2016年9月1日
なぜUber EngineeringはPostgresからMySQLに切り替えたのか
本記事は、原著者の許諾のもとに翻訳・掲載しております。
はじめに
Uberの初期のアーキテクチャは、Pythonで書かれたモノリシックなバックエンドアプリで構成されており、データの永続性のために Postgres を使っていました。当時から比べて今のUberのアーキテクチャはかなり変わっており、 マイクロサービス のモデルや新しいデータプラットフォームになりました。特に、以前Postgresを使っていたケースの多くで、今は Schemaless 、つまりMySQLの上で構築された新しいデータベースのシャーディングレイヤを使います。今回の投稿では、私たちが見つけたPostgresの欠点を探り、MySQLの上でSchemalessと他のバックエンドサービスを構築するに至った経緯について説明していきます。
Postgresのアーキテクチャ
私たちはPostgresで以下のような多くの制約に直面しました。
- 書き込みでの非能率的なアーキテクチャ
- 非能率的なデータレプリケーション
- テーブルが破損する問題
- レプリカのMVCC(多版型同時実行制御)のサポートが弱い
- 新しいリリースへの更新が難しい
このような制約について、Postgresのディスク上のテーブルやインデックスデータの実例の分析を通して見ていきましょう。特にMySQLが InnoDBストレージエンジン で同じデータを表す方法を比べた場合を取り上げます。留意点としては、ここでの分析は最新ではないPostgres リリース9.2シリーズでの経験におおむね基づいて行われています。私たちが知る限りでは、この記事で論じる内部アーキテクチャは、新しくリリースされたPostgresでも大きな違いはありません。少なくとも、(10年ほど前になる)Postgres リリース8.3からリリース9.2が出た時のディスク上の表現の基本的な設計は、ほとんど変わっていません。
ディスク上のフォーマット
リレーショナルデータベースは、いくつかのキーとなるタスクを実行しなければいけません。
- 挿入/更新/削除の機能を提供する
- スキーマ変更の機能を提供する
- 異なる接続では動作するデータ処理の見方があるので、 多版型同時実行制御 (MVCC)メカニズムを実装する
こういった機能すべてをどのように同時に処理するかを考慮することは、ディスク上のデータベースの表現方法を設計する際に主要な要素の一部です。
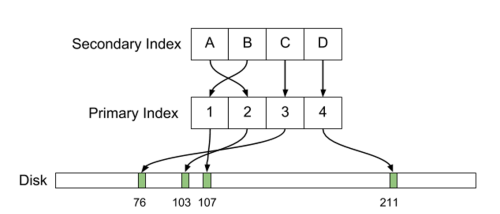
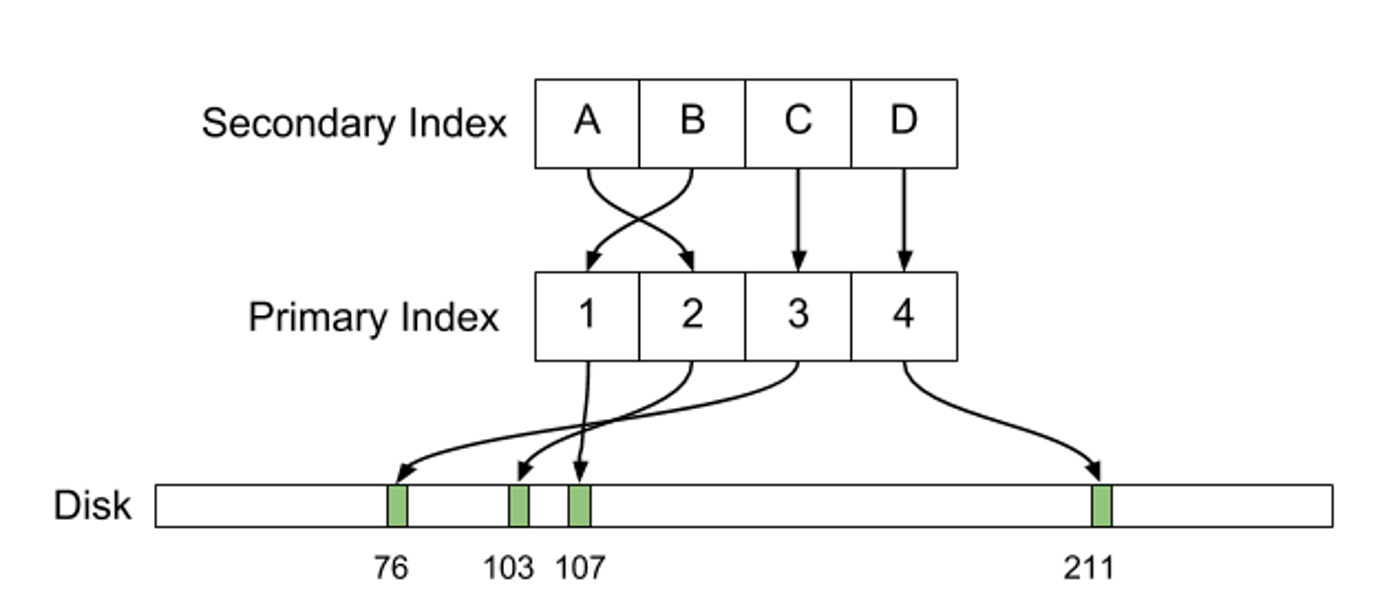
Postgresのコアとなる設計面の1つは、不変の行データにあります。これらの不変型の行はPostgresの専門用語でタプルと呼ばれています。このタプルは、Postgresが ctid と呼ぶものによって、ユニークに定義づけられています。 ctid は概念的にタプルとしてディスク上の位置(言い換えれば物理ディスクのオフセット)を示します。複数の ctids は潜在的に単一の行を表すこともあります(例えば複数バージョンの行がMVCCの目標として存在している場合、あるいは古いバージョンの行が autovacuum の過程でまだ要求されていない場合など)。一連の組織化されたタプルはテーブルを形成します。テーブルそれ自体はインデックスを持ち、 ctid ペイロードに対してインデックスフィールドをマップするデータ構造(典型的なBツリー)として構造化されます。
一般に ctids はユーザには見えませんが、どのように動作するかを知っておくことでPostgresテーブルのディスク上の構造を理解する助けとなります。行に対する現在の ctid を見るには、 WHERE 句でカラムリストに ctid をつけ加えることができます。
uber@[local] uber=> SELECT ctid, * FROM my_table LIMIT 1;
-[ RECORD 1 ]--------+------------------------------
ctid | (0,1)
...other fields here...レイアウトの詳細を説明するために、まずはシンプルなusersテーブルの例を見ていきましょう。各ユーザに対し、自動インクリメントするユーザIDのプライマリキー、ファーストネーム、ラストネーム、出生年のデータを持っています。またユーザのフルネーム(ファーストネームとラストネーム両方)上で合成セカンダリインデックスを、ユーザの出生年上で、もう1つのセカンダリインデックスを定義します。そういったテーブルを作成する データ定義言語 は次のようになるはずです。
CREATE TABLE users (
id SERIAL,
first TEXT,
last TEXT,
birth_year INTEGER,
PRIMARY KEY (id)
);
CREATE INDEX ix_users_first_last ON users (first, last);
CREATE INDEX ix_users_birth_year ON users (birth_year);この定義では3つのインデックスに注意してください。プライマリキーインデックスと、私たちが定義した2つのセカンダリインデックスです。
今回の例として、以下のデーブルのデータから始めてみましょう。偉大な歴史上の数学者のリストです。
