2015年3月30日
redditにおける関心事
(2014-12-24)by Mark Allen Thornton
本記事は、原著者の許諾のもとに翻訳・掲載しております。
(注記:4/16、いただいた翻訳フィードバックを元に記事を修正いたしました。)
(訳注:文中のすべてのグラフ画像は 原文のページ で拡大・縮小しながらご覧いただけます)
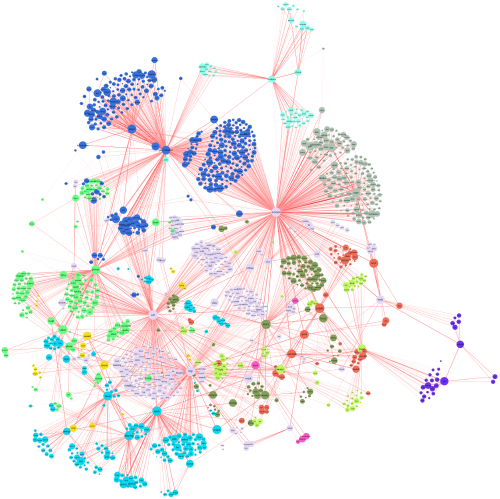
20万ユーザの8400万コメントをネットワーク図で解析
誰しも関心事があります。つまり理解したいと思ったり話し合ったりしたいと思うような個々人の好みに近いトピックのことですね。でも、例えば初めてデートした時のぎこちなさが証明するように、人によって興味の対象は違うもので、すれ違うことだってままあります。ある人にとっては面白い内容でも、他の人にとっては涙が出るくらい退屈だったりすることもあるのです。そんなわけで、この投稿では人々の関心事やその相互の関連性について、もう少しつっこんで考えてみたいなと思っています。
特定の関心事の間には自明で自然な関連性があるという認識は、恐らく多くの人が持っているのではないでしょうか。関心事の分類をどれだけ細かくするかにもよりますが、一部の関連性については、ほぼ自明の場合だってあります。例えば1932年のペニー硬貨を集めるのが趣味な人は、まず間違いなく1933年のペニー硬貨のことも気に掛けるでしょう。その一方で、一見関係が薄そうな関連性の中からも、社会や人間性の意外な側面を明かすことができるかもしれないという心引かれる見込みがないわけではありません。
この見込みを実現へと加速させるため、私は reddit を当たってみました。ご存じない方のために説明しますと、redditは非常に人気の高い情報収集・ディスカッションサイトのことで、この投稿を書いている時点で、300万人以上の登録者数と月間1億7000万のユニーク訪問者数(重複を除く訪問者数)を誇っています。AMA(「Ask Me Anything(何でも質問して)」)として知られるインタビューフォーマットはとりわけ人気が高く、 オバマ大統領 以下、多くの有名人がそのページに名前を連ねるほどです。

redditには大きく分けて3つの基本構成要素があります。リンク、コメント、そしてsubredditです。ユーザ(redditor)は、例えば ニュース や 科学系 の記事、 戦略ゲーム の実況や IT界の逸話 紹介などのサイトを、リンクの形で投稿します。それに対して他のユーザがやることは2つです。そのリンクに投票(upvoteまたはdownvote)すること。これで経過時間なども含め、そのリンクがどれだけ認知度が高いかが決定されます。そしてもう1つはコメントすることです。コメント自体はくだらないものから有意義なものまで様々ですが、redditではコメントに投票する機能もあるため、最悪な(もしくは評判の悪い)コメントは通常隠されます。また、コメントにコメントすることも可能です。それによって、多くのオンラインフォーラムで採用されている完全に順次追加的なフォーマットとは大きく異なるredditの特徴的なディスカッションツリーが形成されます。最後に、これらのリンクやそれに付随するコメントは、投稿者が最初に投稿した場所に応じて、subredditとしてトピックごとにまとめられます。redditでは、膨大な数のsubredditが広い範囲にわたるトピックをカバーしていますが、初期状態ではわずかしか表示されません。
方法
