2016年11月17日
畳み込みニューラルネットワークの仕組み
(2016-08-18)by Brandon Rohrer
本記事は、原著者の許諾のもとに翻訳・掲載しております。
(編注:2016/11/17、記事を修正いたしました。)
ディープラーニングの分野でテクノロジの進化が続いているということが話題になる場合、十中八九畳み込みニューラルネットワークが関係しています。畳み込みニューラルネットワークはCNN(Convolutional Neural Network)またはConvNetとも呼ばれ、ディープニューラルネットワークの分野の主力となっています。CNNは画像を複数のカテゴリに分類するよう学習しており、その分類能力は人間を上回ることもあります。大言壮語のうたい文句を実現している方法が本当にあるとすれば、それはCNNでしょう。
CNNの非常に大きな長所として、理解しやすいことが挙げられます。少なくとも幾つかの基本的な部分にブレークダウンして学べば、それを実感できるでしょう。というわけで、これから一通り説明します。また、画像処理についてこの記事よりも詳細に説明しているビデオがあります。途中で少しつまずいてしまったら、記事中の画像をクリックすれば、関連のビデオを参照できます。
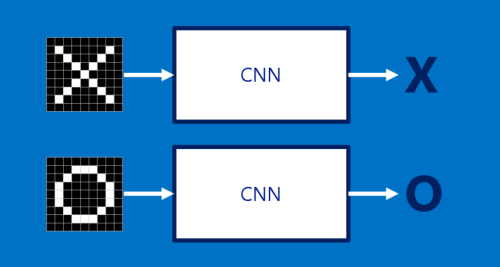
×と○
今回のCNNの説明では、単純化した1つの例題だけを取り上げて検討します。例題は、対象の画像が×か○かを判断する、というものです。これにはCNNの原則を示すのに十分な内容が含まれていますが、それでいて不必要な詳細にはまり込む危険もないほど単純化されています。CNNが実行するジョブは1つだけです。画像をCNNに渡すと、CNNはそれが×か○かを判定します。なおCNNは、渡される画像が常に×か○のどちらかであると想定しています。