| id | first | last | birth_year |
| 1 | Blaise | Pascal | 1623 |
| 2 | Gottfried | Leibniz | 1646 |
| 3 | Emmy | Noether | 1882 |
| 4 | Muhammad | al-Khwārizmī | 780 |
| 5 | Alan | Turing | 1912 |
| 6 | Srinivasa | Ramanujan | 1887 |
| 7 | Ada | Lovelace | 1815 |
| 8 | Henri | Poincaré | 1854 |
先ほども述べたように、これらの行はそれぞれ、ユニークかつ見えない ctid を暗黙のうちに持っています。つまり、テーブル内部の表現については以下のように考えることができます。
| ctid | id | first | last | birth_year |
| A | 1 | Blaise | Pascal | 1623 |
| B | 2 | Gottfried | Leibniz | 1646 |
| C | 3 | Emmy | Noether | 1882 |
| D | 4 | Muhammad | al-Khwārizmī | 780 |
| E | 5 | Alan | Turing | 1912 |
| F | 6 | Srinivasa | Ramanujan | 1887 |
| G | 7 | Ada | Lovelace | 1815 |
| H | 8 | Henri | Poincaré | 1854 |
ctids に ids をマップするプライマリキーインデックスは以下のように定義されます。
| id | ctid |
| 1 | A |
| 2 | B |
| 3 | C |
| 4 | D |
| 5 | E |
| 6 | F |
| 7 | G |
| 8 | H |
id フィールドでBツリーが定義され、Bツリーの各ノードは ctid の値を持ちます。この場合に注意するのが、Bツリーのフィールドの順序は自動インクリメントの id を使用しているテーブルの順序と同じですが、必ずしもそうである必要はありません。
セカンダリインデックスについても似たようになっています。主な違いは、Bツリーが辞書式順序で作られなければならないため、フィールドがプライマリインデックスとは異なる順序で並べられていることです。インデックス( first , last )はファーストネームがアルファベットの最初から並べられています。
| first | last | ctid |
| Ada | Lovelace | G |
| Alan | Turing | E |
| Blaise | Pascal | A |
| Emmy | Noether | C |
| Gottfried | Leibniz | B |
| Henri | Poincaré | H |
| Muhammad | al-Khwārizmī | D |
| Srinivasa | Ramanujan | F |
さらに、インデックス birth_year は下記のように昇順に並べられています。
| birth_year | ctid |
| 780 | D |
| 1623 | A |
| 1646 | B |
| 1815 | G |
| 1854 | H |
| 1887 | F |
| 1882 | C |
| 1912 | E |
ご覧のように、どちらの場合も個々のセカンダリインデックス内の ctid フィールドは辞書式順序では並んでいません。自動インクリメントであるプライマリキーの場合とは違っています。
このテーブルを更新しなければならないとしましょう。例えば、al-Khwārizmīの出生年を、別説の紀元770年に変えることにします。先に述べたように、行のタプルは不変です。したがって、レコードを更新するには、テーブルに新しいタプルを追加しなければなりません。この新たなタプルは、見えない ctid を新しく持ちますが、これを I とします。Postgresは新しいアクティブなタプル I と古いタプルDを区別できなければなりません。Postgresは内部的に、それぞれのタプル内にバージョンのフィールドと(もし存在するのなら)過去のタプルを示すポインタを持っています。その結果、新しいテーブルの構造は次のようになります。
| ctid | prev | id | first | last | birth_year |
| A | null | 1 | Blaise | Pascal | 1623 |
| B | null | 2 | Gottfried | Leibniz | 1646 |
| C | null | 3 | Emmy | Noether | 1882 |
| D | null | 4 | Muhammad | al-Khwārizmī | 780 |
| E | null | 5 | Alan | Turing | 1912 |
| F | null | 6 | Srinivasa | Ramanujan | 1887 |
| G | null | 7 | Ada | Lovelace | 1815 |
| H | null | 8 | Henri | Poincaré | 1854 |
| I | D | 4 | Muhammad | al-Khwārizmī | 770 |
