2015年11月2日
Airbnbのメインデータベースをどうやって2週間で分割したか
本記事は、原著者の許諾のもとに翻訳・掲載しております。
スケーリング=時速160㎞で走行しながら自動車の全ての部品を取り替えること
-Mike Krieger Instagramの共同設立者@ Airbnb OpenAir 2015

Airbnbのピーク時のアクセス数は、毎年夏のピーク時で見ると年率3.5倍で増加しています。
2015年夏の旅行シーズンを前に、Airbnbの基盤チームは、夏季のアクセスで予想されるデータ通信量に対処するため、データベースのスケーリングで忙殺されていました。中でも特に全体への影響が大きかったプロジェクトが、特定のテーブルを、アプリケーションの機能に従ってそれぞれのデータベースに分割することを目的としたプロジェクトでした。これは通常、アプリケーション層のフォームの変更やデータ移行、データの整合性を保証する堅牢性テストなど、最小限のダウンタイムで多大な技術的投資を必要とするものです。何週間もかかるエンジニアリング時間を短縮しようと知恵を絞る中、私たちの 優秀なエンジニア の1人が、データの整合性を保証するという難しい課題に対してMySQLのレプリケーションを活用するという興味深いアイデアを提案しました(このアイデアは別途、AmazonのRDSの”Read Replica Promotion “機能の 明示的な使用例 にリストアップされています)。データベースの分割に際して、ダウンタイムを短期間かつ制約内に抑えることにより、たった1行のブックキーピングも移行コードも書かずに、オペレーションを遂行することができました。ここでは、私たちの仕事と、その遂行過程で学んだことを皆さんと共有したいと思います。

まずは、背景説明
私たちは「水平シャーディングは苦い薬である」という Percona や Asana の意見に賛同しがちです。そのため私たちは、ロードを分散するとともに、エラーの影響範囲を分離するため、アプリケーション機能による垂直分割の手法を取りがちです。例えば私たちのデータベースは、各データベース専用のRDSインスタンス上で処理を行っており、独立したJavaとRailsサービスに対して1対1対応でマップしています。しかし歴史的経緯から、核となるアプリケーションデータの多くは、依然としてAirbnbがシングル・モノリシックなRailsアプリケーションだった頃からのオリジナルのデータベース上にあります。
データベースのアクセスパターンを分析するために社内で構築したクライアント側のクエリプロファイラ(RDSの制約上、クライアント側にある)を使って、ゲストとホストがコミュニケーションできるAirbnbの受信トレイの機能が、メインデータベースの書き込みの1/3近くを占めていることを発見しました。さらに、書き込みのパターンはアクセス数とともに直線的に増加しているので、これを分割することは、メインデータベースの安定を図る上で非常に重要になります。またこれは独立したアプリケーション機能なので、テーブルのクロス結合とトランザクションの全てが除外され得ると確信しました。そこでこのプロジェクトを最優先に取り掛かり始めました。
このプロジェクトの選択肢を検討する際、決定に影響を与えた2つの事実があります。1つ目は、データベースを最後に分割したのが3年前の2012年だったということです。ですから、現在のデータサイズでこのオペレーションを行うことは新しい挑戦であり、私たちは当初予定していたダウンタイムを犠牲にしてでも、技術的な複雑性を最小限にしようとしました。2つ目ですが、2015年を迎えた頃には、我が社は約130人のソフトウェアエンジニアを擁していました。各チームは、パーソナライズ検索、顧客サービスツール、信頼と安全、グローバルペイメント、接続制限を考慮した信頼性の高いモバイルアプリなど、製品の幅広い分野に広がっていて、基盤専門の技術が占める割合はほんのわずかでした。こうしたことを考慮して、技術的な複雑性と必要な投資を最小限に抑えるために、MySQLのレプリケーションを利用することを選んだのです。
プラン
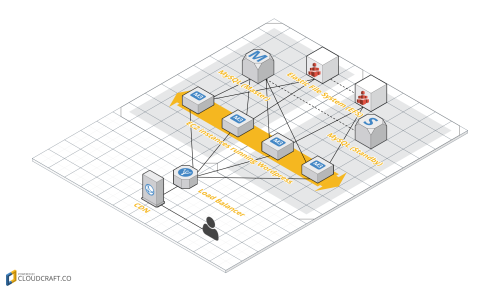
データ移行のためにMySQLの組み込みレプリケーションを使うと決めたことにより、レプリケーションによって等価性が証明されるので、今後はデータの整合性を保証するために自分たちで非常に厄介な構築作業を行う必要はなくなりました。MySQLをAmazonのRDS上で処理すれば、新しいリードレプリカが作成され、スタンドアローンマスタに容易にレプリカが移行されます。私たちのセットアップは、以下のような図になります。

