの記事をシェアしたいと思っています。
データサイエンスアーキテクチャを開発する(R内部パッケージ)
Rを使ってデータに関する面白い事柄を学ぶのが好きです。しかし私の長期的な目標としては、エンジニアにとってRを用いたデータ分析を簡単にすることです。入社した当初は、社内でRを使ったのは私が初めてでしたが、年が経つにつれ、使うエンジニアが増えてきました。Rはデータを直接やりとりし、興味を引かれる疑問に答えるには 実に優れた方法 です。(優秀なソフトウェアエンジニアが折れ線グラフを作成するためにExcelを使ったときはがっかりしました)。
目標に向かって、”1回限り”の分析スクリプトではなくて、あらゆる問題に採用できる、信頼できるツールやフレームワークを構築することに目を向けてきました( StitchFixにJeff Magnussonが投稿した、これら一般的な挑戦のいくつかについて素晴らしい記事 があります)。私のアプローチはRの内部パッケージを構築することで、 AirBnbの手法 に似ています(もっとも私たちのデータチームは彼らに比べれば、年数も浅く規模も小さいですが)。これらの 内部パッケージ は、さまざまな安全面とインフラストラクチャーの問題をユーザに目に見える形で提示することを含めて、データベースとinternal APIの分析についてクエリすることができます。
またRのチュートリアルを構築し、”搭載された”マテリアルを書くことも含まれます。例としては、データベースのクエリに内部の sqlstackr パッケージを導入した チュートリアルを公表しました 。これは ^(2) 一般的なdplyr/tidyr/ggplot2の導入を兼務し、兼務することによってdplyrチュートリアルと開発者を結びつけるよりも、より有効であると分かりました(なぜなら、このデータは間違いなく私の同僚たちが興味を持つに違いないからです! )私の希望としてはデータチームが成熟し、Rについて学ぶエンジニアが増えていくにつれ、このパッケージとガイドのエコシステムが本当の意味で内部のデータサイエンスプラットフォームに拡大していってほしいと思います。
学術界と産業界
よく好んで使われるデータサイエンティストの定義があります。
Data Scientist (n.): Person who is better at statistics than any software engineer and better at software engineering than any statistician.
— (((Josh Wills))) (@joshwills) [2012年5月3日](https://twitter.com/joshwills/status/198093512149958656)
データサイエンティスト(名詞):ソフトウェアエンジニアの中でも統計が得意な人物、そして、統計学者の中でもソフトウェアエンジニアリングが得意な人物。
これは好意的に言っているバージョンではありますが、悩ましいのは逆もしかりであることです。大学院の 私の研究室 では、私よりも他の人たちのほうが統計について知っていました。そして新しい職場では、私よりも同僚たちのほうがソフトウェアエンジニアリングについて知っています。では、どのように移行してきたのでしょうか。
同僚たちよりも統計学について知っている
“Programmers Need To Learn Statistics”(プログラマは統計学を学ぶべき)という主張については、仰々しい記事が山ほど出ています 。私が、同僚よりも統計学的な経験とトレーニングを積んでいることは確かです(またとりあえず社内初の博士でもあります)。しかし、そのことが仕事に支障を及ぼしていると感じたことはありません。
ひとつの理由は、多くの重要な分野において、プログラマと統計学のギャップは埋まりつつあることに気付いてきたことです。これまでに出会ったA/Bテストを解析する開発者たちは、既に、効果量と信頼区間の重要性や、p値ハッキングと複数仮説に基づく検定の危険性にも気付いていました。特にデータチームは、実施基準を普及させようと努力していました。慣れるのにより時間がかかったギャップは、「線形回帰よりもポアソン回帰を使う」、あるいは「対数スケールを使うべき時を知る」といった分野に多かったようです。
さらに重要なのは、私が統計学に関する件を持ち出すたび、開発者たちが非常に熱心に耳を傾け、学ぼうとしているのを知ったことです。今のところ、職場において信頼関係を築き上げられていると感じています。この経験は、開発者を過剰な自信だけで突っ走るものとして描く “Programmers Need To Learn Statistics” のような記事とは相いれない例のひとつです。この点において、私たちのエンジニアリング部門が例外的にうまくいっているにすぎない可能性もありますが(他社からひどい話をたくさん聞いてきました)、統計の重要性が広く認識されるにつれ、ソフトウェア開発業界の姿勢がこの6年間で変わったのだ、と言うこともできるでしょう。