2つのバージョンのal-Khwārizmīの行が存在する限り、インデックスは両方の行を保持しなければなりません。簡潔のために、プライマリキーのインデックスを省略してセカンダリインデックスだけを記すと下記のようになります。
| first | last | ctid |
| Ada | Lovelace | G |
| Alan | Turing | E |
| Blaise | Pascal | A |
| Emmy | Noether | C |
| Gottfried | Leibniz | B |
| Henri | Poincaré | H |
| Muhammad | al-Khwārizmī | D |
| Muhammad | al-Khwārizmī | I |
| Srinivasa | Ramanujan | F |
| birth_year | ctid |
| 770 | I |
| 780 | D |
| 1623 | A |
| 1646 | B |
| 1815 | G |
| 1854 | H |
| 1887 | F |
| 1882 | C |
| 1912 | E |
古い行を赤、新しい行を緑で記しました。Postgresには、見えないところに 別の フィールドがあって、そこに行のバージョンを保持し、最新の行を判断するのに使っています。この追加されたフィールドによって、データベースはどの行のタプルをトランザクションに渡すかを決めています。トランザクション処理では最新のバージョンの行を必要としないこともあるからです。
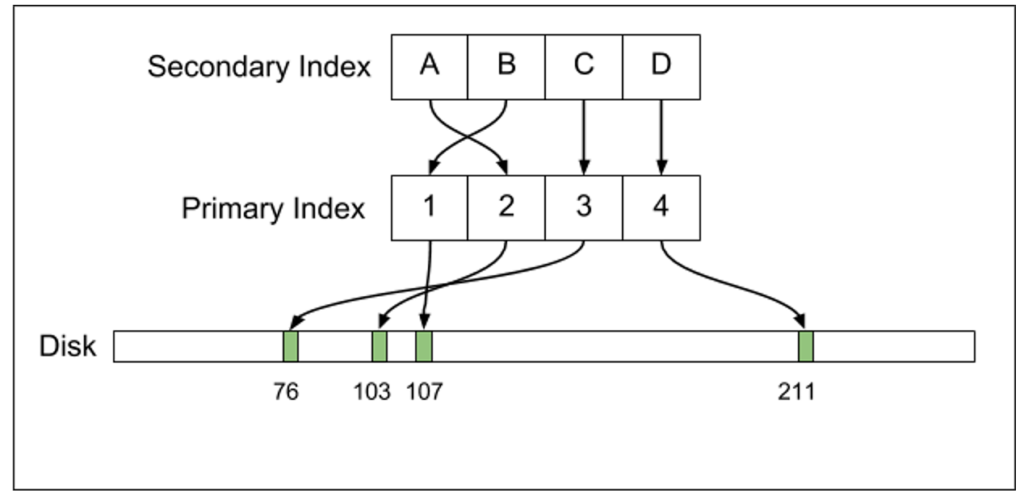
Postgresでは、プライマリインデックスとセカンダリインデックスの全てが、ディスク上のタプルのオフセットを示します。1つのタプルの位置が変わると、全てのインデックスの更新が必要です。
レプリケーション
新たな行をテーブルに挿入する際、ストリーミングレプリケーションが有効であれば、Postgresはテーブルをレプリケーションする必要があります。クラッシュ時のリカバリのため、データベースは ログ先行書き込み (WAL)を前もって保管しており、 2フェーズコミット を実行するために使用します。データベースはストリーミングレプリケーションが有効でなくてもWALを維持する必要があります。というのも、WALが ACID の原子性(atomicity)と永続性(durability)の特性を与えているからです。
WALを理解するには、突然の停電状態といった予期せぬデータベースのクラッシュで何が起きるかを深く考えてください。WALは、データベースがディスク上のテーブルやインデックスという要素に対する変更を行う際の元帳を表しています。Postgresのデーモンが最初に起動すると、この元帳のデータとディスク上の実際のデータとを比較します。元帳のデータがディスク上に反映されていない場合、WALが示すデータを反映するようにデータベースは全てのタプルやインデックスを正します。WALにあるデータは全てロールバックされますが、部分的にトランザクションデータが適用されます(つまり全トランザクションが決して保証されたものではないということです)。
Postgresのストリーミングレプリケーションは、マスタデータベース上のWALをレプリカに送ることで実行されます。レプリカのデータベースはそれぞれが、クラッシュからリカバリする時のように効果的に振るまい、常にWALのアップデートを適用します。あたかもクラッシュが起きて始動した時のように動くのです。ストリーミングレプリケーションと実際のクラッシュリカバリとの唯一の違いを言うと、レプリカは”ホットスタンバイ”モードでストリーミングWALを適用しながら読み込みクエリを出すのに対し、実際のクラッシュモードにあるPostgresのデータベースは通常はどんなクエリも出しません。それはデータベースのインスタンスがクラッシュをリカバリするプロセスが終了させるまで続きます。
WALは実際にクラッシュのリカバリを目的に設計されているために、ディスク上の更新に関しては低いレベルの情報しか持っていません。WALの要素は、行のタプルと実際のディスク上のオフセットの配置(つまり行の ctids )程度です。レプリカが全て追いついた時に、Postgresのマスタとレプリカの使用を中断すると、レプリカ上にある実際のディスク上の要素がマスタのバイトごとにレプリカと正確に一致します。それゆえ、マスタとは時間が離れたとしても、 rsync のようなツールが壊れたレプリカを修正できるのです。
Postgresの設計に対する結論
Postgresの設計は Uberのデータ にとって効率が悪く、困難を伴うものという結論となりました。
ライトアンプリフィケーション
Postgresの設計に関する1つ目の問題は、他のコンテキストで ライトアンプリフィケーション として知られています。一般的に、ライトアンプリフィケーションはSSDディスクにデータを書き込む際の問題のことを言います。これは、小規模の論理的更新(およそ数バイト程度の書き込み)が物理レイヤに転送される時、より規模は大きくなり、その上多くのリソースを消費する更新になるという問題です。同じことがPostgresでも起こります。前出の例で、al-Khwārizmīの出生年に対して小規模な論理的更新を行った場合、以下に示すような、少なくとも4つの物理的更新を発行しなければなりませんでした。
