2016年1月6日
Amazon Redshiftで顧客分析ソリューションを構築
本記事は、原著者の許諾のもとに翻訳・掲載しております。
このブログ記事では、私たちの製品の使用運転を基に、Amazon Redshiftを使った顧客分析の構築方法を説明していきます。この記事で扱う内容は以下の通りです。
- なぜ顧客分析に移行しつつあるのか?
- あなた は、顧客分析を構築すべきか?
- Amazon Redshiftが普及してきている理由
- データを可視化するBIツールの選択
- Amazon Redshiftクラスタの設定
- Alooma でデータパイプラインを構築
- エンゲージメント、リテンション、ファネル、パフォーマンスダッシュボードを作成するための一般的なSQLクエリ
顧客分析の台頭
今日では、何かしらの分析ツールが実装されていないWebサイトやアプリケーションを探すことは難しいと言っていいでしょう。製品を作ったり、戦略的な意思決定をしたりする上でデータを活用することは常識ですし、消費者市場ではことさら必要不可欠なことです。製品の変更に対して、顧客がどう反応するのかの直感的なイメージがあったとしても、時に彼らの反応が驚くべきものになることがあります。分析を基にした製品開発という現代のアプローチは、異なる仮説のテストや製品のパフォーマンス測定、学習、そして製品やサービスを継続して向上させることを可能にしています。
壁を取り払う
GoogleアナリティクスやFlurry、Mixpanel、Localytics、Segmentといった多くの分析ツールは、Web開発者やモバイル開発者が分析を行いやすい製品です。これらのソリューションは通常、複数のプラットフォームに対応した簡単にインストールできるSDKや、ユーザエンゲージメントやファネル、ユーザリテンションを含む、最も一般的な種類の分析向けに、独創的なダッシュボードを提供しています。これらの製品の最も重要な利点の一つは、エンドツーエンドソリューションを提供していることです。また、クライアント側のSDKの開発、構成、設定をすることができたり、メトリクスの収集やデータを保存したりするためのデータウェアハウスの設定、そして分析や可視化ツールを作成するための独自のデータパイプラインを構築することができます。簡単だと思いませんか?
実際、Amazon RedshiftやGoogle BigQueryといったツールを使うことによって、独自のデータウェアハウスやデータ可視化ツールを保有したり管理したりすることの費用と複雑性は軽減されているので、多くの企業が独自の顧客分析を構築することを好んでいます。自分のカスタムソリューションから得られる強力なインサイトを考えれば、独創的でシンプルなものからの移行には、それだけの価値があるということです。
例えば、私たち Alooma では、マーケティングやセールスパイプラインの分析や向上のために独自の顧客分析を構築しています。Webサイトを訪れた人たちがどのようなアクションを取っているかのデータを収集し、それらを私たちのFacebookに掲載される広告やGoogle Adwords、またはSalesforceから得たデータと相互に関連付けています。これによって、セールスやマーケティングパイプラインの各要素のパフォーマンスを分析するダイジェストダッシュボードを簡単に構築することができたり、各キャンペーンでのROIを全体的な視野でとらえることができたりするのです。つまり、どのようなことが機能して、どのようなリソースが私たちのセールスやマーケティングの取り組みに対して効率良く割り当てることができるのか、正確に理解することができるわけです。独創的なソリューションでは、こういったことを提供することが難しい場合があります。
それでは、 Alooma で活用しているAmazon Redshiftを使って、独自の顧客分析をどのように構築することができるのか掘り下げていきましょう。
顧客分析を構築するのはなぜか?
