2017年4月4日
#/usr/binとその同種の周辺を探る

(2017-02-19)by Alexander Blagoev
本記事は、原著者の許諾のもとに翻訳・掲載しております。
(注:2017/04/10、いただいたフィードバックを元に翻訳を修正いたしました。)
はじめに
私はLinuxが大好きです。コンピュータとのやりとりが楽しくなるし学ぶことも多くなります。OSとハードウェアの基盤となる基本原則を学びたい人にとって、Linuxはとてもいい出発点と言えるでしょう。
ご存じのとおりLinuxとは大抵の場合プログラム(コマンド)を通してやりとりします。Linuxと他のUNIX系システムが持っている特徴は、コマンドラインと、パイプのコンセプトです。プログラムの提供する入力と出力を統合すれば、データを操作するのに非常にパワフルなプラットフォームになります。
Linuxのコマンド、プログラム、バイナリ(何と呼んでもいいのですが)の大部分は、/usr/bin、/usr/sbin/、/binそして/usr/local/binに存在しています。これらのディレクトリを見れば、プログラムがたくさん見つかるでしょう。それでふと、これらのバイナリが日々の仕事にどう関わってくるのかと考えました。それで、宝探しをしてみることに決め、発見をこのブログに投稿してみることにしました。
手始めに、私のマシンの/usr/binにある簡単なカウント機能で、データを参照してみます。
ablagoev ➜ ~ ls -la /usr/bin | wc -l
2420これはもちろん日々私が使っているシステムで、ここで多くのものを保管しています。Centos 6.8(X Serverなし)の標準サーバに少しだけソフトウェアを追加して稼働しています。
[root@XXXXXX ~]# ls -la /usr/bin | wc -l
1054半分になりましたが、まだずいぶん数が多いですね。日常業務ではおそらく平均して20コマンドくらいしか使いません。以下はzsh環境でチェックする簡単な方法です。
fc -li -146 | awk '{print $4}' | sort | uniq -cこれで最新の146のコマンドが求められます。fcを使いタイムスタンプを参照し、今日の分だけのコマンドを抽出しました。
このデータを念頭に置いて、/usr/binやその周辺の内部を掘り下げ、隠された宝石がないかどうか調べてみることにしました。私はCentos 6.8の標準インストールをしているので、違うディストリビューションであれば違いがあるでしょう。
この投稿を書きながら各プログラムについて学びました。無知さ加減が目についたらご容赦ください。
目次
Misc
at
/bin/shを使用して、後で実行される標準入力または指定ファイルからコマンドを読み取る
いいですね。私はいつも単発のジョブを設定しようとしてcronの構文を間違ってしまいますが、こういったユースケースに対してはずっと簡単に使えそうです。例を挙げます。
root@XXXX:~# at 9:26 PM
warning: commands will be executed using /bin/sh
at> date > /tmp/test_at.log
at>^Ddate > /tmp/test_at.log は同日の9:26p.m.に実行されます。保留中のジョブも参照可能です。
root@XXXX:~# atq
1 Wed Feb 8 21:26:00 2017 a rootatはイカした日時の書式をいくつか理解しているようです。例えばお茶の時間( at teatime )も知っています。クールですね。
cal
ablagoev ➜ ~ cal
Февруари 2017
нд пн вт ср чт пт сб
1 2 3 4
5 6 7 8 9 10 11
12 13 14 15 16 17 18
19 20 21 22 23 24 25
26 27 28今日の日付を反転表示して、しゃれたカレンダーを表示してくれます。個人的にはすごく便利だと思います。
mkfifo
これも便利です。 mkfifo はシンプルなIPC(プロセス間通信)に使えます。この時生成される named pipe は、Linuxでは通常そうであるように、ファイルです。つまりこのファイルに書き込むプロセス(writer)とこのファイルから読み込むプロセス(reader)が装備されています。下記の2つのPythonのスクリプトを参考にしてみてください。
#!/usr/bin/python
# reader.py
i = 0
while True:
fp = open('fifo', 'r')
line = fp.readline()
print "Item in fifo: " + line.rstrip() + " on iteration " + str(i) + "\n"