この問題を解決するための初歩的なアプローチは、×と○の画像をあらかじめ保存し、渡された画像と保存した画像を比較して、×と○のどちらにより近いかを判定するというものです。このタスクでは、コンピュータは全く融通が利かない点に注意が必要です。コンピュータは、画像をピクセルの2次元配列(巨大なチェッカー盤を思い浮かべてください)として認識しており、ピクセルが置かれる場所にはそれぞれピクセル値が割り振られます。この例題では、1のピクセル値は白、-1は黒を表します。2つの画像を比較する際、1つでも一致しないピクセル値があれば、少なくともコンピュータは、渡された画像は元の画像と同一ではないと判定します。理想としては、渡された画像の配置がずれていたり、画像が縮小していたり、回転していたり、変形していたりしても、コンピュータは×か○かの全体的な形状を見て判定するようにしたいところです。そこでCNNの出番です。
特徴
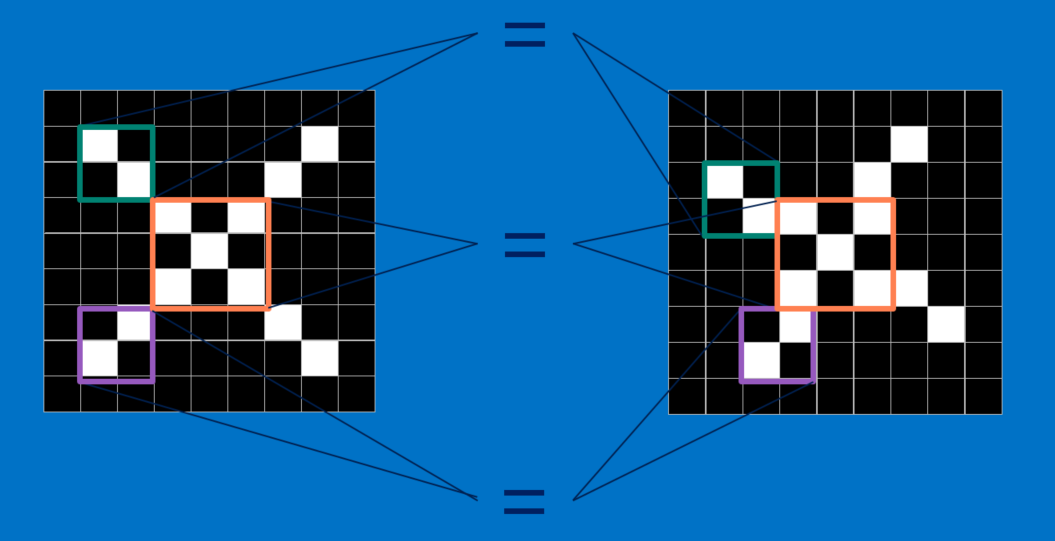
CNNでは、画像をピースごとに比較します。ここでCNNが検索するピースは、特徴と呼ばれます。2つの画像を比較して、だいたい同じ位置にある、特徴がほぼ一致する箇所を検出することで、CNNは、画像全体のマッチングを試みる場合よりも、類似性についてはるかに正確に判定できます。
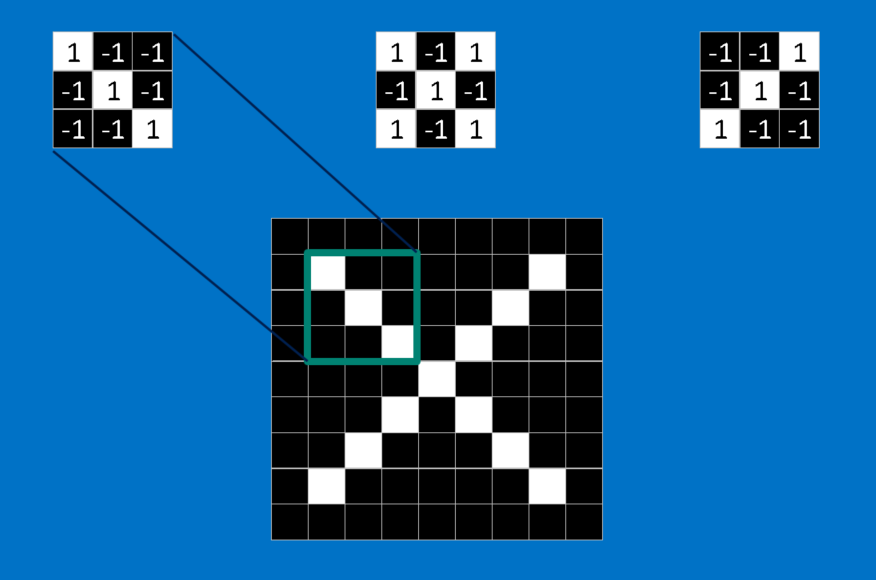
特徴とは、ごく小さい画像、つまり要素数の少ない2次元配列のようなものです。特徴は、画像の共通性のある要素と一致します。×の画像の場合、特徴は対角線と交差で構成されていて、この特徴が×の重要な特質を全て捉えています。これらの特徴はおそらくどの×の画像でも、斜めの線や中心の交点において一致するでしょう。
畳み込み
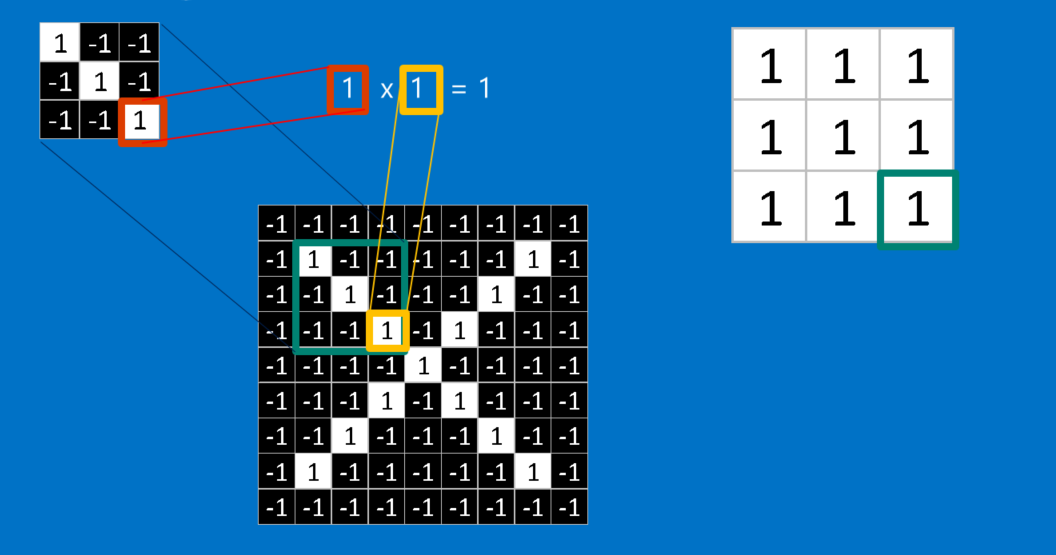
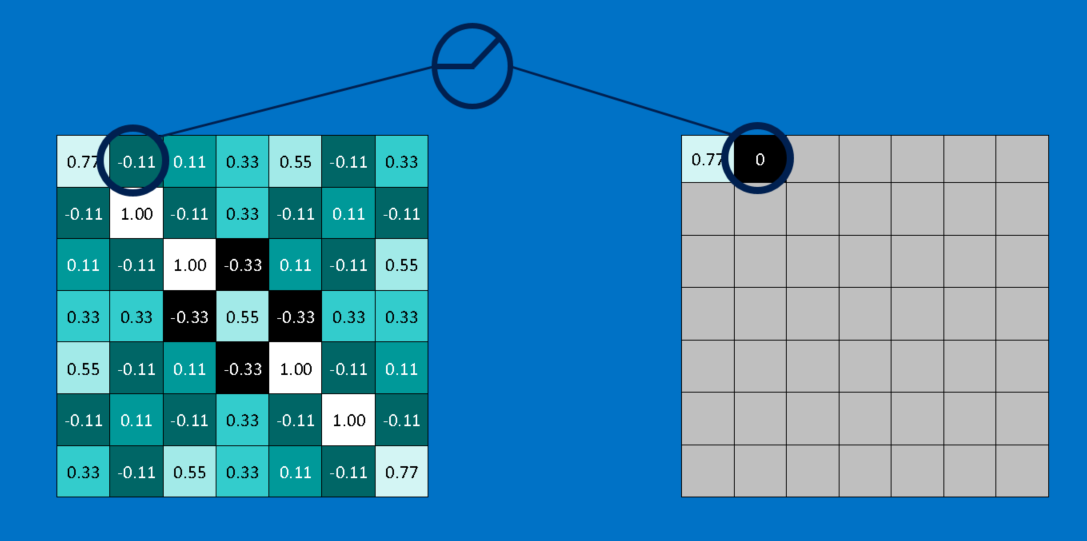