2013年の秋、私は PRAW を使用して20万人以上のredditorを1セットにしたものの中から8400万前後のコメントを取得しました。当時私が興味を持っていたのが、各subredditにはそれぞれに規範となるような書式スタイルがあるかということと、そのスタイルを学んだユーザをひな形化できるかということです(ちなみにその答えは前者がイエスで後者がノーでした)。(それぞれのトピックに関して)最小限のバイアスでデータを取り出すため、私はPRAWのrandom subreddit function(ランダムsubreddit機能)を使い、ランダム性を擬似的に再現しつつsubredditを取得し、続いて最新の1000リンクを介して全コメント投稿者のユーザネームも収集。その後、redditorのリストができてから、(1000項目を上限として)全体のコメント履歴を取得しました。
コメントに関するメタデータ(例えばupvoteの数)を含めた全てのテキストの合計はCSV形式で23GBにまで膨れ上がりました。ここで最初にやったのが、膨大な数に上る内容のないストップワード(例:助詞や助動詞などの機能語)や記号、それに数字などをテキスト処理に掛け削除することです。次にデータセット内の少量(0.1%)のサブサンプルで、残った単語の使用頻度をカウントしました。その後、8400万コメントセットの中で現れた頻度が50回以下のもの、または1000回以上のものを削除。加えて、固有名詞、名詞と動詞以外の一般的な単語、リスト内に存在する単語の変化形(過去形や複数形)も(ごく簡単に)削除しました。ここまでで残ったのが1862の「鍵となる単語(キーワード)」です。最終的に、そのキーワードの使用頻度を(ユーザごとにまとめた)8400万のコメントセットの中でカウントしてみました。
各種前処理に続けて行ったこの処理で、それぞれのキーワードが19万8542人のredditorにおいてカウントされました。なお、一応お伝えしておきますが、これらのユーザは、一般的な(米国の)人々やredditの利用者の代表ではありません。redditがアメリカを代表しているわけではないですし、この選定処理の都合上、コメント数が多いユーザによりバイアスが生じてしまうのは避けられないからですね。それでもサンプルの規模の大きさを考えると、仮に結果が広範囲の人々に対して完全には一般化され得ないとしても、大多数の人の意見を表しているということについてはおおむね確信が持てると思っています。
前処理の最終ステップとして、(各redditorの)キーワードの利用頻度間におけるコサイン類似度行列を計算しました。そして、他の単語(ごく一般的に使われる単語)に対して、バリアンスが非常に低い単語は削除。また中央値の類似度が非常に低い/高い単語も同様に削除します(未分化/多義語や異常値)。その後、残った1444のキーワードセットの間で、隣接行列を計算しました。後続のソーシャルネットワーク図の視覚化の解釈可能性を最大化するため、ネットワーク図内では隣接行列におけるその列の二大要素に基づいて、各ノード(キーワード)に、他のノードに接続するためのエッジ(連結点)を少なくとも2つ与えています。
ネットワーク図は、 R の igraph パッケージを使って視覚化しました。エッジ(ライン)の幅と色は、それぞれの単語の同時生起の対数(底10)に応じて異なり([太い]連結ラインでつながれている単語ほど、同じredditorからより頻繁に使われている)、ノードの大きさは、単語の絶対使用頻度の対数(底10)に応じて異なっています(例えば他の単語に比べ1000倍の頻度で出てくる単語のノード半径は3倍です)。ノードの配色は5段階のwalktrapのコミュニティ検出アルゴリズム(実用的にはクラスタリングアルゴリズムに似ていますが、ソーシャルネットワーク図用のもの)によるものです。なお、色については任意に選択しているため、色をベースに異なるコミュニティとの類似性を解釈することはできません。ノードの位置は、力学モデルによるグラフ描画であるFruchterman-Reingoldアルゴリズムを使って設定しました。このアルゴリズムでは、類似した用語は近い場所にまとめて配置されますが、すべての場合でそうとは限らないため、距離を基準に過剰解釈をすることは避けてください。それよりも、図のエッジ(円の間のライン)の方が、キーワードの関係性についてはより正確な指標となります。