fp.close
i += 1
#!/usr/bin/python
# writer.py
import time
i = 0
while True:
fp = open('fifo', 'a')
fp.write("Hello " + str(i) + "!\n")
fp.close()
i += 1
time.sleep(1)スクリプトを利用する前にFIFOを生成します。
mkfifo fifowriterを起動します。
./writer.pyreaderも起動します。
./reader.pyreaderがFIFOの内容を出力する出力レートに注目してください。writerと同期しています。FIFOが通常のファイルだとしたら、readerは新しいアイテムがあろうがなかろうが、常に読み込むはずです。FIFOに対する読み込みと書き込みはブロッキングオペレーションだからです。FIFOを通常のファイルに変更して違いを確認してみてください。
他に WikipediaのNetcatの項 にもすばらしい例があります。
mkfifo backpipe
nc -l 12345 0<backpipe | nc www.google.com 80 1>backpipeこれはプロキシの例で、ポート12345のリクエストをすべてポート80のwww.google.comに転送します。パイプが単方向性なので、FIFOが必要となります。
resolveip
通常、ホストのIPアドレスを取得するのにはpingを使いますが、 resolveip の方が簡単です。
ablagoev ➜ ~ resolveip en.wikipedia.org
IP address of en.wikipedia.org is 91.198.174.192私と同類の人なら、しょっちゅうIPをコピーする必要にかられ、IPだけを返す-sオプションを使っているはずです。
resolveip -s en.wikipedia.org | xsel -b.bash_aliasesというファイルに保存するだけで、簡単に関数にできます。
# Copy an ip address from a domain
# Usage cip domain.com
function cip() {
ip=$(resolveip -s $1)
echo $ip | xsel -b
echo $ip
}
ablagoev ➜ ~ cip en.wikipedia.org
91.198.174.192timeout
時間制限をかけてコマンドを実行する
コードを編集したくない時に便利です。例を挙げます。
timeout 10 ./programプログラムは10秒間実行され、そのあとTERMシグナルが送られます。シグナルや、時間の単位(例えば分、時間、日)は変更できます。
w
誰がログインしていて何をしているのか表示する
マルチユーザのシステムでは便利です。
root ➜ /home/ablagoev w ablagoev
12:20:44 up 1 day, 56 min, 5 users, load average: 0,06, 0,13, 0,21
USER TTY FROM LOGIN@ IDLE JCPU PCPU WHAT
ablagoev :0 :0 сб11 ?xdm? 1:18m 0.59s upstart --user
ablagoev pts/4 :0 сб11 24:51m 46.01s 45.70s /home/ablagoev/.rbenv/versions/2.3.1/bin/jekyll serve
ablagoev pts/7 :0 сб23 4.00s 2.42s 4:04 gnome-terminal
ablagoev pts/25 :0 сб11 12.00s 3:10 3:10 vim _posts/2017-02-10-adventures-in-usr-bin.markdown
ablagoev pts/33 :0 сб12 1:35m 2.28s 4:04 gnome-terminalwatch
watch はプログラムを定期的に実行したり出力を監視したりするのに便利なツールです。シンプルな時計は以下のようになります。
watch -n 1 -d date-nオプションはwatchにプログラムを毎秒実行するように命令します。-dオプションは出力の差異を強調するようwatchに指示します。
OS
blktrace
この項目についてはブログの投稿をすべて費やしてもいいほどですが、私は正直詳細まで記述できるほど準備ができていません。理解している範囲では、システムのI/Oをiostatよりも低レイヤーで監視することができ、I/O関連のメトリクスを多く測定することができるというものです。この件に関しては これ が優れた投稿だと思います。
これは新しいカーネルにのみ実装されています。古いものにはパッチを当てなくてはなりません。