CNNに新しい画像が渡された瞬間、その画像のどこに先述の特徴が含まれているのか、CNNには見当が付かないので、あらゆる位置で特徴の比較と一致点の検出を試みます。画像全体にわたって、特徴の一致件数を計算することによって、フィルタをかけます。この時に実行する演算が「畳み込み」で、畳み込みニューラルネットワークの名称はここから取られています。
畳み込みで行われる計算は、恐らく小学校6年生でも苦にはならないものでしょう。画像のパッチに対する特徴の一致を計算するには、単純に特徴の各ピクセルを、画像内の対応するピクセル値で掛ければいいだけです。そして答えを合計し、特徴のピクセルの総数で割ります。両方のピクセルが白(値が1)なら1×1=1、両方が黒なら(-1)×(-1)=1となり、いずれにしてもピクセルが一致する場合の計算結果は全て1で、同様に一致しない場合は全て-1です。もし特徴の全てのピクセルが一致している場合、それらを加算してピクセルの総数で割れば答えは1となります。逆に特徴のピクセルが全く一致していない場合、答えは-1となります。
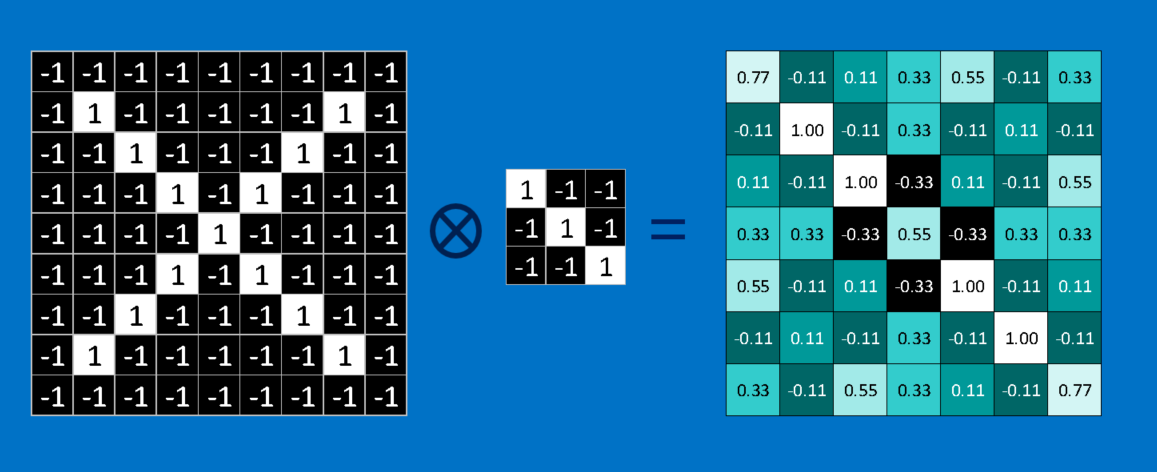
畳み込みを完了するためにこのプロセスを繰り返し、全ての画像パッチで特徴を並べていきます。それぞれの畳み込みから答えが得られたら、各パッチの画像内の位置に基づいて、新たな2次元配列を作ることができます。この一致マップは、元の画像のフィルタ処理版でもあり、特徴が画像内のどこにあるかを視覚化するものです。1に近い値は一致の度合いが強く、-1に近い値は特徴の反転(ネガ)に対して強い一致を示しています。一方でゼロに近い値は、どちらにも一致していないことを示します。

次のステップは、他の各特徴に関して、畳み込み処理を完全な形で繰り返すことです。その結果、それぞれのフィルタによって処理された画像のセットができます。この畳み込みの全体的な工程を単一の処理ステップとして考えるといいでしょう。CNNではこれを畳み込み層と呼んでおり、この畳み込み層は他の層がじきに追加されることを示唆しています。