独創的なソリューションが多くある中で、なぜ独自の顧客分析を構築する必要があるのかと、まず疑問がわいてくるかと思います。これまで私たちは、数多くの企業と話をしてきましたが、その中で何度も耳にしてきた主な理由を以下に挙げます。
- データの所有 – データは強力なものです。顧客に関するデータには、莫大な価値があることを現代の企業は認識しています。いくつかの企業にとっては、最も価値のあるアセットがデータです。彼らは、データが正しく扱われ、常にそれらのアクセス権や所有権の保持が約束されているかを明らかにしておきたいのです。
- カスタムクエリと深いインサイト – サードパーティーのソリューションに内蔵されているダッシュボードは迅速さを提供してくれますが、実装は各サードパーティーのソリューションが決定するので自由にダッシュボードを扱うことができません。どの企業も独自のクエリを書いたり、カスタムリポートや答えを得られるダッシュボードの構築をしたりすることが必要であるという、業界に対する固有の課題を持っています。
- 複数のデータセットの統合 – ビジネスの全体像をつかみたいと思うなら、複数のデータセットの統合が必要になるでしょう。例えば、Web分析データとSalesforceデータとを統合することで、オンラインマーケティングキャンペーンが提供している本来の価値を見定めることができます。独自のデータウェアハウスに複数のソース(分析データ、サーバログ、CRMなど)を統合することによって、データセットを連携することができるので、まとめてクエリを行うことができます。これによって、ビジネスの全体像をつかめるというわけです。
- 機械学習 – データを所有しているのであれば、レコメンドシステムを開発するための機械学習を活用したり、各ユーザに対してカスタム・エクスペリエンスを作り上げたり、各ユーザの潜在価値の評価や、カスタマイズされたキャンペーンで価値の高いユーザに対象を設定しなおすことができます。ただし、全部の生データにアクセスすることができければ、このレベルの精度を実現することは難しくなります。
- コスト – サードパーティーのソリューションは通常、低コスト(もしくは無料)で初心者向けの金額が設定されていますが、規模を拡大していくにつれ、コストは高くつきます。コストを削減するために、企業はよくデータのキャプチャや保存量に制限をかけています。その時点では名案のように思われますが、将来的に履歴データが必要になったとき、その履歴データが「毎月の費用の低減」の名のもとにキャプチャされずにいた場合、問題を引き起こすことになります。私たちの経験では、1日(もしくはそれ以下)に数百万イベント以上処理しているのであれば、独自のカスタム・ソリューションを構築した方が、よりコスト効率が良くなります。
データウェアハウスにAmazon Redshiftを選んだ理由
Redshiftは2013年に公開され、たちまちビッグデータ分析の世界へと私たちを導いてきました。これは2014年中にAmazon Web Servicesの製品で最も急速な成長を遂げた製品です。Redshiftは、ハイパフォーマンスでありながら低コストを実現しており、高い費用対効果を生んでいます。この製品の基礎となるのはカラムナストレージ技術で、アグリゲーションやハイスループットのデータ採集を必要とする分析クエリに最適です。
- 高速 – 大規模な並列処理ウェアハウスアーキテクチャなので、SQLオペレーションを並列したり分散したりする上で、全ての入手可能なリソースを活用することができます。
- スケーラブル – より多くのストレージやより良いパフォーマンスを実現するのに、数回のクリックでより多くのノードをスピンアップできます。最大2ペタバイトです!
- セキュア – Amazon VPC(仮想プライベートクラウド)といったツールを使用することで、停止時ではデータが暗号化され、Redshiftのネットワークは隔離されます。
- 費用対効果 – 他の商業製品よりも、ざっと1桁はコストが安くなります。
自分自身でデータパイプラインを構築すべきか?
データをある場所から別の場所へと移行するのは簡単だと思われますよね? 膨大なデータ量、絶え間なく変化するサードパーティーサービスのスキーマやAPI、フォールトトレランス、そしてエラー処理を考慮した場合、その大変さに圧倒されることでしょう(それに一定の維持費が必要です)。これについては、私たちの別のブログ『 Building a professional grade data pipeline(プロフェッショナルグレードなデータパイプラインの構築) 』で詳しく紹介しています。
どの可視化ツールを選択すべきか?