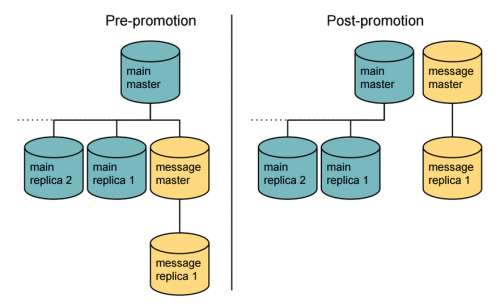
メインマスタデータベースから新たなレプリカ(メッセージマスタ)を作成し、それを昇格させることで新たに独立したマスタとして機能します。次に第2層のレプリカ(メッセージレプリカ)をつなげ、それがメッセージマスタのレプリカとして機能します。問題となるのは、作業が完了するまで、 昇格に数分 、またはそれ以上時間がかかるということです。その間、データの整合性を保つために、関連テーブルへ書き込みを故意にエラーとしなければなりません。データベースへの過重な負担によって、Webサイト全体にダウンタイムが発生すれば、受信トレイだけに局所的に制限した場合のダウンタイムよりコストがかかってしまいます。そうした理由から、チームは開発にかかる数週間を削減するために、この条件を進んで受け入れました。自身のデータベースを管理している方たちのために触れておいたほうがよいと思いますが、 レプリケーションフィルタ は関連テーブル以外のレプリケーションの防止に利用できるので、潜在的に昇格の期間を短くできます。
フェーズ1:事前計画
受信トレイのテーブルを新しいデータベースへ移行すると、クロス結合を要する既存のクエリが無効なものになってしまう可能性がありました。データベースの昇格を元に戻すことはできないので、このオペレーションの成功は、こうした全てのケースを特定し、それらを廃止するかアプリ内の結合で置き換えるかを判断する能力にかかっていました。ありがたいことに、内部クエリアナライザによって、ほとんどのメインサービスにおいて、こうしたクエリを容易に特定できました。そして他のサービスのカバレッジを完全に保てるように、関連データベースの許可を取り消すことができました。Airbnbで仕事を進める上で目指すアーキテクチャ上の原則の1つは、サービスは自身のデータを持つべきであるということでした。この原則のおかげで仕事は非常にシンプルになりました。技術的には簡単でも、チーム間で十分なコミュニケーションを取る必要があったので、このフェーズはプロジェクトで最も時間がかかりました。
次は、オフラインのデータ分析とダウンストリームの製品サービスの両方を強化する広範囲のデータパイプラインです。つまり、事前計画の次のステップは、昇格後に最新のデータを使うことを確認するために、メッセージレプリカのデータエクスポートを使うための全ての関連パイプラインを移動することでした。移行プランの副作用の1つは、たとえデータが昇格後に分岐しても、新しいデータベースが既存のデータベースと同じ名前となってしまうことです(RDSのインスタンスである、メッセージマスタとメッセージレプリカと混同しないでください)。しかし、これにより実際には、データパイプライン内の整合性を保つネーミングルールを保持することができたので、データベースのリネームは選択しませんでした。
このフェーズの最後となりますが、メインのAirbnb Railsアプリケーションはこれらのテーブルに対して書き込みの排他制御があるので、主要なオペレーションの複雑性を緩和するために、すべての関連サービスのアクセスを新しいメッセージデータベースレプリカへスワップすることができました。
フェーズ2:オペレーション