CNNが計算の鬼として名声を高めたのは、ある意味当然と言えるでしょう。ナプキンの裏にでも書いてその概略を説明してみると、多くの加算や乗算、除算が繰り返されることが分かります。数学的に言うと、それらの計算は画像内のピクセルの数、各特徴のピクセルの数、そして特徴の数に比例して増加します。こうした多くの要因によって、汗を流すことなくこの問題を何百万倍も拡大することができるのです。マイクロチップメーカーがCNNの要求に追いつくために専用チップを開発中だという話も、さほど驚くには当たりません。
プーリング
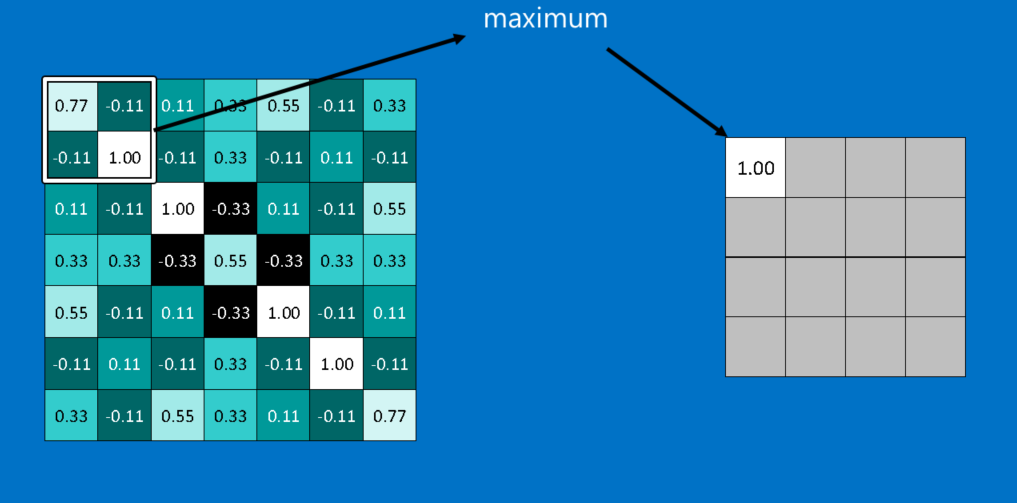
CNNが使う別の強力なツールがプーリングです。プーリングとは、大きな画像を、重要な情報は残しつつ縮小する方法で、画像内を小さなウィンドウに区切り、区切ったそれぞれのウィンドウから最大値を取るというものです。その仕組みは小学校2年生でも理解できるでしょう。実際にはウィンドウの一辺が2ないし3ピクセル、幅が2ピクセルくらいでうまく機能します。
プーリング後、画像のピクセル数は元の4分の1程度になります。それぞれのウィンドウで最大値を取っているため、ウィンドウ内ではそれぞれの特徴の適合度を維持しています。ここではウィンドウ内における特徴の厳密な位置ではなく、ウィンドウの中のどこかに特徴があるということの方が重要です。その結果、CNNは特徴の正確な位置を気にすることなく、画像内で特徴の場所を探すことができます。これは、極度に融通のきかないコンピュータの問題を解決する一助になっています。
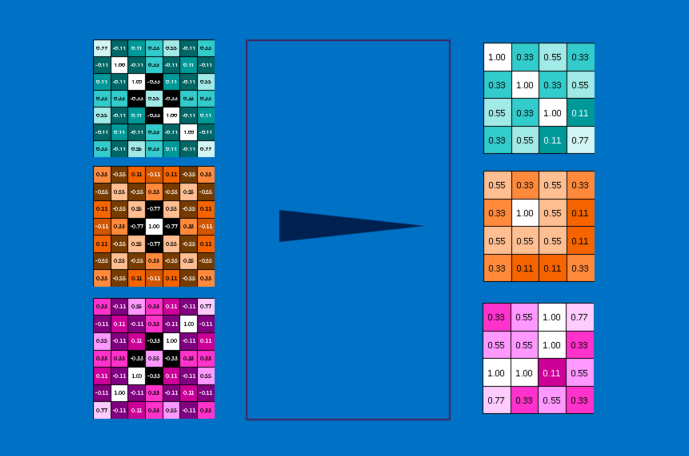
プーリング層とは、画像や画像のコレクションにプーリングを行う操作のことです。結果として出力される画像の枚数は同じですが、それぞれのピクセル数は減少します。これは計算の負荷を管理するのにとても便利で、8メガピクセルの画像が2メガピクセルになれば、下流では処理がはるかに楽になります。