特定のニーズや予算に応じて、様々な可視化ツールから最適なものを選択することができます。
- re:dash – オープンソースの可視化ツールです。比較的ベーシックなインターフェースや機能群で、無料のオープンソースです。自分でサーバにインストールする必要があるので、少し面倒かもしれませんが、なんといっても無料ですから。
- Amazon QuickSight – AmazonのBIツールです。コストと機能群を天秤にかけたときに最も費用対効果の良いソリューションだと言えるでしょう。
- Mode – よくデザインされたクラウドベースの可視化ツールで、データを素早く検証したり、チームメンバーとインサイトを共有したりすることができます。re:dash同様、重度にSQLクエリを書くことに依存しており、高い柔軟性を提供してるのですが、高度なSQLスキルが必要となります。
- Looker – こちらもクラウドベースの可視化ツールです。複雑なSQLクエリを書かずに、複雑な分析を行うことができます。SQLのエキスパートでない場合は、ダッシュボードの作成やインタラクティブなグラフを作成するのに最適なツールです。
- Tableau – 最も普及している可視化ツールの1つです。通常オンプレミス(現在ではクラウドベースでも提供されています)にインストールされており、他のツールに比べると高額ですが、簡単なドラッグアンドドロップのインターフェースによって深い分析を行うことができます。
ステップ1 – Redshiftクラスタの設定
まずは、Redshiftクラスタを設定しましょう。AWSは手順を追って作業が進められる優れた スタートガイド と詳細な 価格表 を用意しています。
どのクラスタサイズを選択すべきか?
経験則からいって、データウェアハウスに保存したいデータ量の3倍のクラスタサイズが良いでしょう。3分の1をデータに、3分の1をクエリから作成した一時テーブルに使用し、残りの3分の1を予備にとっておきます。
例えば、毎秒1000イベント(EPS)のスループットでストリーミングしている1キロバイトあるデータイベントの6カ月間の記録であれば、最低でも 1kb*1000eps*3600[seconds/hour]*24[hours]*180[days]*3 = 46TB のクラスタを用意するといいでしょう。
クラスタに対してどのハードウェアを選択すべきか?
どのハードウェアを選ぶかは、あなたの特定ニーズ次第です。もし、複雑なクエリの実行、低いレイテンシの必要性があるのであれば、ハイパフォーマンスのDense Computeハードウェアを選択するといいでしょう。大量のデータを保存する必要がある、または予算に制約があるようなら、Dense Storageノードが良いでしょう。Redshiftの異なるノードについての詳細は、 こちら をご確認ください。
Redshiftクラスタがアップされ、実行できたら、次のステップに進みます。
ステップ2 – データパイプラインの構築
Redshiftでの顧客分析データパイプラインは、通常以下の機能から構成されています。
- データソースへの接続
- データのクリーニング、フィルタリング、エンリッチ化、変換
- Redshiftテーブルへのデータのマッピング
- Redshiftへのデータの読み込み
私たちはデータパイプライン企業ですから、 Alooma でデータパイプラインを構築しました。驚きました?