- 表領域 に新しい行タプルを書く。
- 新しいタプルのレコードを追加するために、プライマリキーインデックスを更新する。
- 新しいタプルのレコードを追加するために、インデックス(
first,last)を更新する。 - 新しいタプルのレコードを追加するために、インデックス
birth_yearを更新する。
実際、これらの4つの更新は、メインの表領域に対してなされた書き込みを反映するだけです。つまり、書き込みはWALに反映する必要があります。そのため、ディスクへの書き込み量の総計はさらに大きくなります。
ここで着目すべきは、2番目と3番目の更新です。al-Khwārizmīの出生年を更新した時、実際にはプライマリキーを変更しませんでしたし、ファーストネームもラストネームも変更していません。しかしそれでもなお、これらのインデックスは、データベースの行レコードに対する、新しい行タプルの作成で、更新されなければいけません。たくさんのセカンダリインデックスを持つテーブルにとって、これらの余分なステップは、とんでもない非効率を招くことがあり得ます。例えば、12個のインデックスが定義されたテーブルがあるとすると、1つのインデックスによって扱われているだけのフィールドへの更新は、新しい行の ctid を反映するために12のインデックス全てに伝えられなければいけません。
レプリケーション
レプリケーションはディスク上の変更のレベルで発生するので、このライトアンプリフィケーションの問題も自然にレプリケーションレイヤに伝わります。小規模な論理的レコードのレプリケーションに代わって、例えば「 ctid D の出生年を770に変更する」時、データベースは代わりに、たった今述べた4つの書き込み全てのWALエントリを書き出します。そしてこれらのWALエントリ4つが、全てネットワーク上に広がります。こうやって、ライトアンプリフィケーションの問題はレプリケーションアンプリフィケーションの問題へと移行していきます。そして、Postgresのレプリケーションのデータの流れはあっという間に極めて冗長になり、潜在的に大きな通信帯域を占有することになります。
Postgresのレプリケーションが単一のデータセンタだけで発生する場合には、レプリケーションの通信帯域が問題とならないかもしれません。最新のネットワーク機器やスイッチは大きな通信帯域を処理することができます。そして、多くのホスティングプロバイダは無料あるいは安価なイントラデータセンタの通信帯域を提供します。しかしデータセンタ間でレプリケーションが発生する場合には、問題は急速に拡大するでしょう。例えば、Uberはもともと西海岸のコロケーションスペースで、物理的なサーバを運用していました。災害復旧の目的で、私たちは東海岸のコロケーションスペースに、サーバを追加しました。この設計で、西海岸のデータセンタにPostgresインスタンスのマスタ(とレプリカ)を、東海岸のデータセンタにレプリカ一式を設置したのです。
カスケードレプリケーション はデータセンタ間の通信帯域を、マスタと1つのレプリカとの間で必要とされるレプリケーションの量まで制限します。たとえ多くのレプリカが第2のデータセンタにあるとしてもです。しかしそれでも、Postgresレプリケーションのプロトコルの冗長性は、たくさんのインデックスを使用するデータベースに対して、圧倒的な容量のデータの発生要因となることがあります。とても幅広い通信帯域で長距離の接続を手に入れるには費用がかかります。たとえ、金額が問題にならない場合でも、長距離の接続を内部の接続と同じ通信帯域のネットワーク接続にすることは簡単なことではありません。この通信帯域の問題も、WALのアーカイブで問題を引き起こしました。西海岸から東海岸までWALの更新を全て送るだけでなく、全てのWALをファイルストレージWebサービスにアーカイブしました。両方とも追加の保証で、災害が起こった時にデータをリストアし、これによりアーカイブされたWALがデータベースのスナップショットから新しいレプリカを作れるようにするためです。通信量のピーク時の早い段階で、ストレージWebサービスの通信帯域は、WALに書かれていた速度に追随するのに十分というわけではありませんでした。
データ破損
データベース容量を増やすために決まって行っているマスタデータベースの昇格の際、Postgres 9.2にバグが発生しました。 レプリカのたどるタイムライン切り替えが間違って おり、一部のWALレコードを誤って適用したレプリカもありました。このバグが原因で、バージョン管理機構によって非アクティブとマークされるべきレコードの一部が、実際には非アクティブとマークされていなかったのです。
下記のクエリを実行してみると、このバグが上述のユーザテーブル例にどのような影響を及ぼすか確認できます。
SELECT * FROM users WHERE id = 4;結果、2件のレコードが返されます。出生年が紀元780年である元のal-Khwārizmīの行と、出生年が紀元770年である新しいal-Khwārizmīの行です。 WHERE のリストに ctid を追加すれば、返された2件のレコードの ctid が異なる値であることが分かります。2件の別個の行(タプル)ということです。