chrt
システムに「niceness」を設定できることについてはご存じですよね。知らなかったのですが、CPUのスケジューリングポリシーも変更できます。現在、最新のカーネルは以下のポリシーをサポートしています。
- SCHED_OTHERは標準的なラウンドロビンのタイムシェアリングポリシー
- SCHED_BATCHはプロセスの「バッチ」処理の実行に
- SCHED_FIFOは先入れ先出しポリシー(リアルタイムプロセスにのみ適応)
- SCHED_RRはラウンドロビンポリシー(リアルタイムプロセスにのみ適応)
また、プロセスにはリアルタイムと標準の2種類があります。リアルタイムプロセスの方が優先度が高く、時間的な制約のあるアプリケーションに適用されます。
プロセスのポリシーを変更することで、Linuxがプロセスをスケジュールする方法を変更できます。
ユーザプロセスは通常リアルタイムではなく、デフォルトがSCHEDOTHERポリシーになっています。カーネルプロセスを調べてみたところ、SCHEDFIFOのものもありましたが、(少なくとも私のマシンには)SCHED_RRを持っているものはありませんでした。
chrt を使えばプロセスのスケジューリングポリシーの変更やクエリが可能です。例えば、initをチェックするには以下のようになります。
結果としてプロセスポリシーを以下のように変更することができます。
ablagoev ➜ ~ chrt -b -p 0 PID
ablagoev ➜ ~ chrt -p PID
pid 970's current scheduling policy: SCHED_BATCH
pid 970's current scheduling priority: 0しかし、実用的なユースケースや本番環境のポリシーに干渉する意味も見つけることができません。 こちらの投稿 ではいくつかの評価基準が掘り下げられています。ぜひ、このポリシーに関する皆様の経験や知識を共有していただけると嬉しいです。
詳細は以下をお読みください。
man sched_setschedulerlstopo
これはかなりイケてます。マシン(のトポロジー)のハードウェアレイアウトの表示のために使用することができます。数多くの異なる出力フォーマットだけでなくASCIIアートにも対応しているところが最高です。以下に例を挙げています。
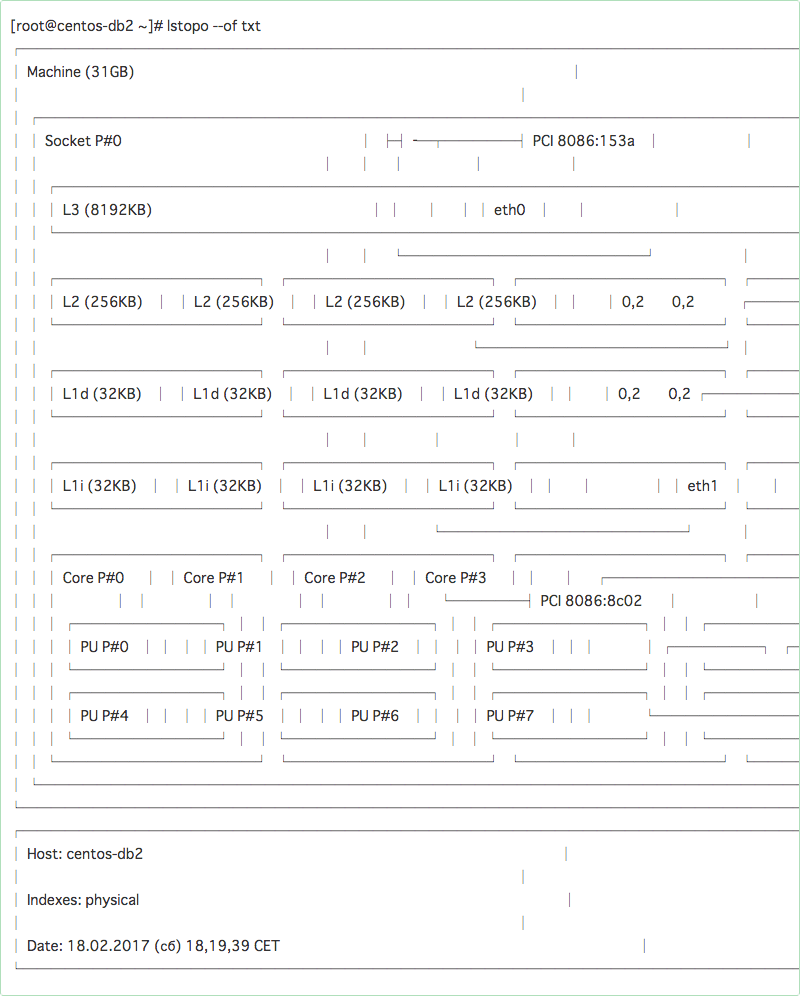
Istopoコマンドは hwloc パッケージで提供されます。
numactlおよびtaskset
これらのコマンドだけの投稿ができるほど話題につきません。私の知る限り、両コマンドはプロセスやスレッドのCPUアフィニティを制御するために使用されます。例えば、異なプロセスやスレッドを異なるコアやソケットに指定することが可能になります。さらに、プロセスやスレッドが使用するべきメモリノード(NUMA環境下でのバッファプール)を管理します。実際、Linuxスケジューラが最適ジョブを実行せず、スレッドや同様のプロセスをコア中に渡してしまう時に使用されています。始める前にまず、NUMAのアーキテクチャをおさらいしましょう。
[root@chat ~]# numactl -H
available: 2 nodes (0-1)
node 0 cpus: 0 1 2 3 8 9 10 11
node 0 size: 24566 MB
node 0 free: 23075 MB
node 1 cpus: 4 5 6 7 12 13 14 15
node 1 size: 24576 MB
node 1 free: 23309 MB
node distances:
node 0 1
0: 10 21
1: 21 10上は2つのCPUソケットと計16コアを持つ48ギガビットのサーバです。メモリは2つのノードに分かれています。
numactlの簡単な例は以下のとおりです。
numactl --cpunodebind=0 ./programこれで1つ目のCPUソケット(0)上の program を実行します。
プロセスのアフィニティを起動時に変更したい場合は、 taskset で実行できます。tasksetはソケットではなくコアで機能しますので、単体のソケットにプロセスを指定したい場合は、全てのコアを一覧にする必要があります。
taskset -p -c 0 pid-c 0を使用することで、PIDをコア#0に指定します。 cat /proc/cpuinfo を使用すればコアを見ることができます。
さらに、プロセスの現在のCPUコアを見たい場合は、psのpsr列を見てください。
ablagoev ➜ ~ ps -o pid,psr,comm -p 1
PID PSR COMMAND
1 1 initつまり、この場合、initプロセスがコア#1になっていることが分かります。