データソースへの接続
まず、データパイプラインは、あなたの全データソースからデータを取得する必要があります。いくつかのデータソースは、データパイプラインにデータをプッシュしてくれますが、パイプラインが自らデータをプルしなくてはいけないものもあります。例えば、iOSやAndroid、Webアプリケーションは、クライアントから直接分析イベントをプッシュしますが、あなたのデータパイプラインでは、最新の更新を収集するために、Salesforce APIを定期的にクエリしなくてはならないかもしれません。
Aloomaでは、全データソースを簡単に素早く統合できる、内蔵コネクタを多数提供しています。GoogleアナリティクスやMixpanel、Localytics、Segment、Amazon S3、Azureストレージ、 Salesforce 、MongoDB、MysQL、PostgreSQLを含むデータソースをサポートしており、 iOS 、 Android 、 JavaScript 、 Python 、 Java のSDKを提供しています。新しいデータソースを毎週追加しています。Aloomaは、構造化(Tabular)また半構造化(JASON)データに適応しており、ピーク時でもハイスループットを処理します。

データの送信
Webサイトやモバイルアプリのトラックを行いたいようであれば、Aloomaの JavaScript 、 Android 、 iOS SDKが利用できます。私たちのJavaScript SDKは、Webサイトの全ページビューを自動的にトラックします。関連する全てのユーザアクションもトラックした方がいいでしょう。例えば、私たちの会社ではセールスリードを監視するために、ユーザがコンタクトフォームを開いた時、閉じた時、送信した時のアクションをトラックしています。JS SDKを使っているときは、ページビューは自動的にトラックされます。
もし、オンラインマーケティングを実施しているようであれば、 キャンペーンパラメータ とランディングページのURLをタグ付けしておくことをお勧めします。これによって、訪問者のソースをトラックすることができます。私たち独自の実装では、支払いを行ったユーザが誘導されてきたキャンペーン、広告、キーワードを確認できるようにしています。そうすれば、各キャンペーン、広告、キーワードの本来のROIを分析することができるのです。
例えば、ランディングページのURLはこんな感じです。 https://www.alooma.com/?utm_source=alooma&utm_medium=content&utm_campaign=blog&utm_cotent=custom_analytics_to_redshift
Google Awardsは、キャンペーンレベルでのキャンペーンURLにトラッキングテンプレートを設定することで簡素化を図っていますが、Facebookや他の広告主の場合は、URLを提供する際に、手動で広告にタグを追加する必要があります。
データのクリーニング、フィルタリング、変換、エンリッチ化
全データソースから生データを入手したあと、Redshiftに読み込む前に準備が必要です。データポイントに対して関連するデータだけを対象とし、中には完全に無視したい場合や、変換したいデータもあれば、エンリッチ化(IPアドレスに従って地理位置情報を追加するなど)したいデータもあると思います。
私たちがよく遭遇する例としては、Redshiftはミリ秒でタイムスタンプを要求するのに対し、Mixpanelでは秒でタイムスタンプを保存する場合です。この問題を修正せずにMixpanelのデータを読み込もうとすると、Redshiftのデータが破損してしまいます。
Alooma では、簡単なPythonコードを書くことができ、データパイプラインの各イベントで実行することができます。Aloomaがデプロイメントとスケーリングを処理している間にPythonコードでデータのフィルタリング、クリーニング、変換が行えるのです。更に、サードパーティーのライブラリでデータのエンリッチ化も可能です。

Redshiftテーブルへのデータのマッピング
データがきれいになったら、Redshiftにどのようにデータを読み込むのかの定義を行います。
Alooma は、全イベント型の各フィールドをシンプルユーザインターフェース内に付随するAmazon Redshiftカラムに簡単にマッピングする手助けをします。自動マッピング機能は、Redshiftに互換性のあるカラム名を各フィールドに対して自動的に選択してくれ、フィールド統計を使って最適なカラムの型(varchar、integer、boolean、timestampなど)を決定してくれます。データスキーマが変更され、新しいフィールドが初めて登場すると、AloomaのダッシュボードにEメールで通知が届くようになっています。これは通常、データの紛失につながりますが、Aloomaでは、あなたがどうマッピングするのかを決めるまで、この新しいフィールドは別のキューに保存されます。新しいフィールドでマッピングの更新を行うと、カラムはAmazon Redshiftに生成されます。
新しいRedshiftテーブルの作成
新しいテーブルを作成するときは、分散キーとソートキーの選択に十分注意してください。このプロセスについては、『 Redshift’s best practices guide(Redshiftのベストプラクティスガイド) 』に詳しく記載してあります。
