2016年10月27日
Railsアプリケーションを、Heroku上で1分間125,000リクエストに対応できるようにスケーリングする
本記事は、原著者の許諾のもとに翻訳・掲載しております。
要約: Herokuでは、Railsのスケーリングが非常に簡単できますが、考慮すべき重要なポイントがあります。DynoとPostgresのさまざまな設定がHerokuでのパフォーマンスにどのように影響を与えるかについて調べました。
スケーリングのテストをする理由
ZeeMee のサーバは、今秋、来たる大学入学のシーズンにリクエストが殺到する見込みです。学生はZeeMeeを使って入学願書に動画や写真を付加することができるので、当社のWebサービスが受ける負荷は非常に深刻なものになっています。ピーク時(大学入学の出願期限)には、リクエストのロードが平均の150倍にもなります。
今年の秋を迎えるにあたり、APIのリクエストの爆発的増加にしっかり備えておこうと考え、Herokuでパフォーマンスがどこまで上げられるかを検討することにしました。当社のアプリはPOJA(plain old JSON API)とGraphQLのエンドポイントを提供しています。私たちのWebアプリ・モバイルアプリでは、これらのAPIで読み込みと書き込みのクエリを行います。
テスト方法
第一段階として、”平均的なユーザ”がZeeMeeを使う際に何をしているかを調べました。ざっと挙げるとZeeMeeのユーザは以下のようなことをしています。
- アカウントの作成
- プロフィール写真のアップロード
- いくつかのアクティビティの書き込み
- アクティビティごとに複数の写真や1つの動画を追加
- 数回のサイト内検索、いくつかの検索結果ページのドリルダウン
- 数回にわたるアクティビティの修正
- 写真や動画の整理
- 友達に対するお礼の送信
- 再度サインインして上記をさらに実行
このような平均的なユーザプロファイルを、 jmeter-ruby を使ってJMeterスクリプトにしました。そのあと Flood IO を使い、ZeeMee Webサービスのステージング環境に対して多くの同時並行処理でそのスクリプトを走らせました。テストの初期段階では、Flood IOがすぐにHeroku上に作ったアプリに大きな負荷をかけました。いっぽう、後半へ行くにつれ、Herokuの能力よりもFlood IOの使い方がボトルネックになっているようでした(この件は以下で詳述します)。
テストを行う中で、私たちはRPM(リクエスト/分)、レスポンスタイム、dynoに対する負荷、データベースに対する負荷(CPU、IOPS、メモリ)を測定し、さらにNew RelicやHerokuのメトリクス機能を使って、サーバのインストルメンテーションを行いました。
テスト全体を通して、コードベースにほぼ変更は加えませんでしたが、唯一変更を必要としたのは、”Test 16の問題”に対処するときです。また、WebワーカがPostgresデータベースへの最大接続数を超えてしまった際に PgBouncer を追加しました。それ以外は、テスト間でRailsのコードベースに手を加えていません。ですから、Heroku上で追加のハードウェアを加えたときに、任意のアプリがいかにスケーリングするかを見極めるには、今回の結果は適したプロキシと言えるでしょう。
結果
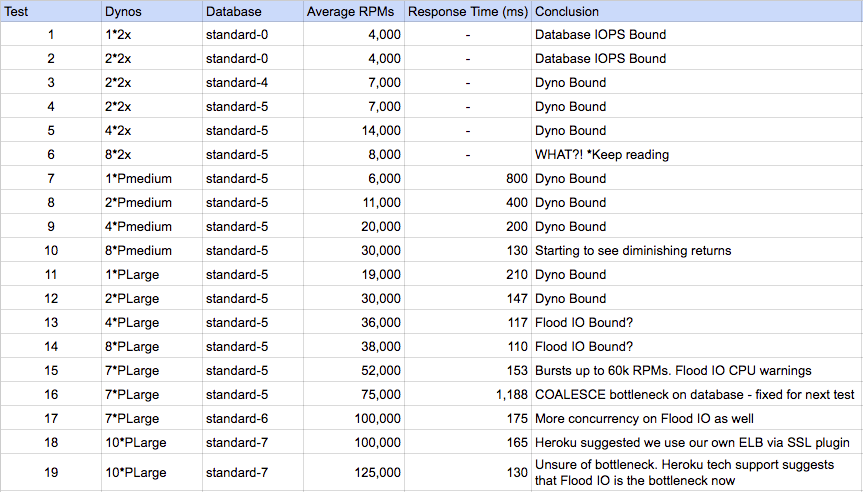
様々なHeroku設定における結果概要
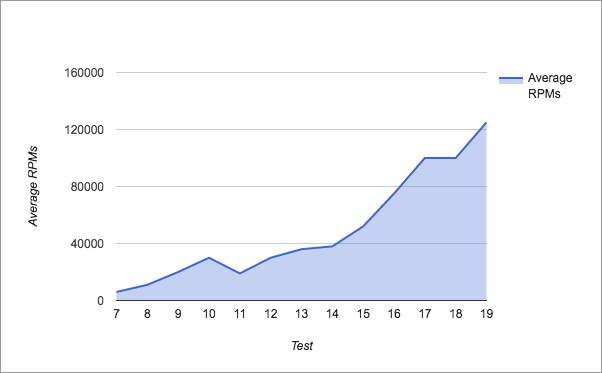
各テストによるRPM
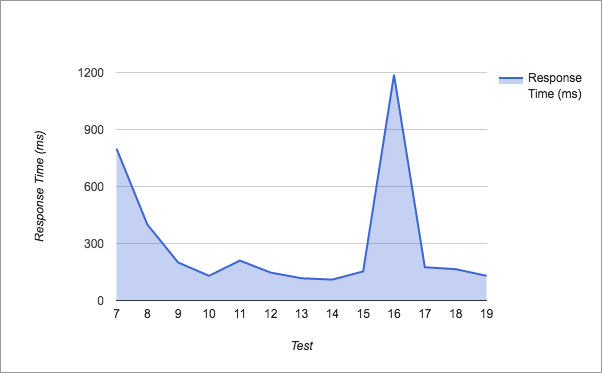
各テストによるレスポンスタイム