Rectified Linear Units
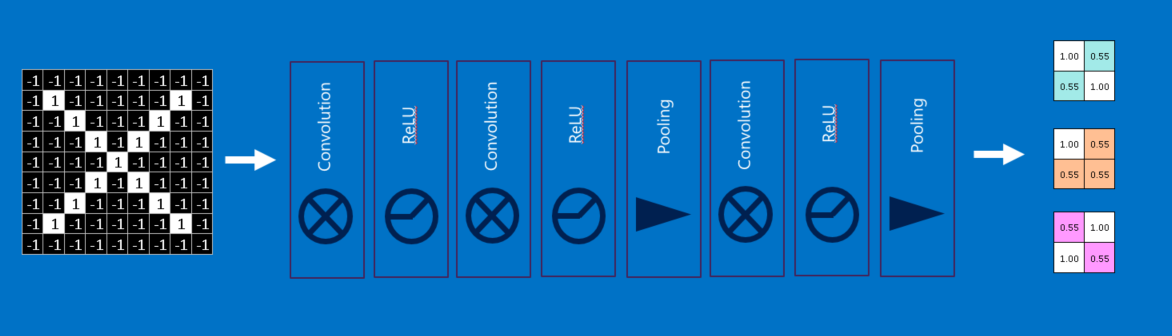
上記の処理において、ささやかながらも重要な役割を果たすのがRectified Linear Units(ReLU)です。その仕組みは非常にシンプルで、マイナスの数字が生じた時に、それを0に変換します。これで学習値が0付近で立ち往生したり無限に向かったりすることがなくなり、CNNの健全性が保たれるのです。たとえて言うならCNNの回転軸に塗るグリースのような感じでしょうか。それ自身では特に魅力は放ちませんが、それがないとCNNは遠くまで行けません。

ReLU層の出力は、入力前と同じサイズですがマイナスの値は取り除かれています。
ディープラーニング
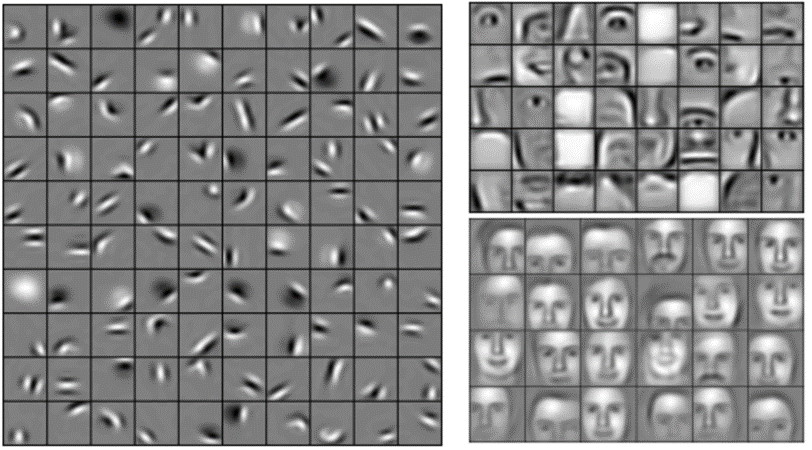
お気付きの方もいると思いますが、各層(2次元配列)への入力は出力(2次元配列)と非常に類似しているため、レゴのように積み重ねることができます。原画像がフィルタ処理され、整流化され、プールされて、特徴がフィルタリングされた縮小画像のセットができあがりますが、このセットには繰り返しのフィルタ処理と縮小が可能です。繰り返すごとに特徴はより大きく複雑になり、画像はよりコンパクトになります。つまり下位層ではエッジやハイライトなどといった画像の単純な面が表現され、上位層では形やパターンといったより複雑な画像の面が表現されるのです。これらは容易に識別できます。例えば人間の顔について訓練がされたCNNの場合、最上位の層は明らかに顔に似たパターンを表します。
全結合層
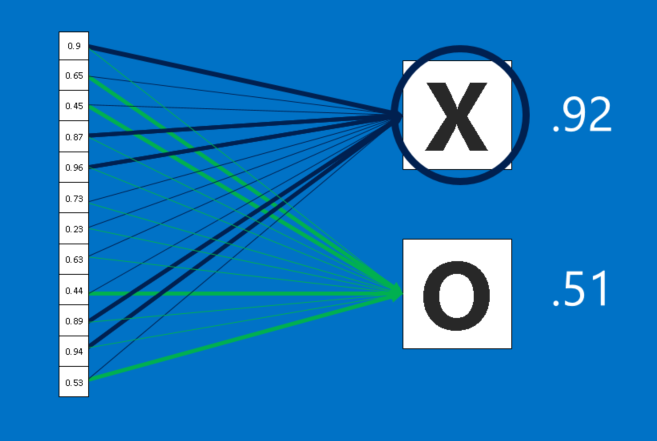