numastat
プロセスやOSのノードメモリ統計をNUMA単位で表示する
[root@chat ~]# numastat
node0 node1
numa_hit 502845176 522381709
numa_miss 0 0
numa_foreign 0 0
interleave_hit 22624 22649
local_node 502838421 522343368
other_node 6755 38341たくさんのミス(プロセスの好むノードではないノードにメモリが割り当てられること)があるのは、システム上のどこかでアフィニティが最適ではないからと考えるのが論理的だと思います。
peekfd
このコマンドは既定のプロセスのI/Oを監視するために使うことができます。先に進める前にpeekfdのLinux Manページから以下の引用をご紹介します。
バグ 恐らく多く存在するでしょう。監視しているプロセスが異常終了しても驚かないように。
本番環境で使用する際は注意が必要です。どなたか安定性についてご存じの方は教えてください。いずれにせよ、保存時にvimの動作を監視します。
root ➜ /home/ablagoev peekfd 20921
writing fd 1:
[1b] [?5h [1b] [?5l [1b] [?25l [1b] [m [1b] [57;1H [1b] [K [1b] [57;1H:w [1b] [?12l [1b] [?25h
[1b] [?25l"t"
writing fd 5:
Example IO
writing fd 1:
[noeol] 1L, 10C written [1b] [1;14H [1b] [?12l [1b] [?25h
writing fd 7:
b0VIM 7.4 [10] 2 [a9] X [8a] [14] [16] [b9] Qablagoevablagoev-VPCF22M1E~ablagoev/t [09] 3210#"! [13] [12] Uファイルに何が書き込まれるか見えるのがすごいです。もちろんstraceを使ったり出力のフィルタリングを行ったりしても同じことができます。
pidstat
このコマンドは、既定のプロセスやシステム全体のあらゆる統計を監視するために使うことができます。top/htopに似ていますが、更に詳しい情報を提供してくれます。例えば以下のような情報です。
[root@chat ~]# pidstat -p 19562 1
Linux 3.10.104-1.el6.elrepo.x86_64 (ldp3chat) 19.02.2017 _x86_64_ (16 CPU)
10,22,03 PID %usr %system %guest %CPU CPU Command
10,22,04 19562 11,00 3,00 0,00 14,00 15 node
10,22,05 19562 10,00 1,00 0,00 11,00 10 node
10,22,06 19562 11,00 3,00 0,00 14,00 11 node
10,22,07 19562 16,00 2,00 0,00 18,00 10 node
10,22,08 19562 23,00 2,00 0,00 25,00 11 node
10,22,09 19562 16,00 1,00 0,00 17,00 14 node
10,22,10 19562 14,00 2,00 0,00 16,00 13 node最後の「1」は統計のポーリングを毎秒実行するようpidstatに指示します。-dオプションを使ってI/O統計を見ることができます。
[root@chat ~]# pidstat -d -p 19562 1
Linux 3.10.104-1.el6.elrepo.x86_64 (chat) 19.02.2017 _x86_64_ (16 CPU)
10,23,38 PID kB_rd/s kB_wr/s kB_ccwr/s Command
10,23,39 19562 0,00 0,00 0,00 node
10,23,40 19562 0,00 0,00 0,00 node
10,23,41 19562 0,00 0,00 0,00 node
10,23,42 19562 0,00 0,00 0,00 node
10,23,43 19562 0,00 0,00 0,00 nodeメモリは以下のとおりです。
[root@chat ~]# pidstat -r -p 19562 1
Linux 3.10.104-1.el6.elrepo.x86_64 (chat) 19.02.2017 _x86_64_ (16 CPU)
10,24,16 PID minflt/s majflt/s VSZ RSS %MEM Command
10,24,17 19562 2,00 0,00 1576132 524288 1,06 node
