2016年1月28日
AWSで避けるべき5つの間違い
(2015/12/26)by Michael Wittig
本記事は、原著者の許諾のもとに翻訳・掲載しております。
今年からAWS(Amazon Web Services)クラウドコンサルタントとして、中小規模のAWSデプロイの相談を受けています。その多くは典型的なWebアプリケーションです。ここで、ぜひ避けたい5つのよくある間違いを紹介します。
- インフラストラクチャを手動で管理する。
- Auto Scaling グループを使わない。
- CloudWatchのメトリクスを分析しない。
- Trusted Advisorを無視する。
- 仮想マシンを活用しない。
典型的なWebアプリケーションにおける間違いを防ぎたい人は、次に進んでください。
典型的なWebアプリケーション
典型的なWebアプリケーションは最低限次の要素で構成されているものを指します。
- ロードバランサ
- スケーラブルなWebバックエンド
- データベース
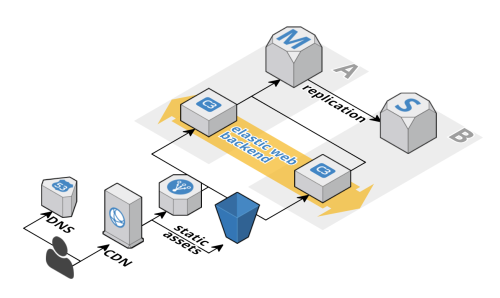
そしてこのアプリケーションは、次の図のような仕組みを持っています。
注釈:(左から)DNS、CDN、静的アセット、エラスティックなWebバックエンド、レプリケーション
この型は非常に一般的で、これ以外の形式で作るならよほど強力な理由が必要です。
間違い1:インフラストラクチャを手動で管理する
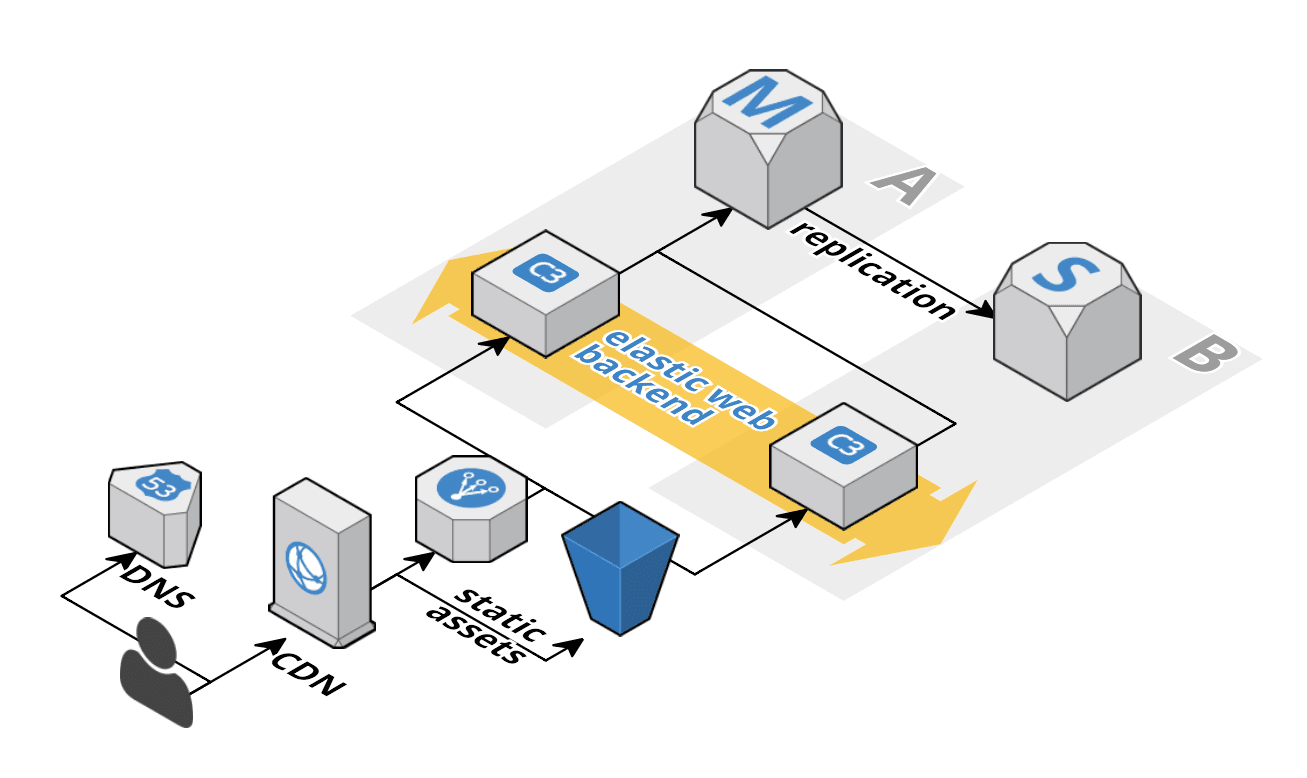
Webベースの管理コンソールをあちこちクリックしてAWSをセットアップしたなら、インフラストラクチャを手動で管理しているということになります。このアプローチの大きな問題点は、再現性がなく、ドキュメント化もされないので、大量の間違いを犯す可能性があることです。幸い、 AWS CloudFormation がその問題を無償で解決してくれます。すべてのリソース(EC2インスタンス、セキュリティグループ、サブネットなど)を手動で作成する代わりに、それらをテンプレートに記述しましょう。CloudFormationがそのテンプレートを有効なスタックに変換します。CloudFormationは次の図のように、すべてのリソースを正しく作成してくれるのです。
テンプレートを更新することによって実行中のスタックに変更を適用することさえ可能です。典型的なWebアプリケーションは、 ここ で紹介されているように、CloudFormationテンプレートに簡単に記述することができます。