この問題は、いくつかの点で極めて厄介でした。まず、問題によって影響を受ける行の数が簡単には分かりませんでした。データベースから返された結果が重複していることが、いくつかのケースでアプリケーションロジックのエラーを引き起こしたのです。結局、この問題を抱えていることが分かっているテーブルの状態を検知できるよう、防御的なプログラミングの文を追加することになりました。このバグは全てのサーバに影響を及ぼしたため、破損した行はレプリカインスタンスごとに異なっていました。つまり、あるレプリカでは行 X は問題があり行 Y は問題がないのに、別のレプリカでは行 X は問題がなく行 Y は問題があるといった状況です。実は、破損データを抱えるレプリカの数と、この問題がマスタに影響を及ぼしたか否かについて、私たちははっきり把握することができませんでした。
分かっていた限り、この問題が出現していたのは1つのデータベースにつき数行だけでしたが、レプリケーションは物理レベルで行われるため、データベースのインデックスが完全に破損してしまうのではないかと非常に懸念しました。Bツリーの本質的な側面は、 リバランス が周期的に行われなければならないということですが、そのリバランス操作によってサブツリーがディスク上の新しい位置に移動するため、ツリー構造が完全に変わることもあります。間違ったデータが移動した場合、これによってツリーの大部分が完全に無効になる可能性もあるのです。
結局、実際のバグを突き止められたので、それを用いて、新たに昇格したマスタに破損した行がないことを確認できました。マスタの新たなスナップショットから全てのレプリカを再同期させることで、レプリカ上の破損の問題を解決しました。労力を要する処理でした。ロードバランシングプールから一度にいくつかのレプリカを取り出す容量しかなかったためです。
私たちが経験したバグは、Postgres 9.2の特定リリースにのみ影響したもので、かなり以前に修正済みです。しかし、このクラスのバグがともかく起こり得るということがいまだ気掛かりです。Postgresの新バージョンで、この種のバグを持つものがいつリリースされるかもしれません。そしてレプリケーションの仕組みから考えると、この問題はレプリケーション階層に含まれる全てのデータベースに広がる可能性をはらんでいます。
レプリカのMVCC
Postgresは、レプリカのMVCCを真の意味ではサポートしていません。レプリカがWALの更新を適用するという事実は、どの時点においても マスタと全く同一のディスク上データのコピーを持つ ことを意味します。この設計はUberにとって問題となります。
Postgresは、MVCCのために行の旧バージョンのコピーを維持しておく必要があります。ストリーミングを行うレプリカに未完了のトランザクションがある場合、データベースに対する更新は、そのトランザクションによって未完了のまま保留されている行に影響するのであればブロックされます。この状況では、Postgresはそのトランザクションが完了するまで、WAL適用のスレッドを中断します。このことは、そのトランザクションの処理に長い時間がかかる場合、レプリカがマスタより大きく遅れてしまうので問題となります。したがってPostgresは、そのような状況ではタイムアウトを適用します。トランザクションがWALの適用を 指定された時間 ブロックした場合、Postgresがそのトランザクションを取り消すのです。
この設計により、レプリカはマスタより常に何秒か遅れる可能性があるため、書いたコードのトランザクションが取り消されてしまうケースも多くなります。この問題は、トランザクションの開始場所と終了場所を見えにくくするコードを書いているアプリケーション開発者は、はっきり認識できないかもしれません。例えば、ある開発者が、領収書をユーザにメールで送るコードを書いているとしましょう。そのコードは書き方によっては、メールの送信が済むまで未完了のまま保留されるデータベーストランザクションを、暗黙的に含むかもしれません。未完了のデータベーストランザクションを、無関係のブロッキングI/Oを実行している間保留するというのは、まずい書き方です。しかし現実には、大部分のエンジニアはデータベースの専門家ではなく、特に未完了トランザクションのような下位レベルの詳細を見えにくくするORMを使っているような場合は、この問題を必ずしも理解できていないかもしれません。
Postgresのアップグレード
レプリケーションレコードは物理レベルで動作するため、Postgresの異なる一般公開(GA)リリース間でデータを複製することはできません。Postgres 9.3を実行しているマスタデータベースはPostgres 9.2を実行しているレプリカに対して複製することはできず、Postgres 9.2を実行しているマスタはPostgres 9.3を実行しているレプリカに対して複製することはできないのです。
私たちは、PostgresのあるGAリリースから別のGAリリースにアップグレードするために、 このようなステップ を踏みました。
- マスタデータベースをシャットダウンする。
pg_upgradeというコマンドをマスタ上で実行すると、マスタデータがインプレースで更新される。この作業は、大規模なデータベースでは大抵長時間かかり、この過程の間、トラフィックはマスタから提供されることができない。- マスタを再起動する。
- マスタの新たなスナップショットを生成する。マスタから全てのデータを完全にコピーするので、このステップでも、大規模なデータベースでは長い時間がかかる。
- 各レプリカの内容を消去して、マスタの新たなスナップショットをレプリカにリストアする。