10,24,18 19562 36,00 0,00 1574416 522588 1,05 node
10,24,19 19562 47,00 0,00 1574416 522588 1,05 node
10,24,20 19562 70,00 0,00 1575440 522840 1,05 node
10,24,21 19562 186,00 0,00 1575440 523632 1,06 node
10,24,22 19562 30,00 0,00 1575440 523632 1,06 nodeタスク(コンテクスト)の切り替えは以下のとおりです。
[root@chat ~]# pidstat -w -p 19562 1
Linux 3.10.104-1.el6.elrepo.x86_64 (chat) 19.02.2017 _x86_64_ (16 CPU)
10,25,48 PID cswch/s nvcswch/s Command
10,25,49 19562 481,00 97,00 node
10,25,50 19562 359,00 64,00 node
10,25,51 19562 401,00 71,00 node
10,25,52 19562 383,00 63,00 nodepwdx
このコマンドは、プロセスによって操作中のディレクトリを簡単に取得できる使い勝手のいいツールです。
ablagoev ➜ ~ pwdx 6038
6038: /home/ablagoev/workspace/ablagoev.github.iodebugging
addr2line
このコマンドは使い方が少し難しいのですが、使うだけの価値はあります。低レイヤーのプログラミングをしている人は日常的に異なる場合において使っています。私はsegfaultのデバッグに便利だと思って使っています。
Segfaultは以下のような形式になっています。
php-fpm[6048]: segfault at 10 ip 00007f46db77a8fb sp 00007fffa155e2d0 error 4 in xcache.so[7f46db763000+23000]上の場合segfaultは共有ライブラリ(xcache.so)に出ています。ライブラリオフセット(xcache.so[7f46db763000+23000])を命令ポインタ(ip part)から減算してaddr2lineの正しいアドレスを算出する必要があります。
00007f46db77a8fb - 7f46db763000 = 178FBアドレスが分かったら、共有のオブジェクトの位置情報と一緒にaddr2lineに与えます。
addr2line -e /usr/lib64/20131226/xcache.so 178FBこのマシンの場合の出力は以下のとおりになります。
/root/source/xcache-3.2.0/mod_cacher/xc_cacher.c:778これはsegfaultを生成するC言語ソースコードの違反行です。最高です。
前述のとおり、このコマンドも単独の記事が書けるほど奥が深いのです。例えば、機能させるには、デバッグシンボルの設定をONにしてバイナリをコンパイルする必要があります。さらに、アドレス計算の裏には面白い理論が存在します(私の読むべきものリストに含まれています)。また、他にもさらに踏み込んだデバッグ(gdb)をしてくれるツールがあります。
gstack
実行中のプロセスのスタックトレースを出力する
繰り返しになりますが、すごいです。暴走プロセスのスタックトレースを見ることができるということは、問題解明に絶対役立ちます。使い方はいたって簡単です。
gstack pidこのコマンドはgdbのラッパです。そのため、ディストリビューションにない場合は、gdbで同じような効果が期待できます。
データ操作
column
このコマンドは素晴らしいのに今まで知りませんでした。列の書式入力に使うことができます。個人的に一番使い勝手がいいと思うのがCSVファイル形式です。とりわけすごいのは異なる列の区切り文字を指定することができることです。
id;event;count
1;test;10
2;test2;20
3;test3;30コマンドを実行します。
ablagoev ➜ ~ column -s ";" -t test
id event count
1 test 10
2 test2 20
3 test3 30次のコマンドと組み合わせて使うとさらに面白くなります。
colrm
このコマンドは入力から列を削除する場合に使えます。個人的にはawkを使い慣れていますが、単純なユースケースにおいては、colrmの方が使いやすいようです。前のコマンドで得た結果を元に、このコマンドを実行して最初の列を削除することができます。