結果
完成したネットワーク図はこのページの一番上にあるので、ご覧になってみてください。私の直感ですが、ここで採用したアプローチは大きな成功を収めたと言えると思います。多くの関心事のコミュニティを識別しているのは明らかなので、たくさんの人がこれに同意してくれるのではないでしょうか。以下に、いくつかの例を挙げてみます。
governmentからの分枝構造
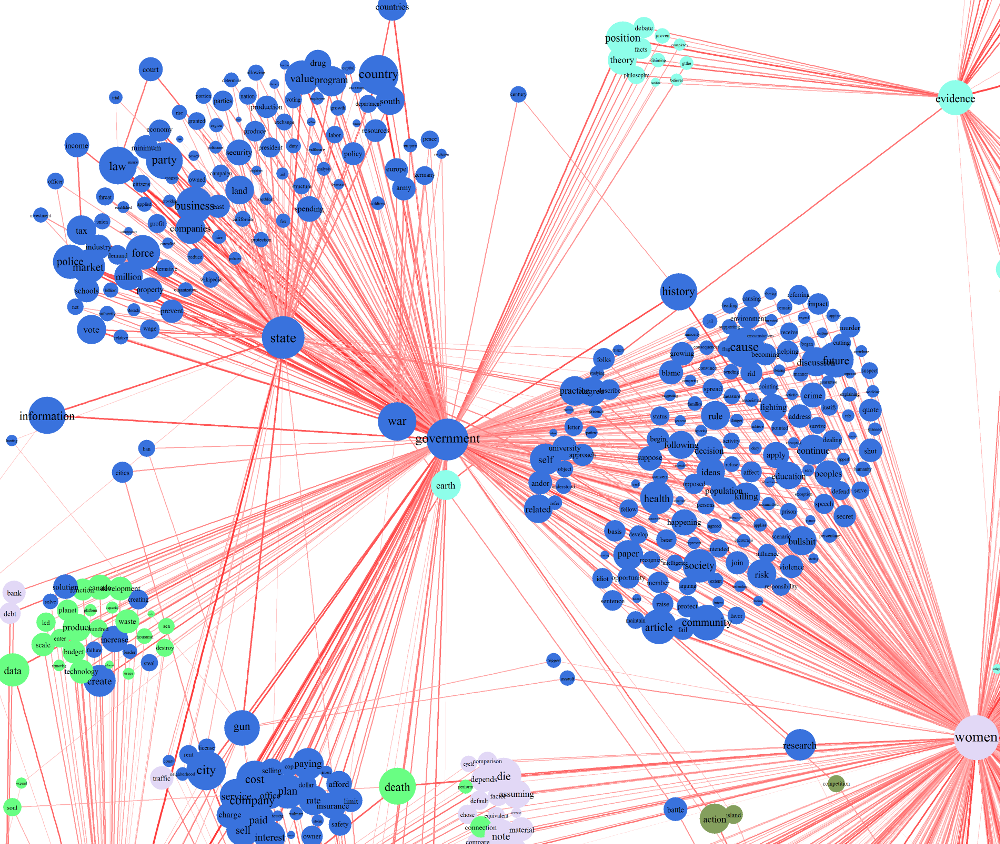
多くのredditorは「government(政府、濃青)」の話題に関心があるようですが、トピック内での関心は、いろんなソースに端を発しているということが分かります。大きな特徴を持つグループとして規定できるのが、「state(州、行政、国家)」と「women(女性)」のディスカッションによる2つの二次配列です。前者については、ディスカッションのトピックとして「business(仕事)」「market(マーケット、市場)」「force(力)」「police(警察)」といった単語が多く使われているため、経済やセキュリティについての内容が中心だということが分かります。一方、後者では、「health(健康)」「community(地域社会)」「education(教育)」などが目立つことから、社会問題についての内容が主になっているようです。これらのクラスタ(集団)は、リベラル派と保守派の政策と相関性があるのかもしれませんが、両者の特徴を正確に言い表しているかどうかは確かではありません。それよりも、私にとってはどちらかというと、社会と経済の「自然な」境界の確認のように見えます。
他にも、政府と強い関係があるキーワードのグループはいくつもあります。“経験主義者”的なグループ(緑がかった青)では、政治哲学に関心があるようです。「technology(テクノロジ、青緑)」のコミュニティとつながりのあるものは、専門的な技術への興味が強いようです。もう1つの(「car(クルマ)」とつながっている)グループは、広い経済よりも“小さな”(つまり個人的な)資産の話題に集中しているようです。この最後のグループの存在は、“経済問題”への関心と、現実的な家庭の経済への関心の分離の程度を示唆しているので、興味深いと思います。
女性。女性?女性!

redditでは、女性について語られることが非常に多いようです。(他のウェブサイトと同様に)大部分が若い男性で構成されているフォーラムでは、驚くようなことではありません。しかし、みんなが女性を話題にしているようなのですが、全員が同じことについて話していないのは明らかです。上の画像の右側には、灰色がかった緑のコミュニティに2つの関連するグループがあるのが分かりますね。ひとつは「men(男性)」を中心に、もうひとつは「sex(セックス)」を中心に構成されています。この2つのグループに含まれる単語から考えると、大まかにはredditorたちは“関係”について話していると解釈していいでしょう。下の方にある「story(物語)」というコミュミティの大きなクラスタは、女性によるあるいは女性に関しての物語とつながりがあるのかもしれません。中心にある「women(女性、灰色がかったピンク)」のノードの左下に大きなクラスタが2つ見えますが、これらはそれほど顕著なものではないでしょう。少なくとも私にはそう思えます。
食べ物と飲み物
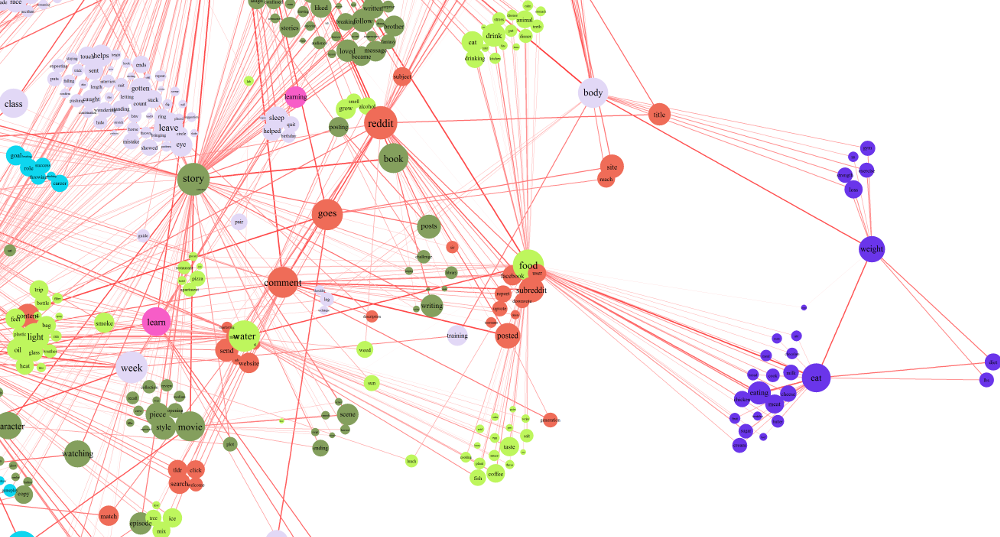