- 各レプリカをレプリケーション階層へ戻す。レプリカが、リストアされている間にマスタによって適用された全ての更新に完全に追いつくのを待つ。
Postgres 9.1からPostgres 9.2へ移行するためのアップグレード処理は、無事に完了しました。ですが、この過程には非常に時間がかかったため、同じ過程を再び踏む余裕はありませんでした。Postgres 9.3が登場した頃には、Uberの成長に伴ってデータセットが大幅に増加していたので、アップグレードするとなればさらに長い時間がかかりそうでした。このため、現行のPostgresのGAリリースは9.5ですが、当社のレガシーなPostgresインスタンスは今でもPostgres 9.2を使っています。
Postgres 9.4以降を使っている場合は、 pglogical などを活用することも考えられます。pglogicalは、Postgresのための論理レプリケーションレイヤを実装しています。pglogicalを使うと、Postgresの異なるリリース間でデータを複製できます。つまり、重大なダウンタイムを伴うことなく9.4から9.5に上げるようなアップグレードを行うことが可能なのです。とはいえ、pglogicalはPostgresのメインラインツリーに組み込まれていないので、やはり扱いにくさがあります。そしてPostgresの古いリリースを使っているケースでは、pglogicalはまだ利用することができません。
MySQLのアーキテクチャ
Postgresの制限のいくつかについて説明してきましたが、SchemalessのようなUber Engineeringの比較的新しいストレージプロジェクトにとってなぜMySQLが重要なツールであるかもお話しします。MySQLは多くのケースで、当社の使い方にとってより都合が良いことが分かりました。違いを理解するため、MySQLのアーキテクチャを吟味し、Postgresのアーキテクチャと比較していきましょう。特に分析したいのは、MySQLが InnoDBストレージエンジン を使って動作する仕組みです。InnoDBはUberで使われているだけでなく、MySQLのストレージエンジンとして最も普及しているかもしれません。
InnoDBにおけるディスク上のレプリケーション
Postgresと同様、InnoDBはMVCCや可変データといった高度な機能をサポートしています。InnoDBのディスク上のフォーマットを徹底的に議論するというのはこの記事の範囲外ですので、以下では、Postgresとの主な違いに注目したいと思います。
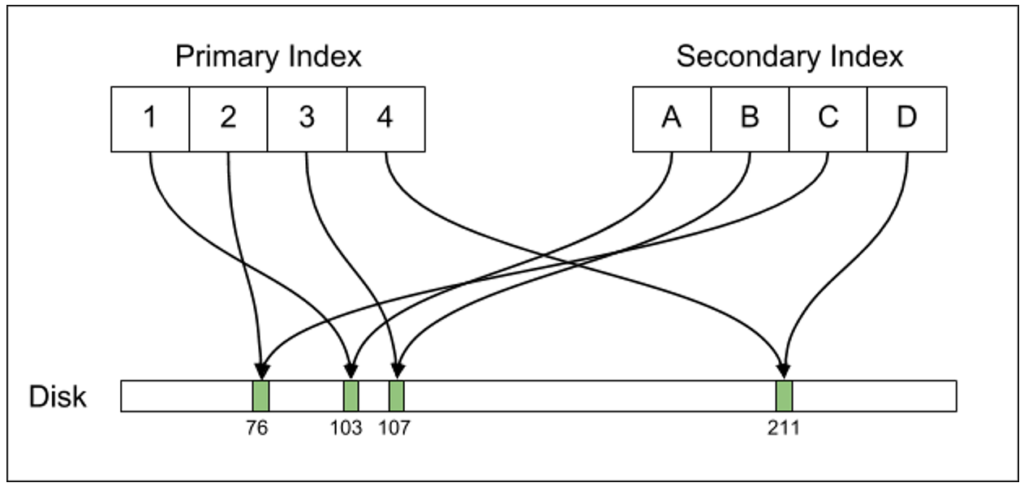
アーキテクチャの上で最も重要な違いは、Postgresがインデックスレコードをディスク上の位置に直接マップする一方、InnoDBは二次的構造を持っているということです。ディスク上の行位置を指すポインタ(例:Postgresにおける ctid )を保持する代わりに、InnoDBではセカンダリインデックスレコードが、プライマリキーの値を指すポインタを保持します。そうしてMySQLのセカンダリインデックスは、インデックスキーをプライマリキーと関連づけているのです。
| first | last | id (primary key) |
| Ada | Lovelace | 7 |
| Alan | Turing | 5 |
| Blaise | Pascal | 1 |
| Emmy | Noether | 3 |
| Gottfried | Leibniz | 2 |
| Henri | Poincaré | 8 |
| Muhammad | al-Khwārizmī | 4 |
| Srinivasa | Ramanujan | 6 |
インデックス(first, last)に対してインデックス検索を実行するためには、実は2回の検索が必要となります。最初の検索ではテーブルを探し、レコードのプライマリキーを見つけます。プライマリキーが見つかったら、2回目の検索でプライマリキーのインデックスを探し、行のディスク上の位置を見つけるのです。
この設計のため、InnoDBではセカンダリキー検索を実行する際、Postgresに比べて若干不利となります。Postgresでは1つのインデックスだけを探せばよいのですが、InnoDBでは2つのインデックスを探さなければならないからです。しかし、データが正規化されているので、行の更新で必要となるのは、その行更新によって実際に変更されるインデックスレコードを更新することだけです。その上、InnoDBは一般的に、行更新をインプレースで実行します。古いトランザクションがMVCCのために行を参照する必要がある場合、MySQLは古い行を ロールバックセグメント と呼ばれる特別な領域にコピーします。
al-Khwārizmīの出生年を更新する時に何が起こるか見ていきましょう。スペースがある場合、 id が4である行の出生年フィールドは、インプレースで更新されます(出生年は一定量のスペースを占める整数なので、実はこの更新は常にインプレースで実行されます)。出生年のインデックスも、新しい出生年を反映するようインプレースで更新されます。古い行データはロールバックセグメントにコピーされます。プライマリキーのインデックスは更新される必要がなく、名前のインデックス( first , last )も更新される必要はありません。このテーブルに多数のインデックスがあったとしても、やはり birth_year フィールドを実際にインデックス化しているインデックスを更新するだけで済みます。よって、例えば signup_date や last_login_time といったフィールドに対するインデックスがある場合、Postgresではこれらのインデックスを更新する必要がありますが、InnoDBではその必要がありません。