ablagoev ➜ ~ column -s ";" -t test | colrm 1 4
event count
test 10
test2 20
test3 30comm
分類済みの2つのファイルを行単位で比較する
comm を使えば2つのファイルを比較して、片方のファイルにしか存在しない項目(行)の有無や両方のファイルに存在する行を確認することができます。例えば、以下のような2つファイルがあるとします。
ex1
Common line
In both files
Only in 1st fileex2
Common line
In both files
Only in 2nd filecomm を両方のファイルで実行することで、以下のような結果を得ることができます。
ablagoev ➜ ~ comm ex1 ex2
Common line
In both files
Only in 1st file
Only in 2nd file列ごとに出力は分けられ、最初の列は最初のファイルのみに存在し、2つ目の列は2つ目のファイルのみに存在し、3つ目の列は両方のファイルに存在するといったように結果を表示します。ここでの注意点は、ファイルがアルファベット順に分類されている必要があるということです。そして、表示したい列を制御するオプションもあります。
csplit
このコマンドはsplit(ご存じない方は要チェックです)に似ていますが、csplitは大きいファイルを複数の小さいファイルに分割してくれます。splitとは異なり、 csplit は正規表現で使うことができ、分割したファイルはそれぞれ異なる大きさにすることができます。以下の例を見てください(テキストファイル)。
Item: Shoes
Price: 9.99
Quantity: 10
----
Item: Dresses
Price: 19.99
Quantity: 15
----
Item: Socks
Price: 1.99
Quantity: 30以下のコマンドを実行します。
csplit --suppress-matched data.txt '/^----$/' {*}結果、アイテムブロックのみを含む3つのファイルが表示されます。 --suppress-matched オプションはcsplitに共通の行は出力結果に表示しないよう指示します。 {*} はcsplitにパターンマッチングを可能な限り実行するよう指示します。残念ながら、csplitは行単位で実行します。例えば、正規表現の複数行モードでは使えません。
cut
Cutはよく使われていますが、私はこれまで使ったことがありません。見た限りでは、とてもパワフルなツールのようです。colrm同様にcutコマンドはファイルの部分的(列)抽出を可能にしてくれますcolrmとは異なり、開始・終了オフセットの設定だけでなく、区切り文字を指定することもできます。これが、CSVファイルの強力な解析の実行を可能にしてくれます。例えば、以下のデータ(テキストファイル)があります。
id;name;count
1;Shoes;10
2;Dresses;15
3;Socks;30上でcutを実行すると以下のようになります。
ablagoev ➜ ~ cut -d';' -f1 data.txt
id
1
2
3-dオプションで区切り文字を指定します(ここでは、「;」になります)。-fオプションで出力したい列の指定をします。列1と列3を出力したい場合は、以下のようになります。
ablagoev ➜ ~ cut -d';' -f1,3 data.txt
id;count
1;10
2;15
3;30この他にもコマンドに柔軟性を持たせるオプションはあります。ここであえて挙げるとしたら、出力する区切り文字を制御するオプションでしょう。例えば以下のとおりです。
ablagoev ➜ ~ cut -d';' -f1,3 --output-delimiter $'\t' data.txt
id count
1 10
2 15
3 30–output-delimter $’\t’はタブ文字を使うようcutに指示します。
join
これも人気のあるコマンドです。詳しくは知りませんが、何とか説明してみましょう。2つのファイルのデータを、共通フィールド単位で結合します。例えば以下の2つのファイルがあります。
ex1
Date Count
2017-02-02 10
2017-02-03 10
2017-02-04 10ex2
Date Sum
2017-02-02 50
2017-02-03 60
2017-02-04 70joinを実行すると結果は以下のようになります。
ablagoev ➜ ~ join ex1 ex2
Date Count Sum
2017-02-02 10 50
2017-02-03 10 60