もし、ジョイン(ユーザIDやセッションIDなど)に使われているキーがあるようなら、それは分散キーとして使います。Amazon Redshiftでは、同じ分散キーと共に全データポイントは、同じパーティションに保存されます。これによって、クエリの間、ネットワークを通って送信されるデータ量が削減され、パフォーマンスが劇的に向上します。AloomaのWebまたはモバイルSDKを使用するようであれば、分散キーに適した選択は、Distinctユーザを意味する roperties_distinct_id です。また適したソートキーは、データの一部分だけクエリするためにタイムスタンプを使用するので、イベントの時間を意味する metadata_timestamp となります。

Redshiftへのデータの読み込み
データウェアハウスへのデータの読み込みは、特にAmazon Redshiftの場合は、注意が必要です。高いスループットの読み込みを行うために、データはバッチでバッファ・ロードされなくてはなりません。設計の際には、データの損失を防ぐために、Redshiftがメンテナンス(サイズ変更やバキューム)や長時間のクエリで利用ができない時があることを考慮する必要があります。
Alooma では、こうした全ての問題を考慮し、データの読み込みの最適化を行っています。Aloomaはデータをバッファリングし、マイクロバッチに読み込み、(利用可能であれば)読み込みプロセスを並列化し、最適なスループットやレイテンシを保ちます。通常データは、Aloomaに初めて到達した数秒後にRedshiftに読み込まれ、利用可能となります。

ステップ3 – 分析
この時点で、Redsiftにはあなたのデータがあるはずです。では、Aloomaでリードジェネレーションファネル分析をどのように構築するか実演してみましょう。
イベントテーブル
Redshiftテーブルには、ユーザが取ったアクションである、主なページビュー、開かれたコンタクトフォーム、そして送信されたコンタクトフォームのイベントがあります。私たちのイベントテーブルには(簡素化された)以下の構成があります。
| timestamp | distinct_id | event | page | os | … |
|---|---|---|---|---|---|
| … | … | … | … | … | … |
timestampはイベントの時間、distinct_idは特定のユーザに付けられたID、eventはイベント名(‘ページビュー’や‘開かれたコンタクトフォーム’など)、osはユーザのオペレーティングシステムになります。通常は、リファラや画面サイズ、国、都市といった、もっと多くのフィールドがあります(ここでは簡素化のため表示していません)。
Salesforceテーブル
Salesforceから2つの主なテーブルをインポートします。
- 見込み客 – これはWebサイトから抽出したもので、リードやソース、オーナー、そして実際に顧客になったかどうかの情報が含まれています。
- オポチュニティ – 見込み客が要件を満たしていれば(すなわち、あなたのビジネスに関連している)、Salesforceではオポチュニティとなります。このテーブルには、年収の見込みのオポチュニティサイズ、そして営業チームが見積もった契約締結の可能性が含まれています。
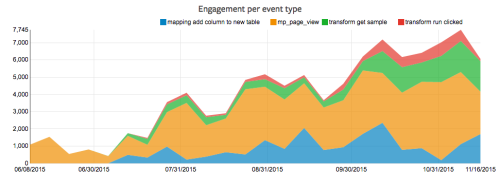
エンゲージメント
製品と併せてユーザのエンゲージメントの分析を試みる場合、毎日/毎週/毎月どのくらいのイベントを保存していたか、といったことを測定することができます。
毎週のイベント
このグラフを作成する簡単なクエリは以下のようになります。
SELECT date_trunc('week',metadata_timestamp) AS week,
count(1) AS COUNT
FROM events
GROUP BY weekするとテーブルはこんな感じになります。
| 週 | カウント |
|---|---|
| 2015年6月29日 午前12時 | 1,230 |
| 2015年7月6日 午前12時 | 889 |
| 2015年6月8日 午前12時 | 1081 |
| … | … |
そして最終的に、以下のようなグラフを作成することができます。

イベントが複数ある場合は、以下のクエリを走らせることでスタックチャートを作成することもできます。
SELECT date_trunc('week',metadata_timestamp) AS week,
event,
count(1) AS COUNT
FROM events
GROUP BY week, eventこの場合、‘イベント’カラムが追加され、結果がイベント型に分類されます。
| 週 | イベント | カウント |
|---|---|---|
| 2015年6月29日 午前12時 | mppageview | 1,230 |
| 2015年6月29日 午前12時 | contactformopened | 889 |
| 2015年6月8日 午前12時 | mppageview | 1081 |
| … | … | … |