また、この設計によって、vacuumの実行やコンパクションがより効率的になっています。vacuumされるべき行は全て、ロールバックセグメントで直接利用することができるのです。一方、Postgresのautovacuum処理は、削除された行を特定するためにテーブルの完全スキャンを実行しなければなりません。
MySQLは、追加のレイヤを使った間接参照を行う。つまり、セカンダリインデックスレコードはプライマリインデックスレコードを指し、プライマリインデックス自体はディスク上の行位置を保持する。行オフセットが変わった場合、更新される必要があるのはプライマリインデックスだけである。
レプリケーション
MySQLは複数の 異なるレプリケーションモード をサポートしています。
- 文ベースのレプリケーションは、論理SQL文を複製する(例えば、
UPDATE users SET birth_year=770 WHERE id = 4のようなリテラル文を文字どおり複製する) - 行ベースのレプリケーションは、変更された行レコードを複製する
- 混合レプリケーションでは、上記2つのモードを組み合わせて使用する
これらのモードには様々なトレードオフがあります。文ベースのレプリケーションは通常、最もコンパクトですが、少量のデータを更新するためにレプリカがコストの高い文を適用しなければならない場合もあります。一方、行ベースのレプリケーションは、PostgresのWALレプリケーションと似ており、より冗長になるものの、レプリカに対する更新がより予測しやすく効率的なものになります。
MySQLでは、プライマリインデックスだけが、行のディスク上のオフセットを指すポインタを持ちます。このことは、レプリケーションに際して重大な影響をもたらします。MySQLのレプリケーションストリームに含まれる必要があるのは、行に対する論理的更新についての情報だけです。レプリケーションの更新は、「行 X のタイムスタンプを T_1 から T_2 に変更する」といった類のものです。レプリカは、このような文の結果として行われるべきインデックスの変更を自動的に推論します。
対照的に、Postgresのレプリケーションストリームは、「ディスクオフセット8,382,491で、書き込みバイト XYZ 」のような物理的変更を含みます。Postgresでは、ディスクになされるあらゆる物理的変更はWALストリームに含まれる必要があります。小さな論理的変更(タイムスタンプの更新など)は、ディスク上の変更を多数伴います。つまりPostgresは、新しいタプルを挿入し、そのタプルを指す全てのインデックスを更新しなければならないのです。したがって、多くの変更がWALストリームに組み込まれることになります。設計がこのように異なっているため、MySQLレプリケーションのバイナリログは、PostgreSQLのWALストリームよりもかなりコンパクトなものとなっています。
それぞれのレプリケーションストリームの仕組みは、MVCCのレプリカに関する動作に対しても重大な影響を及ぼしています。MySQLのレプリケーションストリームは論理的更新なので、レプリカは真の意味でMVCCのセマンティクスを持つことが可能です。このため、レプリカに対するリードクエリがレプリケーションストリームをブロックすることはありません。対照的に、PostgresのWALストリームはディスク上の物理的変更を含むので、Postgresのレプリカはリードクエリと衝突するレプリケーション更新を適用できず、その結果MVCCを実現できないのです。
MySQLのレプリケーションアーキテクチャでは、バグがテーブル破損を引き起こしたとしても、その問題によって壊滅的な事態に陥ることはあまり考えられません。レプリケーションは論理レイヤで行われますので、 Bツリー のリバランスのような操作でインデックスが破損することは決してありません。典型的なMySQLレプリケーションの問題は、文がスキップされる(または、それより発生頻度は低いものの、2度適用される)ケースです。これによってデータが欠落したり無効になったりするかもしれませんが、データベースの停止には至りません。
最後に、MySQLのレプリケーションアーキテクチャでは、MySQLの異なるリリース間での複製を難なく行うことができます。MySQLではレプリケーションフォーマットが変わった場合にのみバージョン番号が上がりますが、MySQLの異なるリリース間でレプリケーションフォーマットが異なることはあまりありません。また、MySQLの論理レプリケーションフォーマットのおかげで、ストレージエンジンレイヤにおけるディスク上の変更がレプリケーションフォーマットに影響を及ぼすことはありません。MySQLのアップグレードを行う典型的な方法は、一度に1つのレプリカに対して更新を適用し、全てのレプリカを更新したら、そのうちの1つを新しいマスタに昇格させるというものです。このアップグレードに伴うダウンタイムはほぼゼロですので、MySQLは最新の状態に保ちやすくなっています。
MySQLの設計に関するその他の利点