食べ物やダイエットに強い興味があるredditorもいます。「diet(ダイエット)」は特に、他のトピックとはつながっていません。黄緑色のグループを見ると、「food(食べ物)」と「water(水)」を中心としたコミュニティができています。その中の多くの単語が「body(体、灰色がかったピンク)」のノードと関係していることは、ごく自然なことでしょう。特に興味深いのは、右端にある紫のグループです。食べ物や体と強い関連がありますが、ダイエットや健康的な食事とより深いつながりがあるようです。このノードは、redditの減量サポートコミュニティのメンバーを表しているのでしょうか?また、上の図で目立つ特徴としては、reddit自体について頻繁に話題にしているオレンジ色のコミュニティがあることです。
楽しみ・ゲーム

この図では、スポーツとテレビゲームの組み合わせに関わる、ターコイズ色の大きなグループに注目しています。この2つが互いに関連しているのは、恐らくどちらの文脈でも使われる似た単語があること、個々のredditorが一部重なる興味を持っている可能性があるということを示しているのでしょう。概して言えば、左の2つのクラスタはよりテレビゲームとの関連が強く、右のクラスタは伝統的なスポーツと関係があるようです。図の一番上にある青緑色のテクノロジのコミュニティと有意な関係が見られますが、意外性はありませんね。全体に散在しているのは、音楽に最大の焦点をおいたコミュニティ(黄色)です。
おまけ:ネットワーク図の正規化
これまでにお話ししてきたようなネットワーク図に加え、“正規化”したグラフも作成しました。前者の図は、redditorによる単語の使用あるいは共起を元に作られたものですが、こちらのグラフは、redditor間で広く使用された異なるキーワードの合計のコサイン類似度(相互関係に近い)に基づいています。その結果として、先に挙げたグラフの根拠となっていた、絶対的な単語使用頻度の影響は実質的には消えてしまいました。各ノードに2つ以上のエッジがあるかわりに、このグラフでは、全てのつながり(ここでは全て同じスケールになっています)の上位わずか0.1%だけが選ばれています。つながりが1つもないノードは、グラフから取り除かれています。ネットワーク図の形が変わっているのは明らかですが、じっくり観察してみると、先ほどのグラフと多くの類似点があることに気付きます。これまでに紹介したいくつかのつながりが、どちらかと言えば自明のものであるのに対し、このグラフは人々の興味の“微細構造”と呼べるようなものをもう少し明らかにしていると思います。コサイン類似度により線形になったエッジの色に注目してください。ノードのサイズは、その次数中心性の対数(底10)(つまり、他のノードとのつながりの数)によって変化します。

データのシェア
多くのリクエストを受け、この記事の元となった生のデータを入手できるようにしました。データはredditのAPIから入手可能なのですが、redditのサーバを介する手間を省くことができます。コメントは他者が見ることを想定して公に投稿されたものなので、プライバシーの問題はありません。また、redditのユーザネームはユーザがつけたものと同様に匿名性がありますが、個人の特定を難しくするため、任意の数字IDに置き換えました。下に、10個のCSV圧縮ファイルへのリンクを貼っておきました。それぞれの行は異なるコメントになっています。そして列は、ユーザID、リンクのタイトル、subreddit、データを集めた時(投稿されてからの秒数)、投稿された時、upvote、downvote、コメントの8つです。全てのファイルでユーザIDが1から始まっていますが、ファイル1のID1は、他のファイルのID1とは異なるユーザです。

{kind=link}