他者から統計について学べたのは、大学院だからこそできた得難いことでした。私は自分よりも知識のある人たちに囲まれており、研究室のミーティングやセミナーでは余りあるほど有用な統計理論や方法論に触れることができました。また、もし間違いを犯しても誰かが助けてくれるという安心感もありました。現在は、統計学を学びたければ自発的に行わねばならず、また自身の仕事に細心の注意を払う必要があります。例えばもしレポートで不適切な統計的仮説を使ったとしても、誰からも指摘されない可能性が高いからです。
同僚たちよりもソフトウェアエンジニアリングについて知らない
これまでずっとプログラミングの実践に関心を持ち続け、長期に渡ってGitHubを使い、PythonやRなどのオープンソースプロジェクトに寄与してきましたが、テック企業への参加はまさにある種のシフトでした。私は物心ついて以来Macユーザで、この数年はRに全ての時間を捧げてきました。Stack OverflowはMicrosoftのテクノロジ、特にC#、ASP.NET、そしてSQL Serverで構築されていて、私が加わるまでは社内にRの経験者はいませんでした。 言語戦争のある一面にこだわるわけではありませんが 、その変化が自分にとってどのような意味を持つのか不安でした。
しかしこれもまた大した問題ではないのが明白になり、さらにMacとRだけで会社に多大なる貢献ができることも分かってきました。 RSQLServer と jTDSドライバ の開発者に負うところも大きいです。彼らのお陰で、私は容易にRStudioからデータベースを照会することができます。Visual Studioを立ち上げたParallels Desktopのウィンドウを常に開いていますが、ほとんどの場合、その必要もない状況です。時々、コードをプッシュすることもありますが(たいてい広告ターゲットの実験に関するもの)、特に摩擦の原因にはなっていません。フロントエンドWebデザインとサイト信頼性エンジニアリングを含め、ソフトウェアエンジニアリングにおいて同僚に比べると 非常に 知識が限られている分野はたくさんありますが、多くの企業と同様、結局はそれらの懸案に関わることはありません。
その他の変化
生物学の研究をやめたこと。 恐らく、これが最も気をもんだ変化と言えるでしょう。8年間(学部時代のほとんどの時間を含む)、私は生物学を中心に研究してきたのです。正直に言うと、数カ月間を費やして他の問題に取り組んで初めて、 自分が決して生物学の問いにそこまで熱意を感じていなかった ことに気付いたのです。
@daattali @JennyBryan @noamross @hspter
Me: I had the weirdest, longest dream I cared about RNA
Wife: That wasn't a dream it was a PhD
— David Robinson (@drob) 2016年4月16日
訳:
「 @drob @JennyBryan @noamross @hspter 6日後に、僕もバイオの次のフェーズに加わるよ!」
「 @daattali @JennyBryan @noamross @hspter
僕『かなり妙でしかも長い夢を見たんだ。夢の中で、僕はRNAについて考えていた』
妻『それ夢じゃないわよ、博士課程のことでしょ』」
生物学を勉強すると、コンピュータや統計学についての課題がたくさん出てきます。そして、バイオインフォマティクスという分野では面白い動きがたくさん起こっているんです。しかし生物学のデータの分析をやめると、結局は自分自身を解析するための知識や興味が無かったのだ、ということになってしまうでしょう。例えば、刺激への反応として100個の遺伝子の発現が変化したら…といった解析です。(何年も酵母のゲノムについて研究した後でさえ、遺伝子名で認識できる遺伝子は、手で数えられる程しかありません)対して、私は長年のStack Overflowユーザであり、ソフトウェア開発のエコシステムの状況にも、広く興味を持っています。ですから上述したネットワーク図のように、分析結果を見れば意味のあるものかどうかすぐに分かります。自分が本当に興味を持っているデータを扱うということは、これまでと 違う と感じます。
文章を書くこと: これはその価値に今まで気付いていませんでしたが、私の武器です。学位を取るために、たくさんの文章を書きました。主に学術誌の論文や博士論文です。そして実は、その手のフォーマルな文章を書くことを かなり大げさ に感じます。この1年間、私の書く文章は内部向けのレポートや書類やブログ投稿の記事でしたので、カジュアルな口語体で書くようになりました。(どれでもいいのでこのブログ記事のどれかと、 私の博士論文 の文章を比べてみてください)発表を目指している研究がいくつかあるのに、この理由で、学術論文のための文章を書くマインドセットに戻るのが とても難しい です。
一緒に働いた人たち
私のユーモアのセンスはちょっと変わっています。私のツイートには架空の「Dev」がよく登場して道化役をしてくれます。エンジニアの文化や私の知らない文化を風刺しているんです。
Me: You can't just add two p-values together.