CNNにはさらに別の策もあります。それは全結合層が、フィルタ処理された高次の画像を投票に変換するということです。今回の場合で言うと、選ぶのは×か○の2つのカテゴリのみとなります。全結合層は従来のニューラルネットワークの最も基本的な要素であり、入力を2次元配列として扱う代わりに単一のリストとして全てを同等に扱います。全ての値は現在の画像が×か○かについて、それぞれに票を得ますが、このプロセスは完全に民主的というわけではありません。一部の値は画像が×だった場合にそれを識別する能力が他よりも優れており、一方で○の場合の画像を識別するのがめっぽう得意な値もあるからです。これらの値は他よりもたくさんの票を得ます。そして投票の結果は、それぞれの値およびカテゴリ間において重みおよび連結強度で表されます。
新しい画像がCNNに示された時、その画像が下位層を通過して最終的に全結合層に達します。そして選挙が行われ、票数の多い答えが勝利して入力のカテゴリを宣言するという流れです。

全結合層も、出力(投票のリスト)と入力(値のリスト)は全体的に類似しているため、その他の層と同じように積み重ねることができます。実際に複数の全結合層が一緒に積み重ねられることは少なくありません(その際、それぞれの中間層は実態のない”隠し”カテゴリに投票します)。その結果として、層が追加されるごとにネットワークはさらに洗練された特徴の組み合わせを学び、より良い選択ができるようになります。
バックプロパゲーション
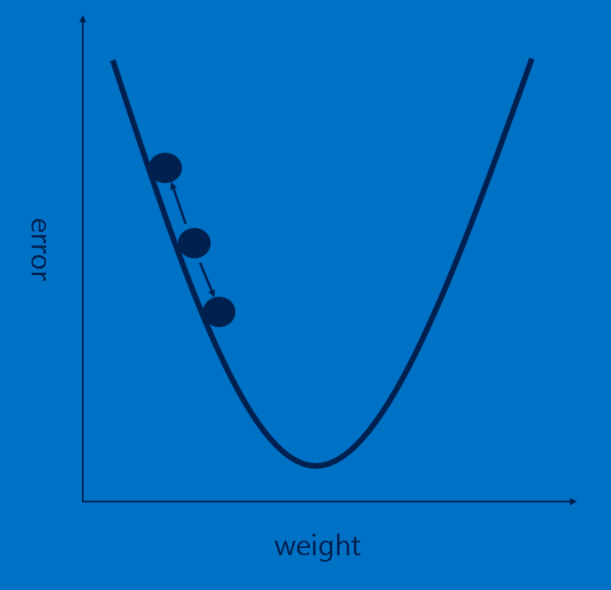
注釈:(横軸)重み (縦軸)誤差
良い感じで説明を進めていると思いますが、まだ大きな穴があります。つまり、特徴はどのようにして定義されるのかと、全結合層における重みをどのように設定するかです。もし、こういったもの全てを手動で選択しなければならなかったとしたら、CNNは恐らく今のようには多くの人の支持を得られていなかったでしょう。幸い、バックプロパゲーションと呼ばれている機械学習のマジックが私たちに代わってこの作業を引き受けてくれます。