最終的に、ユーザアクションがより明確で高精度なスタックチャートを作成することができました。

月間アクティブユーザ(MAU:Monthly Active users)
上記グラフにはアクションを起こしたユーザの実数が分からないという問題があります。アクションが増加したことは分かるのですが、その理由がユーザ数の増加にあるのか、あるいは元々のユーザが製品を多く使うようになったためなのかが分かりません。
ですので月間アクティブユーザを併せて計測します。
MAUのグラフは以下のクエリで作成します。
SELECT date_trunc('month',metadata_timestamp) AS month,
count(distinct properties_distinct_id) AS COUNT
FROM events
GROUP BY month
order by month desc| 月 | カウント |
|---|---|
| 2015年11月1日 午前12時 | 3,628 |
| 2015年10月1日 午前12時 | 3,979 |
| 2015年9月1日 午前12時 | 1081 |
| … | … |

ファネル
エンゲージメントのグラフは興味を引きますが、「虚栄の指標」と言われています。というのも、製品のパフォーマンスが向上したのか否かが分からないからです。エンゲージメントは、例えばマーケティングに多くお金をかければ、右肩上がりにできるのです。
ファネルでは製品が現実的に改良されたか否かを評価することができます。例えば、私たちのWebサイトの訪問者がどの程度取引に至った(コンバージョンした)かが分かります。コンバージョンレートが上がれば、実際に製品が改良された言えます。
ファネルには3段階あります。
1.ユーザがWebサイトを訪問する – ぺージビューイベント
2.ユーザがお問い合わせフォームを開く
3.ユーザがお問い合わせフォームを送信する
ファネルを表示する簡単なクエリは以下のようになります。
WITH timestamped_events AS
(SELECT properties_distinct_id,
min(CASE WHEN event = 'mp_page_view' THEN metadata_timestamp END) AS ts_landingpage,
min(CASE WHEN event = 'contact_form_opened' THEN metadata_timestamp END) AS ts_contactformopened,
min(CASE WHEN event = 'contact_form_sent' THEN metadata_timestamp END) AS ts_contactformsent
FROM events
GROUP BY properties_distinct_id)
SELECT sum(CASE WHEN ts_landingpage IS NOT NULL THEN 1 ELSE 0 END) AS landingpage_count,
sum(CASE WHEN ts_contactformopened IS NOT NULL THEN 1 ELSE 0 END) AS contactformopened_count,
sum(CASE WHEN ts_contactformsent IS NOT NULL THEN 1 ELSE 0 END) AS contactformsent_count
FROM timestamped_eventsクエリの前半では、各ページ訪問者の個別IDとその訪問者が初めて上記のアクションのどれかを行った時の一時テーブルを作ります。後半のクエリでは、それぞれの段階でアクションを起こした個別の訪問者数を計算します。
| ページ訪問者数 | コンタクトフォームを開いた人数 | コンタクトフォームを送信した人数 |
|---|---|---|
| 15,997 | 1,427 | 174 |

また、ファネルの時間的変化も見ることができます。
WITH timestamped_events AS
(SELECT properties_distinct_id,
min(CASE WHEN event = 'mp_page_view' THEN metadata_timestamp END) AS ts_landingpage,
min(CASE WHEN event = 'contact_form_opened' THEN metadata_timestamp END) AS ts_contactformopened,
min(CASE WHEN event = 'contact_form_sent' THEN metadata_timestamp END) AS ts_contactformsent
FROM events
GROUP BY properties_distinct_id )
SELECT date_trunc('week', ts_landingpage) AS week,
sum(CASE WHEN ts_landingpage IS NOT NULL THEN 1 ELSE 0 END) AS landingpage_count,
sum(CASE WHEN ts_contactformopened IS NOT NULL THEN 1 ELSE 0 END) AS contactformopened_count,