私たちのブログにCloudFormationサンプルを多数掲載 していますし、私はAWSとCloudFormationに関する テキスト も執筆しています。インフラストラクチャを手動で管理しなければならない理由はありません。それはプロらしくない上に、大混乱を招くでしょう。
間違い2:Auto Scaling グループを使わない
Auto Scaling グループに関する最大の問題は、自動スケーリングと勘違いされる傾向にあることです! すべてのEC2インスタンスは、Auto Scaling グループ内で実行されるべきです。たとえEC2インスタンスが1つだったとしても同じです。Auto Scaling グループは、EC2インスタンスをモニタリングし、仮想マシンの論理グループとして機能するもので、しかも無償なのです。
典型的なWebアプリケーションにおいては、Webサーバは、Auto Scaling グループの仮想マシン上で動きます。もちろん、Auto Scaling グループを使って、現在の作業負荷に基づいた仮想マシン数をスケールすることも可能ですが、前提条件としてAuto Scaling グループが必要です。自動スケーリングは、(論理グループの)CPU使用率やロードバランサが受け取るリクエスト数のようなメトリクスにアラームを設定することによって実現されます。アラームのしきい値に達した場合、Auto Scaling グループのマシン数を増やすというようなアクションを定義できます。
間違い3:CloudWatchのメトリクスを分析しない
AWSのすべてのサービスは、 CloudWatch というサービスへ興味深いメトリクスを提供しています。仮想マシンは、CPU使用率、ネットワーク使用率、ディスク動作について報告します。データベースも、メモリ使用率とIOPS使用量を報告します。それらのデータを分析すれば良いのです。1日のCPU使用率を表した次のグラフをご覧ください。
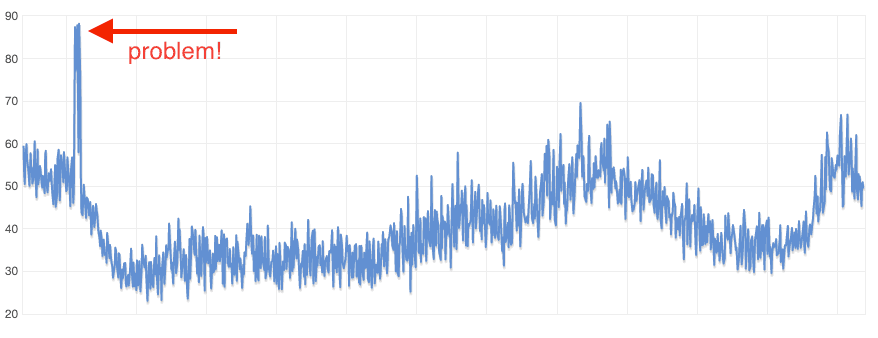
使用率が極端に高い箇所がわかりますか? これは毎日見られました。いつも同じ時間です。どうやらcronjobが怪しいと思ったら、やはりそうでした。しかし、このマシンは、Webサーバとして稼働中でしたので、毎日cronjobのせいでレイテンシが増えていたのです。このcronjobを別の仮想マシンで実行することによって問題を解決しましょう。すべてCloudWatch内で対応可能ですが、自分で調査する必要があります!