ここまで、PostgresとMySQLについて、ディスク上のアーキテクチャに注目してきました。MySQLのアーキテクチャにおける他の重要な側面もまた、Postgresよりかなり優れたパフォーマンスを実現させています。
バッファプール
まず、この2つのデータベースでは、キャッシングの動作が異なっています。Postgresは内部キャッシュ用に一部のメモリを割り当てますが、このキャッシュは、マシンのメモリの合計量に比べると、一般的に小さなサイズです。Postgresではパフォーマンス向上のため、最近アクセスされたディスクデータを、 ページキャッシュ を介してカーネルが自動的にキャッシュできるようになっています。例えば、当社最大のPostgresレプリカでは768GBのメモリが利用できますが、そのメモリの約25GBだけが、Postgresプロセスによってフォールトされる実際の 常駐セットサイズ(RSS)メモリ です。このため、700GB以上のメモリがLinuxのページキャッシュに使用できる状態となっています。
この設計で問題なのは、ページキャッシュを介したデータへのアクセスが、RSSメモリへのアクセスに比べて実際にはコストがやや高くなることです。Postgresプロセスはディスクのデータを検索する際、データの位置を特定するために lseek(2) と read(2) システムコールを発行します。これらのシステムコールはそれぞれ、コンテキストスイッチを伴いますが、これはメインメモリのデータにアクセスするよりもコストが高くなります。実は、Postgresはこの点に関して、十分な最適化もなされていません。つまりPostgresは、 seek と read の操作が単一のシステムコールに統合された pread(2) システムコールを使用しないのです。
一方、InnoDBストレージエンジンは、InnoDB バッファプール と呼ばれる独自のLRUを実装しています。これはLinuxのページキャッシュと論理的に似ているものの、ユーザ空間に実装されています。Postgresの設計よりもかなり複雑な仕組みですが、InnoDBにおけるバッファプールの設計には、以下の非常に大きな利点があります。
- カスタムのLRU設計を実装することが可能となる。例えば、LRUを無効にする異常なアクセスパターンを検知し、甚大な被害を防ぐようにするなど。
- 結果として、コンテキストスイッチが少なくなる。InnoDBのバッファプールを介してアクセスされたデータは、ユーザ/カーネルのコンテキストスイッチを必要としない。最悪のケースでは TLBミス が発生するものの、これは比較的コストが低く、 ラージページ の使用によって最小限に抑えることが可能である。
接続の処理方法
MySQLは、接続ごとにスレッドを生成するという同時接続を実装しています。この方式では比較的オーバーヘッドが低くなります。具体的には、各スレッドでスタック空間用にいくらかのメモリオーバーヘッドが生じ、加えて、接続特有のバッファのためにいくらかのメモリがヒープ上で割り当てられます。MySQLの同時接続数を1万ぐらいにスケールするのは珍しいことではなく、実際に当社では現在、MySQLインスタンスのいくつかをそれに近い接続数に設定しています。
一方、Postgresは、接続ごとにプロセスを生成する設計となっています。これはいくつかの理由で、接続ごとにスレッドを生成する設計よりもコストがかなり高くなります。新しいプロセスをフォークすることは、新しいスレッドを生成するよりも多くのメモリを占有します。その上、IPCのコストは、プロセス間の方がスレッド間よりもはるかに高くなるのです。スレッドを扱う時の軽量な futex の代わりに、Postgres 9.2は、IPCに System V IPC プリミティブを使用します。futexが競合していない一般的なケースでは、コンテキストスイッチを行う必要がないため、futexはSystem V IPCより高速です。
Postgresの設計に関連するメモリとIPCのオーバーヘッドに加えて、Postgresは、たとえ十分なメモリが利用できる場合であっても、多くの接続数を扱うためのサポートが単純に不足しているように思われます。当社では、数百を超えるアクティブな接続に合わせてPostgresをスケールすることが大きな問題となってきました。 ドキュメントでは理由があまり具体的に述べられていませんが 、Postgresで多くの接続数にスケールするには、プロセス外の接続プーリング機構を使うことが強く推奨されています。したがって、当社ではPostgresで接続プーリングを行うために pgbouncer を使っていますが、これは概してうまくいってきました。ただし、サービスに使われているはずの接続よりも多くのアクティブな接続(大抵は”トランザクションでアイドル状態”の接続)を開始するというアプリケーションのバグが、バックエンドサービスで時折発生しています。そしてこのバグは、当社で長時間のダウンタイムを引き起こしてきたのです。
まとめ
Postgresは初期のUberで役立ちましたが、会社の成長に従ってPostgresをスケールする際に大きな問題に直面しました。当社には現在、レガシーなPostgresインスタンスがいくつかありますが、データベースの大半はMySQL上(主に Schemaless のレイヤを使用)で構築しているか、特別なケースではCassandraのようなNoSQLデータベースを使用しています。私たちはMySQLに概してかなり満足しており、Uberでのより高度な使い方をご紹介するブログ記事を今後また掲載するかもしれません。