Dev: The hell I can't:
newPval = pval1 + pval2;
Me: But-
Dev: Is all statistics this easy
— David Robinson (@drob) 2016年3月29日
僕「p値とp値を足すなんてダメだよ」
Dev「いやいや。newPval = pval1 + pval2;」
僕「えっ」
Dev「統計学ってこんな簡単なんだ」
Me [smugly]: So you see, when you use the right correction, the p-value is .023, not .02
Dev: Are you the guy who broke the build yesterday
— David Robinson (@drob) 2016年4月11日
僕「(平静を装って)なるほど、それじゃ正しくはp値は.023なわけだ。.02じゃなくて」
Dev「昨日このコード壊したのって君?」
分からない方のために言っておきますが、この一連のツイートは露骨なウソなんです。まず初めに、こういったやり取りは実際には起こっていません。しかしもっと重要なのは、ツイートの登場人物は、私の同僚の開発者を象徴していることは全くないということです。この会社の人たちはみんな、頭が良くて有能で思いやりもあります。これは、この職場の気に入っている部分の一つです。
職場のいいところをリストにすると長くなります(きっと間違いなく、データチームと広告サーバチームの全メンバーが入ります)ので、少しだけ例を挙げてみます。 Jason Punyon は、私のベータ分布についてのブログ記事を最初に見つけた人で、開発者です。Jasonは優秀なエンジニアで、この会社にいる6年間で培った製品知識は膨大な量で、しかも有益です。私が本当に感銘を受けたのは、データを大切に扱うことと、ユーザを大切に扱うことを両立しているところです。
数カ月前、私はある実験をしました。求人広告に載っている給与額と、実際の報酬額とを比較し(この実験については、また今度別のブログ記事に書きます)、社内で結果を共有しました。私はただ共有することがうれしかったんです。けれどJasonは結果を受けて、アクションを起こしました。雇う側の人たちみんな(我が社も含みます)に、給料の情報を提供するよう求め始めたのです。彼は、自分自身の選択や会社の意思決定のための材料として、データを真剣に見ています。また、開発者たちのことを、人としても自社製品のユーザとしても大切に思っているので、待遇の情報を前もって知る権利があると考えたのです。私は彼と同じ会社で働けることを誇りに思います。
私が感銘を受けた人は、エンジニア部門以外にもたくさんいます。ですから、 コミュニティチーム と一緒に仕事をするのは特にうれしいです。例えば、 Taryn Pratt (別名 bluefeet )は、私より数カ月早くチームに参加しました。私はここで仕事をする前、Stack Overflowのコミュニティに回答を投稿していましたが、Tarynの貢献とは 比べ物になりません 。彼女は、長年熱心に回答し、モデレータも務めました。そして、その間に、3,500以上の質問に答え、22,000を超えるhelpfulのフラグを立てたのです。これは驚くべき数です。
Tarynは、ここでは開発者ではありませんが、素晴らしい技術経験とスキルを持っています(コミュニティのマネージャのほとんどがそうです)。そして、彼女は、Stack Overflowのコミュニティで、こういったスキル、特にSQL関連の質問によく回答しています。その中で、彼女は最近Rを学び始めました。ですから、そうしたQ&A活動に対して統計的かつデータ主導型のメソッドを適用して、Q&A活動のパターン解析やその理解もできるはずです。彼女やチームの他のメンバたちの力によって、データサイエンスがコミュニティで役立つ様子を見ると、とても興奮します。
大学院生への私からのアドバイス:成果を公開してください。
私がここで働き始めて間もなく、Jasonのツイートの裏で、社内で私を雇うと良いのではという話が思い付きで始まったと聞きました。

注釈:おっと、こいつを雇ったらどうだろう?
今、この仕事に携われていることを本当にラッキーだと思っています。そういう事情を知ると、さらにうれしく感じます。私の就職は、恐らく、予想だにしなかった偶然の産物どころではなく、その経験からアドバイスできるようなことは見つかりません。しかし、大学院生にアドバイスを送るとしたら、私が思い付くのはこれです。 成果の公開は、時間の無駄ではない。
大学院在学中、私は自分の論文を発表するのに必死でした。学位を取るのに必要なことでしたし、私のキャリアを左右する唯一のものだと思い込んでいたからです。結局、私は、自分の専門分野で博士号を取るために、大体平均的な数の論文を発表しました( ここ で確認していただけます)。私としてはそれで満足でしたが、正直言いますと、発表数がもっと少なかったり、全くなかったりしたら、私の人生はどうなっていたのか分からず、別物になっていたことでしょう。しかし、確かに言えることは、ベータ分布についての投稿をしていなければ、私の人生は違っていたでしょうし、Stack Overflowで回答することがなければ、もっと違う人生になっていたでしょう。
学術論文は、研究成果を発表する1つの方法です。しかし、それが唯一ではありません。というのも、学術論文は査読に時間がかかり、提出時に”完璧である”ことが求められます。学術論文が研究成果を公にする 唯一の 方法とする態度は危険であり、だからこそ、優れた学術研究の多くが長年放置されたり、 論文とは言えない として(恐らく私のブログ記事は全て、学術論文としての提出の基準を満たしていないでしょう)、完全に抹殺されたりしているのだと思います。ですから、私が言いたいのは、何か面白いものを持っているけれども論文とは言えない場合、ブログの投稿やStack Overflowでの回答、あるいはGitHubのオープンソースプロジェクトとして書けばいいんです。 とにかく、公開してください。
冒頭に言ったように、私は、ベータ分布に関する質問に答えておいて本当に良かったと思います。それによって製品に関わる作業をする機会を得て、私のプログラミングの知識が増え、生産性が向上しました。製品を構築する人々と一緒に作業をしますが、彼らからは、今日までずっと感銘を受けています。ここでの1年は、私が望める限りの最高の仕事でした。
いや、ほぼ最高の。
*Sigh*
Back to work I guess pic.twitter.com/rjHmPk3X0V
— David Robinson (@drob) 2016年4月7日
ため息
仕事に戻ります。
-
Stack Overflowの作業をしていて、internal Rツールの使用方法についてもっと知りたい場合は、 このガイドを確認してください 。これには、他のチュートリアルへのリンクが含まれています。 ↩