テスト1から5 では、dyno数とデータベースハードウェアを増やしたので 予想通り、スケールアップ しました。
注目すべきはテスト6です。全く意味が分かりません! dyno数を倍に増やしたのに、スループットが半減しています。恐らくこれは、2つのdynoが共存した他のHerokuユーザのdynoが非常に多忙だったのでしょう。ハイパーバイザが多忙であるにも関わらず、dynoのインスタンスは低いCPU稼働になっているようでした。この謎を解明するのは、内側からMatrixの外側を見るようなものです。ヒントはありましたが、どれも具体的なものではありませんでした。この件について突き詰めていくと、Herokuのサポートチームが私たちの疑念を解き明かしてくれました。
テスト結果における重要な点は、シングルテナント(performance)dynoを使わない限り、レスポンスが遅い状態をコントロールすることはできないとうことです。
しかし、さらにひどいのは、ロードバランシング用にHerokuがランダムルーティングのアルゴリズムを使用しているため、一つ遅いdynoがあると全てのアプリを使い物にならなくしてしまうのです。単体のHerokuアプリで短いレスポンスタイムと長いレスポンスタイムを混在させると、アプリ全体のパフォーマンスがめちゃくちゃになることは よく知られています 。テスト結果における重要な点は、シングルテナント(performance)dynoを使わない限り、レスポンスが遅い状態をコントロールすることはできないとうことです。騒々しいご近所さんは、遅いクエリと速いクエリを混在させることで起きる同様の問題の原因になります。
複数のテナントの問題を乗り越えたテスト7以降では、何も問題は起きませんでした。 総合的にみて、私たちはHerokuのパフォーマンスに満足しています。しばらくすると効果は減少していったものの、ハードウェアの追加に比例して、大半のスケーリングはうまくいきました( テスト16は例外的ですが、特定のSQLクエリを向上させることで、これは簡単に対処できます )。
総合的にみて、私たちはHerokuのパフォーマンスに満足しています。
最終的に私たちは、HerokuそのものよりもむしろFlood IOの設定が弱点であるということに行き着きました。より多くの分散型のFlood設定でさらにテストを行い、その時がきたら結果を報告したいと思います。
Herokuでスケーリングするためのチェックリスト
最後に、Heroku上でRailアプリをスケーリングする際に覚えておいてほしいことを以下に挙げておきます。
- IOPSデータベースを観察すること。驚くことに今回のテストでは、CPUやメモリの制限を超える前にIOPSの制限を超えてしまいました。
- Postgresへの接続数が限界を超えてしまわないようにするため(大規模なデータベースプランでの接続制限は500)、最終的にはPgBouncerが必要になる。Dyno数を各dynoの同時並行処理数で掛けると概算を出すことができます。私たちは、10個ある各P-Large dynoで67の処理を行っていたので、67×10=670という接続数は、Postgresの接続制限500を上回っていることになります。
- 早い段階でシングルテナント(P-mediumまたはP-large)dynoに移行する。そうすることで、コントロールを取り戻せるだけではなく、移行後のレスポンスタイムの低下と変動を軽減することができます。
- New Relicでアプリのインストルメンテーションを行い、ボトルネックを計測するためにHerokuのMetrics機能を使用する。
- Herokuサポートを利用する。サポートチームは高い専門知識を持っており、様々な問題を解明してくれます。彼らはパフォーマンスグラフや詳細な診断結果を提供してくれました。最高のサポートチームです!