2017-02-04 10 70最初の列に基づいてファイルを結合することができました。このコマンドは両方のファイルでどの列を使うか、区切り文字に何を指定する(デフォルト設定は空白)かなどを柔軟に選ばせてくれます。
paste
Pasteは複数のファイルを連結したい場合に使用できます。最も簡単なケースとしては、ファイルの中の全ての行を連結したい場合に使えます。以下のファイル(データ)を例に見てみましょう。
1
2
3
4
5
6
7
8
9
10コマンドを実行します。
ablagoev ➜ ~ paste -s -d ',' data
1,2,3,4,5,6,7,8,9,10-d オプションによって区切り文字が指定され、-sオプションによってファイルの行を連結されます。ここで-sオプションの表現方法と単一ファイルでは機能しない理由が理解できていません。
-sは各ファイルからの行単位の集約ではなく、ファイル単位の集約する
恐らく-sを実行しなければ、行単位で処理が実行されるのでしょう。
ファイル結合の別の例を見てみましょう。以下のファイル(ex1とex2)があります。
Name
Shoes
Skirs
Socks
DressesQuantity
10
20
30
40ablagoev ➜ ~ paste ex1 ex2
Name Quantity
Shoes 10
Skirs 20
Socks 30
Dresses 40もちろん最初に挙げた例のように区切り文字を指定することもできます。
replace
このコマンドをさえ知っていれば、簡単な検索や置換を実行するためにsedコマンドの構文を暗記する必要がなかったのにと思います。このコマンドはファイルの文字列の置き換えに使えます。以下のファイル(データ)を例として見てみましょう。
variable = 10
operation = variable + 12
print variablereplace を実行して「variable」を「x」に置き換えます。
ablagoev ➜ ~ replace variable x -- data
data converted
ablagoev ➜ ~ cat data
x = 10
operation = x + 12
print x速くて簡単です。複数の検索や置換を同時に実行することも複数のファイルで実行することもできます。
look
このコマンドは貴重です。ファイルの各行のうち、指定された文字列で始まっている行を表示します。基本的にはgrep “^PREFIX”と同じことをしてくれますが、正規構文なしで実行してくれます。以下のファイル(データ)で見てみましょう。
pref: 123
some other thing
pref: 234
another thing
pref: 222ablagoev ➜ ~ look pref data
pref: 123
pref: 234
pref: 222Manページで look をスペルチェックに使用する面白いユースケースが紹介されています。恐らく/usr/share/dict/wordsに英語辞典があり、 look コマンドでスペルチェックするようデフォルト設定されているのでしょう。以下のようになります。
ablagoev ➜ ~ look defini
defining
definite
definitely
definiteness
definiteness's
definition
definition's
definitions
definitive
definitivelynl
とても便利なちょっとしたツールです。ファイルに行番号を追加してくれます。以下のファイル(データ)があります。
This is the first line.
This is the second line.
This is the third line.上のファイルで nl を実行します。
ablagoev ➜ ~ nl data
1 This is the first line.
2 This is the second line.
3 This is the third line.tac
Catのようなコマンドですが、ファイルを逆順に出力してくれます。
ablagoev ➜ ~ cat data
1
2
3
4
5
6ablagoev ➜ ~ tac data
6
5
4
3
2
1expand
これは簡単なコマンドですが便利です。タブをスペースに変換してくれます。
unexpand
上のコマンドとは反対のことをします。スペースをタブに変換してくれます。
おわりに
以上で終わりです。この投稿を書きながら多くのことを学ぶことができ、さらにLinux愛が深まりました。システムの透明性や詳細を提供してくれていることに感嘆します。他にもすごいコマンドを知っている方はぜひ下のコメント欄で共有してください。ここで挙げたコマンドの多くは初めて見るものもあったので、誤りがあるかもしれません。もしあるようでしたらぜひご指摘ください。