sum(CASE WHEN ts_contactformsent IS NOT NULL THEN 1 ELSE 0 END) AS contactformsent_count
FROM timestamped_events
GROUP BY week| 週 | ページ訪問者数 | コンタクトフォームを開いた人数 | コンタクトフォームを送信した人数 |
|---|---|---|---|
| 2015年6月15日 午前12時 | 171 | 4 | 0 |
| 2015年7月13日, 午前12時 | 244 | 24 | 3 |
| 2015年8月17日 午前12時 | 816 | 58 | 8 |

リテンション
最も有名で重要なグラフの1つがリテンションコホート分析です。これによって、私たちの製品に対するリピート率が分かります。どのくらいの頻度で製品を購入するのか、初めてサイトを訪れたユーザが再訪問したり、固定客になったりする割合も知ることができます。
リテンションコホートのチャートを見れば、製品が改良されているのか否かが見極められます。もし、今週製品を使い始めたユーザがチャーンとなった数が先月のチャーンの人数よりも少なければ、製品の改良がユーザエクスペリエンスに好影響を与えたと推測できます。
以下は、初めて製品を使った週ごとに顧客をグループ分けするクエリです。
WITH users AS
( SELECT properties_distinct_id AS user_id,
date_trunc('week', min(metadata_timestamp)) AS activated_at
FROM events
GROUP BY 1) ,
events AS
( SELECT properties_distinct_id AS user_id,
metadata_timestamp AS occurred_at
FROM events)
SELECT DATE_TRUNC('week',u.activated_at) AS signup_date,
TRUNC(EXTRACT('EPOCH'
FROM e.occurred_at - u.activated_At)/(3600*24*7)) AS user_period,
COUNT(DISTINCT e.user_id) AS retained_users
FROM users u
JOIN events e ON e.user_id = u.user_id
AND e.occurred_at >= u.activated_at
WHERE u.activated_at >= getdate() - INTERVAL '11 week'
GROUP BY 1,2
ORDER BY 1,2| 登録した日時 | 使用している期間 | リピート数 |
|---|---|---|
| 2015年9月7日 午前12時 | 0.00 | 808 |
| 2015年9月7日 午前12時 | 1.00 | 72 |
| 2015年9月7日 午前12時 | 2.00 | 51 |
| … | … | … |

セールスパイプライン
私たちのSalesforceインテグレーションを使って、見込み客が顧客にならなかった理由を分析します。Salesforceインテグレーションから‘オポチュニティ’テーブルをクエリすることができます。
SELECT
Loss_Reason,
Alternative,
count(1) count
FROM opportunities
WHERE closed = TRUE
AND won = FALSE
group by 1,2| 損失の理由 | 代替案 | カウント |
|---|---|---|
| 特長の欠落 | 社内で再考 | 4 |
| 価格 | 社内で再考 | 3 |
| … | … | … |

ここまで events テーブルのみを使ってきました。顧客分析によってデータをより高度に分析できましたが、みなさんの顧客分析の構築に最大の利点となる活用方法を紹介していません。それは、複数の異なるデータセットの結合です。
この例では、分析用のイベントデータをSalesforceから得た販売データと結合します。こういったクエリは、製品を隅から隅まで評価し、お金を支払うリピート客が、特定の広告に使われた特定のキーワードに対する特定のクリックからどのように導かれてきたのかを見ることができます。多くの分析ツールが販売員間のオフラインでの話に留まっているのに対し、私たちの統合システムでは、販売データを使うことができます。見込み客が現実の顧客になるのが、たとえ最初のWebサイト来訪から 数カ月 後のことだとしても。
例えば、セールスパイプラインにおいて、見込み客が私たちのWebサイトのどこでコンバージョンしたかをステータスの内訳で見ることができます。

ふう、長い記事になっていましましたね。お役に立てればうれしいです。これで全部です。これからも多く投稿して、みなさんのデータからより深い分析やインサイトを掘り下げていきます。引き続きご覧ください。もし私たちに書いてほしいアイデアなどがありましたら、気軽にご連絡ください。
顧客分析の構築のお手伝いが必要でしたら こちら までご連絡ください。顧客分析の事例もお待ちしています。