プロダクション基盤チームのメンバーにとって勝負の日
事前計画の準備が全てそろったら、実際のオペレーションは以下の手順で行いました。
-
受信トレイに10分間以下のダウンタイムが発生する予定であることを顧客サービスのチームに伝えておきます。ダウンタイムのせいで、ゲストがAirbnbにチェックインする時に外国で途方に暮れてしまう場合があります。ですから、ループの中で適切な機能を全て維持し、アクセス数が最低の週の間にオペレーションを実行することが重要なことです。
-
新しいメッセージデータベースのユーザ権限とデータベースの接続を使用するために、受信トレイのクエリへの変更をデプロイします。このステップではまだ、読み出しはメッセージレプリカに送られ、書き込みはメインマスタに送られます。ですから、ここではまだ外部への影響はありません。しかし、メインマスタへの接続が二重になってしまうので、オペレーションが始まるまではこのステップをストップさせます。このステップは可能な限り短時間にさせたいところです。データベースホストを次のステップでスワップする時にデプロイは必要ありません。これはZookeeperのデータベースホストエントリをアップデートする、コンフィギュレーションツールがあるためです。Zookeeperは SmartStack で見つけることができます。
-
受信トレイの全ての書き込みアクセスをメッセージマスタにスワップします。ここではまだ移行が完了していないので、新しいマスタ上の全ての書き込みはエラーになり、ダウンタイムの開始を計測し始めます。読み込みのみのクエリならば成功する状態にはあるのですが、実際にほぼ全てのメッセージ機能がこの間はダウンします。これは、メッセージを既読にするというクエリにDBへの書き込みが必要だからです。
-
ステップ2で紹介したメッセージデータベースユーザとメインマスタと全てのデータベースの接続を切断します。デプロイやクラスタのリスタートをする代わりに直接接続を切ることで、レプリケーションが追いつくのに必要である、新しいマスタとして機能するレプリカに、全ての書き込みを移動する時間を最小限にすることができます。
-
以下のことを調べてレプリケーションが追いついているか確認します。
1.受信トレイの全てのテーブルの最新のエントリがメッセージマスタとメッセージレプリカに記録されている。
2.メインマスタの全てのメッセージ接続は切断されている。
3.メッセージマスタの新しい接続が成立している。 -
メッセージマスタをプロモートします。今までの経験から、データベースはRDS昇格の間に約30秒間、完全にダウンし、その間にマスタの読み出しもエラーになります。しかし、昇格は起動後、作動するまで約3分30秒かかるので、書き込みは4分間近くエラーとなります。
-
次のRDSの自動バックアップウィンドウが現れる前に、新しくプロモートされたメッセージマスタの マルチAZ配置 を有効にします。フェイルオーバーのサポートを強化するのに加え、マルチAZがRDSスナップショットやバックアップ中のレイテンシの急上昇を最小にしてくれます。
-
全てのメトリックがうまくいって、データベースが安定したら、各データベースの関連のないテーブルをドロップしてください。最後のこのステップは、無効なデータをどのサービスも消費しないようにするために重要です。
もしオペレーションが失敗していた場合は、Zookeeperのデータベースホストのエントリを取り戻し、受信トレイのテーブル機能をただちに修復していたでしょう。しかし、独立したメッセージデータベースに到達した書き込みは失われる可能性がありました。理論上は、失われたメッセージを修復するのは可能でしたが、それは簡単ではない試みですし、ユーザを混乱させてしまったでしょう。ということで、オペレーションを実行する前に、私たちはしっかりと上記のステップをそれぞれテストしました。
結果

メインデータベースマスタの書き込みの明らかな下降
このプロジェクトは開始してから完了するまでに2週間かかり、受信トレイのダウンタイムはちょうど7分半以下となり、メインデータベースのサイズは20%縮小しました。そして、一番重要なことは、メインマススタデータベース上の書き込みのクエリを33%縮小したことで、非常に安定したデータベースを得られたことです。このクエリが縮小されていなかったらこの先数カ月間でさらに50%増加すると見込まれていました。これは明らかに私たちのメインデータベースでは限界を超えてしまっていました。ということでこのプロジェクトのおかげで、長期的なデータベースの安定性や拡張性への投資を追求する貴重な時間を過ごすことができました。
サプライズ:RDSスナップショットはレイテンシを非常に増加させる可能性がある
以下は RDSのドキュメンテーション からの引用です。
シングルAZ配置とは異なり、MySQL、Oracle、およびPostgreSQLエンジンのマルチAZ配置のバックアップ中は、スタンバイからバックアップが実行されるため、プライマリのI/Oアクティビティは停止しません。ただし、マルチAZ配置のバックアップ中に、数分間、レイテンシが増加する可能性があります。
ほとんどの場合、RDSの高い有用性とフェイルオーバーのサポートを最大限に活用するために、RDSの全てのマスタインスタンス上のマルチAZ配置は有効にします。今回のプロジェクトの作業中に、データベースのロードがかなり重くなったことで、RDSスナップショット中に発生したレイテンシが、AZ配置が機能していても、クエリのバックログを生成し、データベースをダウンさせるのに十分な影響を及ぼしたことを私たちは目撃しました。常に覚えておきたいのは、スナップショットはレイテンシを増加させるということです。しかし、このプロジェクトより前には、私たちはデータベースのロードに関連したレイテンシの非線形的増加がダウンタイムに影響する可能性について気付いていませんでした。
RDSスナップショットが日々の自動バックアップのために私たちが頼っているコアなRDSの機能性であるというのを考えればこれは重要なことです。メインデータベースのロードの増加や、RDSスナップショットがサイトを不安定にする原因になりやすいという事実は、以前は私たちにとって未知の世界でした。しかし、プロジェクトを進めてみると、当初予測していたよりも緊急を要するものだったということに気付かされました。

オペレーション後にお祝いをしている、今回のプロジェクトのリーダーエンジニアのXinyao
謝辞:私がBen HughesとSonic Wangからの助言を元に当初の計画を書いていた時にプロジェクトを率いてくれたXinyao Hu。テーブルのクロス結合を消去するためにコードをリファクタリングするのを手助けしてくれたBrian MoreartyとEric Levine。オペレーションを実行していた午後の時間を楽しく過ごしてくれたプロダクション基盤チームのみんな。
プロダクション基盤 チームの過去のプロジェクトを以下よりぜひチェックしてください。

株式会社リクルート プロダクト統括本部 プロダクト開発統括室 グループマネジャー 株式会社ニジボックス デベロップメント室 室長 Node.js 日本ユーザーグループ代表
- X: @yosuke_furukawa
- Github: yosuke-furukawa
関連記事