バックプロパゲーションを利用するためには、既に答えが分かっている画像のコレクションが必要です。つまり、忍耐強く、数千もの画像を次々と見ていき、×か〇かのラベルを付けたものです。こうしてラベルを付けた画像を、訓練していないCNNに使います。「訓練されていない」とは、個々の特徴の各ピクセルの状態や全結合層におけるあらゆる重みがランダムな値に設定されているという意味です。そこへ、CNNに次から次へと画像の入力を始めるのです。
CNNが各画像を処理すると、投票になります。投票の中の誤り、つまり誤差の量によって、特徴と重みの適切さが分かります。特徴と重みは、誤差を減らすよう調整できます。それぞれの値は上下に少しずつ調整され、新しい誤差が都度計算されます。そして、誤差が少ない方の調整が保持されます。全ての畳み込み層の特徴のピクセルと全結合層の重みにこの作業をかけた後、新しい重みによって、画像判定効果がわずかに改善された回答が得られます。ラベル付き画像セットの中の画像を使ってこの作業が次々と繰り返されます。1枚の画像にのみ起こるねじれはすぐに忘れられますが、多くの画像に起こるパターンは、特徴と接続の重みに埋め込まれます。ラベルの付いている画像が多いほど、セットに対する値が安定し、幅広いケースに適用することが可能になります。
恐らく、これではっきり分かったと思いますが、バックプロパゲーションもまた、計算の負荷が高いステップで、専門的なコンピュータハードウェアを利用したいと考える動機の1つとなります。
ハイパーパラメータ
残念ながら、CNNの全ての面がそれほどすんなり学べるわけではありません。CNNの設計者が行う必要のある意思決定はまだたくさんあります。
- 各畳み込み層の特徴の数は? 各特徴におけるピクセルの数は?
- 各プーリング層のウィンドウのサイズは? ストライドは?
- 追加された各全結合層の隠しニューロンの数は?