メトリクスを分析した後に、第二段階としてアラームを定義します。その逆ではないのです!
間違い4: Trusted Advisorを無視する
AWS Trusted Advisor をご存知でしょうか?これは、AWSが定義したベストプラクティスに対して、AWS アカウントをチェックするツールです。特に以下の項目に重点が置かれています。
- コスト最適化
- パフォーマンス
- セキュリティ
- 耐障害性
もし、Trusted Advisorのダッシュボードが下の図の様になっていたら、AWSの環境を改善するいいタイミングだと思ってください。
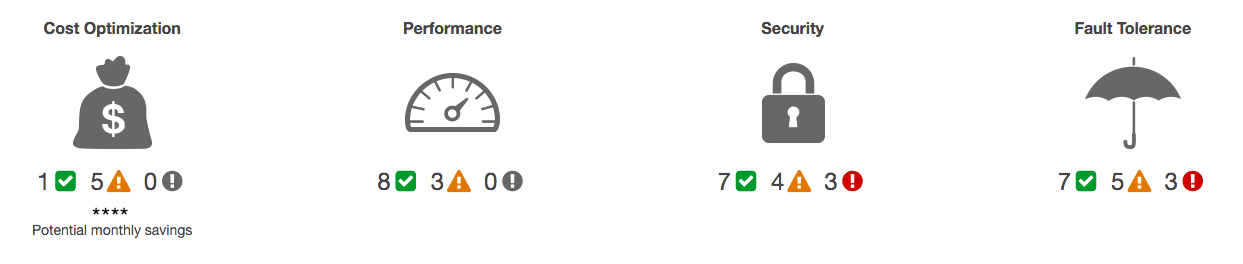
*注釈:
cost optimization:コスト最適化
performance:パフォーマンス
security:セキュリティ
fault tolerance:耐障害性
*
私は、最初にセキュリティ対策をすることをお勧めします。週に一度、Trusted Advisorからメールを送信し、前週からの変更点(解決したことや新しい問題点)を通知させることができます。設定画面でこれをアクティブにしてください。AWSサポートを有料版にグレードアップすると、Trusted Advisorのチェック項目が増え、更に強力になります。
間違い5:仮想マシンを活用しない
Amazon EC2のインスタンスが活用されていないと分かったら、インフラストラクチャを手動で管理していない限り、インスタンスサイズを小さくする(マシンの数を減らす、または c3.xlarge を c3.large にする)ほうがいいに決まっています。では、Amazon EC2のインスタンスを活用しているかどうかは、どうしたら分かるのでしょうか。Amazon CloudWatchのメトリクスを確認してください。とても簡単ですね。Auto Scaling グループを利用している場合は、後でスケールアップしたり、早めにスケールダウンしたりするために、自動スケーリングの設定とCloudWatchのメトリクスも確認してください。
まとめ
AWSクラウドコンサルタントとして、数多くのAWS アカウントを見てきました。そしてベストプラクティスを提供するために、それぞれのアカウントで見られる間違いを集めて、集計しました。これによって分かった、AWSにおける最も一般的な5つの間違いは以下の通りです。
- インフラストラクチャを手動で管理する。
- Auto Scaling グループを使わない。
- CloudWatchのメトリクスを分析しない。
- Trusted Advisorを無視する。
- 仮想マシンを活用しない。
さあ、次は皆さんのインフラストラクチャをチェックしてみましょう。
それでは、良いクリスマスをお過ごしください。