これらに加え、構造に関して、よりハイレベルな意思決定をしなければなりません。それぞれ何層にするかと、どのような順序にするかです。ディープニューラルネットワークには1000を超える層を持たせることが可能なので、多くの可能性が開かれています。
多くの順列組み合わせがありますが、可能なCNNコンフィギュレーションのうちのごく一部しかテストは行われていません。CNNの設計は、コミュニティの知識の蓄積からもたらされることが多く、時にはパフォーマンスが驚くほど向上するような逸脱もあります。さて、ここまでCNNの基礎の基礎を一通り説明してきましたが、新種の層や層接続のより複雑な方法など、実験の結果、既に効果が確認されている手法が他にもたくさんあります。
画像を超えて
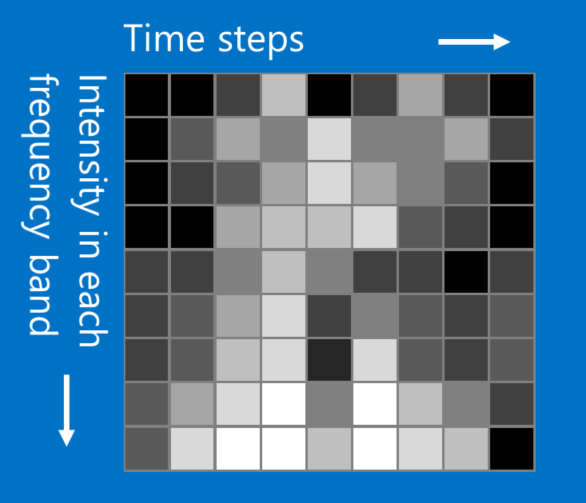
注釈:(横軸)タイムステップ (縦軸)各周波数帯の密度
ここで使用している×と〇のサンプルは画像ですが、CNNは画像以外のデータ型も分類することができます。その手法とは、もともとのデータ型が何であっても、先述の画像と同じように処理できるものに変換することです。例えば、音声信号は、短時間のチャンクに分割することができます。そして、各チャンクを低音域、中音域、高音域、あるいは、より細かい周波数帯に分割します。それによって、列がタイムチャンクで、行が周波数帯である2次元配列として表現することができます。このフェイク画像の中の近接する「ピクセル」同士には緊密な関係があります。これにCNNがうまく機能するのです。研究者は、非常にクリエイティブになり、テキストデータを自然言語処理に、化学データを薬品開発にさえ適応させてきました。
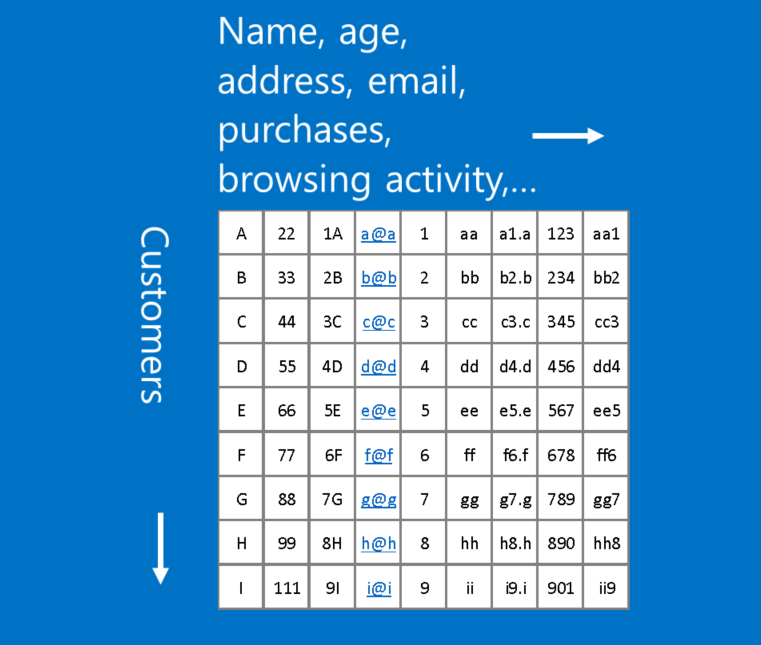
注釈:(横軸)名前、年齢、住所、Eメール、購入履歴、閲覧履歴等 (縦軸)顧客
この形式に合わないデータの例は、顧客データです。顧客データでは、テーブルの行が顧客、列が名前、住所、Eメール、購入履歴、閲覧履歴などの顧客情報を表しています。この場合、行や列のどの位置かはさほど重要ではありません。列の配置を変更しても、行を並べ替えても、データの有用性を損ねることはありません。逆に、画像の行や列を並べ替えた場合、多くは使い物にならなくなります。
大雑把に言えば、列を入れ替えてもデータの有用性が変わらない場合、CNNは使えません。
しかし、問題を画像のようなパターンに変換できるなら、CNNが最適かもしれません。
より深く学ぶために
ディープラーニングについてもっと知りたいと思ったら、私の ディープラーニングについて解説した投稿 が参考になると思います。また、この投稿を書くきっかけとなったJustin Johnson氏とAndrej Karpathy氏の Stanford CS 231コースからのノート や、ニューラルネットワーク関係で非常に分かりやすい文章を書く Christopher Olah氏 の著作もお薦めです。
作業を通して学習したい方には、人気のディープラーニングツールがあります。ぜひ全て試してみてください。そして、その感想を聞かせてください。
畳み込みニューラルネットワークやその関連分野についての説明をお楽しみいただけましたでしょうか。お気軽にご意見、ご質問をください。
